LARS
v2.0-beta8:

LARS é um aplicativo que permite executar LLM (Large Language Models) localmente em seu dispositivo, fazer upload de seus próprios documentos e participar de conversas em que o LLM fundamenta suas respostas com o conteúdo carregado. Esse aterramento ajuda a aumentar a precisão e reduzir o problema comum de imprecisões ou “alucinações” geradas por IA. Esta técnica é comumente conhecida como "Geração Aumentada de Recuperação" ou RAG.
Existem muitos aplicativos de desktop para executar LLMs localmente, e o LARS pretende ser o aplicativo LLM de código aberto definitivo centrado em RAG. Para esse fim, o LARS leva o conceito de RAG muito mais longe, adicionando citações detalhadas a cada resposta, fornecendo nomes de documentos específicos, números de páginas, destaques de texto e imagens relevantes para sua pergunta, e até mesmo apresentando um leitor de documentos diretamente no janela de resposta. Embora nem sempre todas as citações estejam presentes para todas as respostas, a ideia é ter pelo menos alguma combinação de citações apresentadas para cada resposta RAG e geralmente é esse o caso.
Vídeo de demonstração de recursos do LARS
Python v3.10.x ou superior: https://www.python.org/downloads/
PyTorch:
Se você planeja usar sua GPU para executar LLMs, certifique-se de instalar os drivers de GPU e os kits de ferramentas CUDA/ROCm conforme apropriado para sua configuração e só então prossiga com a configuração do PyTorch abaixo
Baixe e instale a versão PyTorch apropriada para o seu sistema: https://pytorch.org/get-started/locally/
Clone o repositório:
git clone https://github.com/abgulati/LARS
cd LARS
GitHub Settings -> Developer settings (located on the bottom left!) -> Personal access tokensInstale dependências do Python:
Janelas via PIP:
pip install -r .requirements.txt
Linux via PIP:
pip3 install -r ./requirements.txt
Observação sobre o Azure: algumas bibliotecas obrigatórias do Azure NÃO estão disponíveis na plataforma MacOS! Um arquivo de requisitos separado é, portanto, incluído para MacOS, excluindo estas bibliotecas:
MacOS:
pip3 install -r ./requirements_mac.txt
Voltar ao índice
Após a instalação, execute o LARS usando:
cd web_app
python app.py # Use 'python3' on Linux/macOS
Navegue para http://localhost:5000/ no seu navegador
Todos os diretórios de aplicativos exigidos pelo LARS serão agora criados em disco
O servidor HF-Waitress será iniciado automaticamente e fará o download de um LLM (Microsoft Phi-3-Mini-Instruct-44) na primeira execução, o que pode demorar um pouco dependendo da velocidade da sua conexão com a Internet
Na primeira consulta, um modelo de incorporação (all-mpnet-base-v2) será baixado do HuggingFace Hub, o que deve demorar um pouco
Voltar ao índice
No Windows:
Baixe o Microsoft Visual Studio Build Tools 2022 do site oficial - "Ferramentas para Visual Studio"
NOTA: Ao instalar o acima, certifique-se de selecionar os seguintes componentes:
Desktop development with C++
