textgenrnn
T
Treine facilmente sua própria rede neural geradora de texto de qualquer tamanho e complexidade em qualquer conjunto de dados de texto com algumas linhas de código ou treine rapidamente em um texto usando um modelo pré-treinado.
textgenrnn é um módulo Python 3 baseado em Keras/TensorFlow para criar char-rnns, com muitos recursos interessantes:
Você pode brincar com textgenrnn e treinar qualquer arquivo de texto com GPU gratuitamente neste Notebook Colaboratório! Leia esta postagem do blog ou assista a este vídeo para obter mais informações!
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate () [Spoiler] Anyone else find this post and their person that was a little more than I really like the Star Wars in the fire or health and posting a personal house of the 2016 Letter for the game in a report of my backyard.
O modelo incluído pode ser facilmente treinado em novos textos e pode gerar texto apropriado mesmo após uma única passagem dos dados de entrada .
textgen . train_from_file ( 'hacker_news_2000.txt' , num_epochs = 1 )
textgen . generate () Project State Project Firefox
Os pesos do modelo são relativamente pequenos (2 MB em disco) e podem ser facilmente salvos e carregados em uma nova instância textgenrnn. Como resultado, você pode brincar com modelos que foram treinados em centenas de passagens pelos dados. (na verdade, textgenrnn aprende tão bem que você precisa aumentar significativamente a temperatura para obter resultados criativos!)
textgen_2 = textgenrnn ( '/weights/hacker_news.hdf5' )
textgen_2 . generate ( 3 , temperature = 1.0 ) Why we got money “regular alter”
Urburg to Firefox acquires Nelf Multi Shamn
Kubernetes by Google’s Bern
Você também pode treinar um novo modelo, com suporte para incorporações em nível de palavra e camadas RNN bidirecionais, adicionando new_model=True a qualquer função de treinamento.
Também é possível se envolver no desenrolar do resultado, passo a passo. O modo interativo irá sugerir as N principais opções para o próximo caractere/palavra e permitirá que você escolha uma.
Ao executar textgenrnn no terminal, passe interactive=True e top=N para generate . N padrão é 3.
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate ( interactive = True , top_n = 5 )
Isso pode adicionar um toque humano ao resultado; parece que você é o escritor! (referência)
textgenrnn pode ser instalado a partir do pypi via pip :
pip3 install textgenrnnPara o textgenrnn mais recente, você deve ter uma versão mínima do TensorFlow 2.1.0 .
Você pode ver uma demonstração de recursos comuns e opções de configuração de modelo neste Jupyter Notebook.
/datasets contém conjuntos de dados de exemplo usando dados do Hacker News/Reddit para treinar textgenrnn.
/weights contém modelos pré-treinados nos conjuntos de dados mencionados acima que podem ser carregados em textgenrnn.
/outputs contém exemplos de texto gerado a partir dos modelos pré-treinados acima.
textgenrnn é baseado no projeto char-rnn de Andrej Karpathy com algumas otimizações modernas, como a capacidade de trabalhar com sequências de texto muito pequenas.
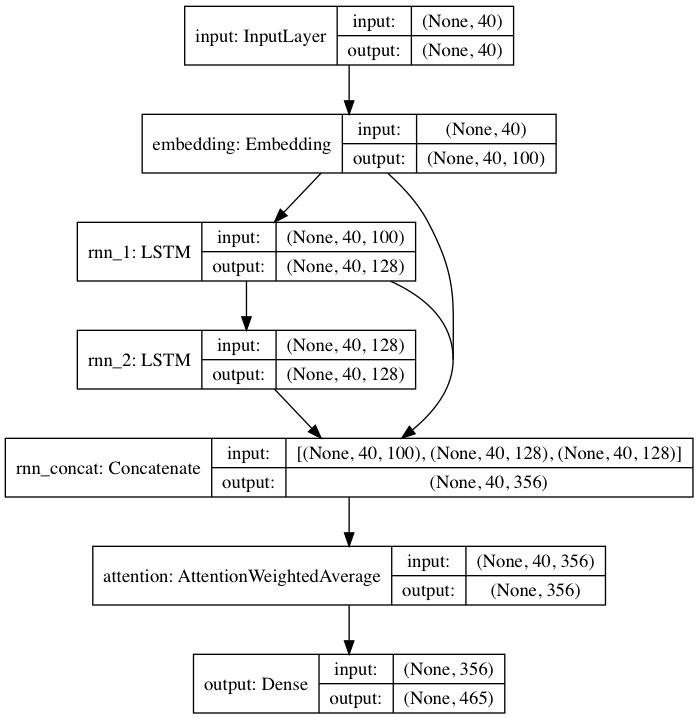
O modelo pré-treinado incluído segue uma arquitetura de rede neural inspirada em DeepMoji. Para o modelo padrão, textgenrnn recebe uma entrada de até 40 caracteres, converte cada caractere em um vetor de incorporação de caracteres de 100-D e os alimenta em uma camada recorrente de memória de longo curto prazo (LSTM) de 128 células. Essas saídas são então alimentadas em outro LSTM de 128 células. Todas as três camadas são então alimentadas em uma camada de Atenção para ponderar os recursos temporais mais importantes e calculá-los juntos (e como os embeddings + 1º LSTM são conectados por salto na camada de atenção, as atualizações do modelo podem retropropagar-se para eles mais facilmente e evitar o desaparecimento gradientes). Essa saída é mapeada para probabilidades de até 394 caracteres diferentes de serem o próximo caractere na sequência, incluindo caracteres maiúsculos, minúsculos, pontuação e emoji. (se treinar um novo modelo em um novo conjunto de dados, todos os parâmetros numéricos acima podem ser configurados)
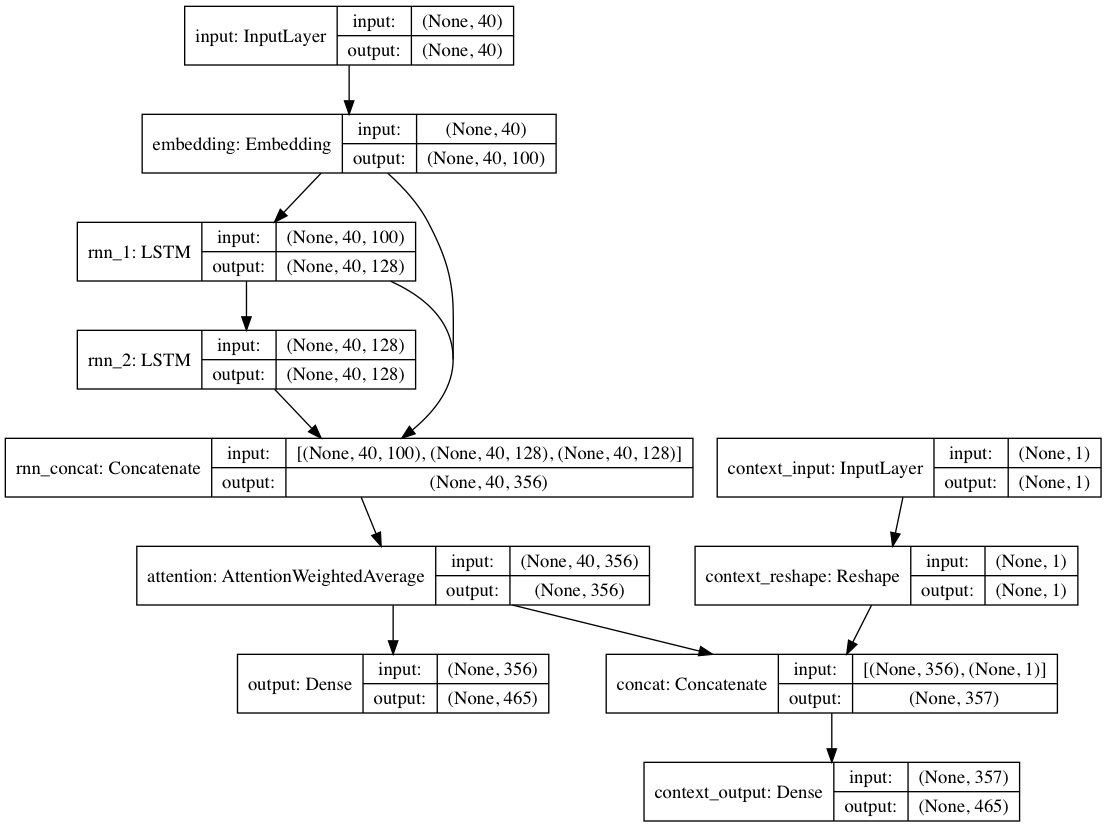
Alternativamente, se rótulos de contexto forem fornecidos com cada documento de texto, o modelo pode ser treinado em modo contextual, onde o modelo aprende o texto dado o contexto para que as camadas recorrentes aprendam a linguagem descontextualizada . O caminho somente texto pode aproveitar as camadas descontextualizadas; ao todo, isso resulta em um treinamento muito mais rápido e em um melhor desempenho do modelo quantitativo e qualitativo do que apenas treinar o modelo apenas com o texto.
