cassandra lucene index
2.1.20.0
O Índice Cassandra Lucene do Stratio, derivado do Stratio Cassandra, é um plugin para Apache Cassandra que estende sua funcionalidade de índice para fornecer pesquisa quase em tempo real, como ElasticSearch ou Solr, incluindo recursos de pesquisa de texto completo e pesquisa multivariável, geoespacial e bitemporal gratuita. Isso é alcançado por meio de uma implementação baseada em Apache Lucene de índices secundários Cassandra, onde cada nó do cluster indexa seus próprios dados. Os índices Cassandra da Stratio são um dos módulos principais nos quais a plataforma BigData da Stratio se baseia.
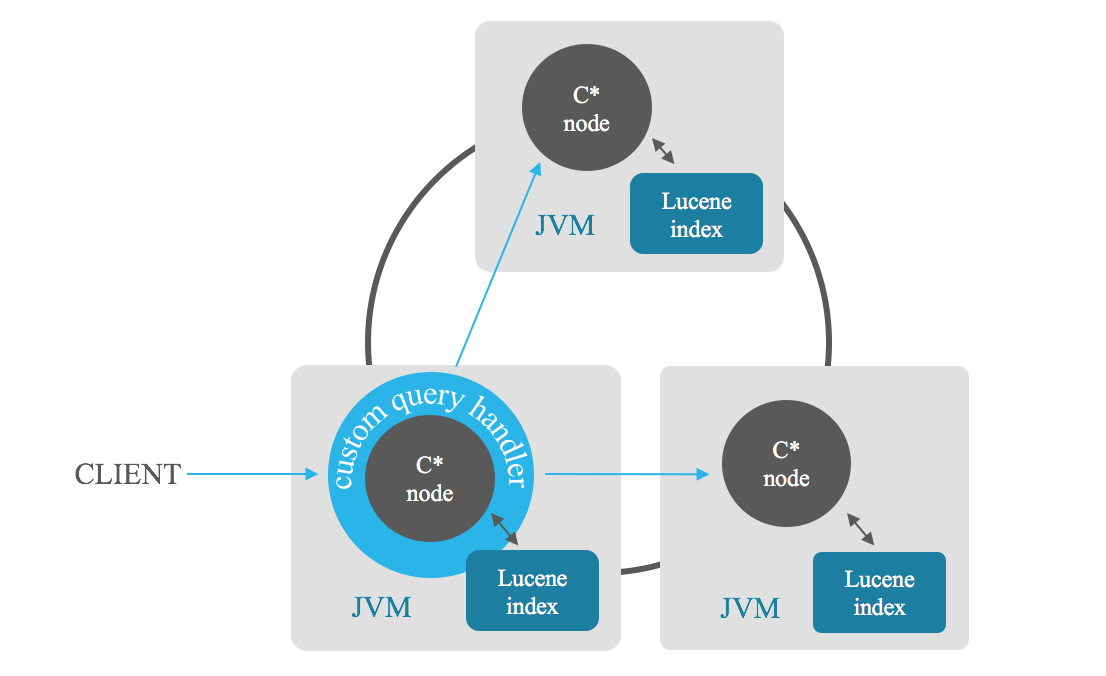
As pesquisas de relevância de índice permitem recuperar os n resultados mais relevantes que satisfazem uma pesquisa. O nó coordenador envia a pesquisa para cada nó do cluster, cada nó retorna seus n melhores resultados e então o coordenador combina esses resultados parciais e fornece os n melhores deles, evitando a varredura completa. Você também pode basear a classificação em uma combinação de campos.
Qualquer célula nas tabelas pode ser indexada, incluindo aquelas na chave primária e também nas coleções. Linhas largas também são suportadas. Você pode verificar intervalos de token/chave, aplicar cláusulas CQL3 adicionais e paginar os resultados filtrados.
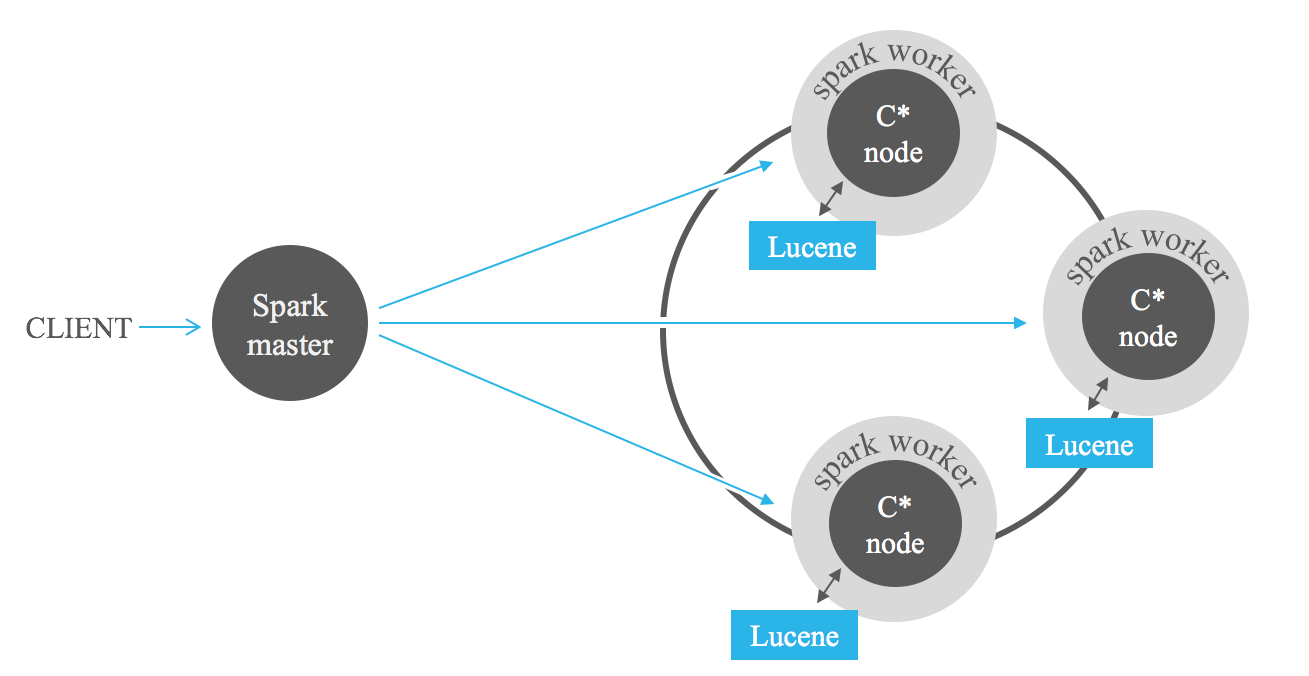
As pesquisas filtradas por índice são uma ajuda poderosa ao analisar os dados armazenados no Cassandra com estruturas MapReduce como Apache Hadoop ou, melhor ainda, Apache Spark. Adicionar filtros Lucene na entrada dos trabalhos pode reduzir drasticamente a quantidade de dados a serem processados, evitando a verificação completa.
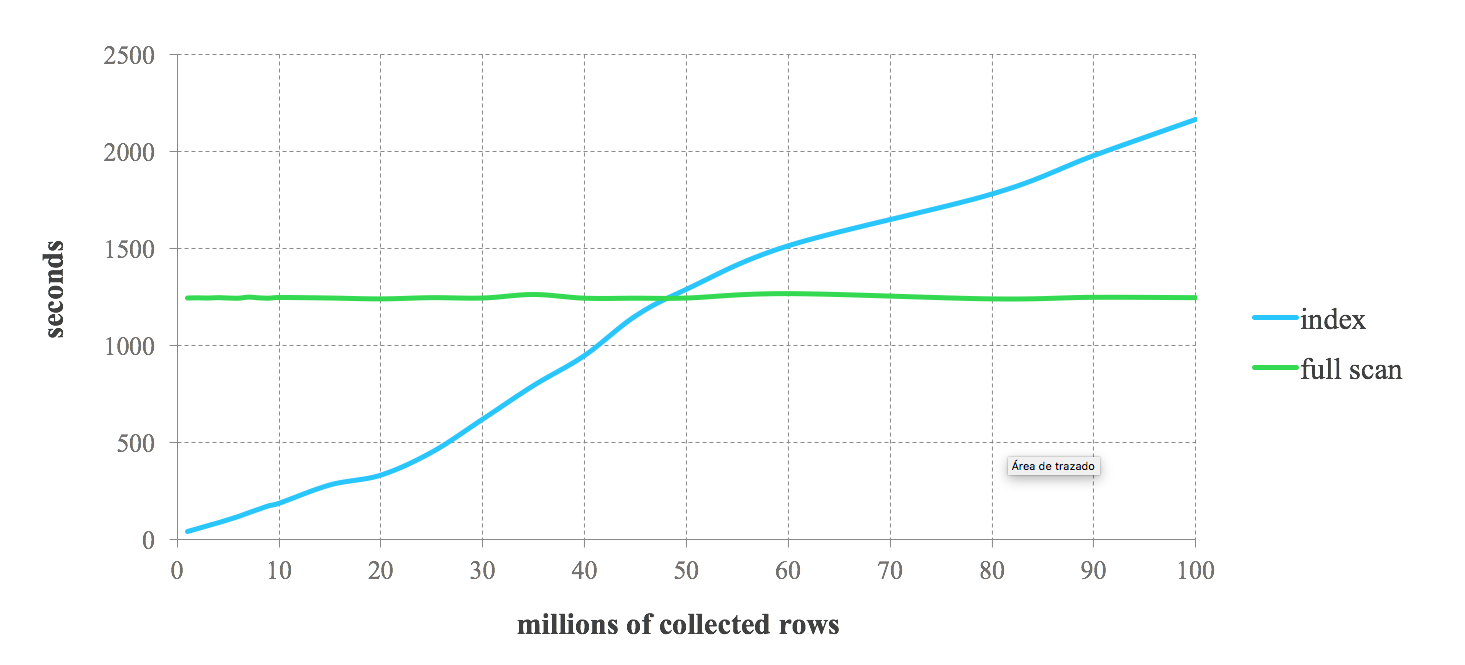
O resultado do benchmark a seguir pode dar uma ideia sobre o desempenho esperado ao combinar índices Lucene com Spark. Fazemos consultas sucessivas solicitando de 1% a 100% dos dados armazenados. Podemos observar um alto desempenho do índice para as consultas que solicitam dados fortemente filtrados. No entanto, o desempenho diminui em consultas menos restritivas. À medida que aumenta o número de registros retornados pela consulta, chegamos a