# Then from the "Optional" category on the right, make sure to select the following:
MSVC C++ x64/x86 build tools
C++ CMake tools for Windows
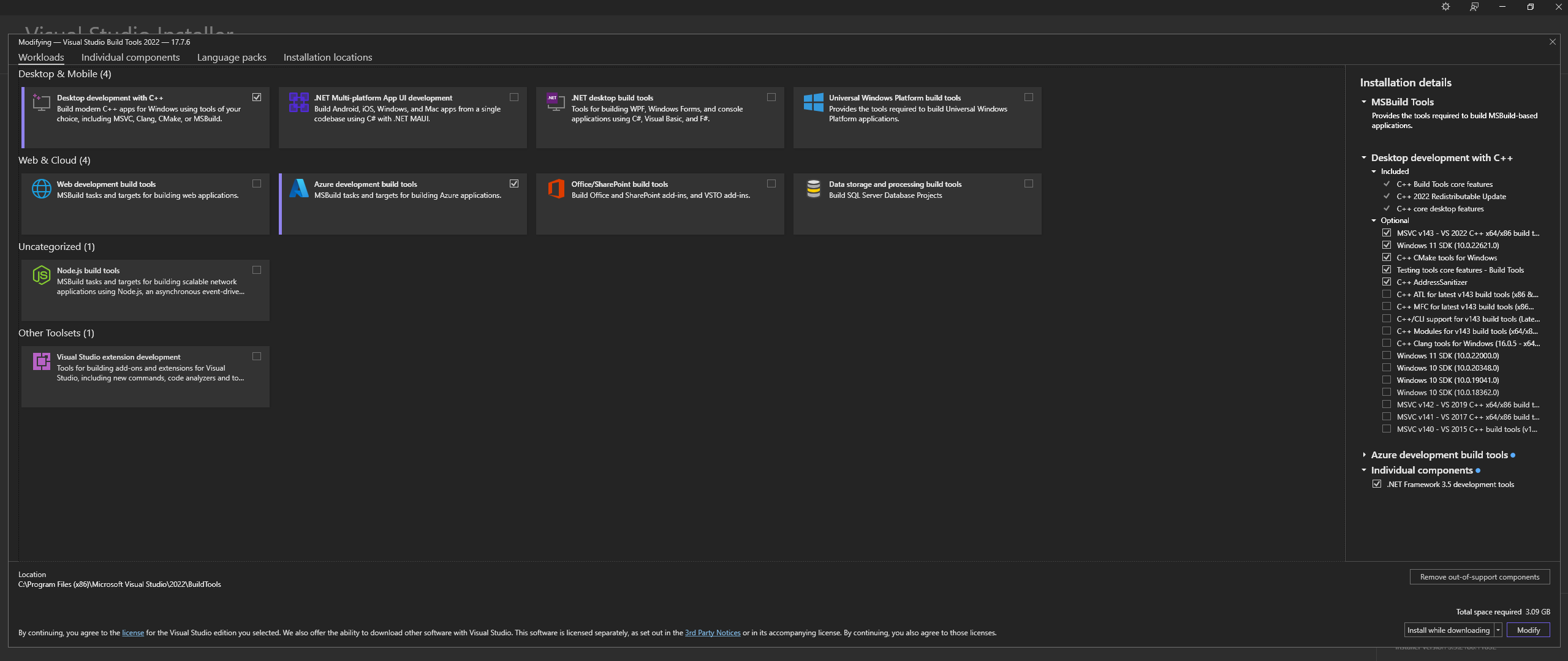
Desktop development with C++ e os opcionais MSVC and C++ CMake estejam selecionados conforme descrito acimaNo Linux (baseado em Ubuntu e Debian), instale os seguintes pacotes:
sudo apt-get update
sudo apt-get install -y software-properties-common build-essential libffi-dev libssl-dev cmake
Baixe do repositório oficial:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
Instale CMAKE no Windows a partir do site oficial
C:Program FilesCMakebinConstrua llama.cpp com CMAKE:
Nota: Para uma compilação mais rápida, adicione o argumento -j para executar vários trabalhos em paralelo. Por exemplo, cmake --build build --config Release -j 8 executará 8 trabalhos em paralelo.
Construa com CUDA:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="52;61;70;75;80;86"
cmake --build build --config Release
cmake -B build
cmake --build build --config Release
Se você enfrentar problemas ao tentar executar CMake -B build , verifique as extensas etapas de solução de problemas de instalação do CMake abaixo
Adicione ao PATH:
path_to_cloned_repollama.cppbuildbinRelease
Verifique a instalação através do terminal:
llama-server
Instale drivers de GPU Nvidia
Instale o Nvidia CUDA Toolkit - LARS construído e testado com v12.2 e v12.4
Verifique a instalação através do terminal:
nvcc -V
nvidia-smi
Correção CMAKE-CUDA (muito importante!):
Copie todos os quatro arquivos do seguinte diretório:
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.2extrasvisual_studio_integrationMSBuildExtensions
e cole-os no seguinte diretório:
C:Program Files (x86)Microsoft Visual Studio2022BuildToolsMSBuildMicrosoftVCv170BuildCustomizations
Esta é uma dependência opcional, mas altamente recomendada - Somente PDFs serão suportados se esta configuração não for concluída
Windows:
Baixe do site oficial
Adicione ao PATH, por meio de:
Configurações avançadas do sistema -> Variáveis de ambiente -> Variáveis de sistema -> Variável EDIT PATH -> Adicione o abaixo (altere de acordo com seu local de instalação):
C:Program FilesLibreOfficeprogram
Ou via PowerShell:
Set PATH=%PATH%;C:Program FilesLibreOfficeprogram
Linux baseado em Ubuntu e Debian - Baixe do Site Oficial ou instale via terminal:
sudo apt-get update
sudo apt-get install -y libreoffice
Fedora e outras distros baseadas em RPM - Baixe no Site Oficial ou instale via terminal:
sudo dnf update
sudo dnf install libreoffice
MacOS – Baixe no Site Oficial ou instale via Homebrew:
brew install --cask libreoffice
Verifique a instalação:
No Windows e MacOS: execute o aplicativo LibreOffice
No Linux através do terminal:
libreoffice --version
LARS utiliza a biblioteca Python pdf2image para converter cada página de um documento em uma imagem conforme necessário para OCR. Esta biblioteca é essencialmente um wrapper em torno do utilitário Poppler que cuida do processo de conversão.
