cherche
2.2.1
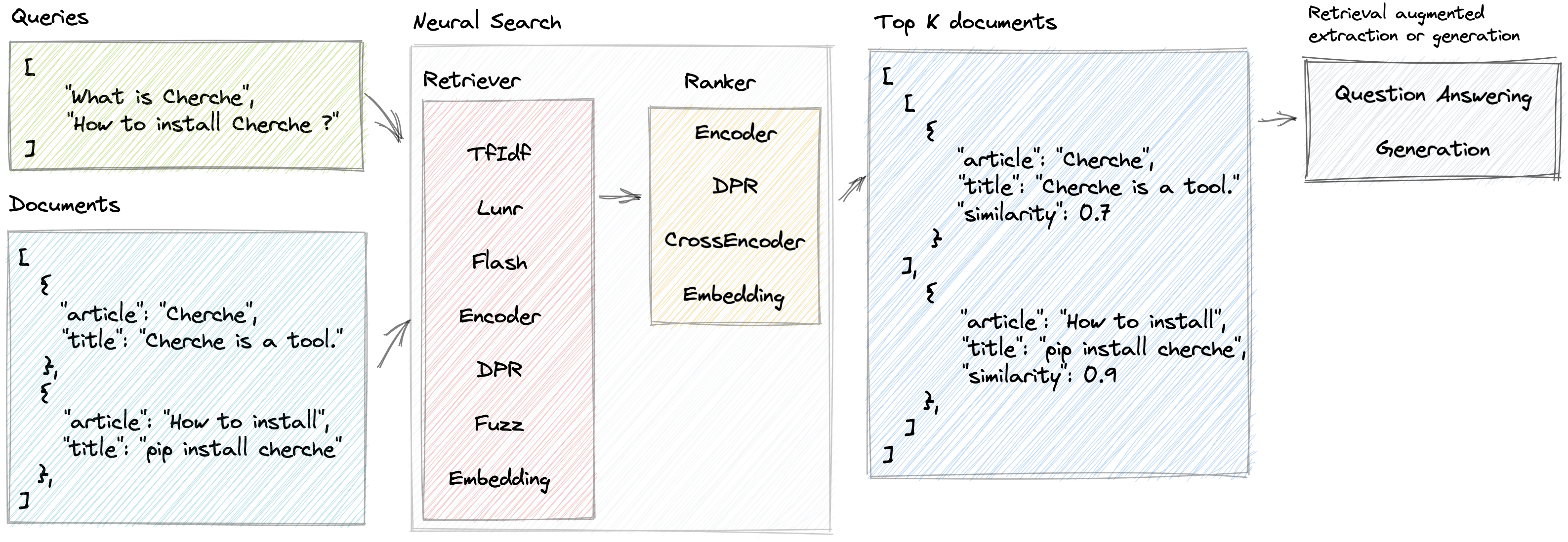
Pesquisa neural

Cherche permite o desenvolvimento de um pipeline de pesquisa neural que emprega recuperadores e modelos de linguagem pré-treinados, tanto como recuperadores quanto como classificadores. A principal vantagem do Cherche reside na sua capacidade de construir gasodutos de ponta a ponta. Além disso, Cherche é adequado para pesquisa semântica offline devido à sua compatibilidade com computação em lote.
Aqui estão alguns dos recursos que Cherche oferece:
Demonstração ao vivo de um mecanismo de pesquisa de PNL desenvolvido por Cherche
Para instalar o Cherche para uso com um recuperador simples na CPU, como TfIdf, Flash, Lunr, Fuzz, use o seguinte comando:
pip install cherchePara instalar o Cherche para uso com qualquer recuperador ou classificador semântico na CPU, use o seguinte comando:
pip install " cherche[cpu] "Finalmente, se você planeja usar qualquer recuperador ou classificador semântico na GPU, use o seguinte comando:
pip install " cherche[gpu] "Seguindo estas instruções de instalação, você poderá usar o Cherche com os requisitos adequados às suas necessidades.
A documentação está disponível aqui. Ele fornece detalhes sobre recuperadores, classificadores, pipelines e exemplos.
