aiwhispr
version 0.941
AIWhispr é uma ferramenta sem/baixo código para automatizar pipelines de incorporação de vetores para pesquisa semântica. Uma configuração simples orienta o pipeline para leitura de arquivos, extração de texto, criação de embeddings vetoriais e armazenamento em um banco de dados vetorial.
AIWhispr

AIWhispr possui conectores para os seguintes bancos de dados vetoriais
1 Qdrant
2 Milvus
3 Tecer
4 Senso de tipo
5MongoDB
6 Postgres - PGVetor
Certifique-se de ter instalado e iniciado seu banco de dados de vetores.
A variável de ambiente AIWHISPR_HOME_DIR deve ser o caminho completo para o diretório aiwhispr.
A variável de ambiente AIWHISPR_LOG_LEVEL pode ser definida como DEBUG / INFO / WARNING / ERROR
AIWHISPR_HOME=/<...>/aiwhispr
AIWHISPR_LOG_LEVEL=DEBUG
export AIWHISPR_HOME
export AIWHISPR_LOG_LEVEL
Lembre-se de adicionar as variáveis de ambiente em seu script de login do shell
Execute o comando abaixo
$AIWHISPR_HOME/shell/install_python_packages.sh
Se a instalação do uwsgi estiver falhando, certifique-se de ter gcc, python-dev , python3-dev instalado.
sudo apt-get install gcc
sudo apt install python-dev
sudo apt install python3-dev
pip3 install uwsgi
AIWhispr vem com um aplicativo simplificado para ajudá-lo a começar.
Execute o aplicativo streamlit
cd $AIWHISPR_HOME/python/streamlit
streamlit run ./Configure_Content_Site.py &
Isso deve iniciar um aplicativo streamlit na porta padrão 8501 e iniciar uma sessão no seu navegador da web
Existem 3 etapas para configurar o pipeline para indexar seu conteúdo para pesquisa semântica.
1. Configure para ler arquivos de um local de armazenamento
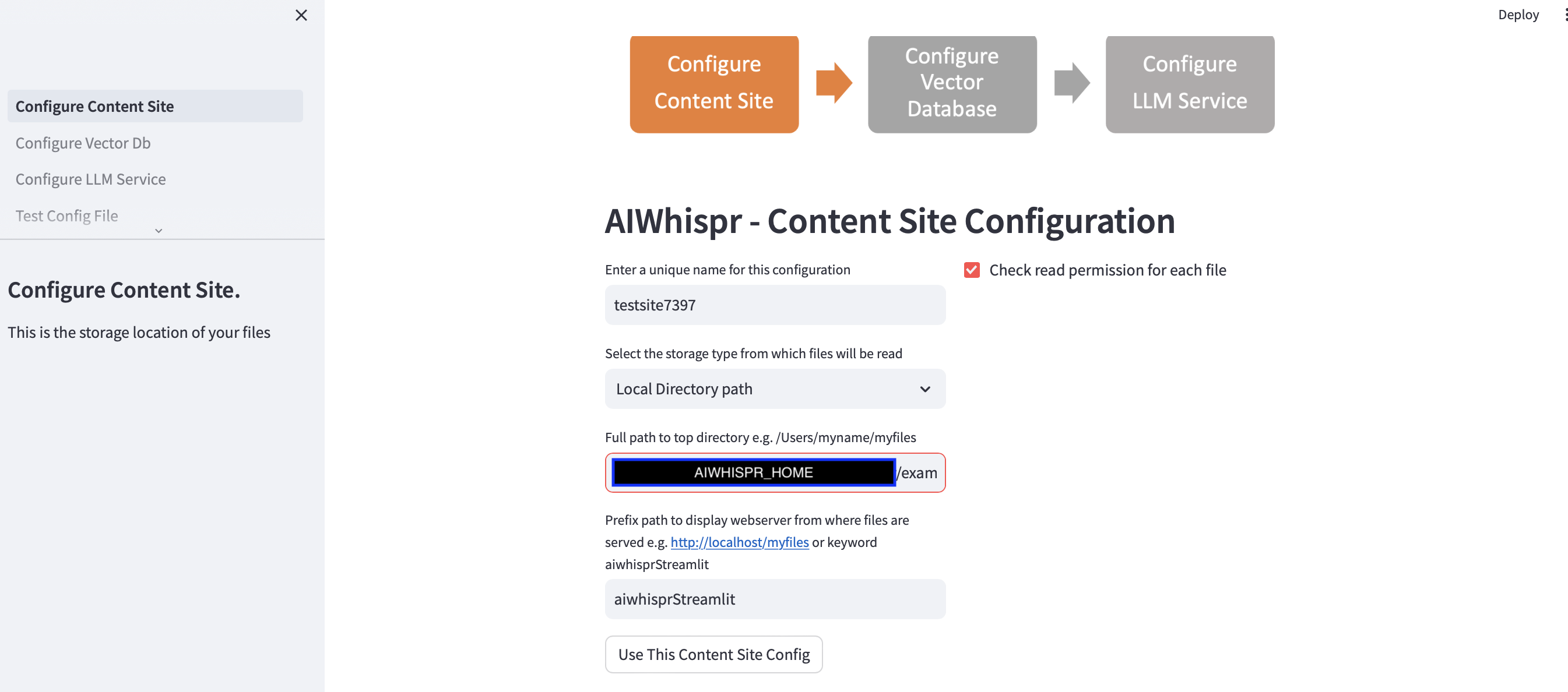
Você pode continuar com a configuração padrão clicando no botão "Usar esta configuração do site de conteúdo"
e vá para a próxima etapa para configurar a conexão do banco de dados vetorial.
