korpatbert
1.0.0
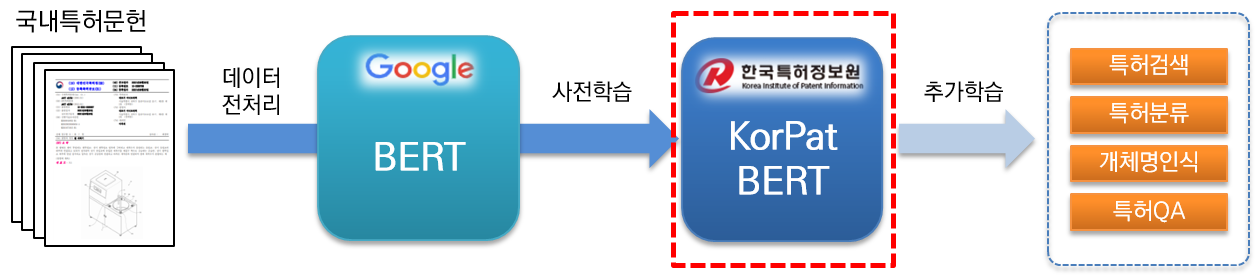
KorPatBERT (Patente Coreana BERT) é um modelo de linguagem de IA pesquisado e desenvolvido pelo Serviço de Informações de Patentes da Coreia.
A fim de resolver problemas de processamento de linguagem natural coreano no campo de patentes e preparar infraestrutura de informação inteligente na indústria de patentes, o pré-treinamento em uma grande quantidade de documentos de patentes nacionais (base: cerca de 4,06 milhões de documentos, grande: cerca de 5,06 milhões de documentos) é baseado na arquitetura do modelo básico existente do Google BERT (pré-treinamento) e é fornecido gratuitamente.
É um modelo de linguagem pré-treinado de alto desempenho especializado na área de patentes e pode ser utilizado em diversas tarefas de processamento de linguagem natural.
[Base KorPatBERT]
[KorPatBERT-grande]
[Base KorPatBERT]
[KorPatBERT-grande]
Aproximadamente 10 milhões de substantivos principais e substantivos compostos foram extraídos dos documentos de patentes usados no aprendizado de modelos de linguagem e adicionados ao dicionário do usuário do analisador de morfemas coreano Mecab-ko e depois divididos em subpalavras por meio do Google SentencePiece. tokenizer (tokenizador de patente de sentença Mecab-ko).
| modelo | Principal@1(ACC) |
|---|---|
| GoogleBERT | 72,33 |
| KorBERT | 73,29 |
| KOBERT | 33,75 |
| KrBERT | 72,39 |
| Base KorPatBERT | 76,32 |
| KorPatBERT-grande | 77.06 |
| modelo | Principal@1(ACC) | Principais@3(ACC) | Principais@5(ACC) |
|---|---|---|---|
| Base KorPatBERT | 61,91 | 82,18 | 86,97 |
| KorPatBERT-grande | 62,89 | 82,18 | 87,26 |
| Nome do programa | versão | Caminho do guia de instalação | Obrigatório? |
|---|---|---|---|
| píton | 3.6 e superior | https://www.python.org/ | S |
| anaconda | 4.6.8 e superior | https://www.anaconda.com/ | N |
| fluxo tensor | 2.2.0 e superior | https://www.tensorflow.org/install/pip?hl=ko | S |
| pedaço de frase | 0.1.96 ou superior | https://github.com/google/sentencepiece | N |
| mecab-ko | 0.996-pt-0.0.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | S |
| mecab-ko-dic | 2.1.1 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | S |
| mecab-python | 0.996-pt-0.9.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | S |
| python-mecab-ko | 1.0.11 ou superior | https://pypi.org/project/python-mecab-ko/ | S |
| Keras | 2.4.3 e superior | https://github.com/keras-team/keras | N |
| bert_for_tf2 | 0.14.4 e superior | https://github.com/kpe/bert-for-tf2 | N |
| tqdm | 4.59.0 e superior | https://github.com/tqdm/tqdm | N |
| soynlp | 0,0,493 ou superior | https://github.com/lovit/soynlp | N |
Installation URL: https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/
mecab-ko > 0.996-ko-0.9.2
mecab-ko-dic > 2.1.1
mecab-python > 0.996-ko-0.9.2
from korpat_tokenizer import Tokenizer
# (vocab_path=Vocabulary 파일 경로, cased=한글->True, 영문-> False)
tokenizer = Tokenizer(vocab_path="./korpat_vocab.txt", cased=True)
# 테스트 샘플 문장
example = "본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다."
# 샘플 토크나이즈
tokens = tokenizer.tokenize(example)
# 샘플 인코딩 (max_len=토큰 최대 길이)
ids, _ = tokenizer.encode(example, max_len=256)
# 샘플 디코딩
decoded_tokens = tokenizer.decode(ids)
# 결과 출력
print("Length of Token dictionary ===>", len(tokenizer._token_dict.keys()))
print("Input example ===>", example)
print("Tokenized example ===>", tokens)
print("Converted example to IDs ===>", ids)
print("Converted IDs to example ===>", decoded_tokens)
Length of Token dictionary ===> 21400
Input example ===> 본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다.
Tokenized example ===> ['[CLS]', '본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.', '[SEP]']
Converted example to IDs ===> [5, 58, 554, 32, 2716, 6554, 817, 20418, 20308, 20514, 15, 732, 15572, 39, 1634, 12, 11, 5934, 20514, 20367, 9, 315, 16, 5922, 17, 33, 279, 20399, 16971, 26, 5934, 20514, 13, 674, 26, 11, 10132, 1686, 33, 3781, 15, 11950, 12, 64, 87, 12, 3958, 315, 10, 51, 39, 25, 11, 5934, 20514, 15, 1803, 12889, 399, 24, 25, 118, 12, 11, 817, 20418, 20308, 299, 20367, 10, 439, 56, 13, 18, 14, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Converted IDs to example ===> ['본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.']
※ É igual ao método de aprendizagem base do Google BERT e, para exemplos de uso, consulte a seção 2.3 특허분야 사전학습 언어모델(KorPatBERT) 사용자 매뉴얼 .
Estamos divulgando o modelo linguístico do Instituto Coreano de Informações sobre Patentes por meio de determinados procedimentos para organizações, empresas e pesquisadores interessados nele. Preencha o formulário de inscrição e o acordo de acordo com o procedimento de inscrição abaixo e envie a inscrição por e-mail para o responsável.
| nome do arquivo | explicação |
|---|---|
| pat_all_mecab_dic.csv | Dicionário do usuário de patentes Mecab |
| lm_test_data.tsv | Conjunto de dados de amostra de classificação |
| korpat_tokenizer.py | Programa KorPat Tokenizer |
| test_tokenize.py | Amostra de uso do tokenizador |
| test_tokenize.ipynb | Amostra de uso do tokenizador (Júpiter) |
| test_lm.py | Amostra de uso de modelo de linguagem |
| test_lm.ipynb | Amostra de uso do modelo de linguagem (Jupyter) |
| korpat_bert_config.json | Arquivo de configuração KorPatBERT |
| korpat_vocab.txt | Arquivos de vocabulário KorPatBERT |
| modelo.ckpt-381250.meta | Arquivo de modelo KorPatBERT |
| modelo.ckpt-381250.index | Arquivo de modelo KorPatBERT |
| modelo.ckpt-381250.data-00000-of-00001 | Arquivo de modelo KorPatBERT |


