Chatbot transformador com TensorFlow 2
Crie um chatbot completo com Transformer no TensorFlow 2. Confira meu tutorial em blog.tensorflow.org.
Atualizações
- 16 de junho de 2022:
- Atualize o script
setup.sh para instalar a versão Apple Silicon do TensorFlow 2.9 (use-o apenas se estiver se sentindo aventureiro). - Atualizadas as duas camadas personalizadas,
PositionalEncoding e MultiHeadAttentionLayer , para permitir o salvamento do modelo via model.save() ou tf.keras.models.save_model() . -
train.py mostra como chamar model.save() e tf.keras.models.load_model() .
- 8 de dezembro de 2020: suporte atualizado para TensorFlow 2.3.1 e TensorFlow Datasets 4.1.0
- 18 de janeiro de 2020: Adicionado notebook com suporte para Google Colab TPU no TensorFlow 2.1.
Pacotes
- TensorFlow 2.9.1
- Conjuntos de dados do TensorFlow
Configurar
- crie um novo ambiente anaconda e inicialize
chatbot do ambiente conda create -n chatbot python=3.8
conda activate chatbot
- execute o script de instalação
- Nota: o script instalaria CUDA e cuDNN via conda se estiver instalando em um sistema Linux, ou
tensorflow-metal para dispositivos com Apple Silicon (observe que há muitos bugs com TensorFlow na GPU Apple Silicon, por exemplo, o otimizador Adam não funciona).
Conjunto de dados
- Usaremos as conversas em filmes e programas de TV fornecidas pelo Cornell Movie-Dialogs Corpus, que contém mais de 220 mil trocas de conversação entre mais de 10 mil pares de personagens de filmes, como nosso conjunto de dados.
- Pré-processamos nosso conjunto de dados na seguinte ordem:
- Extraia pares de conversação
max_samples em uma lista de questions e answers . - Pré-processe cada frase removendo caracteres especiais em cada frase.
- Crie tokenizador (mapeie texto para ID e ID para texto) usando TensorFlow Datasets SubwordTextEncoder.
- Tokenize cada frase e adicione
start_token e end_token para indicar o início e o fim de cada frase. - Filtre a frase que possui mais do que tokens
max_length . - Preencher frases tokenizadas para
max_length
- Verifique a implementação do dataset.py.
Modelo
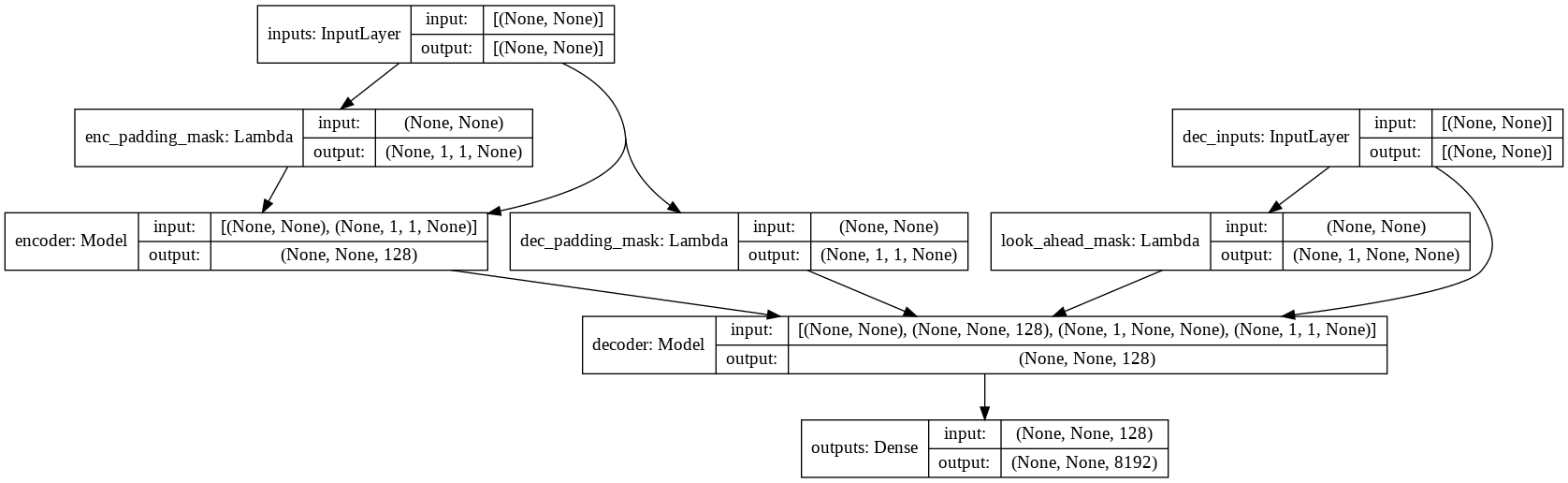
- verifique model.py para a implementação de Atenção Multi-Headed, Codificação Posicional e Transformador.
Correr
- verifique todos os sinalizadores e hiperparâmetros disponíveis
python main.py --help
python train.py --output_dir runs/save_model --batch_size 256 --epochs 50 --max_samples 50000
- o modelo treinado final será salvo em
runs/save_model .
Amostras
input: where have you been?
output: i m not talking about that .
input: it's a trap!
output: no , it s not .