O exemplo padrão indexará notícias da BBC para pesquisa semântica.
O aplicativo streamlit pressupõe que você está iniciando uma nova configuração e atribuirá um nome de configuração aleatório. Você pode sobrescrever isso para dar um nome mais significativo. O nome da configuração deve ser exclusivo; não pode conter espaços em branco ou caracteres especiais.
A configuração padrão lerá o conteúdo do caminho do diretório local $AIWHISPR_HOME/examples/http/bbc
Contém mais de 2.000 notícias da BBC que são indexadas para pesquisa semântica.
Você pode optar por ler o conteúdo armazenado no AWS S3, Azure Blob, Google Cloud Storage.
A configuração do caminho do prefixo é usada para criar links da web href para os resultados da pesquisa. Você pode continuar com a palavra-chave padrão "aiwhisprStreamlit"
Clique no botão "Usar esta configuração do site de conteúdo" e prossiga para a próxima etapa para configurar a conexão do banco de dados vetorial clicando em "Configurar banco de dados vetorial" na barra lateral esquerda.
2. Configurar banco de dados vetorial
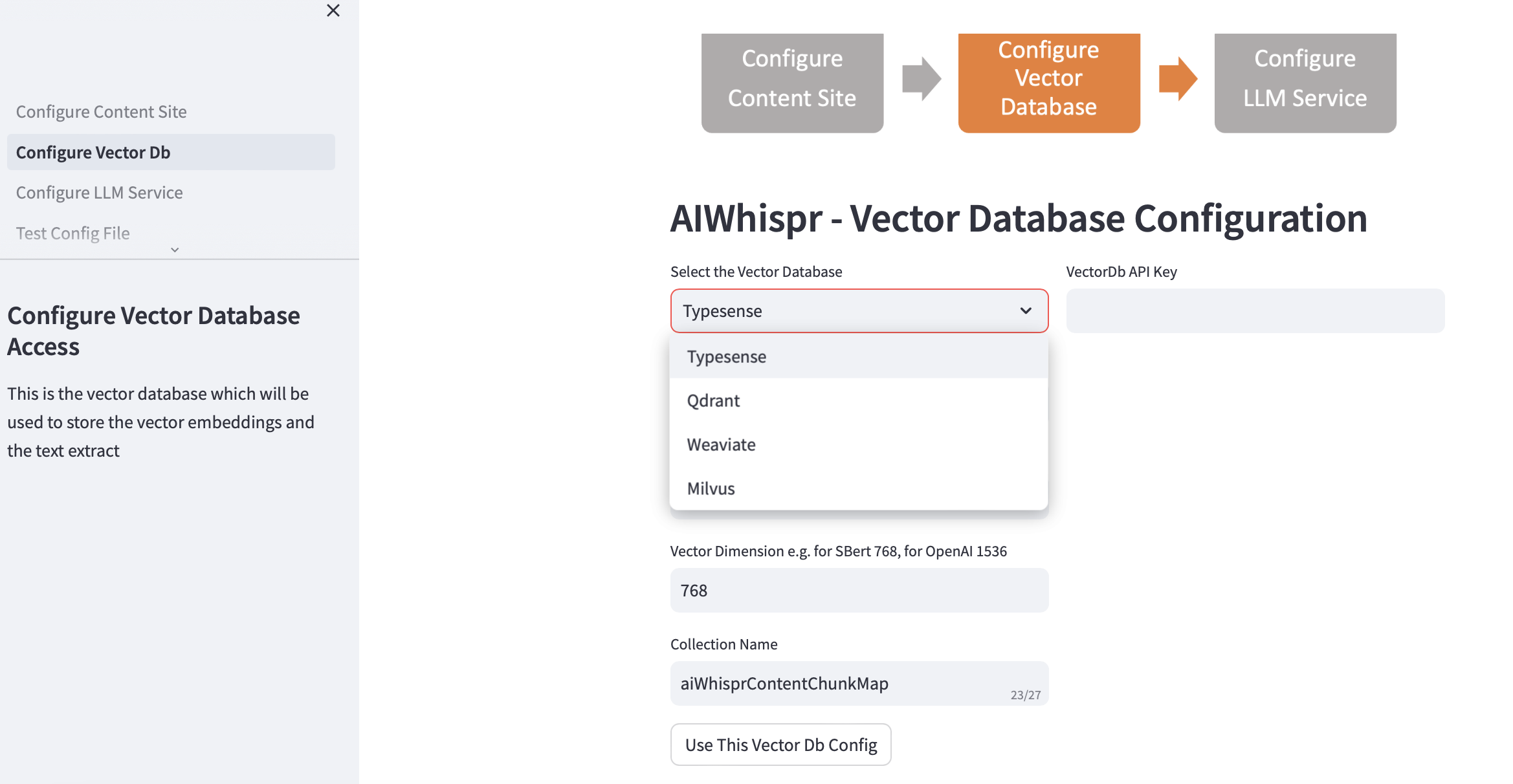
Escolha seu vectordb e forneça os detalhes da conexão.
Quando você escolhe o banco de dados vetorial, o endereço IP do banco de dados vetorial e os números de porta são preenchidos com base nas instalações padrão. Você pode alterar isso com base na sua configuração.
Seu banco de dados vetorial deve estar configurado para autenticação. No caso de Qdrant, Weaviate, Typesense é necessária uma chave de API. Para Milvus, uma combinação de ID de usuário e senha deve ser configurada.
