inverted_index
1.0.0
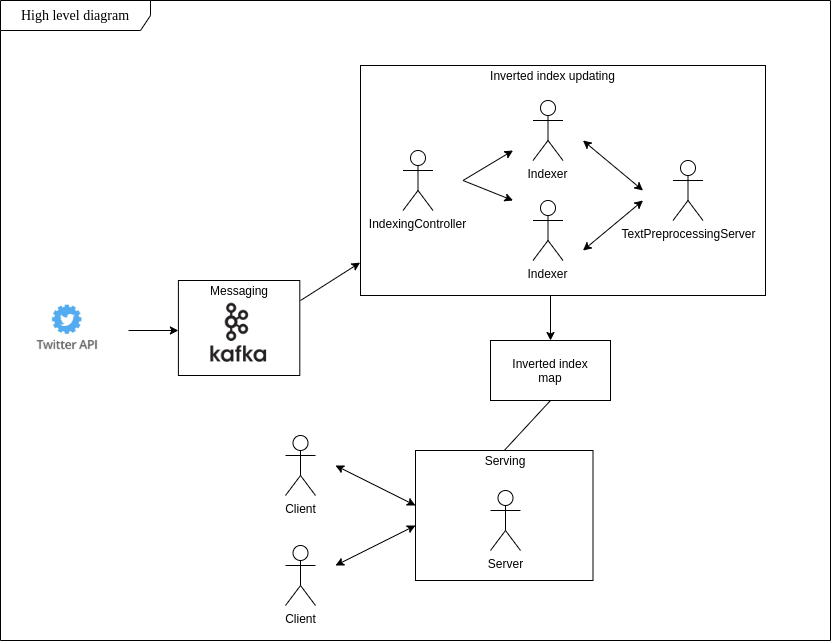
Pesquisar frases que as pessoas dizem pode ser difícil. E quanto às atualizações dinâmicas deste conjunto de dados? Armazenamento escalável e baixa latência? Meu principal objetivo neste projeto é construir um sistema que atenda a esses requisitos e permita estar atualizado com as tendências presentes nos tweets em tempo real.
Seguindo a ideia de índice invertido, implementei o aplicativo que em tempo real encontra tweets com conteúdo específico, armazena-os em um sistema de arquivos local e permite fazer buscas baseadas em palavras logo após inicializar a conexão do cliente.
Para executar o aplicativo você precisa:
git clone https://github.com/cyberpunk317/inverted_index.git TWITTER_APP_KEY = 'YOUR APP KEY'
TWITTER_APP_SECRET = 'YOUR APP SECRET'
TWITTER_KEY = 'YOUR KEY'
TWITTER_SECRET = 'YOUR SECRET' Crie Dockerfiles para cliente e servidor:
./gradlew clean build createClientDockerfile createMainDockerfile
Isso produzirá app_server.Dockerfile e app_client.Dockerfile no diretório raiz.
Iniciar aplicação:
docker-compose up
Inicie uma sessão de cliente:
docker build -f app_client.Dockerfile -t client:latest . && docker run -it --rm --network=host client:latest bash
Comece a digitar palavras de interesse. O servidor retornará a localização dos tweets no formato 'dataset_v2//tweet_N.txt'. Por exemplo:
You entered: war
Server response: [dataset_v2/Veeresh Dambal/tweet_30.txt, dataset_v2/pedro schliesser/tweet_1.txt]
Consulte os problemas em aberto para obter uma lista dos recursos propostos (e dos problemas conhecidos).
Distribuído sob a licença MIT. Consulte LICENSE para obter mais informações.