Os pesos do modelo incluídos no pacote são treinados em centenas de milhares de documentos de texto enviados pelo Reddit (via BigQuery), de uma variedade muito diversificada de subreddits. A rede também foi treinada usando a abordagem descontextual mencionada acima, a fim de melhorar o desempenho do treinamento e mitigar o preconceito autoral.
Ao ajustar o modelo em um novo conjunto de dados de textos usando textgenrnn, todas as camadas são treinadas novamente. No entanto, como a rede pré-treinada original tem inicialmente um "conhecimento" muito mais robusto, o novo textgenrnn treina mais rápido e com mais precisão no final e pode potencialmente aprender novos relacionamentos não presentes no conjunto de dados original (por exemplo, os embeddings de caracteres pré-treinados incluem o contexto para o personagem para todos os tipos possíveis de gramática moderna da Internet).
Além disso, o retreinamento é feito com um otimizador baseado em momento e uma taxa de aprendizado linearmente decrescente, os quais evitam a explosão de gradientes e tornam muito menos provável que o modelo divirja após o treinamento por um longo tempo.
Você não obterá texto gerado de qualidade 100% das vezes , mesmo com uma rede neural altamente treinada. Essa é a principal razão pela qual postagens virais em blogs/tweets no Twitter que utilizam a geração de texto NN geralmente geram muitos textos e selecionam/editam os melhores posteriormente.
Os resultados variarão muito entre os conjuntos de dados . Como a rede neural pré-treinada é relativamente pequena, ela não pode armazenar tantos dados quanto os RNNs normalmente exibidos em postagens de blog. Para obter melhores resultados, use um conjunto de dados com pelo menos 2.000 a 5.000 documentos. Se um conjunto de dados for menor, você precisará treiná-lo por mais tempo, definindo num_epochs mais alto ao chamar um método de treinamento e/ou treinar um novo modelo do zero. Mesmo assim, atualmente não existe uma boa heurística para determinar um “bom” modelo.
Não é necessária uma GPU para treinar novamente o textgenrnn, mas levará muito mais tempo para treinar em uma CPU. Se você usa uma GPU, recomendo aumentar o parâmetro batch_size para melhor utilização do hardware.
Documentação mais formal
Uma implementação baseada na web usando tensorflow.js (funciona especialmente bem devido ao pequeno tamanho da rede)
Uma forma de visualizar os resultados da camada de atenção para ver como a rede “aprende”.
Um modo para permitir que a arquitetura do modelo seja usada para conversas do chatbot (pode ser lançado como um projeto separado)
Mais profundidade em relação ao contexto (contexto posicional + permitindo vários rótulos de contexto)
Uma rede pré-treinada maior que pode acomodar sequências de caracteres mais longas e uma compreensão mais aprofundada da linguagem, criando frases melhor geradas.
Ativação hierárquica de softmax para modelos em nível de palavra (uma vez que Keras tenha um bom suporte para isso).
FP16 para treinamento super rápido em Volta/TPUs (desde que Keras tenha um bom suporte para isso).
Max Woolf (@minimaxir)
Os projetos de código aberto de Max são apoiados por seu Patreon. Se você achou este projeto útil, quaisquer contribuições monetárias para o Patreon serão apreciadas e serão utilizadas de forma criativa.
Andrej Karpathy pela proposta original do char-rnn por meio da postagem do blog The Unreasonable Effectiveness of Recurrent Neural Networks.
Daniel Grijalva por contribuir com um modo interativo.
MIT
Código da camada de atenção usado pelo DeepMoji (licenciado pelo MIT)


