uFuzzy
1.0.17
Uma pesquisa difusa minúscula e eficiente que não é uma droga. Este é o meu confuso? Existem muitos iguais, mas este é meu.¹
uFuzzy é uma biblioteca de pesquisa difusa projetada para combinar uma frase de pesquisa relativamente curta (agulha) com uma grande lista de frases curtas a médias (palheiro). Pode ser melhor descrito como um String.includes() mais indulgente. Os aplicativos comuns incluem filtragem de lista, preenchimento/sugestão automática e pesquisas por títulos, nomes, descrições, nomes de arquivos e funções.
No modo MultiInsert padrão do uFuzzy, cada correspondência deve conter todos os caracteres alfanuméricos da agulha na mesma sequência; no modo SingleError , erros de digitação únicos são tolerados em cada termo (distância Damerau – Levenshtein = 1). Sua API .search() pode combinar com eficiência termos fora de ordem, suporta múltiplas exclusões de substring (por exemplo, fruit -green -melon ) e termos exatos com caracteres não alfanuméricos (por exemplo, "C++" , "$100" , "#hashtag" ). Quando mantido corretamente , ele também pode corresponder com eficiência a várias propriedades de objetos.
Array.sort() que obtém acesso às estatísticas/contadores de cada partida. Não há nenhuma "pontuação" composta de caixa preta para entender.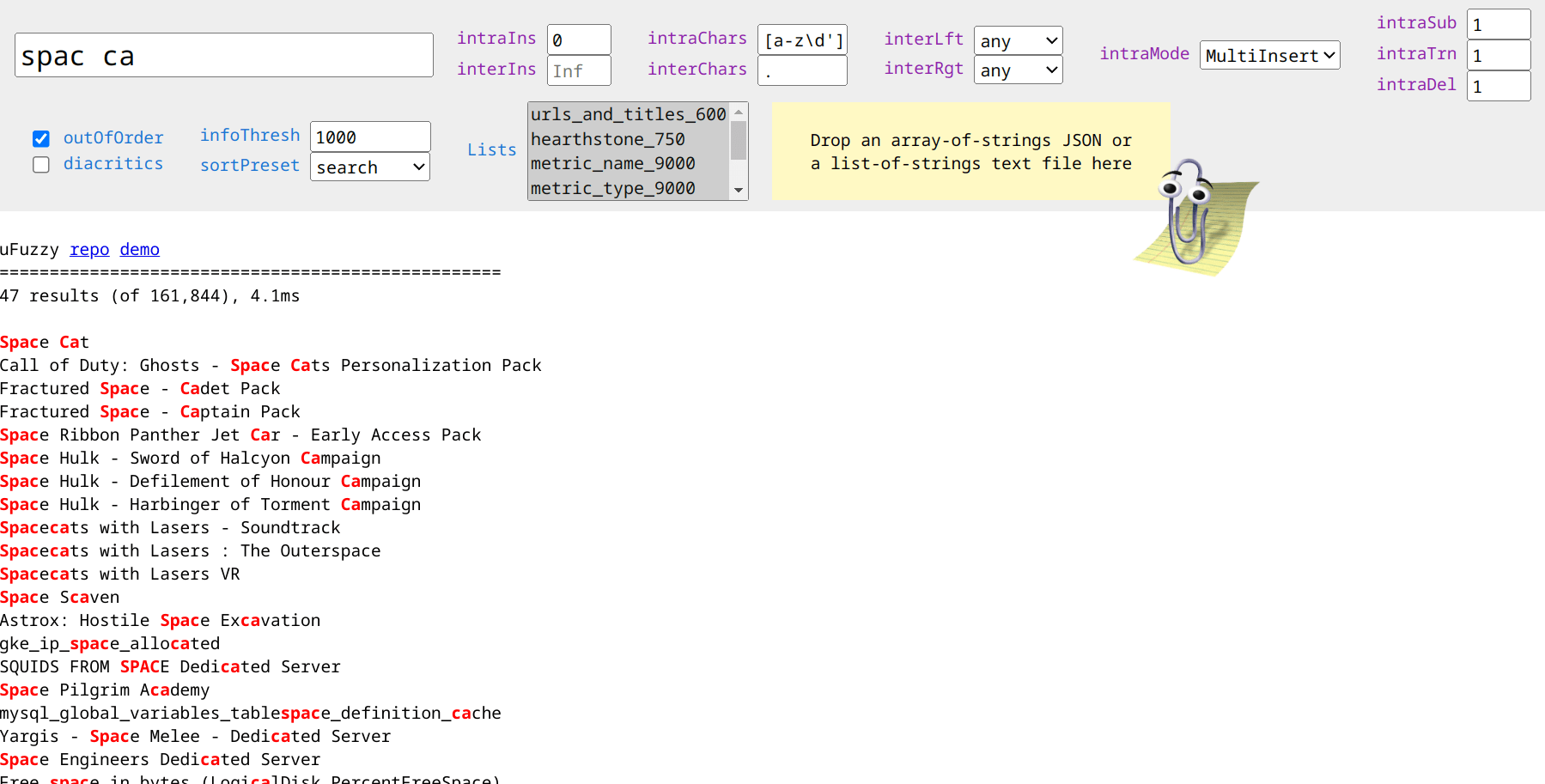
uFuzzy é otimizado para o alfabeto latino/romano e depende internamente de expressões regulares não Unicode.
O suporte para mais idiomas funciona aumentando os regexps latinos integrados com caracteres adicionais ou usando a variante {unicode: true} universal e mais lenta. Uma alternativa {alpha: "..."} mais simples, mas menos flexível, substitui as partes AZ e az das expressões regulares latinas integradas por caracteres de sua escolha (a caixa das letras será correspondida automaticamente durante a substituição).
