ustore
v0.13.12
![]()
![]()
![]()
![]()
![]()
![]()
Introdução ao YouTube • Bate-papo no Discord • Documentação completa
Instalar o UStore é muito fácil e o uso é tão simples quanto um Python dict .
$ pip install ukv
$ python
from ukv import umem
db = umem . DataBase ()
db . main [ 42 ] = 'Hi' Acabamos de criar um banco de dados transacional incorporado na memória e adicionamos uma entrada em sua coleção main . Você prefere esses dados no disco? Mude uma linha.
from ukv import rocksdb
db = rocksdb . DataBase ( '/some-folder/' )Você prefere se conectar a um servidor UStore remoto? UStore vem com uma interface Apache Arrow Flight RPC!
from ukv import flight_client
db = flight_client . DataBase ( 'grpc://0.0.0.0:38709' ) Você está armazenando MultiDiGraph do tipo NetworkX? Ou DataFrame semelhante ao Pandas?
db = rocksdb . DataBase ()
users_table = db [ 'users' ]. table
users_table . merge ( pd . DataFrame ([
{ 'id' : 1 , 'name' : 'Lex' , 'lastname' : 'Fridman' },
{ 'id' : 2 , 'name' : 'Joe' , 'lastname' : 'Rogan' },
]))
friends_graph = db [ 'friends' ]. graph
friends_graph . add_edge ( 1 , 2 )
assert friends_graph . has_edge ( 1 , 2 ) and
friends_graph . has_node ( 1 ) and
friends_graph . number_of_edges ( 1 , 2 ) == 1As chamadas de função podem parecer idênticas, mas a implementação subjacente pode abordar centenas de terabytes de dados colocados em algum lugar na memória persistente de uma máquina remota.
Alguém está atualizando simultaneamente essas coleções? Agrupe suas operações para garantir consistência!
db = rocksdb . DataBase ()
with db . transact () as txn :
txn [ 'users' ]. table . merge (...)
txn [ 'friends' ]. graph . add_edge ( 1 , 2 )Até agora cobrimos apenas a ponta do UStore. Você pode usá-lo para...
Mas a UStore pode mais. Aqui está o mapa:
## Uso Básico
O UStore pretende não apenas ser um banco de dados, mas um kit de ferramentas para "construir seu banco de dados" e um padrão aberto para bancos de dados NoSQL potencialmente transacionais, definindo interfaces binárias de cópia zero para operações de "Criar, Ler, Atualizar, Excluir" ou, abreviadamente, CRUD.
Alguns cabeçalhos C99 simples podem vincular quase qualquer mecanismo de armazenamento subjacente a vários drivers de linguagem de alto nível, estendendo seu suporte a valores de strings binárias para gráficos, documentos de esquema flexível e outras modalidades, com o objetivo de substituir MongoDB, Neo4J, Pinecone e ElasticSearch com um único sistema transacional ACID.
Redis, por exemplo, fornece RediSearch, RedisJSON e RedisGraph com objetivos semelhantes. O UStore faz isso melhor, permitindo que você adicione seus Key-Value Stores (KVS) favoritos, incorporados, autônomos ou fragmentados, como FoundationDB, multiplicando sua funcionalidade.
Objetos binários grandes podem ser colocados dentro do UStore. O desempenho variará muito dependendo da tecnologia subjacente usada. O UCSet na memória será o mais rápido, mas o menos adequado para objetos maiores. O UDisk persistente, quando configurado corretamente, pode ignorar totalmente o kernel do Linux, incluindo a camada do sistema de arquivos, endereçando diretamente os dispositivos de bloco.
A E/S persistente moderna em servidores de última geração pode exceder 100 GB/s por soquete quando construída em drivers de espaço do usuário como SPDK. Isso está próximo do rendimento real da RAM de última geração e desbloqueia casos de uso novos e incomuns para bancos de dados. Agora é possível colocar um arquivo de vídeo do tamanho de um Gigabyte em um banco de dados transacional ACID, próximo aos seus metadados, em vez de usar um armazenamento de objetos separado, como o MinIO.
JSON é o formato de documento mais usado atualmente. As coleções de documentos do UStore suportam JSON, bem como MessagePack e BSON, usados pelo MongoDB.