um ponto em que o índice se torna mais lento que a varredura completa. Portanto, a decisão de usar índices em seus trabalhos do Spark depende da seletividade da consulta. A compensação entre ambas as abordagens depende do caso de uso específico. Geralmente, a combinação de índices Lucene com Spark é recomendada para trabalhos que recuperam no máximo 25% dos dados armazenados.
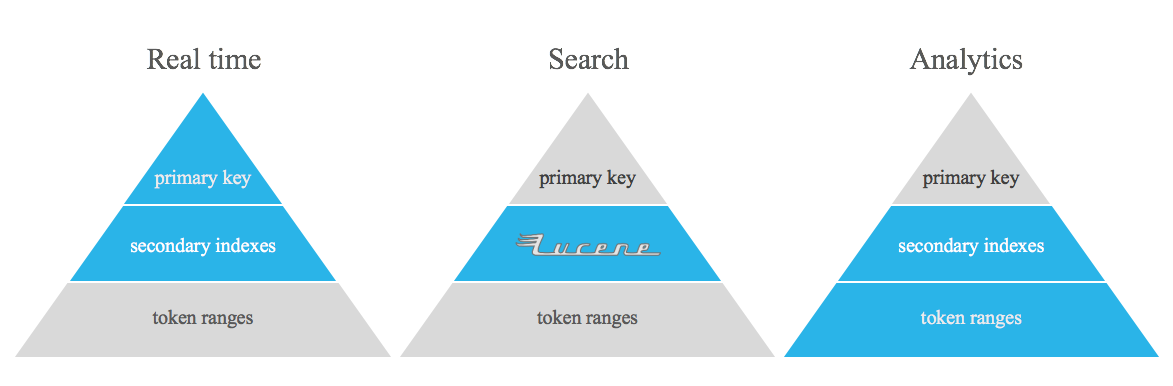
Este projeto não se destina a substituir tabelas desnormalizadas, índices invertidos e/ou índices secundários do Apache Cassandra. É apenas uma ferramenta para realizar algum tipo de consulta que é realmente difícil de ser resolvida usando os recursos prontos para uso do Apache Cassandra, preenchendo a lacuna entre tempo real e análise.
Informações mais detalhadas estão disponíveis na documentação do Índice Cassandra Lucene da Stratio.