Windows:
Baixe do repositório oficial
Adicione ao PATH, por meio de:
Configurações avançadas do sistema -> Variáveis de ambiente -> Variáveis de sistema -> Variável EDIT PATH -> Adicione o abaixo (altere de acordo com seu local de instalação):
path_to_installationpoppler_versionLibrarybin
Ou via PowerShell:
Set PATH=%PATH%;path_to_installationpoppler_versionLibrarybin
Linux:
sudo apt-get update
sudo apt-get install -y poppler-utils wget
Esta é uma dependência opcional - o Tesseract-OCR não é usado ativamente no LARS, mas os métodos para usá-lo estão presentes no código-fonte
Windows:
Baixe Tesseract-OCR para Windows via UB-Mannheim
Adicione ao PATH, por meio de:
Configurações avançadas do sistema -> Variáveis de ambiente -> Variáveis de sistema -> Variável EDIT PATH -> Adicione o abaixo (altere de acordo com seu local de instalação):
C:Program FilesTesseract-OCR
Ou via PowerShell:
Set PATH=%PATH%;C:Program FilesTesseract-OCR
Voltar ao índice
LARS foi construído e testado com Python v3.11.x
Instale o Python v3.11.x no Windows:
Baixe v3.11.9 do site oficial
Durante a instalação, marque "Adicionar Python 3.11 ao PATH" ou adicione-o manualmente mais tarde, por meio de:
Configurações avançadas do sistema -> Variáveis de ambiente -> Variáveis de sistema -> Variável EDIT PATH -> Adicione o abaixo (altere de acordo com seu local de instalação):
C:Usersuser_nameAppDataLocalProgramsPythonPython311
Ou via PowerShell:
Set PATH=%PATH%;C:Usersuser_nameAppDataLocalProgramsPythonPython311
Instale Python v3.11.x no Linux (baseado em Ubuntu e Debian):
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt-get update
sudo apt-get install -y python3.11 python3.11-venv python3.11-dev
sudo python3.11 -m ensurepip
Verifique a instalação através do terminal:
python3 --version
Se você encontrar erros com pip install , tente o seguinte:
Remova os números de versão:
==version.number , por exemplo:urllib3==2.0.4urllib3Crie e use um ambiente virtual Python:
É aconselhável usar um ambiente virtual para evitar conflitos com outros projetos Python
Windows:
Crie um ambiente virtual Python (venv):
python -m venv larsenv
Ative e posteriormente use o venv:
.larsenvScriptsactivate
Desative venv quando terminar:
deactivate
Linux e MacOS:
Crie um ambiente virtual Python (venv):
python3 -m venv larsenv
Ative e posteriormente use o venv:
source larsenv/bin/activate
Desative venv quando terminar:
deactivate
Se os problemas persistirem, considere abrir um problema no repositório GitHub do LARS para obter suporte.
CMake nmake failed ao tentar criar llama.cpp, como abaixo: 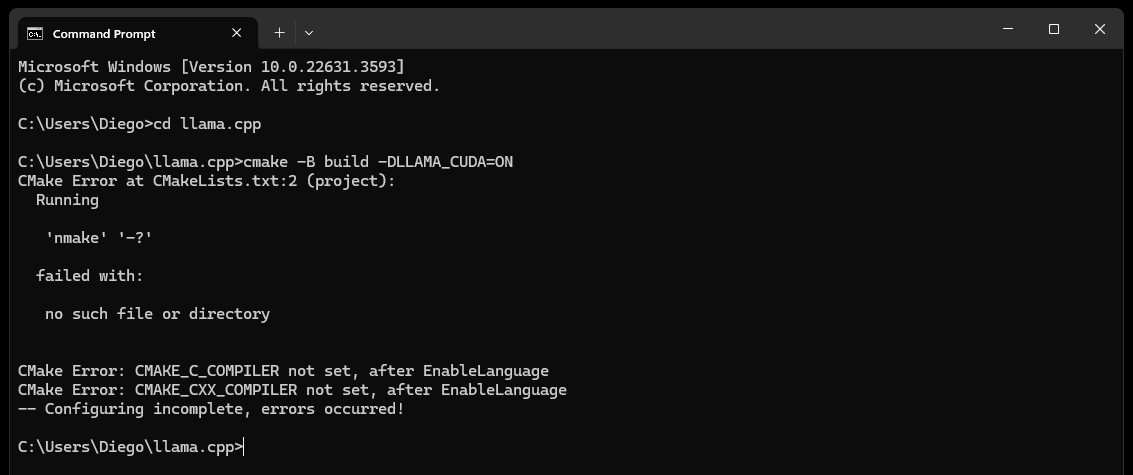
Isso normalmente indica um problema com as ferramentas de compilação do Microsoft Visual Studio, pois o CMake não consegue encontrar a ferramenta nmake, que faz parte das ferramentas de compilação do Microsoft Visual Studio. Tente as etapas abaixo para resolver o problema:
Certifique-se de que as ferramentas de compilação do Visual Studio estejam instaladas:
Certifique-se de ter as ferramentas de compilação do Visual Studio instaladas, incluindo o nmake. Você pode instalar essas ferramentas por meio do Instalador do Visual Studio selecionando a carga de trabalho Desktop development with C++ e os Opcionais MSVC and C++ CMake
Verifique a Etapa 0 da seção Dependências, especificamente a captura de tela nela contida
Verifique as variáveis de ambiente:
C:Program Files (x86)Microsoft Visual Studio2019CommunityVCAuxiliaryBuild
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7IDE
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7Tools
Use o prompt de comando do desenvolvedor:
Abra um "Prompt de Comando do Desenvolvedor para Visual Studio" que configura as variáveis de ambiente necessárias para você
Você pode encontrar esse prompt no menu Iniciar no Visual Studio
Definir gerador CMake:
cmake -G "NMake Makefiles" -B build -DLLAMA_CUDA=ON
Se os problemas persistirem, considere abrir um problema no repositório GitHub do LARS para obter suporte.