A função utilitária uFuzzy.latinize() pode ser usada para retirar acentos/diacríticos comuns do palheiro e da agulha antes da pesquisa.
// Latin (default)
let opts = { alpha : "a-z" } ;
// OR
let opts = {
// case-sensitive regexps
interSplit : "[^A-Za-z\d']+" ,
intraSplit : "[a-z][A-Z]" ,
intraBound : "[A-Za-z]\d|\d[A-Za-z]|[a-z][A-Z]" ,
// case-insensitive regexps
intraChars : "[a-z\d']" ,
intraContr : "'[a-z]{1,2}\b" ,
} ;
// Latin + Norwegian
let opts = { alpha : "a-zæøå" } ;
// OR
let opts = {
interSplit : "[^A-Za-zæøåÆØÅ\d']+" ,
intraSplit : "[a-zæøå][A-ZÆØÅ]" ,
intraBound : "[A-Za-zæøåÆØÅ]\d|\d[A-Za-zæøåÆØÅ]|[a-zæøå][A-ZÆØÅ]" ,
intraChars : "[a-zæøå\d']" ,
intraContr : "'[a-zæøå]{1,2}\b" ,
} ;
// Latin + Russian
let opts = { alpha : "a-zа-яё" } ;
// OR
let opts = {
interSplit : "[^A-Za-zА-ЯЁа-яё\d']+" ,
intraSplit : "[a-z][A-Z]|[а-яё][А-ЯЁ]" ,
intraBound : "[A-Za-zА-ЯЁа-яё]\d|\d[A-Za-zА-ЯЁа-яё]|[a-z][A-Z]|[а-яё][А-ЯЁ]" ,
intraChars : "[a-zа-яё\d']" ,
intraContr : "'[a-z]{1,2}\b" ,
} ;
// Unicode / universal (50%-75% slower)
let opts = {
unicode : true ,
interSplit : "[^\p{L}\d']+" ,
intraSplit : "\p{Ll}\p{Lu}" ,
intraBound : "\p{L}\d|\d\p{L}|\p{Ll}\p{Lu}" ,
intraChars : "[\p{L}\d']" ,
intraContr : "'\p{L}{1,2}\b" ,
} ;Todas as pesquisas atualmente não diferenciam maiúsculas de minúsculas; não é possível fazer uma pesquisa com distinção entre maiúsculas e minúsculas.
NOTA: O arquivo testdata.json é um conjunto de dados diversificado de 162.000 strings/frases com 4 MB de tamanho, portanto, o primeiro carregamento pode ser lento devido à transferência de rede. Tente atualizar depois de armazenado em cache pelo seu navegador.