O UStore ainda não é dimensionado horizontalmente, mas oferece desempenho de nó único muito maior e tem escalabilidade vertical quase linear em sistemas com muitos núcleos, graças às bibliotecas simdjson e yyjson de código aberto. Além disso, para interagir com os dados, você não precisa de uma linguagem de consulta personalizada como MQL. Em vez disso, priorizamos padrões RFC abertos para realmente evitar bloqueios de fornecedores:
Os bancos de dados gráficos modernos, como o Neo4J, enfrentam grandes cargas de trabalho. Eles exigem muita RAM e seus algoritmos observam os dados, uma entrada por vez. Otimizamos em ambas as frentes:
Feature Stores e bancos de dados de vetores, como Pinecone, Milvus e USearch, fornecem índices independentes para pesquisa de vetores. O UStore o implementa como uma modalidade separada, no mesmo nível de Documentos e Gráficos. Características:
UStore para Python e para C++ parecem muito diferentes. Nosso Python SDK imita outras bibliotecas Python - Pandas e NetworkX. Da mesma forma, a biblioteca C++ fornece a interface que os desenvolvedores C++ esperam.
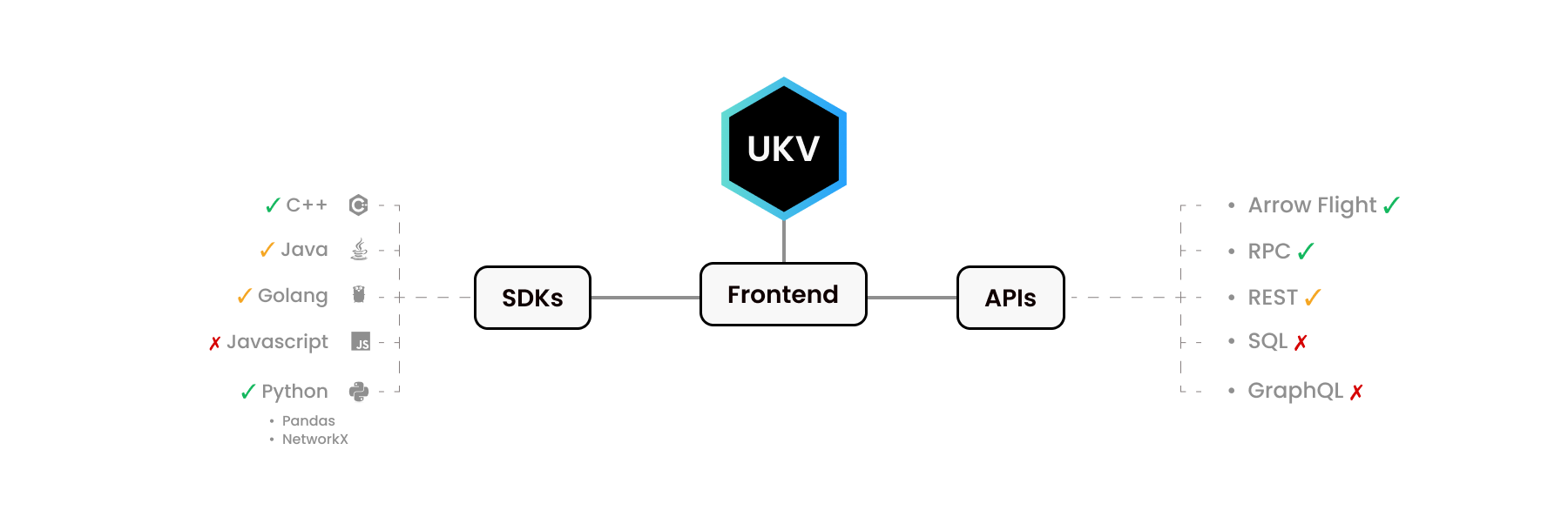
Como sabemos, as pessoas usam línguas diferentes para fins diferentes. Algumas funcionalidades de nível C não estão implementadas em alguns idiomas. Ou porque não houve demanda, ou porque ainda não chegamos lá.
| Nome | Transacionar | Coleções | Lotes | Documentos | Gráficos | Cópias |
|---|---|---|---|---|---|---|
| Padrão C99 | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| SDK C++ | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| SDK Python | ✓ | ✓ | ✓ | ✓ | ✓ | 0-1 |
| SDK GoLang | ✓ | ✓ | ✓ | ✗ | ✗ | 1 |
| SDK Java | ✓ | ✓ | ✗ | ✗ | ✗ | 1 |
| API Arrow Flight | ✓ | ✓ | ✓ | ✓ | ✓ | 0-2 |
Alguns frontends aqui possuem ecossistemas inteiros ao seu redor! A API Apache Arrow Flight, por exemplo, possui seus próprios drivers para C, C++, C#, Go, Java, JavaScript, Julia, MATLAB, Python, R, Ruby e Rust.