Eventualmente (após aproximadamente 60 segundos) você verá um alerta na página indicando um erro:
Failed to start llama.cpp local-server
Isso indica que a primeira execução foi concluída, todos os diretórios de aplicativos foram criados, mas nenhum LLM está presente no diretório models e agora pode ser movido para ele
Mova seus LLMs (qualquer formato de arquivo suportado por llama.cpp, de preferência GGUF) para o diretório models recém-criado, localizado por padrão nos seguintes locais:
C:/web_app_storage/models/app/storage/models/app/models Depois de colocar seus LLMs no diretório models apropriado acima, atualize http://localhost:5000/
Você receberá novamente um alerta de erro informando Failed to start llama.cpp local-server após aproximadamente 60 segundos
Isso ocorre porque seu LLM agora precisa ser selecionado no menu Settings do LARS
Aceite o alerta e clique no ícone de engrenagem Settings no canto superior direito
Na guia LLM Selection , selecione seu LLM e o formato de modelo de prompt apropriado nos menus suspensos apropriados
Modifique as configurações avançadas para definir corretamente as opções GPU , o Context-Length e, opcionalmente, o limite de geração de token ( Maximum tokens to predict ) para o LLM selecionado
Clique em Save e se uma atualização automática não for acionada, atualize a página manualmente
Se todas as etapas foram executadas corretamente, a configuração inicial está concluída e o LARS está pronto para uso
O LARS também lembrará suas configurações do LLM para uso posterior
Voltar ao índice
Formatos de documentos suportados:
Se o LibreOffice estiver instalado e adicionado ao PATH conforme detalhado na Etapa 4 da seção Dependências, os seguintes formatos serão suportados:
Se o LibreOffice não estiver configurado, apenas PDFs serão suportados
Opções de OCR para extração de texto:
O LARS fornece três métodos para extrair texto de documentos, acomodando vários tipos e qualidades de documentos:
Extração de texto local: usa PyPDF2 para extração eficiente de texto de PDFs não digitalizados. Ideal para processamento rápido quando a alta precisão não é crítica ou quando o processamento totalmente local é uma necessidade.
Azure ComputerVision OCR – Melhora a precisão da extração de texto e oferece suporte a documentos digitalizados. Útil para lidar com layouts de documentos padrão. Oferece um nível gratuito adequado para testes iniciais e uso de baixo volume, limitado a 5.000 transações/mês a 20 transações/minuto.
OCR do Azure AI Document Intelligence – Melhor para documentos com estruturas complexas, como tabelas. Um analisador personalizado no LARS otimiza o processo de extração.
NOTAS:
As opções de OCR do Azure incorrem em custos de API na maioria dos casos e não são incluídas no LARS.
Um nível gratuito limitado para ComputerVision OCR está disponível conforme link acima. Este serviço é mais barato em geral, mas mais lento e pode não funcionar para layouts de documentos não padrão (exceto A4, etc.).
Considere os tipos de documentos e suas necessidades de precisão ao selecionar uma opção de OCR.
LLMs:
Atualmente, apenas LLMs locais são suportados
O menu Settings oferece muitas opções para o usuário avançado configurar e alterar o LLM por meio da guia LLM Selection
Observe se estiver usando llama.cpp: Muito importante: selecione o formato de modelo de prompt apropriado para o LLM que você está executando
LLMs treinados para os seguintes formatos de modelo de prompt são atualmente suportados via llama.cpp:
Ajuste as configurações do Core por meio de Advanced Settings (aciona o recarregamento do LLM e a atualização da página):
Ajuste as configurações para alterar o comportamento de resposta a qualquer momento:
Incorporação de modelos e banco de dados de vetores:
Quatro modelos de incorporação são fornecidos no LARS:
Com exceção das incorporações Azure-OpenAI, todos os outros modelos são executados inteiramente localmente e gratuitamente. Na primeira execução, esses modelos serão baixados do HuggingFace Hub. Este é um download único e, posteriormente, eles estarão presentes localmente.
O usuário pode alternar entre esses modelos de incorporação a qualquer momento através da guia VectorDB & Embedding Models no menu Settings
Tabela carregada por documentos: No menu Settings , uma tabela é exibida para o modelo de incorporação selecionado exibindo a lista de documentos incorporados ao banco de dados vetorial associado. Se um documento for carregado diversas vezes, ele terá diversas entradas nesta tabela, o que pode ser útil para depurar quaisquer problemas.
Limpando o VectorDB: Use o botão Reset e forneça a confirmação para limpar o banco de dados de vetores selecionado. Isso cria um novo vectorDB em disco para o modelo de incorporação selecionado. O antigo vectorDB ainda está preservado e pode ser revertido modificando manualmente o arquivo config.json.