A integração da tecnologia de pesquisa Lucene no Cassandra fornece:
O Índice Cassandra Lucene da Stratio e sua integração com a tecnologia de pesquisa Lucene fornecem:
Ainda não suportado:
counter de indexaçãoO Índice Cassandra Lucene da Stratio é distribuído como um plugin para Apache Cassandra. Assim, basta construir um JAR contendo o plugin e adicioná-lo ao classpath do Cassandra:
git clone http://github.com/Stratio/cassandra-lucene-indexcd cassandra-lucene-indexgit checkout ABCXmvn clean packagecp plugin/target/cassandra-lucene-index-plugin-*.jar <CASSANDRA_HOME>/lib/Versões específicas do índice Cassandra Lucene são direcionadas para versões específicas do Apache Cassandra. Portanto, cassandra-lucene-index ABCX destina-se a ser usado com Apache Cassandra ABC, por exemplo, cassandra-lucene-index:3.0.7.1 para cassandra:3.0.7. Observe que os lançamentos prontos para produção são tags de versão (por exemplo, 3.0.6.3), não usam branch-X nem master branchs em produção.
Alternativamente, o patch também pode ser feito com este perfil Maven, especificando o caminho de instalação do Cassandra, esta tarefa também exclui versões JAR anteriores do plugin no diretório CASSANDRA_HOME/lib/:
mvn clean package -Ppatch -Dcassandra_home= < CASSANDRA_HOME >Se você não possui uma versão instalada do Cassandra, há também um perfil alternativo para permitir que o Maven baixe e corrija a versão adequada do Apache Cassandra:
mvn clean package -Pdownload_and_patch -Dcassandra_home= < CASSANDRA_HOME >Agora você pode executar o Cassandra e fazer alguns testes usando a Cassandra Query Language:
< CASSANDRA_HOME > /bin/cassandra -f
< CASSANDRA_HOME > /bin/cqlsh Os arquivos de índice do Lucene serão armazenados nos mesmos diretórios onde estarão os do Cassandra. O diretório de dados padrão é /var/lib/cassandra/data e cada índice é colocado próximo às SSTables de sua família de colunas indexadas.
Lembre-se de que se você usar a pesquisa de formato geográfico, precisará incluir o jar JTS.
Para obter mais detalhes sobre o Apache Cassandra, consulte sua documentação.
Criaremos a seguinte tabela para armazenar tweets:
CREATE KEYSPACE demo
WITH REPLICATION = { ' class ' : ' SimpleStrategy ' , ' replication_factor ' : 1 };
USE demo;
CREATE TABLE tweets (
id INT PRIMARY KEY ,
user TEXT ,
body TEXT ,
time TIMESTAMP ,
latitude FLOAT,
longitude FLOAT
);Agora você pode criar um índice Lucene personalizado com a seguinte instrução:
CREATE CUSTOM INDEX tweets_index ON tweets ()
USING ' com.stratio.cassandra.lucene.Index '
WITH OPTIONS = {
' refresh_seconds ' : ' 1 ' ,
' schema ' : ' {
fields: {
id: {type: "integer"},
user: {type: "string"},
body: {type: "text", analyzer: "english"},
time: {type: "date", pattern: "yyyy/MM/dd"},
place: {type: "geo_point", latitude: "latitude", longitude: "longitude"}
}
} '
}; Isso indexará todas as colunas da tabela com os tipos especificados e será atualizada uma vez por segundo. Como alternativa, você pode atualizar explicitamente todos os fragmentos do índice com uma pesquisa vazia com consistência ALL :
CONSISTENCY ALL
SELECT * FROM tweets WHERE expr(tweets_index, ' {refresh:true} ' );
CONSISTENCY QUORUMAgora, para pesquisar tweets dentro de um determinado intervalo de datas:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"}
} ' );A mesma pesquisa pode ser realizada forçando uma atualização explícita dos fragmentos de índice envolvidos:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
refresh: true
} ' ) limit 100 ;Agora, para pesquisar os 100 tweets mais relevantes onde o campo do corpo contém a frase “big data dá às organizações” dentro do intervalo de datas mencionado acima:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;Para refinar a pesquisa para obter apenas os tweets escritos por usuários cujos nomes começam com "a":
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;Para obter os 100 resultados filtrados mais recentes, você pode usar a opção de classificação :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;A pesquisa anterior pode ser restrita a tweets criados próximos a uma posição geográfica:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;Também é possível ordenar os resultados por distância a uma posição geográfica:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) limit 100 ;Por último, mas não menos importante, você pode rotear qualquer pesquisa para um determinado intervalo de token ou partição, de forma que apenas um subconjunto de nós do cluster seja atingido, economizando recursos preciosos:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) AND TOKEN(id) >= TOKEN( 0 ) AND TOKEN(id) < TOKEN( 10000000 ) limit 100 ;Este último é a base para suporte a Hadoop, Spark e outros frameworks MapReduce.
Por favor, consulte a documentação abrangente do índice Cassandra Lucene da Stratio.


