yagooglesearch
v1.10.0
yagooglesearch é uma biblioteca Python para executar pesquisas inteligentes, realistas e ajustáveis no Google. Ele simula o comportamento humano real de pesquisa do Google para evitar a limitação de taxa pelo Google (a temida resposta HTTP 429) e, se o HTTP 429 for bloqueado pelo Google, a lógica é recuar e continuar tentando. A biblioteca não usa a API do Google e é fortemente baseada na biblioteca googlesearch. Os recursos incluem:
requests para solicitações HTTP e gerenciamento de cookiesEste código é fornecido no estado em que se encontra e você é totalmente responsável pela forma como ele é usado. A extração dos resultados da Pesquisa Google pode violar seus Termos de Serviço. Outra biblioteca de pesquisa Python do Google teve algumas informações/discussões interessantes sobre ela:
O método preferido do Google é usar sua API.
pip install yagooglesearchgit clone https://github.com/opsdisk/yagooglesearch
cd yagooglesearch
virtualenv -p python3 .venv # If using a virtual environment.
source .venv/bin/activate # If using a virtual environment.
pip install . # Reads from pyproject.toml import yagooglesearch
query = "site:github.com"
client = yagooglesearch . SearchClient (
query ,
tbs = "li:1" ,
max_search_result_urls_to_return = 100 ,
http_429_cool_off_time_in_minutes = 45 ,
http_429_cool_off_factor = 1.5 ,
# proxy="socks5h://127.0.0.1:9050",
verbosity = 5 ,
verbose_output = True , # False (only URLs) or True (rank, title, description, and URL)
)
client . assign_random_user_agent ()
urls = client . search ()
len ( urls )
for url in urls :
print ( url ) Mesmo que pesquisar no Google através da GUI exiba uma mensagem como “Cerca de 13.000.000 resultados”, isso não significa que yagooglesearch encontrará algo próximo disso. Os testes mostram que, no máximo, cerca de 400 resultados são retornados. Se você definir 400 < max_search_result_urls_to_return , uma mensagem de aviso será impressa nos logs. Veja o nº 28 para a discussão.
Baixa e lenta é a estratégia ao executar pesquisas no Google usando yagooglesearch . Se você começar a receber respostas HTTP 429, o Google detectou você como um bot e bloqueará seu IP por um determinado período de tempo. yagooglesearch não é capaz de ignorar o CAPTCHA, mas você pode fazer isso manualmente, realizando uma pesquisa no Google a partir de um navegador e provando que você é humano.
Os critérios e limites para ser bloqueado são desconhecidos, mas em geral, randomizar o agente do usuário, esperar tempo suficiente entre os resultados da pesquisa paginada (7 a 17 segundos) e esperar tempo suficiente entre diferentes pesquisas no Google (30 a 60 segundos) deve ser suficiente. Sua milhagem definitivamente irá variar. Usar esta biblioteca com o Tor provavelmente fará com que você seja bloqueado rapidamente.
Se yagooglesearch detectar uma resposta HTTP 429 do Google, ele ficará suspenso por http_429_cool_off_time_in_minutes Minutes minutos e tentará novamente. Cada vez que um HTTP 429 é detectado, o tempo de espera aumenta por um fator de http_429_cool_off_factor .
O objetivo é fazer com que yagooglesearch se preocupe com a detecção e recuperação do HTTP 429 e não sobrecarregue o script que o utiliza.
Se você não deseja que yagooglesearch lide com HTTP 429 e prefere lidar com isso sozinho, passe yagooglesearch_manages_http_429s=False ao instanciar o objeto yagooglesearch. Se um HTTP 429 for detectado, a string "HTTP_429_DETECTED" é adicionada a um objeto de lista que será retornado, e cabe a você decidir qual será o próximo passo. O objeto de lista conterá quaisquer URLs encontrados antes da detecção do HTTP 429.
import yagooglesearch
query = "site:twitter.com"
client = yagooglesearch . SearchClient (
query ,
tbs = "li:1" ,
verbosity = 4 ,
num = 10 ,
max_search_result_urls_to_return = 1000 ,
minimum_delay_between_paged_results_in_seconds = 1 ,
yagooglesearch_manages_http_429s = False , # Add to manage HTTP 429s.
)
client . assign_random_user_agent ()
urls = client . search ()
if "HTTP_429_DETECTED" in urls :
print ( "HTTP 429 detected...it's up to you to modify your search." )