Editar prompt do sistema:
O prompt do sistema serve como uma instrução para o LLM para toda a conversa
O LARS fornece ao usuário a capacidade de editar o prompt do sistema por meio do menu Settings , selecionando a opção Custom no menu suspenso na guia System Prompt
Alterações no prompt do sistema iniciarão um novo bate-papo
Forçar ativação/desativação do RAG:
Através do menu Settings , o usuário pode forçar a ativação ou desativação do RAG (Retrieval Augmented Generation – o uso do conteúdo de seus documentos para melhorar as respostas geradas pelo LLM) sempre que necessário
Isso geralmente é útil para avaliar as respostas do LLM em ambos os cenários
A desativação forçada também desativará os recursos de atribuição
A configuração padrão, que usa PNL para determinar quando o RAG deve ou não ser executado, é a opção recomendada
Esta configuração pode ser alterada a qualquer momento
Histórico de bate-papo:
Use o menu do histórico de bate-papo no canto superior esquerdo para navegar e retomar conversas anteriores
Muito importante: esteja atento às incompatibilidades de modelos de prompt ao retomar conversas anteriores! Use o ícone Information no canto superior direito para garantir que o LLM usado na conversa anterior e o LLM atualmente em uso sejam baseados nos mesmos formatos de modelo de prompt!
Avaliação do usuário:
Cada resposta pode ser avaliada em uma escala de 5 pontos pelo usuário a qualquer momento
Os dados de classificações são armazenados no banco de dados chat-history.db SQLite3 localizado no diretório do aplicativo:
C:/web_app_storage/app/storage/appOs dados de classificações são muito valiosos para avaliação e refinamento da ferramenta para seus fluxos de trabalho
O que fazer e o que não fazer:
Voltar ao índice
Se um bate-papo der errado ou alguma resposta estranha for gerada, simplesmente tente iniciar um New Chat através do menu no canto superior esquerdo
Alternativamente, inicie um novo bate-papo simplesmente atualizando a página
Se houver problemas com citações ou desempenho do RAG, tente redefinir o vectorDB conforme descrito na Etapa 4 do Guia Geral do Usuário acima
Se surgir algum problema no aplicativo e não for resolvido simplesmente iniciando um novo bate-papo ou reiniciando o LARS, tente excluir o arquivo config.json seguindo as etapas abaixo:
CTRL+Cconfig.json localizado em LARS/web_app (mesmo diretório de app.py )Para quaisquer problemas graves de dados e citações que não sejam resolvidos mesmo com a redefinição do VectorDB conforme descrito na Etapa 4 do Guia Geral do Usuário acima, execute as seguintes etapas:
CTRL+CC:/web_app_storage/app/storage/appSe os problemas persistirem, considere abrir um problema no repositório GitHub do LARS para obter suporte.
Voltar ao índice
O LARS foi adaptado para um ambiente de implantação de contêiner Docker por meio de duas imagens separadas, conforme abaixo:
Ambos têm requisitos diferentes, sendo o primeiro uma implantação mais simples, mas sofrendo um desempenho de inferência muito mais lento devido à CPU e à memória DDR agindo como gargalos
Embora não seja explicitamente obrigatório, alguma experiência com contêineres Docker e familiaridade com os conceitos de conteinerização e virtualização serão muito úteis nesta seção!
Começando com etapas de configuração comuns para ambos:
Instalando o Docker
Sua CPU deve suportar virtualização e deve estar habilitada no BIOS/UEFI do seu sistema
Baixe e instale o Docker Desktop
Se estiver no Windows, pode ser necessário instalar o subsistema Windows para Linux, se ainda não estiver presente. Para fazer isso, abra o PowerShell como administrador e execute o seguinte:
wsl --install
Certifique-se de que o Docker Desktop esteja instalado e funcionando, abra um prompt de comando/terminal e execute o seguinte comando para garantir que o Docker esteja instalado e funcionando corretamente:
docker ps
Crie um volume de armazenamento Docker, que será anexado aos contêineres LARS em tempo de execução:
Criar um volume de armazenamento para uso com o contêiner LARS é altamente vantajoso, pois permitirá que você atualize o contêiner LARS para uma versão mais recente ou alterne entre as variantes de contêiner de CPU e GPU, mantendo todas as suas configurações, histórico de bate-papo e bancos de dados de vetores perfeitamente. .
Execute o seguinte comando em um prompt de comando/terminal:
docker volume create lars_storage_volue
Este volume será anexado ao contêiner LARS posteriormente em tempo de execução, por enquanto prossiga para a construção da imagem LARS nas etapas abaixo.
Em um Prompt de Comando/Terminal, execute os seguintes comandos:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized
docker build -t lars-no-gpu .
# Once the build is complete, run the container:
docker run -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-no-gpu
Uma vez feito isso, navegue até http://localhost:5000/ em seu navegador e siga o restante das etapas da primeira execução e do Guia do usuário
As seções de solução de problemas também se aplicam ao Container-LARS
Requisitos (além do Docker):
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Para Linux, você está com tudo configurado acima, então pule a próxima etapa e vá diretamente para as etapas de construção e execução mais abaixo
Se estiver no Windows, e se esta for a primeira vez que você executa um contêiner de GPU Nvidia no Docker, prepare-se, pois será uma viagem e tanto (bebida favorita ou três altamente recomendadas!)