Primeiro, o uFuzzy isoladamente para demonstrar seu desempenho.
https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy&search=super%20ma
Agora a mesma página de comparação, inicializada com fuzzysort, QuickScore e Fuse.js:
https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy,fuzzysort,QuickScore,Fuse&search=super%20ma
Aqui está a lista completa da biblioteca, mas com um conjunto de dados reduzido (apenas hearthstone_750 , urls_and_titles_600 ) para evitar travar seu navegador:
https://leeoniya.github.io/uFuzzy/demos/compare.html?lists=hearthstone_750,urls_and_titles_600&search=moo
Respostas:
Mais: https://github.com/leeoniya/uFuzzy/issues
npm i @leeoniya/ufuzzy
const uFuzzy = require ( '@leeoniya/ufuzzy' ) ; < script src = "./dist/uFuzzy.iife.min.js" > < / script > let haystack = [
'puzzle' ,
'Super Awesome Thing (now with stuff!)' ,
'FileName.js' ,
'/feeding/the/catPic.jpg' ,
] ;
let needle = 'feed cat' ;
let opts = { } ;
let uf = new uFuzzy ( opts ) ;
// pre-filter
let idxs = uf . filter ( haystack , needle ) ;
// idxs can be null when the needle is non-searchable (has no alpha-numeric chars)
if ( idxs != null && idxs . length > 0 ) {
// sort/rank only when <= 1,000 items
let infoThresh = 1e3 ;
if ( idxs . length <= infoThresh ) {
let info = uf . info ( idxs , haystack , needle ) ;
// order is a double-indirection array (a re-order of the passed-in idxs)
// this allows corresponding info to be grabbed directly by idx, if needed
let order = uf . sort ( info , haystack , needle ) ;
// render post-filtered & ordered matches
for ( let i = 0 ; i < order . length ; i ++ ) {
// using info.idx here instead of idxs because uf.info() may have
// further reduced the initial idxs based on prefix/suffix rules
console . log ( haystack [ info . idx [ order [ i ] ] ] ) ;
}
}
else {
// render pre-filtered but unordered matches
for ( let i = 0 ; i < idxs . length ; i ++ ) {
console . log ( haystack [ idxs [ i ] ] ) ;
}
}
} uFuzzy fornece um uf.search(haystack, needle, outOfOrder = 0, infoThresh = 1e3) => [idxs, info, order] que combina as etapas filter , info , sort acima. Este método também implementa uma lógica eficiente para combinar termos de pesquisa fora de ordem e suporte para múltiplas exclusões de substrings, por exemplo, fruit -green -melon .
Obtenha suas correspondências ordenadas primeiro:
let haystack = [
'foo' ,
'bar' ,
'cowbaz' ,
] ;
let needle = 'ba' ;
let u = new uFuzzy ( ) ;
let idxs = u . filter ( haystack , needle ) ;
let info = u . info ( idxs , haystack , needle ) ;
let order = u . sort ( info , haystack , needle ) ; Marcador innerHTML básico (intervalos agrupados <mark> ):
let innerHTML = '' ;
for ( let i = 0 ; i < order . length ; i ++ ) {
let infoIdx = order [ i ] ;
innerHTML += uFuzzy . highlight (
haystack [ info . idx [ infoIdx ] ] ,
info . ranges [ infoIdx ] ,
) + '<br>' ;
}
console . log ( innerHTML ) ; Marcador innerHTML com função de marcação personalizada (intervalos agrupados <b> ):
let innerHTML = '' ;
const mark = ( part , matched ) => matched ? '<b>' + part + '</b>' : part ;
for ( let i = 0 ; i < order . length ; i ++ ) {
let infoIdx = order [ i ] ;
innerHTML += uFuzzy . highlight (
haystack [ info . idx [ infoIdx ] ] ,
info . ranges [ infoIdx ] ,
mark ,
) + '<br>' ;
}
console . log ( innerHTML ) ;Marcador de elemento DOM/JSX com marcação personalizada e funções de acréscimo:
let domElems = [ ] ;
const mark = ( part , matched ) => {
let el = matched ? document . createElement ( 'mark' ) : document . createElement ( 'span' ) ;
el . textContent = part ;
return el ;
} ;
const append = ( accum , part ) => { accum . push ( part ) ; } ;
for ( let i = 0 ; i < order . length ; i ++ ) {
let infoIdx = order [ i ] ;
let matchEl = document . createElement ( 'div' ) ;
let parts = uFuzzy . highlight (
haystack [ info . idx [ infoIdx ] ] ,
info . ranges [ infoIdx ] ,
mark ,
[ ] ,
append ,
) ;
matchEl . append ( ... parts ) ;
domElems . push ( matchEl ) ;
}
document . getElementById ( 'matches' ) . append ( ... domElems ) ;uFuzzy possui dois modos operacionais que diferem na estratégia de correspondência:
example - exatoexamplle - inserção única (adição)exemple - substituição única (substituição)exmaple - transposição única (swap)exmple - exclusão única (omissão)xamp - parcialxmap - parcial com transposiçãoExistem 3 fases em uma pesquisa:
haystack com um RegExp rápido compilado a partir de sua needle sem realizar nenhuma operação extra. Ele retorna uma matriz de índices correspondentes na ordem original.needle em dois RegExps mais caros que podem particionar cada partida. Portanto, deve ser executado em um subconjunto reduzido do palheiro, geralmente retornado pela fase Filtro. A demonstração do uFuzzy é limitada a <= 1.000 itens filtrados, antes de prosseguir com esta fase.Array.sort() para determinar a ordem do resultado final, utilizando o objeto info retornado da fase anterior. Uma função de classificação personalizada pode ser fornecida por meio de uma opção uFuzzy: {sort: (info, haystack, needle) => idxsOrder} .Um arquivo uFuzzy.d.ts de 200 LoC generosamente comentado.
As opções com prefixo inter aplicam-se a licenças entre termos de pesquisa, enquanto aquelas com prefixo intra aplicam-se a licenças dentro de cada termo de pesquisa.
| Opção | Descrição | Padrão | Exemplos |
|---|---|---|---|
intraMode | Como a correspondência de termos deve ser realizada | 0 | 0 MultiInserção1 erro únicoVeja como funciona |
intraIns | Número máximo de caracteres extras permitidos entre cada caractere dentro de um termo | Corresponde ao valor de intraMode ( 0 ou 1 ) | Procurando por "gato"...0 pode corresponder a: cat , s cat , cat ch, va cat e1 também corresponde a : carrinho , capítulo , excluído |
interIns | Número máximo de caracteres extras permitidos entre os termos | Infinity | Procurando "onde está"...Infinity pode corresponder: onde está , onde tem blá w é dom5 não pode corresponder: onde está a sabedoria blá |
intraSubintraTrnintraDel | Para intraMode: 1 apenas,Tipos de erros a serem tolerados dentro dos termos | Corresponde ao valor de intraMode ( 0 ou 1 ) | 0 Não1 Sim |
intraChars | Regexp parcial para inserção permitida caracteres entre cada caractere dentro de um termo | [azd'] | [azd] corresponde apenas a caracteres alfanuméricos (sem distinção entre maiúsculas e minúsculas)[w-] corresponderia a alfanumérico, sublinhado e hífen |
intraFilt | Retorno de chamada para exclusão de resultados com base no termo e correspondência | (term, match, index) => true | Faça o que quiser, talvez... - Limite de diferença de comprimento - Distância de Levenshtein - Compensação de prazo ou conteúdo |
interChars | Regexp parcial para caracteres permitidos entre termos | . | . corresponde a todos os caracteres[^azd] corresponderia apenas a espaços em branco e pontuação |
interLft | Determina o limite esquerdo do termo permitido | 0 | Procurando por "mania"...0 qualquer - em qualquer lugar: rom mania n1 solto - espaço em branco, pontuação, alfa-num, transições de mudança de caso: Track Mania , mania c2 estrito - espaço em branco, pontuação: mania cally |
interRgt | Determina o limite direito do termo permitido | 0 | Procurando por "mania"...0 qualquer - em qualquer lugar: rom mania n1 solto - espaço em branco, pontuação, alfa-num, transições de mudança de caixa: Mania Star2 estrito - espaço em branco, pontuação: mania _foo |
sort | Função de classificação de resultados personalizada | (info, haystack, needle) => idxsOrder | Padrão: classificação de pesquisa, prioriza correspondências completas e densidade de caracteres Demonstração: classificação digitada antecipadamente, prioriza deslocamento inicial e duração da correspondência |
Esta avaliação é extremamente restrita e, claro, tendenciosa para meus casos de uso, corpus de texto e minha experiência completa na operação de minha própria biblioteca. É altamente provável que eu não esteja aproveitando ao máximo algum recurso de outras bibliotecas que pode melhorar significativamente os resultados em algum eixo; Congratulo-me com PRs de melhoria de qualquer pessoa com conhecimento de biblioteca mais profundo do que o proporcionado pela minha rápida leitura de 10 minutos sobre qualquer exemplo de "Uso básico" e documento README.