O tamanho da dimensão vetorial deve ser especificado com base no LLM que você planeja usar para codificar texto como incorporações vetoriais. Exemplo: para Open AI "text-embedding-ada-002" deve ser configurado como 1536, que é o tamanho do vetor retornado pelo serviço de incorporação OpenAI.
O nome da coleção padrão criada no banco de dados vetorial é aiwhisprContentChunkMap. Você pode especificar seu próprio nome de coleção.
Clique no botão "Use This Vector Db Config" e passe para a próxima etapa clicando em "Configurar LLM Service" na barra lateral esquerda.
3. Configurar o serviço LLM
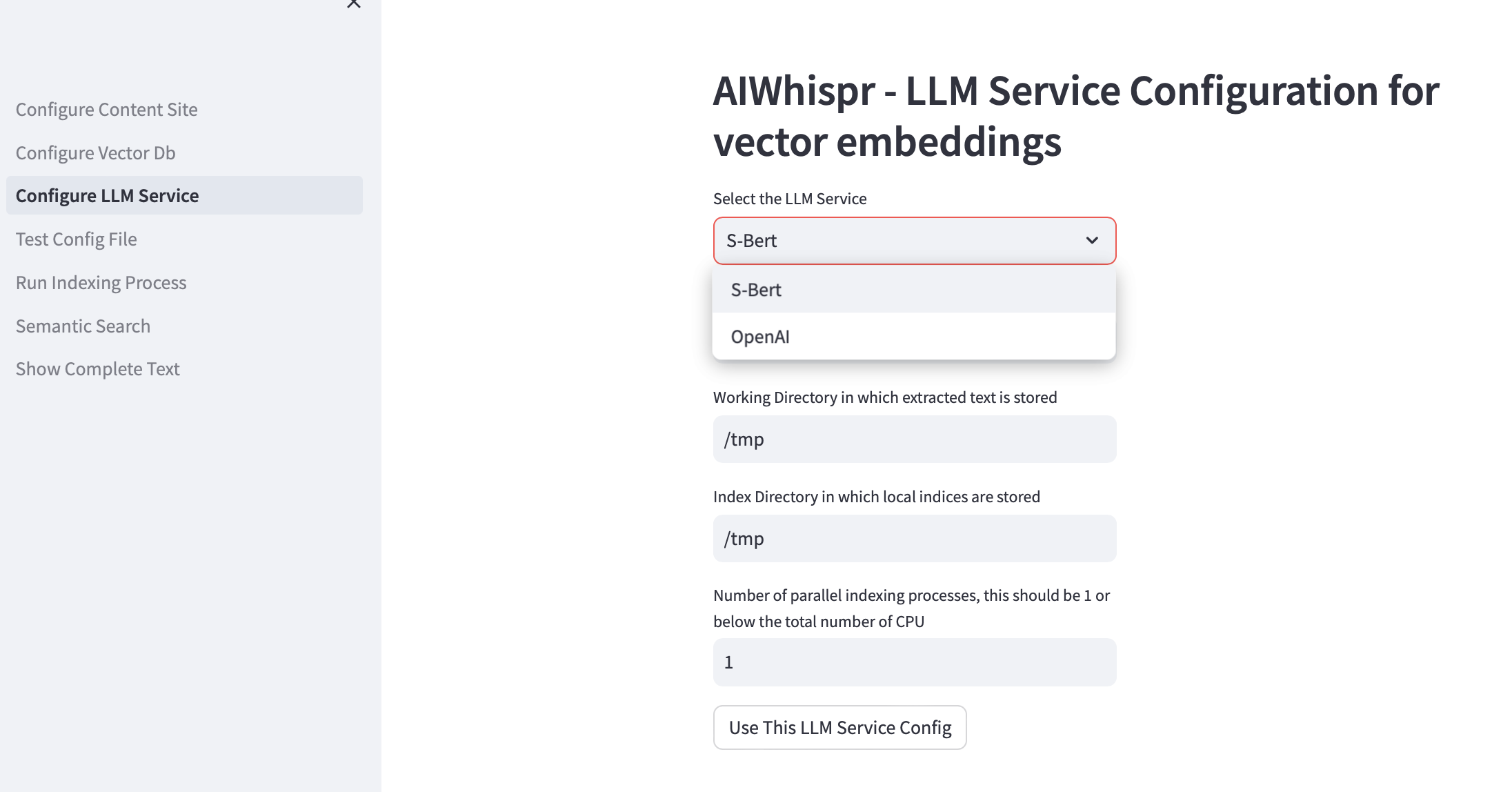
Você pode optar por criar incorporações de vetores usando modelos pré-treinados Sbert que são executados localmente ou usam a API OpenAI.
Para a família de modelos SBert, o modelo padrão usado é all-mpnet-base-v2. Você pode especificar outro modelo SBert.
Para OpenAI, o modelo de incorporação padrão é text-embedding-ada-002
O diretório de trabalho padrão é /tmp
O diretório de trabalho é o local na máquina local que será usado como diretório de trabalho para processar os arquivos que são lidos/baixados de seu local de armazenamento. O texto extraído dos seus documentos é então dividido em tamanhos menores, geralmente 700 palavras, que são então codificados como incorporações vetoriais. O diretório de trabalho é usado para armazenar os pedaços de texto.
O diretório de indexação local padrão é /tmp
Você pode especificar um caminho de diretório local persistente para o diretório de trabalho e de índice.