Arriscando a redundância extrema, antes de prosseguir, certifique-se de que as seguintes dependências estejam presentes:
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Docker Desktop
Windows Subsystem for Linux (WSL)
Consulte a seção Dependências Nvidia CUDA e a seção Configuração do Docker acima se não tiver certeza
Se os itens acima estiverem presentes e configurados, você pode prosseguir
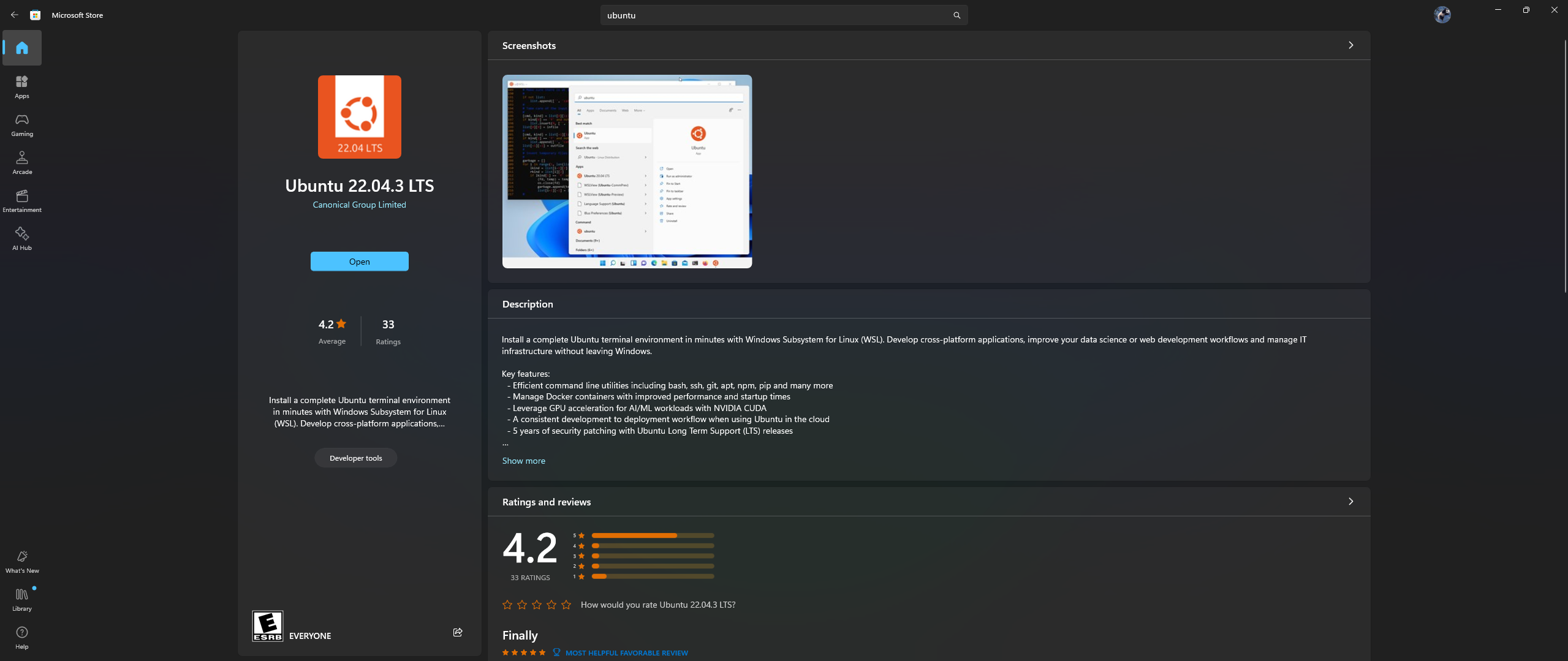
Abra o aplicativo Microsoft Store em seu PC e baixe e instale o Ubuntu 22.04.3 LTS (deve corresponder à versão na linha 2 no dockerfile)
Sim, você leu certo acima: baixe e instale o Ubuntu do aplicativo da loja da Microsoft, consulte a captura de tela abaixo:
Agora é hora de instalar o Nvidia Container Toolkit no Ubuntu, siga as etapas abaixo para fazer isso:
Inicie um shell do Ubuntu no Windows procurando por Ubuntu no menu Iniciar após a conclusão da instalação acima
Nesta linha de comando do Ubuntu que é aberta, execute as seguintes etapas:
Configure o repositório de produção:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
Atualize a lista de pacotes do repositório e instale os pacotes Nvidia Container Toolkit:
sudo apt-get update && apt-get install -y nvidia-container-toolkit
Configure o tempo de execução do contêiner usando o comando nvidia-ctk, que modifica o arquivo /etc/docker/daemon.json para que o Docker possa usar o tempo de execução do contêiner Nvidia:
sudo nvidia-ctk runtime configure --runtime=docker
Reinicie o daemon do Docker:
sudo systemctl restart docker
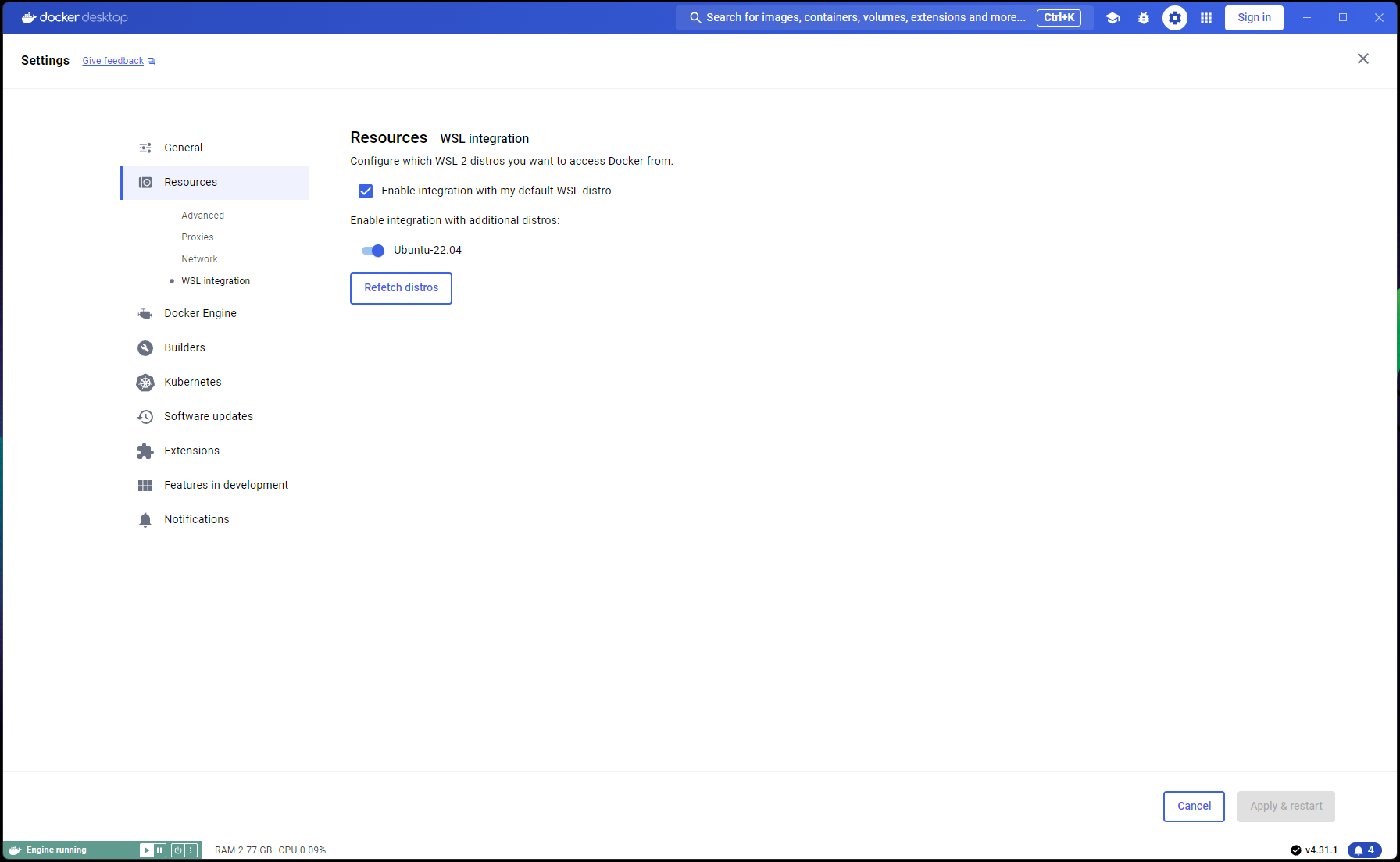
Agora que a configuração do Ubuntu está concluída, é hora de concluir as integrações WSL e Docker:
Abra uma nova janela do PowerShell e defina esta instalação do Ubuntu como padrão WSL:
wsl --list
wsl --set-default Ubuntu-22.04 # if not already marked as Default
Navegue para Docker Desktop -> Settings -> Resources -> WSL Integration -> Verificar integrações padrão e Ubuntu 22.04. Consulte a captura de tela abaixo:
Agora, se tudo foi feito corretamente, você está pronto para construir e executar o contêiner!
Em um Prompt de Comando/Terminal, execute os seguintes comandos:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized_nvidia_cuda_gpu
docker build -t lars-nvcuda .