Lata de minhocas #1.
Antes de discutirmos o desempenho, vamos falar sobre a qualidade da pesquisa, porque a velocidade é irrelevante quando seus resultados são uma estranha mistura de "Ah, sim!" e "WTF?".
A qualidade da pesquisa é muito subjetiva. O que constitui uma boa correspondência superior em um caso de "digitação antecipada/sugestão automática" pode ser uma correspondência ruim em um cenário de "pesquisa/localização de tudo". Algumas soluções otimizam para o último, outras para o primeiro. É comum encontrar botões que distorcem os resultados em qualquer direção, mas muitas vezes são instintivos e imperfeitos, sendo pouco mais do que um substituto para a produção de uma "pontuação" de correspondência única e composta.
ATUALIZAÇÃO (2024): A crítica abaixo sobre correspondências bizarras só é verdadeira para a configuração padrão do Fuse.js. Contra-intuitivamente, definir ignoreFieldNorm: true melhorou consideravelmente os resultados, mas a ordem das correspondências de alta qualidade continua péssima.
Vamos dar uma olhada em algumas correspondências produzidas pela biblioteca de pesquisa difusa mais popular, Fuse.js, e algumas outras para as quais o realce de correspondência é implementado na demonstração.
Procurando pelo termo parcial "twili" , vemos estes resultados aparecendo acima de vários resultados óbvios de "crepúsculo" :
https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy,fuzzysort,QuickScore,Fuse&search=twili
Essas correspondências ruins não são apenas isoladas, mas na verdade têm classificação superior às substrings literais.
Terminando o termo de pesquisa com "crepúsculo" , ainda obtém resultados bizarros mais altos:
https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy,fuzzysort,QuickScore,Fuse&search=twilight
Alguns motores funcionam melhor com correspondências parciais de prefixos, às custas de maiores custos de inicialização/indexação:
https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy,FlexSearch,match-sorter,MiniSearch&search=twili
Aqui, match-sorter retorna 1.384 resultados, mas apenas os primeiros 40 são relevantes. Como sabemos onde está o corte?
Lata de minhocas #2.
Todos os benchmarks são ruins, mas este pode ser mais ruim do que outros.
Ainda assim, algo é melhor do que uma demissão YMMV/faça você mesmo e certamente melhor do que nada.
Ambiente
| Data | 2023-10 |
|---|---|
| Hardware | Processador: Ryzen 7 PRO 5850U (1,9 GHz, 7 nm, 15 W TDP) RAM: 48 GB SSD: Samsung SSD 980 PRO 1 TB (NVMe) |
| SO | Endeavour OS (Arch Linux) v6.5.4-arch2-1x86_64 |
| Cromo | v117.0.5938.132 |
libs para o nome da biblioteca desejada: https://leeoniya.github.io/uFuzzy/demos/compare.html?bench&libs=uFuzzybench para evitar benchmarking do DOM.test , chest , super ma , mania , puzz , prom rem stor , twil . Para avaliar os resultados de cada biblioteca, ou comparar várias, basta visitar a mesma página com mais libs e sem bench : https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy,fuzzysort,QuickScore ,Fusível e pesquisa = super% 20ma.
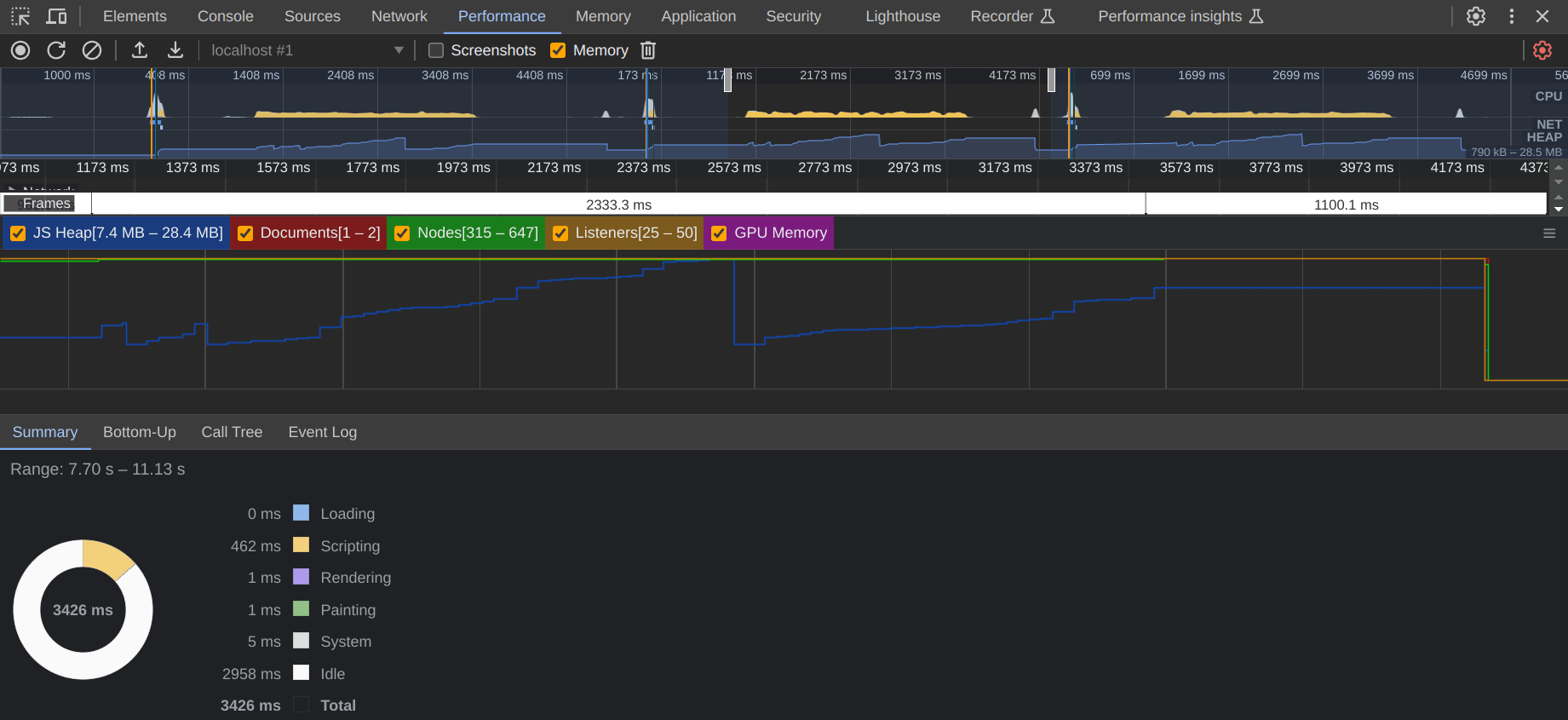
Existem várias métricas avaliadas:
| Biblioteca | Estrelas | Tamanho (min) | Iniciar | Procurar (x 86) | Pilha (pico) | Retido | CG |
|---|---|---|---|---|---|---|---|
| uFuzzy (tente) | ★ 2,3k | 7,6 KB | 0,5ms | 434ms | 28,4 MB | 7,4 MB | 18ms |
| uFuzzy (tente) (cache de prefixo externo) | 210ms | 27,8 MB | 7,4 MB | 18ms | |||
| uFuzzy (tente) (fora de ordem, mais confuso) | 545ms | 29,5 MB | 7,4 MB | 18ms | |||
| uFuzzy (tente) (outOfOrder, mais confuso, SingleError) | 508ms | 30,0 MB | 7,4 MB | 18ms | |||
| ------- | |||||||
| Fuse.js (tente) | ★ 16,6k | 24,2 KB | 31ms | 33875ms | 245 MB | 13,9 MB | 25ms |
| FlexSearch (leve) (tente) | ★ 10,7 mil | 6,2 KB | 3210ms | 83ms | 670MB | 316 MB | 553ms |
| Lunr.js (tente) | ★ 8,7k | 29,4 KB | 1704ms | 996ms | 380 MB | 123 MB | 166ms |
| Orama (anteriormente Lyra) (tente) | ★ 6,4k | 41,5 KB | 2650ms | 225ms | 313 MB | 192 MB | 180ms |
| MiniSearch (tente) | ★ 3,4 mil | 29,1 KB | 504ms | 1453ms | 438 MB | 67 MB | 105ms |
| classificador de correspondência (tentar) | ★ 3,4 mil | 7,3 KB | 0,1ms | 6245 ms | 71MB | 7,3 MB | 12ms |
| fuzzysort (tente) | ★ 3,4k | 6,2 KB | 50ms | 1321ms | 175 MB | 84 MB | 63ms |
| Wade (tente) | ★ 3k | 4 KB | 781ms | 194ms | 438 MB | 42MB | 130ms |
| pesquisa difusa (tente) | ★ 2,7 mil | 0,2 KB | 0,1ms | 529ms | 26,2 MB | 7,3 MB | 18ms |