O index-dir é usado para armazenar a lista de indexação de arquivos de conteúdo que devem ser lidos. AIWhispr suporta vários processos para indexação, cada processo usará sua própria lista de indexação, permitindo assim que você aproveite várias CPUs em sua máquina.
Se você deseja aproveitar várias CPUs para indexação (leitura de conteúdo, criação de incorporação de vetores, armazenamento em banco de dados de vetores), especifique isso na caixa de teste para o número de processos paralelos. Nossa recomendação é que seja 1 ou no máximo (Número de CPUs/2). Exemplo em uma máquina com 8 CPU, isso deve ser definido como 4. AIWhispr usa multiprocessamento para contornar as limitações do Python GIL.
Clique em "Usar esta configuração de serviço LLM" para criar a versão final do arquivo de configuração do pipeline de incorporação vetorial.
O conteúdo do arquivo de configuração e sua localização na sua máquina serão exibidos.
Você pode testar esta configuração clicando em “Testar arquivo de configuração” na barra lateral esquerda.
4. Configuração de teste
Agora você deve ver uma mensagem que mostra a localização do arquivo de configuração do pipeline de incorporação de vetor e um botão "Test Configfile"
Clicar no botão iniciará o processo que testará a configuração do pipeline para
Você deverá ver a mensagem "NO ERRORS" no final dos logs, informando que esta configuração de pipeline pode ser usada.
Clique em “Executar processo de indexação” na barra lateral esquerda para iniciar o pipeline.
5. Execute o processo de indexação
Você deverá ver um botão "Iniciar indexação".
Clique neste botão para iniciar o pipeline. Os logs são atualizados a cada 15 segundos.
O exemplo padrão indexa mais de 2.000 notícias da BBC, o que leva aproximadamente 20 minutos.
Não saia desta página enquanto o processo de indexação estiver em execução, ou seja, enquanto o status "Em execução" do Streamlit estiver exibido no canto superior direito.
Você também pode verificar se o processo de indexação está sendo executado usando grep em sua máquina.
ps -ef | grep python3 | grep index_content_site.py
6. Pesquisa Semântica
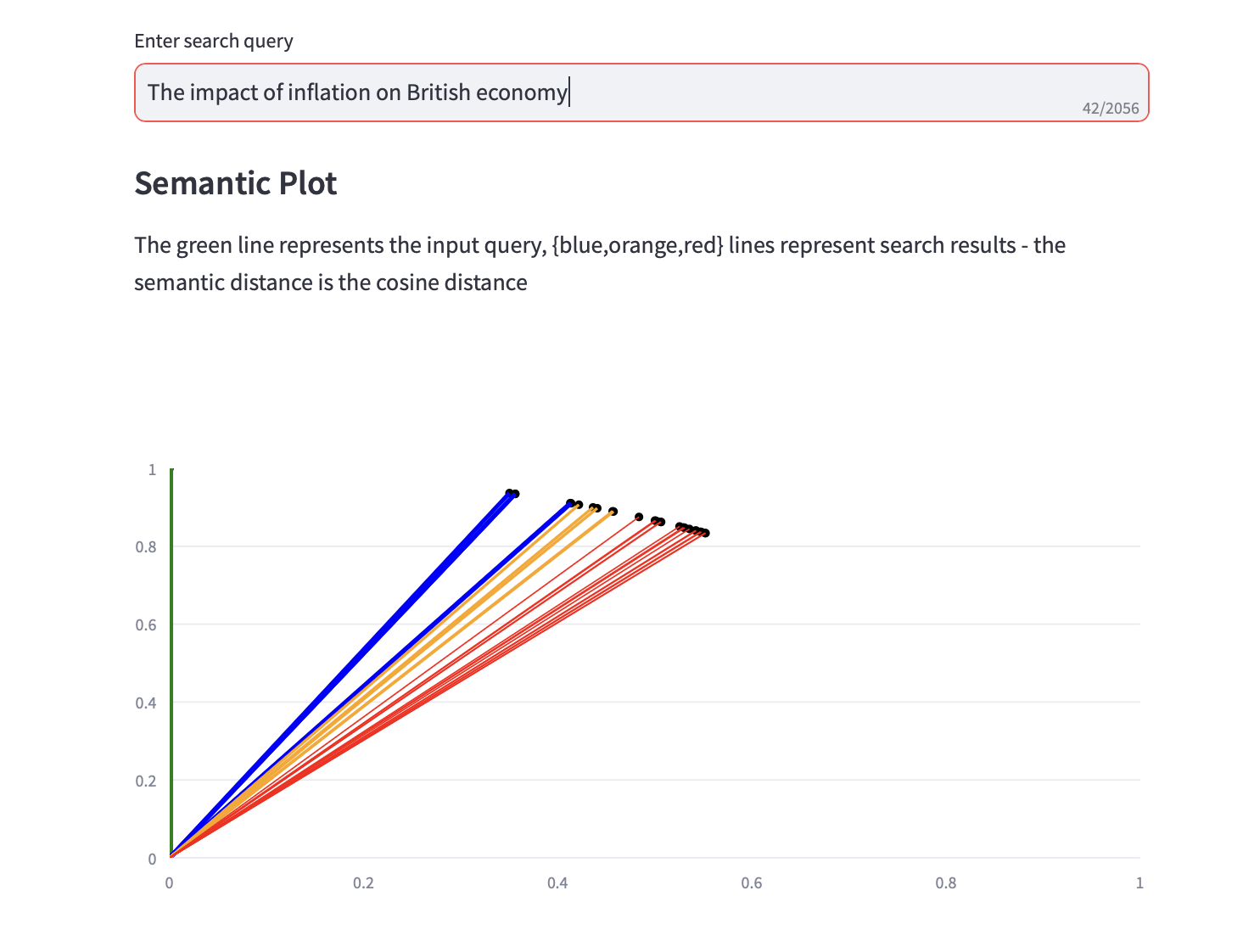
Agora você pode executar consultas de pesquisa semântica.
Um gráfico semântico que exibe a distância do cosseno e uma das 3 principais análises de PCA para os resultados da pesquisa também é exibido junto com os resultados da pesquisa de texto.