# Once the build is complete, run the container:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda
Uma vez feito isso, navegue até http://localhost:5000/ em seu navegador e siga o restante das etapas da primeira execução e do Guia do usuário
As seções de solução de problemas também se aplicam ao Container-LARS
Caso você encontre erros relacionados à rede, especialmente relacionados a repositórios de pacotes indisponíveis ao construir o contêiner, este é um problema de rede de sua parte, geralmente relacionado a problemas de Firewall
No Windows, navegue até Control PanelSystem and SecurityWindows Defender FirewallAllowed apps ou pesquise Firewall no menu Iniciar e vá para Allow an app through the firewall e certifique-se de que ```Docker Desktop Backend`` seja permitido através
Na primeira vez que você executar o LARS, o modelo de incorporação de transformadores de sentença será baixado
No ambiente conteinerizado, esse download às vezes pode ser problemático e resultar em erros quando você faz uma consulta
Se isso ocorrer, basta acessar o menu Configurações do LARS: Settings->VectorDB & Embedding Models e alterar o modelo de incorporação para BGE-Base ou BGE-Large, isso forçará um recarregamento e um novo download
Uma vez feito isso, faça perguntas novamente e a resposta deverá ser gerada normalmente
Você pode voltar para o modelo de incorporação de transformadores de frases e o problema deverá ser resolvido
Conforme declarado na seção Solução de problemas acima, os modelos de incorporação são baixados na primeira vez que o LARS é executado
É melhor salvar o estado do contêiner antes de desligá-lo, para que esta etapa de download não precise ser repetida sempre que o contêiner for iniciado.
Para fazer isso, abra outro Prompt de Comando/Terminal e confirme as alterações ANTES de fechar o contêiner LARS em execução:
docker ps # note the container_id here
docker commit <container_ID> <new_image_name> # for new_image_name, I simply add 'pfr', for 'post-first-run' to the current image name, example: lars-nvcuda-pfr
Isso criará uma imagem atualizada que você poderá usar em execuções subsequentes:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda-pfr
NOTA: Feito o acima, se você verificar o espaço usado pelas imagens com docker images , notará muito espaço usado. MAS, não leve os tamanhos aqui literalmente! O tamanho mostrado para cada imagem inclui o tamanho total de todas as suas camadas, mas muitas dessas camadas são compartilhadas entre imagens, especialmente se essas imagens forem baseadas na mesma imagem base ou se uma imagem for uma versão confirmada de outra. Para ver quanto espaço em disco suas imagens Docker estão realmente usando, use:
docker system df
Voltar ao índice
| Categoria | Tarefas | Status |
|---|---|---|
| Correções de bugs: | Perigo de criação de arquivo de texto de zero byte - Às vezes, se o OCR/extração de texto do documento de entrada falhar, um arquivo 0B .txt pode sobrar, o que causa novas tentativas de acreditar que o arquivo já foi carregado | ? Tarefa Futura |
| Recursos práticos: | Centrado na facilidade de uso: | |
| Alternar UI de nível gratuito do Azure CV-OCR | ✅ Feito em 8 de junho de 2024 | |
| Excluir bate-papos | ? Tarefa Futura | |
| Renomear bate-papos | ? Tarefa Futura | |
| Script de instalação do PowerShell | ? Tarefa Futura | |
| Script de instalação do Linux | ? Tarefa Futura | |
| Back-end de inferência do Ollama LLM como alternativa ao llama.cpp | ? Tarefa Futura | |
| Integração de serviços de OCR de outros provedores de nuvem (GCP, AWS, OCI, etc.) | ? Tarefa Futura | |
| Alternância da interface do usuário para ignorar extrações de texto anteriores ao enviar um documento | ? Tarefa Futura | |
| Pop-up modal para uploads de arquivos: espelhar opções de extração de texto das configurações, substituição global em envios, alternar para persistir configurações | ? Tarefa Futura | |
| Centrado no desempenho: | ||
| Suporte Nvidia TensorRT-LLM AWQ | ? Tarefa Futura | |
| Tarefas de pesquisa: | Investigue Nvidia TensorRT-LLM: Necessita construir motores AWQ-LLM TRT específicos para a GPU alvo, NvTensorRT-LLM é seu próprio ecossistema e só funciona em Python v3.10. | ✅ Feito em 13 de junho de 2024 |
| OCR local com Vision LLMs: MS-TrOCR (concluído), Kosmos-2.5 (alta prioridade), Llava, Florence-2 | ? Atualização em andamento de 5 de julho de 2024 | |
| Melhorias no RAG: Reclassificação, RAPTOR, T-RAG | ? Tarefa Futura | |
| Investigue a integração do GraphDB: usando LLMs para extrair dados de relacionamento entre entidades de documentos e preencher, atualizar e manter um GraphDB | ? Tarefa Futura |
Voltar ao índice
Espero que o LARS tenha sido valioso em seu trabalho e convido você a apoiar seu desenvolvimento contínuo! Se você aprecia a ferramenta e gostaria de contribuir com suas melhorias futuras, considere fazer uma doação. Seu apoio me ajuda a continuar melhorando o LARS e adicionando novos recursos.
Como doar Para fazer uma doação, use o seguinte link para meu PayPal:
Doe via PayPal
As suas contribuições são muito apreciadas e serão utilizadas para financiar futuros esforços de desenvolvimento.
Voltar ao índice


