mage ai
0.9.75
Dê poderes mágicos à sua equipe de dados.
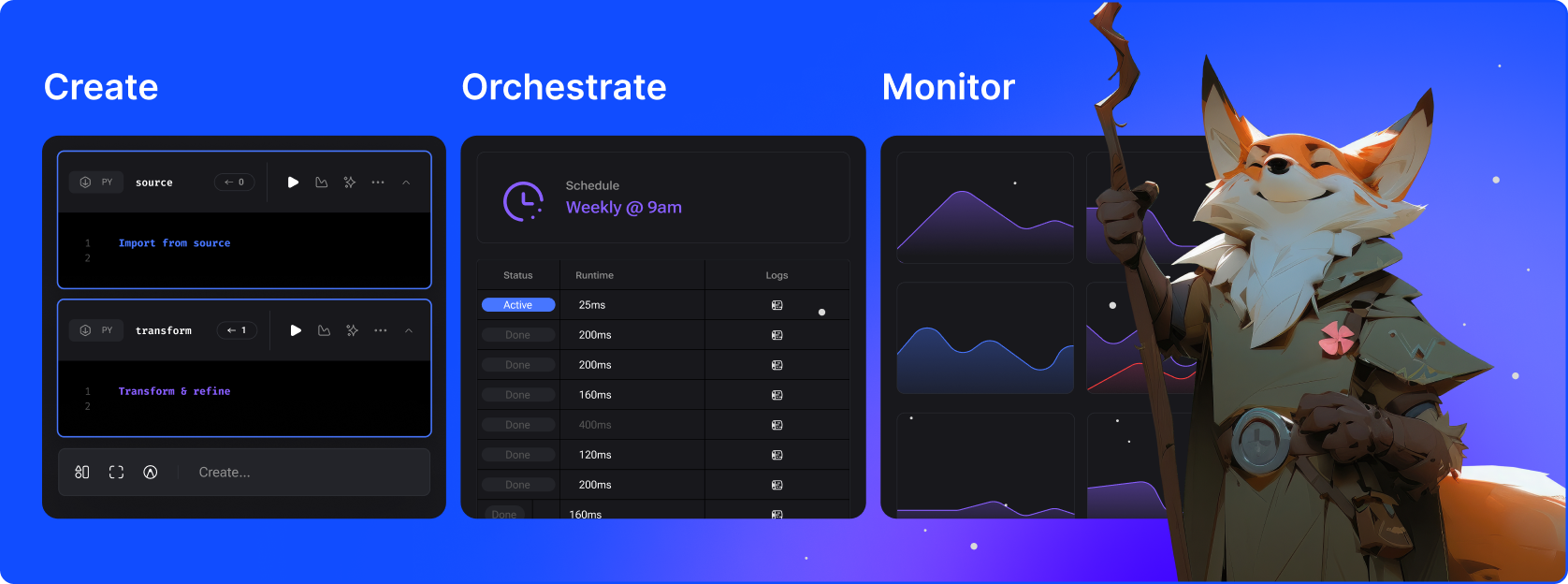
Mage é uma estrutura híbrida para transformação e integração de dados. Combina o melhor dos dois mundos: a flexibilidade dos notebooks com o rigor do código modular.
Extraia e sincronize dados de fontes de terceiros.
Transforme dados com pipelines em tempo real e em lote usando Python, SQL e R.
Carregue dados em seu data warehouse ou data lake usando nossos conectores pré-construídos.
Execute, monitore e orquestre milhares de pipelines sem perder o sono.
Além de centenas de recursos de classe empresarial, inovações de infraestrutura e surpresas mágicas.
 Para equipes. Plataforma totalmente gerenciada para integração e transformação de dados. Para equipes. Plataforma totalmente gerenciada para integração e transformação de dados. |  Auto-hospedado. Sistema para construir, executar e gerenciar pipelines de dados. Auto-hospedado. Sistema para construir, executar e gerenciar pipelines de dados. |
Para obter documentação sobre como começar, como desenvolver e como implantar em produção, confira o live
Portal de documentação do desenvolvedor .
A forma recomendada de instalar a versão mais recente do Mage é através do Docker com o seguinte comando:
docker pull mageai/mageai:mais recente
Você também pode instalar o Mage usando pip ou conda, embora isso possa causar problemas de dependência sem o ambiente adequado.
pip instalar mago-ai
conda install -c conda-forge mage-ai
Procurando ajuda? A maneira mais rápida de começar é verificar nossa documentação aqui.
Procurando exemplos rápidos? Abra um projeto de demonstração diretamente no seu navegador ou confira nossos guias.
Crie e execute um pipeline de dados com nosso aplicativo de demonstração .
AVISO
A demonstração ao vivo é pública para todos, por favor não salve nada sensível (por exemplo, senhas, segredos, etc).

Clique na imagem para reproduzir o vídeo
| Orquestração | Programe e gerencie pipelines de dados com observabilidade. | |
| Caderno | Editor interativo Python, SQL e R para codificação de pipelines de dados. | |
| Integrações de dados | Sincronize dados de fontes de terceiros com seus destinos internos. | |
| Pipelines de streaming | Ingira e transforme dados em tempo real. | |
| DBT | Construa, execute e gerencie seus modelos dbt com Mage. |
Um pipeline de dados de amostra definido em 3 arquivos ➝
Carregar dados ➝
@data_loaderdef load_csv_from_file() -> pl.DataFrame:return pl.read_csv('default_repo/titanic.csv')Transformar dados ➝
@transformerdef select_columns_from_df(df: pl.DataFrame, *args) -> pl.DataFrame:return df[['Idade', 'Fare', 'Sobreviveu']]
Exportar dados ➝
@data_exporterdef export_titanic_data_to_disk(df: pl.DataFrame) -> Nenhum:df.to_csv('default_repo/titanic_transformed.csv')