Cherche permite encontrar o documento certo em uma lista de objetos. Aqui está um exemplo de corpus.
from cherche import data
documents = data . load_towns ()
documents [: 3 ]
[{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris is the capital and most populous city of France.' },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : "Since the 17th century, Paris has been one of Europe's major centres of science, and arts." },
{ 'id' : 2 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'The City of Paris is the centre and seat of government of the region and province of Île-de-France.'
}]Aqui está um exemplo de pipeline de pesquisa neural composto por um TF-IDF que recupera documentos rapidamente, seguido por um modelo de classificação. O modelo de classificação classifica os documentos produzidos pelo recuperador com base na semelhança semântica entre a consulta e os documentos. Podemos chamar o pipeline usando uma lista de consultas e obter documentos relevantes para cada consulta.
from cherche import data , retrieve , rank
from sentence_transformers import SentenceTransformer
from lenlp import sparse
# List of dicts
documents = data . load_towns ()
# Retrieve on fields title and article
retriever = retrieve . BM25 (
key = "id" ,
on = [ "title" , "article" ],
documents = documents ,
k = 30
)
# Rank on fields title and article
ranker = rank . Encoder (
key = "id" ,
on = [ "title" , "article" ],
encoder = SentenceTransformer ( "sentence-transformers/all-mpnet-base-v2" ). encode ,
k = 3 ,
)
# Pipeline creation
search = retriever + ranker
search . add ( documents = documents )
# Search documents for 3 queries.
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 , 'similarity' : 0.69513524 },
{ 'id' : 63 , 'similarity' : 0.6214994 },
{ 'id' : 65 , 'similarity' : 0.61809087 }],
[{ 'id' : 16 , 'similarity' : 0.59158516 },
{ 'id' : 0 , 'similarity' : 0.58217555 },
{ 'id' : 1 , 'similarity' : 0.57944715 }],
[{ 'id' : 26 , 'similarity' : 0.6925601 },
{ 'id' : 37 , 'similarity' : 0.63977146 },
{ 'id' : 28 , 'similarity' : 0.62772334 }]]Podemos mapear o índice dos documentos para acessar seu conteúdo usando pipelines:
search += documents
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.69513524 },
{ 'id' : 63 ,
'title' : 'Bordeaux' ,
'similarity' : 0.6214994 },
{ 'id' : 65 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.61809087 }],
[{ 'id' : 16 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris received 12.' ,
'similarity' : 0.59158516 },
{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.58217555 },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.57944715 }],
[{ 'id' : 26 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.6925601 },
{ 'id' : 37 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.63977146 },
{ 'id' : 28 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.62772334 }]]Cherche fornece recuperadores que filtram documentos de entrada com base em uma consulta.
Cherche fornece classificadores que filtram documentos na saída de recuperadores.
Os classificadores Cherche são compatíveis com os modelos SentenceTransformers que estão disponíveis no hub Hugging Face.
Cherche oferece módulos dedicados ao atendimento de perguntas. Esses módulos são compatíveis com os modelos pré-treinados do Hugging Face e totalmente integrados aos pipelines de pesquisa neural.
Cherche foi criado para/pela Renault e agora está disponível para todos. Aceitamos todas as contribuições.

Lunr retriever é um wrapper em torno de Lunr.py. Flash retriever é um wrapper em torno do FlashText. Os rankers DPR, Encode e CrossEncoder são wrappers dedicados ao uso dos modelos pré-treinados de SentenceTransformers em um pipeline de pesquisa neural.
Se você usa cherche para produzir resultados para sua publicação científica, consulte nosso artigo SIGIR:
@inproceedings { Sourty2022sigir ,
author = { Raphael Sourty and Jose G. Moreno and Lynda Tamine and Francois-Paul Servant } ,
title = { CHERCHE: A new tool to rapidly implement pipelines in information retrieval } ,
booktitle = { Proceedings of SIGIR 2022 } ,
year = { 2022 }
}A equipe de desenvolvimento do Cherche é composta por Raphaël Sourty, François-Paul Servant, Nicolas Bizzozzero, Jose G Moreno. ?