| pesquisa js (tente) | ★ 2,1k | 17,1 KB | 5620ms | 1190ms | 1740MB | 734MB | 2600ms |
| Elasticlunr.js (tente) | ★ 2k | 18,1 KB | 933ms | 1330ms | 196 MB | 70 MB | 135ms |
| Fuzzyset (tentar) | ★ 1,4k | 2,8 KB | 2962ms | 606ms | 654 MB | 238 MB | 239ms |
| índice de pesquisa (tente) | ★ 1,4k | 168 KB | RangeError: tamanho máximo da pilha de chamadas excedido | ||||
| sifter.js (tente) | ★ 1,1k | 7,5 KB | 3ms | 1070ms | 46,2 MB | 10,6 MB | 18ms |
| fzf-for-js (tentar) | ★ 831 | 15,4 KB | 50ms | 6290ms | 153 MB | 25MB | 18ms |
| confuso (tente) | ★ 819 | 1,4 KB | 0,1ms | 5427ms | 72MB | 7,3 MB | 14ms |
| rápido-fuzzy (tente) | ★346 | 18,2 KB | 790ms | 19266ms | 550 MB | 165MB | 140ms |
| ItensJS (tentar) | ★305 | 109 KB | 2.400ms | 11304ms | 320 MB | 88 MB | 163ms |
| LiquidMetal (tentar) | ★ 292 | 4,2 KB | (colidir) | ||||
| FuzzySearch (tente) | ★ 209 | 3,5 KB | 2ms | 3948ms | 84 MB | 10,5 MB | 18ms |
| FuzzySearch2 (tente) | ★ 186 | 19,4 KB | 93ms | 4189ms | 117 MB | 40,3 MB | 40ms |
| QuickScore (tente) | ★ 153 | 9,5 KB | 10ms | 6915ms | 133 MB | 12,1 MB | 18ms |
| ndx (tente) | ★ 142 | 2,9 KB | 300ms | 581ms | 308 MB | 137MB | 262ms |
| fzy (tente) | ★ 133 | 1,5 KB | 0,1ms | 3932ms | 34MB | 7,3 MB | 10ms |
| ferramentas difusas (tentar) | ★13 | 3 KB | 0,1ms | 5138ms | 164 MB | 7,5 MB | 18ms |
| fuzzyMatch (tente) | ★0 | 1 KB | 0,1ms | 2415ms | 83,5 MB | 7,3 MB | 13ms |