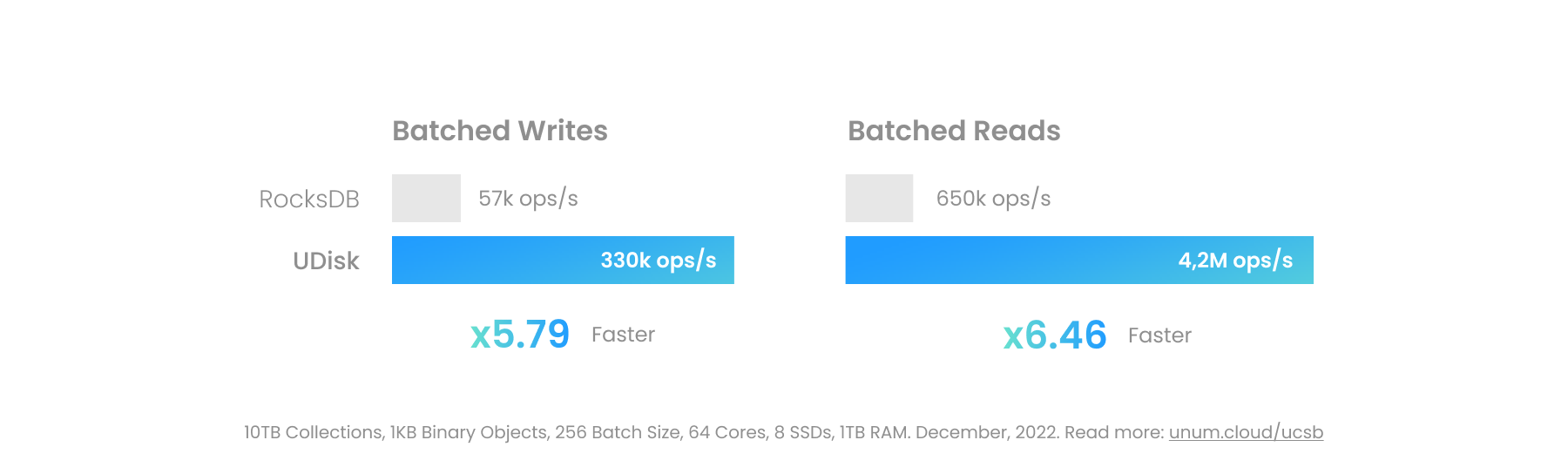
Os seguintes motores podem ser usados quase de forma intercambiável. Historicamente, LevelDB foi o primeiro. O RocksDB então melhorou a funcionalidade e o desempenho. Agora serve de base para metade das startups de DBMS.
| NívelDB | RochasDB | UDisk | UCSet | |
|---|---|---|---|---|
| Velocidade | 1x | 2x | 10x | 30x |
| Persistente | ✓ | ✓ | ✓ | ✗ |
| Transacional | ✗ | ✓ | ✓ | ✓ |
| Bloquear suporte a dispositivos | ✗ | ✗ | ✓ | ✗ |
| Criptografia | ✗ | ✗ | ✓ | ✗ |
| Relógios | ✗ | ✓ | ✓ | ✓ |
| Instantâneos | ✓ | ✓ | ✓ | ✗ |
| Amostragem Aleatória | ✗ | ✗ | ✓ | ✓ |
| Enumeração em massa | ✗ | ✗ | ✓ | ✓ |
| Coleções nomeadas | ✗ | ✓ | ✓ | ✓ |
| Código aberto | ✓ | ✓ | ✗ | ✓ |
| Compatibilidade | Qualquer | Qualquer | Linux | Qualquer |
| Mantenedor | Unum | Unum |
UCSet e UDisk são projetados e mantidos pela Unum. Ambos possuem recursos completos, mas o recurso mais importante que nossas alternativas oferecem é o desempenho. Ser rápido na memória é fácil. A lógica central do UCSet pode ser encontrada na biblioteca ucset modelo apenas de cabeçalho.
Projetar o UDisk foi um empreendimento muito mais desafiador de 7 anos. Incluía a invenção de novas estruturas semelhantes a árvores, a implementação de desvio parcial do kernel com io_uring , desvio completo com SPDK , aceleração de GPU CUDA e até mesmo um sistema de arquivos interno personalizado. UDisk é o primeiro mecanismo a ser projetado do zero com arquiteturas paralelas e desvio de kernel em mente .
A atomicidade é sempre garantida. Mesmo em gravações não transacionais - todas as atualizações são aprovadas ou todas falham.
