auto rag eval
1.0.0
Este repositório é o companheiro do artigo ICML 2024 Avaliação automatizada de modelos de linguagem aumentada de recuperação com geração de exame específico de tarefa (Blog)
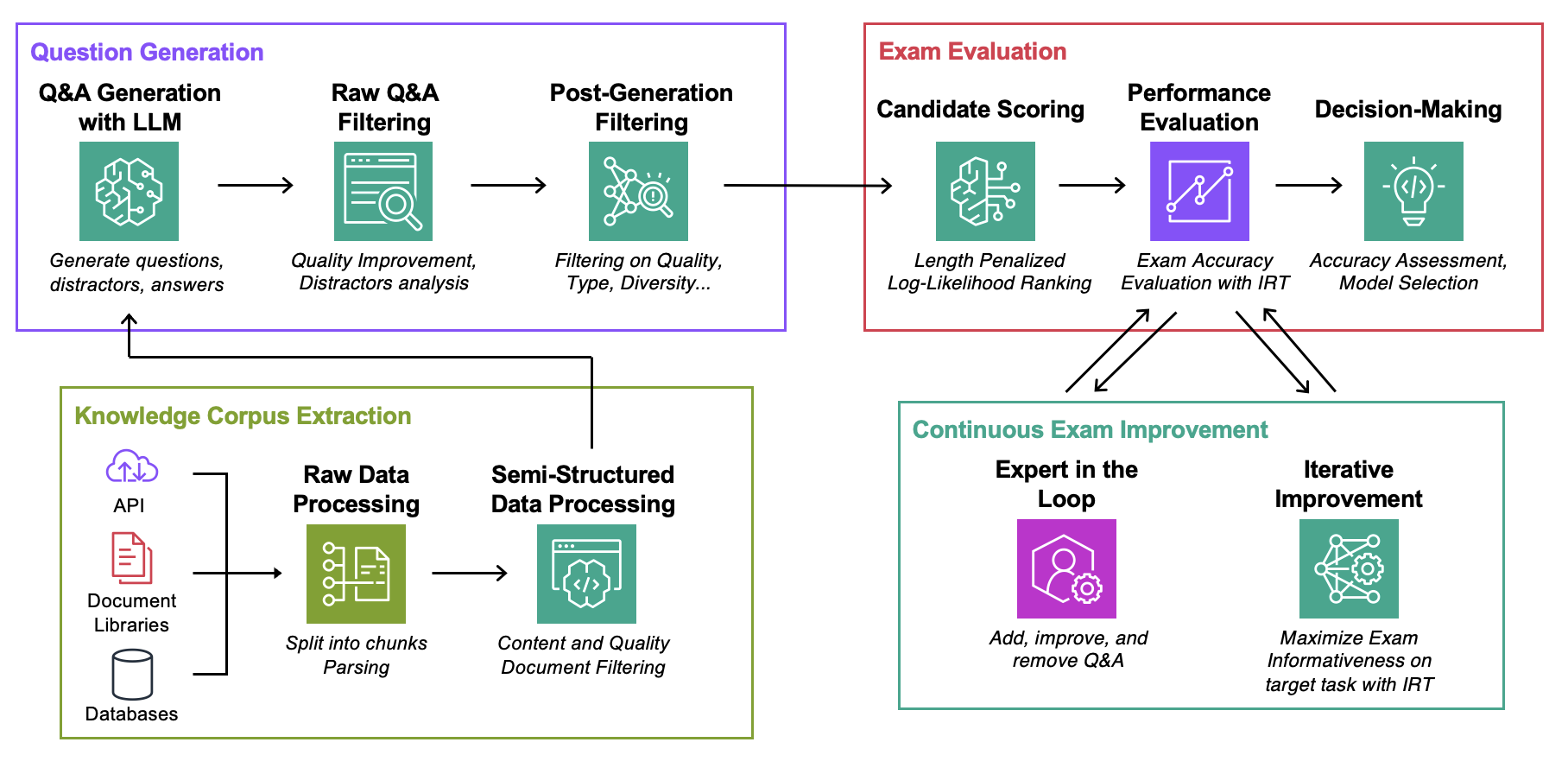
Objetivo : Para um determinado corpus de conhecimento:
A única coisa que você precisa para experimentar este código é um arquivo json com seu corpus de conhecimento no formato descrito abaixo.
Data : para cada caso de uso, contém:ExamGenerator : Código para gerar e processar o exame de múltipla escolha usando corpus de conhecimento e gerador(es) LLM.ExamEvaluator : Código para avaliar o exame usando uma combinação (Retrieval System, LLM, ExamCorpus) , contando com a biblioteca lm-harness .LLMServer : endpoints LLM unificados para gerar o exame.RetrievalSystems : Classes do Sistema de Recuperação Unificado (por exemplo, DPR, BM25, Embedding Similarity...). Ilustramos nossa metodologia em 4 tarefas de interesse: solução de problemas do AWS DevOPS, perguntas e respostas do StackExchange, perguntas e respostas de arquivos secundários e perguntas e respostas do Arxiv. Em seguida, mostramos como adaptar a metodologia a qualquer tarefa.
Execute os comandos abaixo, onde question-date são os dados com a geração de dados brutos. Adicione --save-exam se quiser salvar o exame e remova-o se estiver interessado apenas em análises.
cd auto-rag-eval
rm -rf Data/StackExchange/KnowledgeCorpus/main/ *
python3 -m Data.StackExchange.preprocessor
python3 -m ExamGenerator.question_generator --task-domain StackExchange
python3 -m ExamGenerator.multi_choice_exam --task-domain StackExchange --question-date " question-date " --save-exam cd auto-rag-eval
rm -rf Data/Arxiv/KnowledgeCorpus/main/ *
python3 -m Data.Arxiv.preprocessor
python3 -m ExamGenerator.question_generator --task-domain Arxiv
python3 -m ExamGenerator.multi_choice_exam --task-domain Arxiv --question-date " question-date " --save-exam cd auto-rag-eval
rm -rf Data/SecFilings/KnowledgeCorpus/main/ *
python3 -m Data.SecFilings.preprocessor
python3 -m ExamGenerator.question_generator --task-domain SecFilings
python3 -m ExamGenerator.multi_choice_exam --task-domain SecFilings --question-date " question-date " --save-exam cd src/llm_automated_exam_evaluation/Data/
mkdir MyOwnTask
mkdir MyOwnTask/KnowledgeCorpus
mkdir MyOwnTask/KnowledgeCorpus/main
mkdir MyOwnTask/RetrievalIndex
mkdir MyOwnTask/RetrievalIndex/main
mkdir MyOwnTask/ExamData
mkdir MyOwnTask/RawExamData Armazene em MyOwnTask/KnowledgeCorpus/main um arquivo json , que contém uma lista de documentação, cada uma com o formato abaixo. Consulte DevOps/html_parser.py , DevOps/preprocessor.py ou StackExchange/preprocessor.py para obter alguns exemplos.
{ ' source ' : ' my_own_source ' ,
' docs_id ' : ' Doc1022 ' ,
' title ' : ' Dev Desktop Set Up ' ,
' section ' : ' How to [...] ' ,
' text ' : " Documentation Text, should be long enough to make informative questions but shorter enough to fit into context " ,
' start_character ' : ' N/A ' ,
' end_character ' : ' N/A ' ,
' date ' : ' N/A ' ,
} Primeiro gere o exame bruto e o índice de recuperação. Observe que pode ser necessário adicionar suporte para seu próprio LLM, mais sobre isso abaixo. Você pode querer modificar o prompt usado para a geração do exame na classe LLMExamGenerator em ExamGenerator/question_generator.py .
python3 -m ExamGenerator.question_generator --task-domain MyOwnTaskFeito isso (pode levar algumas horas dependendo do tamanho da documentação), gere o exame processado. Para fazer isso, verifique MyRawExamDate em RawExamData (por exemplo, 2023091223) e execute:
python3 -m ExamGenerator.multi_choice_exam --task-domain MyOwnTask --question-date MyRawExamDate --save-exam Atualmente oferecemos suporte a endpoints para Bedrock (Claude) no arquivo LLMServer . A única coisa necessária para trazer a sua própria classe é uma classe, com uma função inference que recebe um prompt na entrada e na saída do prompt e do texto completo. Modifique a classe LLMExamGenerator em ExamGenerator/question_generator.py para incorporá-la. Diferentes LLM geram diferentes tipos de perguntas. Portanto, você pode querer modificar a análise bruta do exame em ExamGenerator/multi_choice_questions.py . Você pode experimentar usando o notebook failed_questions.ipynb do ExamGenerator .
Aproveitamos o pacote lm-harness para avaliar o sistema (LLM&Retrieval) no exame gerado. Para fazer isso, siga os próximos passos:
Crie uma pasta de benchmark para sua tarefa, aqui DevOpsExam , consulte ExamEvaluator/DevOpsExam para obter o modelo. Ele contém um arquivo de código preprocess_exam,py para modelos de prompt e, mais importante, um conjunto de tarefas para avaliar modelos:
DevOpsExam contém as tarefas associadas ao ClosedBook (não recuperação) e OpenBook (Oracle Retrieval).DevOpsRagExam contém as tarefas associadas às variantes de recuperação (DPR/Embeddings/BM25...). O script task_evaluation.sh fornecido ilustra a avaliação de Llamav2:Chat:13B e Llamav2:Chat:70B na tarefa, usando In-Context-Learning (ICL) com respectivamente 0, 1 e 2 amostras.
Para citar este trabalho, use
@misc{autorageval2024,
title={Automated Evaluation of Retrieval-Augmented Language Models with Task-Specific Exam Generation},
author={Gauthier Guinet and Behrooz Omidvar-Tehrani and Anoop Deoras and Laurent Callot},
year={2024},
eprint={2405.13622},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Consulte CONTRIBUINDO para obter mais informações.
Este projeto está licenciado sob a licença Apache-2.0.