# Remove HTTP_429_DETECTED from list.
urls . remove ( "HTTP_429_DETECTED" )
print ( "URLs found before HTTP 429 detected..." )
for url in urls :
print ( url )
yagooglesearch suporta o uso de um proxy. O proxy fornecido é usado durante todo o ciclo de vida da pesquisa para torná-la mais humana, em vez de alternar entre vários proxies para diferentes partes da pesquisa. O ciclo de vida geral da pesquisa é:
google.com Para usar um proxy, forneça uma string de proxy ao inicializar um objeto yagooglesearch.SearchClient :
client = yagooglesearch . SearchClient (
"site:github.com" ,
proxy = "socks5h://127.0.0.1:9050" ,
) Os esquemas de proxy suportados são baseados naqueles suportados na biblioteca requests Python (https://docs.python-requests.org/en/master/user/advanced/#proxies):
httphttpssocks5 - "faz com que a resolução DNS aconteça no cliente, e não no servidor proxy." Você provavelmente não deseja isso, pois todas as pesquisas de DNS seriam provenientes de onde yagooglesearch está sendo executado, em vez do proxy.socks5h - "Se você deseja resolver os domínios no servidor proxy, use meias5h como esquema." Esta é a melhor opção se você estiver usando SOCKS porque a pesquisa de DNS e a pesquisa do Google são provenientes do endereço IP do proxy. Se você estiver usando um certificado autoassinado para um proxy HTTPS, provavelmente precisará desabilitar a verificação SSL/TLS quando:
yagooglesearch.SearchClient : import yagooglesearch
query = "site:github.com"
client = yagooglesearch . SearchClient (
query ,
proxy = "http://127.0.0.1:8080" ,
verify_ssl = False ,
verbosity = 5 ,
) query = "site:github.com"
client = yagooglesearch . SearchClient (
query ,
proxy = "http://127.0.0.1:8080" ,
verbosity = 5 ,
)
client . verify_ssl = False Se você quiser usar vários proxies, essa carga recai sobre o script que utiliza a biblioteca yagooglesearch para instanciar um novo objeto yagooglesearch.SearchClient com o proxy diferente. Abaixo está um exemplo de loop em uma lista de proxies:
import yagooglesearch
proxies = [
"socks5h://127.0.0.1:9050" ,
"socks5h://127.0.0.1:9051" ,
"http://127.0.0.1:9052" , # HTTPS proxy with a self-signed SSL/TLS certificate.
]
search_queries = [
"python" ,
"site:github.com pagodo" ,
"peanut butter toast" ,
"are dragons real?" ,
"ssh tunneling" ,
]
proxy_rotation_index = 0
for search_query in search_queries :
# Rotate through the list of proxies using modulus to ensure the index is in the proxies list.
proxy_index = proxy_rotation_index % len ( proxies )
client = yagooglesearch . SearchClient (
search_query ,
proxy = proxies [ proxy_index ],
)
# Only disable SSL/TLS verification for the HTTPS proxy using a self-signed certificate.
if proxies [ proxy_index ]. startswith ( "http://" ):
client . verify_ssl = False
urls_list = client . search ()
print ( urls_list )
proxy_rotation_index += 1 Se você tiver um valor de cookie GOOGLE_ABUSE_EXEMPTION , ele poderá ser passado para google_exemption ao instanciar o objeto SearchClient .
O parâmetro &tbs= é usado para especificar filtros textuais ou baseados em tempo.
&tbs=li:1
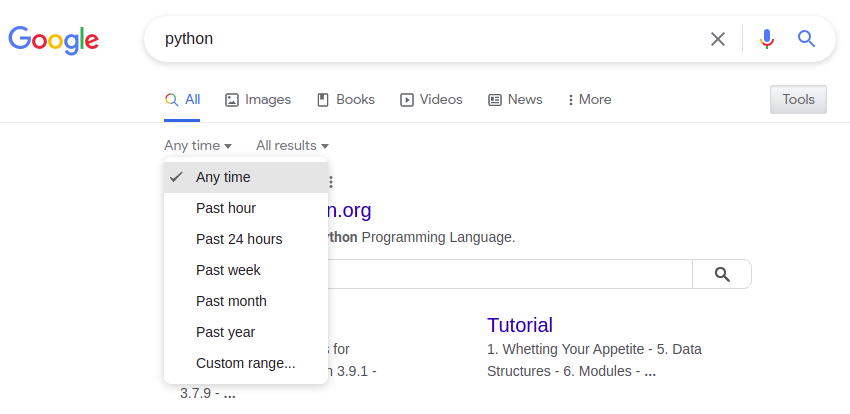
| Filtro de tempo | &tbs= parâmetro de URL | Notas |
|---|---|---|
| Última hora | qdr:h | |
| Último dia | qdr:d | Últimas 24 horas |
| Semana passada | qdr:w | |
| Mês passado | qdr:m | |
| Ano passado | qdr:y | |
| Personalizado | cdr:1,cd_min:01/01/2021,cd_max:01/06/2021 | Veja a função yagooglesearch.get_tbs() |
Atualmente, a função .filter_search_result_urls() removerá qualquer URL que contenha a palavra “google”. Isso evita que os URLs de pesquisa retornados sejam poluídos com URLs do Google. Observe isso se você estiver tentando pesquisar explicitamente resultados que possam ter "google" no URL, como site:google.com computer
Distribuído sob a licença BSD de 3 cláusulas. Consulte LICENÇA para obter mais informações.
@opsdisk
Link do projeto: https://github.com/opsdisk/yagooglesearch