A consistência é implementada da forma mais estrita possível - "Serialização Estrita", o que significa que:
O comportamento padrão, entretanto, pode ser ajustado no nível de operações específicas. Para isso ::ustore_option_transaction_dont_watch_k pode ser passado para ustore_transaction_init() ou qualquer operação transacional de leitura/gravação, para controlar as verificações de consistência durante o teste.
| Lê | Escreve | |
|---|---|---|
| Cabeça | Série estrita | Série estrita |
| Transações em instantâneos | Serial | Série estrita |
| Transações sem instantâneos | Série estrita | Série estrita |
| Transações sem relógios | Série estrita | Sequencial |
Se este tópico for novo para você, confira o blog Jepsen.io sobre consistência.
| Lê | Escreve | |
|---|---|---|
| Transações em instantâneos | ✓ | ✓ |
| Transações sem instantâneos | ✗ | ✓ |
A durabilidade não se aplica a sistemas na memória por definição. Em sistemas híbridos ou persistentes preferimos desativá-lo por padrão. Quase todo SGBD baseado em KVS prefere implementar seu próprio mecanismo de durabilidade. Ainda mais em bancos de dados distribuídos, onde podem existir três logs Write Ahead separados:
Se você ainda precisa de durabilidade, flush escreve em commits com um sinalizador opcional. No driver C você chamaria ustore_transaction_commit() com o sinalizador ::ustore_option_write_flush_k .
Todo o DBMS cabe em uma imagem Docker com menos de 100 MB. Execute o script a seguir para extrair e executar o contêiner, expondo o servidor Apache Arrow Flight na porta 38709 . Os SDKs do cliente também se comunicarão por meio da mesma porta, por padrão.
docker run -d --rm --name ustore-test -p 38709:38709 unum/ustoreO arquivo de configuração padrão pode ser recuperado com:
cat /var/lib/ustore/config.jsonA maneira mais simples de conectar e testar seria o seguinte comando:
python ...Imagens pré-embaladas do UStore estão disponíveis em várias plataformas:
Não hesite em comercializar e redistribuir o UStore.
Ajustar bancos de dados é tanto arte quanto ciência. Projetos como o RocksDB fornecem dezenas de botões para otimizar o comportamento. Permitimos o encaminhamento de arquivos de configuração especializados para o mecanismo subjacente.
{
"version" : " 1.0 " ,
"directory" : " ./tmp/ "
}Temos também um procedimento mais simples, que seria suficiente para 80% dos usuários. Isso pode ser estendido para utilizar vários dispositivos ou diretórios, ou para encaminhar uma configuração de mecanismo especializada.
{
"version" : " 1.0 " ,
"directory" : " /var/lib/ustore " ,
"data_directories" : [
{
"path" : " /dev/nvme0p0/ " ,
"max_size" : " 100GB "
},
{
"path" : " /dev/nvme1p0/ " ,
"max_size" : " 100GB "
}
],
"engine" : {
"config_file_path" : " ./engine_rocksdb.ini " ,
}
}As coleções de bancos de dados também podem ser configuradas com arquivos JSON.
A partir da versão atual, são usados inteiros assinados de 64 bits. Ele permite chaves exclusivas no intervalo de [0, 2^63) . Compilações de 128 bits com UUIDs estão chegando, mas chaves de comprimento variável são altamente desencorajadas. Por que isso?
O uso de chaves de comprimento variável impõe inúmeras limitações no design de um armazenamento de valores-chave. Em primeiro lugar, implica comparações lentas em termos de caracteres - um assassino de desempenho em CPUs hiperescalares modernas. Em segundo lugar, força a união de chaves e valores em um disco para minimizar os metadados necessários para navegação. Por último, viola a nossa visão lógica simples do KVS como um "alocador de memória persistente", colocando muito mais responsabilidade nele.
A abordagem recomendada para lidar com chaves de string é:
Isso resultará em um único ponto de conversão de representações de string para inteiro e manterá a maior parte do sistema ágil e as interfaces de nível C mais simples do que poderiam ser.
Só podemos abordar valores de 4 GB ou menores no momento. Por que? Os armazenamentos de valores-chave geralmente são destinados a operações de alta frequência. Freqüentemente (milhares de vezes por segundo), acessar e modificar arquivos de 4 GB ou maiores é impossível em hardware moderno. Portanto, optamos por tipos de comprimento menor, tornando o uso da representação Apache Arrow um pouco mais fácil e permitindo que o KVS comprima melhor os índices.
Nosso roteiro de desenvolvimento é público e está hospedado no repositório GitHub. As próximas tarefas incluem:
Leia o roteiro completo em nossos documentos aqui.


