lnx
v0.9.0 Master

Rico em recursos | ⚡ Insanamente rápido
Uma implantação ultrarrápida e adaptável do mecanismo de pesquisa tantivy via REST.
O lnx foi desenvolvido para não reinventar a roda, ele se baseia no tempo de execução que rouba trabalho tokio-rs , na estrutura hiperweb combinada com o poder de computação bruto do mecanismo de pesquisa tantivy .
Juntos, isso permite que o lnx ofereça indexação em milissegundos em dezenas de milhares de inserções de documentos de uma só vez (não é mais necessário esperar que as coisas sejam indexadas!), Transações por índice e a capacidade de processar pesquisas como se fosse apenas mais uma pesquisa na tabela hash?
O lnx, embora muito novo, oferece uma ampla gama de recursos graças ao ecossistema em que se encontra.
Aqui você pode ver o lnx fazendo pesquisas enquanto você digita em um conjunto de dados de 27 milhões de documentos chegando a 18 GB razoáveis, uma vez indexado, executado em meu i7-8700k usando ~ 3 GB de RAM com nosso sistema fast-fuzzy . Tem um conjunto de dados maior para tentarmos? Abra um problema!
O lnx pode fornecer a capacidade de ajustar o sistema de acordo com seu caso de uso específico. Você pode personalizar os threads de tempo de execução assíncronos. O pool de threads de simultaneidade, threads por leitor e threads de gravação, todos por índice.
Isso lhe dá a capacidade de controlar detalhadamente para onde estão indo seus recursos de computação. Tem um grande conjunto de dados, mas menor quantidade de leituras simultâneas? Bata nos threads do leitor em troca de simultaneidade máxima inferior.
Os números abaixo foram obtidos por nosso lnx-cli no pequeno conjunto de dados movies.json , não tentamos mais, pois o Meilisearch leva um tempo incrivelmente longo para indexar milhões de documentos, embora o novo mecanismo Meilisearch tenha melhorado isso um pouco.
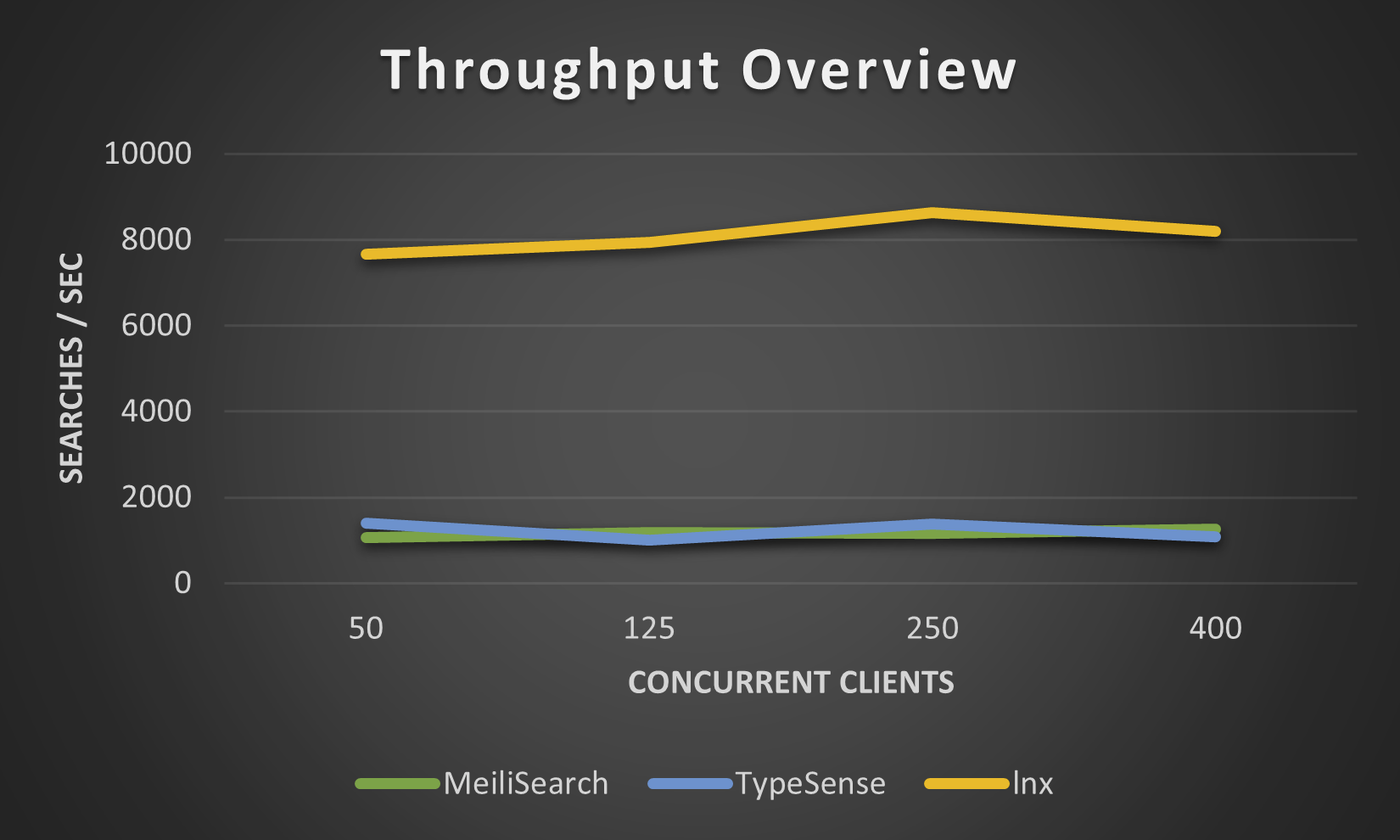
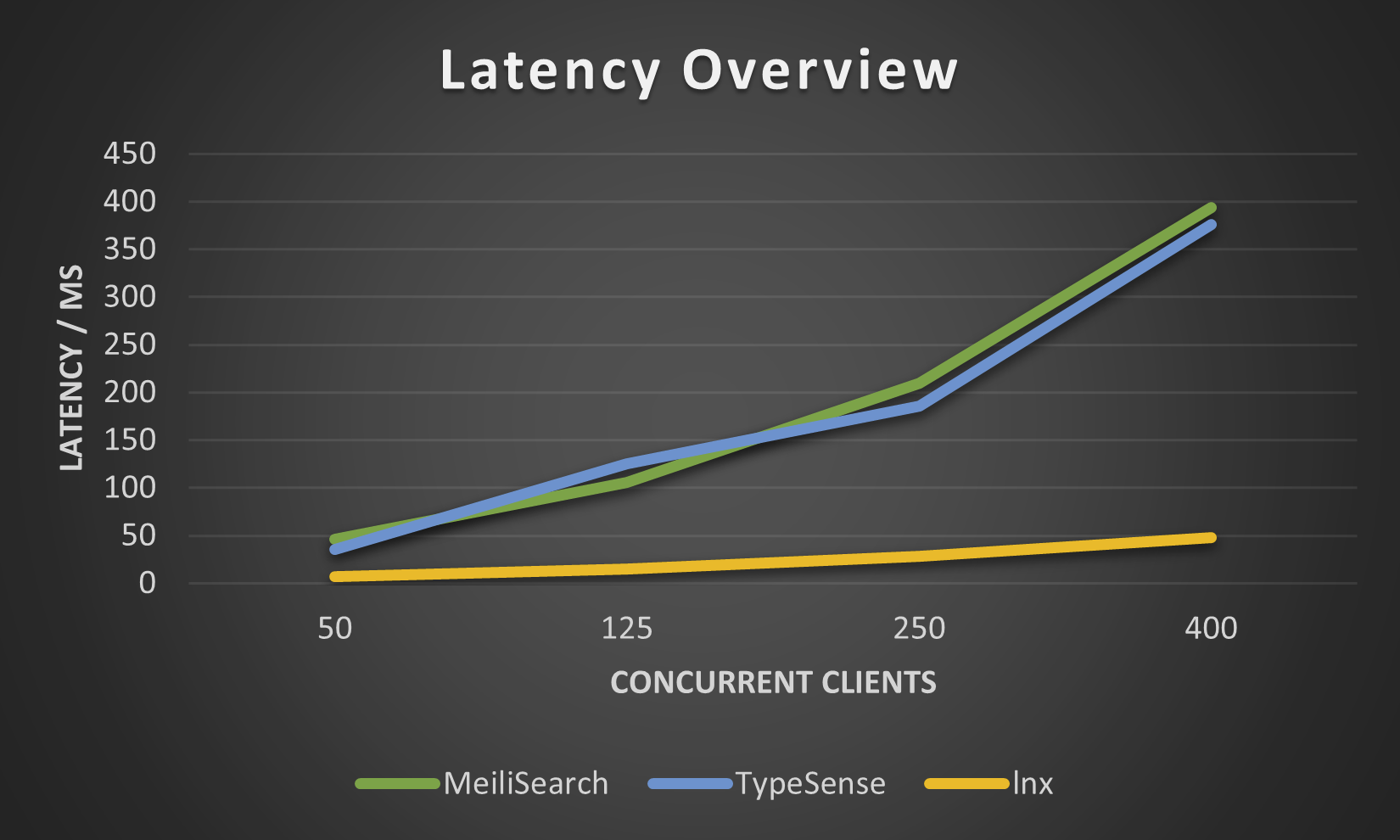
Por mais que o lnx ofereça uma ampla gama de recursos, ele não consegue fazer tudo sendo um sistema tão jovem. Naturalmente, tem algumas limitações:


