SeekStorm
v0.11.0

SeekStorm é uma biblioteca de pesquisa de texto completo de código aberto inferior a um milissegundo e um servidor multilocatário implementado em Rust .
Desenvolvimento iniciado em 2015, em produção desde 2020, Rust port em 2023, código aberto em 2024, trabalho em andamento.
SeekStorm é de código aberto licenciado sob a Licença Apache 2.0
Postagens de blog: SeekStorm agora é de código aberto e SeekStorm obtém pesquisa facetada, pesquisa de proximidade geográfica, classificação de resultados
Tipos de consulta
Tipos de resultados
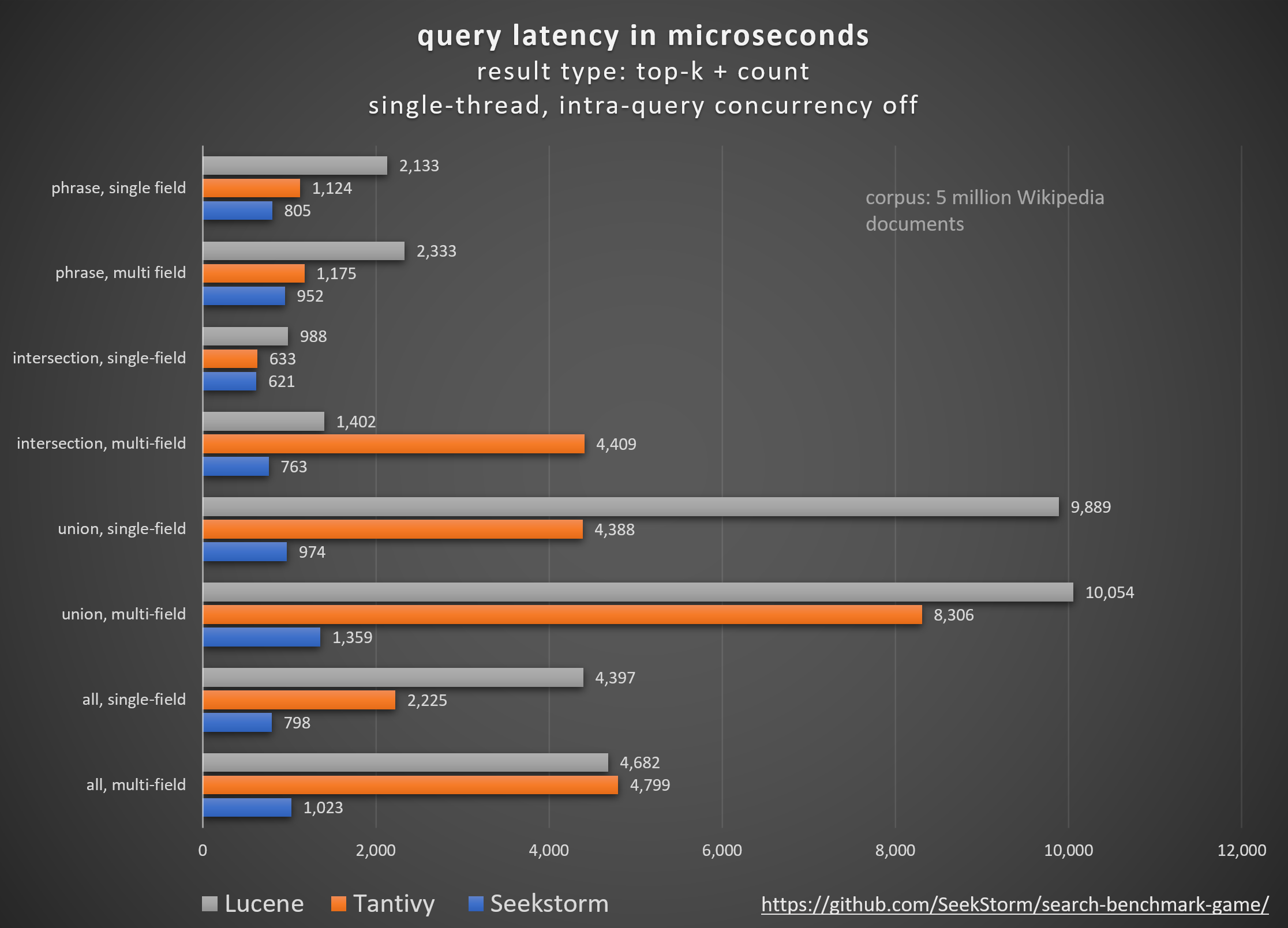
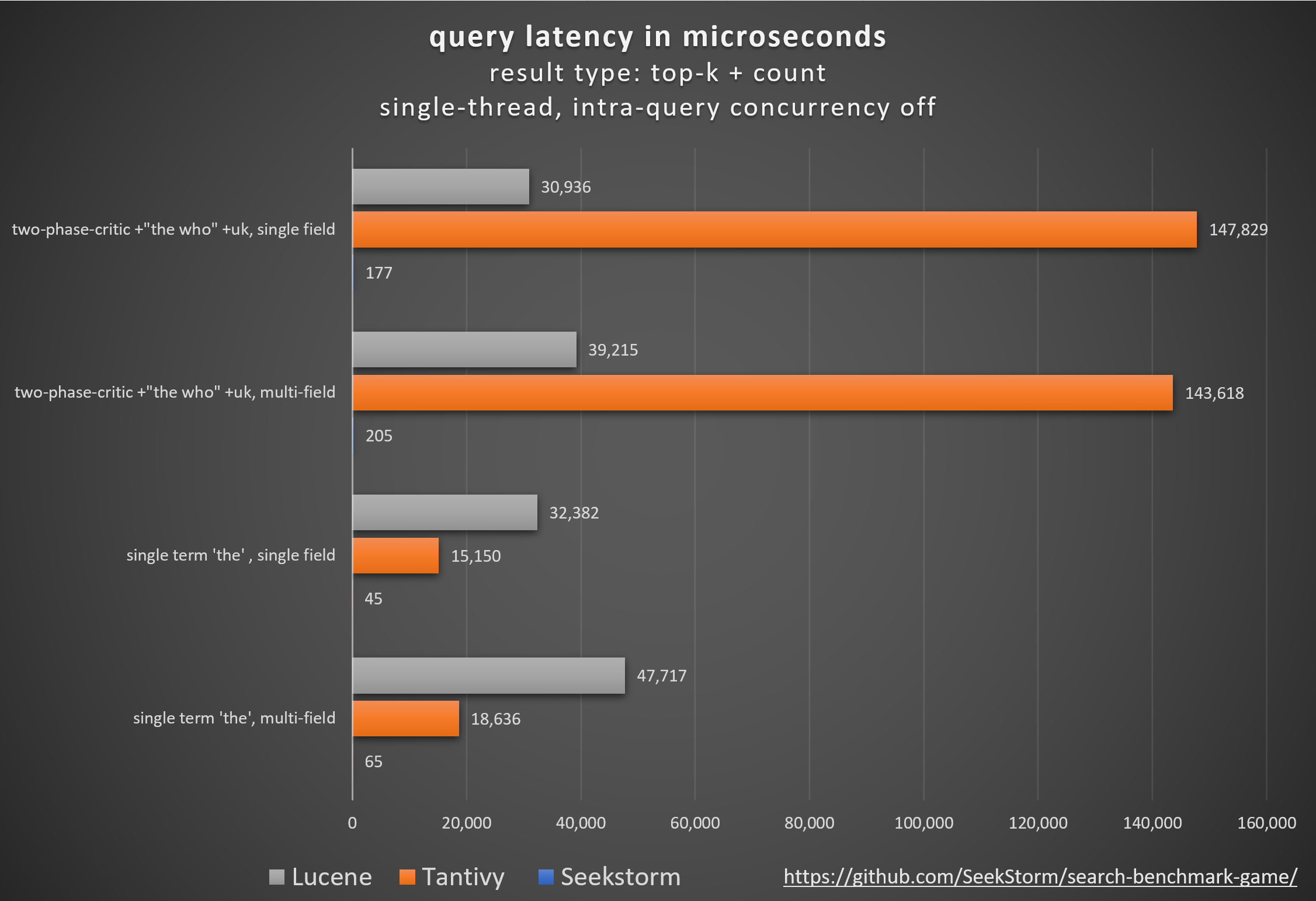
Desempenho
Menor latência, maior rendimento, menor custo e consumo de energia, esp. para consultas simultâneas e de vários campos.
Latências baixas garantem uma experiência de usuário tranquila e evitam perda de clientes e receitas.
Embora alguns dependam de aceleradores de hardware proprietários (FPGA/ASIC) ou clusters para melhorar o desempenho,
SeekStorm alcança um impulso semelhante algoritmicamente em um único servidor comum.
Consistência
Nenhuma latência de consulta imprevisível durante e após a indexação de grande volume, pois o SeekStorm não requer mesclagens de segmentos com uso intensivo de recursos.
Latências estáveis – sem custos de inicialização a frio devido à compilação just-in-time, sem atrasos imprevisíveis na coleta de lixo.
Dimensionamento
Mantém baixa latência, alto rendimento e baixo consumo de RAM, mesmo para índices em escala de bilhões.
Número de campo, comprimento de campo e tamanho de índice ilimitados.
Relevância
O ranking de proximidade de prazo fornece resultados mais relevantes em comparação ao BM25.
Em tempo real
Pesquisa verdadeira em tempo real, ao contrário do NRT: todo documento indexado pode ser pesquisado imediatamente, mesmo antes e durante a confirmação.
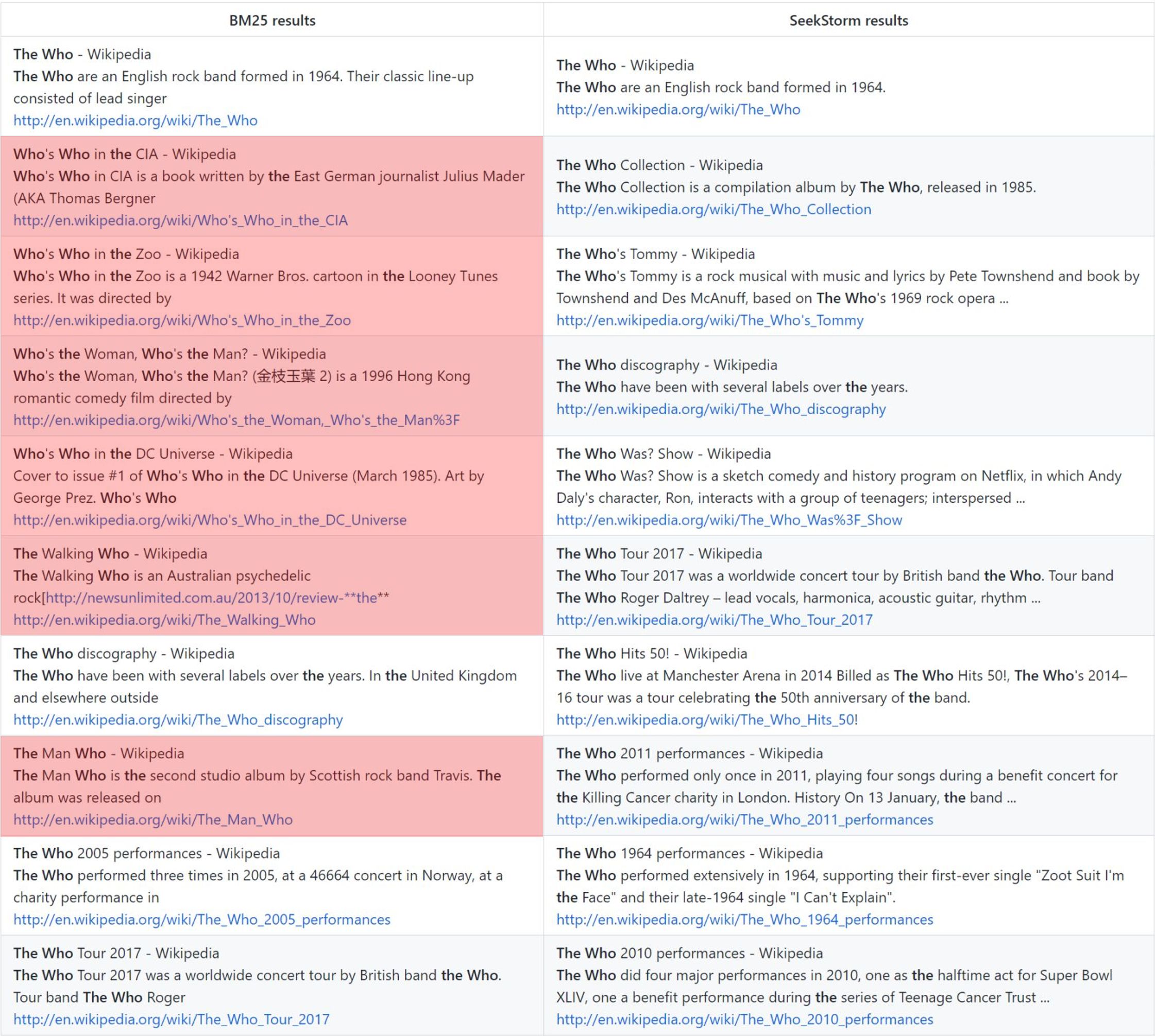
quem: classificação vanilla BM25 vs. classificação de proximidade SeekStorm
Metodologia
Comparando diferentes bibliotecas de mecanismos de pesquisa de código aberto (pesquisa lexical BM25) usando o search_benchmark_game de código aberto desenvolvido por Tantivy e Jason Wolfe.
Benefícios
Resultados detalhados de benchmark https://seekstorm.github.io/search-benchmark-game/
Repositório de código de referência https://github.com/SeekStorm/search-benchmark-game/
Consulte nossas postagens no blog para obter informações mais detalhadas: SeekStorm agora é de código aberto e SeekStorm obtém pesquisa facetada, pesquisa de proximidade geográfica, classificação de resultados
Apesar do que os ciclos de hype https://www.bitecode.dev/p/hype-cycles querem que você acredite, a pesquisa por palavras-chave não morreu, pois o NoSQL não foi a morte do SQL.
Você deve manter uma caixa de ferramentas e escolher a melhor ferramenta para a tarefa em questão. https://seekstorm.com/blog/vector-search-vs-keyword-search1/
A pesquisa por palavra-chave é apenas um filtro para um conjunto de documentos, retornando aqueles onde ocorrem determinadas palavras-chave, geralmente combinadas com uma métrica de classificação como BM25. Uma funcionalidade muito básica e central, que é muito desafiadora para implementar em escala com baixa latência. Como a funcionalidade é tão básica, há um número ilimitado de campos de aplicação. É um componente que deve ser usado em conjunto com outros componentes. Existem casos de uso que podem ser melhor resolvidos hoje com pesquisa vetorial e LLMs, mas para muitos outros, a pesquisa por palavra-chave ainda é a melhor solução. A pesquisa por palavra-chave é exata, sem perdas e muito rápida, com melhor dimensionamento, melhor latência, menor custo e consumo de energia. A pesquisa vetorial trabalha com similaridade semântica, retornando resultados com determinada proximidade e probabilidade.
Se você pesquisar resultados exatos, como nomes próprios, números, placas de veículos, nomes de domínio e frases (por exemplo, detecção de plágio), a pesquisa por palavra-chave será sua amiga. A pesquisa vetorial, por outro lado, enterrará o resultado exato que você está procurando entre uma miríade de resultados que estão apenas de alguma forma relacionados semanticamente. Ao mesmo tempo, se você não souber os termos exatos ou estiver interessado em um tópico, significado ou sinônimo mais amplo, não importa quais termos exatos sejam usados, a pesquisa por palavra-chave irá falhar.
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.A pesquisa vetorial é perfeita se você não conhece os termos exatos da consulta ou está interessado em um tópico, significado ou sinônimo mais amplo, independentemente dos termos exatos da consulta usados. Mas se você estiver procurando termos exatos, por exemplo, nomes próprios, números, placas de veículos, nomes de domínio e frases (por exemplo, detecção de plágio), você deve sempre usar a pesquisa por palavra-chave. A pesquisa vetorial irá apenas enterrar o resultado exato que você está procurando entre uma miríade de resultados que estão apenas de alguma forma relacionados. Possui um bom recall, mas baixa precisão e maior latência. É propenso a falsos positivos, por exemplo, na detecção de plágio, à medida que palavras exatas e ordem das palavras se perdem.
A pesquisa vetorial permite pesquisar não apenas texto semelhante, mas tudo que pode ser transformado em um vetor: texto, imagens (reconhecimento facial, impressões digitais), áudio e permite que você faça coisas mágicas como rainha - mulher + homem = rei .
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generationA pesquisa vetorial não substitui a pesquisa por palavra-chave, mas sim uma adição complementar - melhor para ser usada em uma solução híbrida onde os pontos fortes de ambas as abordagens são combinados. A pesquisa por palavra-chave não está desatualizada, mas é comprovada pelo tempo .
Portamos (parcialmente) a base de código SeekStorm de C# para Rust
Rust é ótimo para aplicativos de desempenho crítico que lidam com big data e/ou muitos usuários simultâneos. Algoritmos rápidos brilharão ainda mais com uma linguagem de programação consciente do desempenho?
veja ARQUITETURA.md
cargo build --release
AVISO : certifique-se de definir a variável de ambiente MASTER_KEY_SECRET como secreta, caso contrário, suas chaves de API geradas serão comprometidas.
https://docs.rs/seekstorm
Documentação de construção
cargo doc --no-deps
Acesse a documentação localmente
SeekStormtargetdocseekstormindex.html
SeekStormtargetdocseekstorm_serverindex.html
Adicione as caixas necessárias ao seu projeto
cargo add seekstorm
cargo add tokio
cargo add serde_json use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;use um tempo de execução Rust assíncrono
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {criar índice
let index_path= Path :: new ( "C:/index/" ) ;
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let _index_arc = Arc :: new ( RwLock :: new ( index ) ) ;abrir índice (alternativamente para criar índice)
let index_path= Path :: new ( "C:/index/" ) ;
let mut index_arc= open_index ( index_path , false ) . await . unwrap ( ) ; documentos de índice
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; submeter documentos
index_arc . commit ( ) . await ;índice de pesquisa
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter ) . await ;exibir resultados
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_string ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter= Some ( highlighter ( & index_arc , highlights , result_object . query_term_strings ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let mut index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}pesquisa multithread
let query_vec= vec ! [ "house" .to_string ( ) , "car" .to_string ( ) , "bird" .to_string ( ) , "sky" .to_string ( ) ] ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Union ;
let result_type= ResultType :: TopkCount ;
let thread_number = 4 ;
let permits = Arc :: new ( Semaphore :: new ( thread_number ) ) ;
for query in query_vec {
let permit_thread = permits . clone ( ) . acquire_owned ( ) . await . unwrap ( ) ;
let query_clone = query . clone ( ) ;
let index_arc_clone = index_arc . clone ( ) ;
let query_type_clone = query_type . clone ( ) ;
let result_type_clone = result_type . clone ( ) ;
let offset_clone = offset ;
let length_clone = length ;
tokio :: spawn ( async move {
let rlo = index_arc_clone
. search (
query_clone ,
query_type_clone ,
offset_clone ,
length_clone ,
result_type_clone ,
false ,
Vec :: new ( ) ,
)
. await ;
println ! ( "result count {}" , rlo.result_count ) ;
drop ( permit_thread ) ;
} ) ;
}arquivo JSON de índice em formato JSON, JSON delimitado por nova linha e JSON concatenado
let file_path= Path :: new ( "wiki_articles.json" ) ;
let _ =index_arc . ingest_json ( file_path ) . await ;indexe todos os arquivos PDF em diretórios e subdiretórios
ingest do console): [
{
"field" : " title " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text " ,
"boost" : 10
},
{
"field" : " body " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text "
},
{
"field" : " url " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Text "
},
{
"field" : " date " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Timestamp " ,
"facet" : true
}
] let file_path= Path :: new ( "C:/Users/johndoe/Downloads" ) ;
let _ =index_arc . ingest_pdf ( file_path ) . await ;indexar arquivo PDF
let file_path= Path :: new ( "C:/test.pdf" ) ;
let file_date= Utc :: now ( ) . timestamp ( ) ;
let _ =index_arc . index_pdf_file ( file_path ) . await ;indexar bytes do arquivo PDF
let file_date= Utc :: now ( ) . timestamp ( ) ;
let document = fs :: read ( file_path ) . unwrap ( ) ;
let _ =index_arc . index_pdf_bytes ( file_path , file_date , & document ) . await ;obter bytes de arquivo PDF
let doc_id= 0 ;
let file=index . get_file ( doc_id ) . unwrap ( ) ;limpar índice
index . clear_index ( ) ;excluir índice
index . delete_index ( ) ;fechar índice
index . close_index ( ) ;string de versão da biblioteca seekstorm
let version= version ( ) ;
println ! ( "version {}" ,version ) ;As facetas são definidas em 3 locais diferentes:
Um exemplo prático mínimo de indexação e pesquisa facetada requer apenas 60 linhas de código. Mas confundir tudo apenas com a documentação pode ser entediante. É por isso que fornecemos um exemplo de início rápido aqui:
Adicione as caixas necessárias ao seu projeto
cargo add seekstorm
cargo add tokio
cargo add serde_jsonAdicionar declarações de uso
use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;use um tempo de execução Rust assíncrono
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {criar índice
let index_path= Path :: new ( "C:/index/" ) ; //x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let mut index_arc = Arc :: new ( RwLock :: new ( index ) ) ;documentos de índice
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; submeter documentos
index_arc . commit ( ) . await ;índice de pesquisa
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let query_facets = vec ! [ QueryFacet :: String { field: "age" .to_string ( ) ,prefix: "" .to_string ( ) ,length: u16 :: MAX } ] ;
let facet_filter= Vec :: new ( ) ;
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter , query_facets , facet_filter ) . await ;exibir resultados
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_owned ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter2= Some ( highlighter ( & index_arc , highlights , result_object . query_terms ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter2 , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}exibir facetas
println ! ( "{}" , serde_json::to_string_pretty ( &result_object.facets ) .unwrap ( ) ) ;fim da função principal
Ok ( ( ) )
} Um rápido tutorial passo a passo sobre como construir um mecanismo de pesquisa da Wikipedia a partir de um corpus da Wikipedia usando o servidor SeekStorm em 5 etapas fáceis.

Baixar SeekStorm
Baixe SeekStorm do repositório GitHub
Descompacte no diretório de sua preferência e abra no código do Visual Studio.
ou alternativamente
git clone https://github.com/SeekStorm/SeekStorm.git
Construir SeekStorm
Instale o Rust (se ainda não estiver presente): https://www.rust-lang.org/tools/install
No terminal do Visual Studio Code digite:
cargo build --release
Obtenha o corpus da Wikipedia
Corpus pré-processado da Wikipedia em inglês (5.032.105 documentos, 8,28 GB descompactados). Embora wiki-articles.json tenha uma extensão .JSON, não é um arquivo JSON válido. É um arquivo de texto, onde cada linha contém um objeto JSON com atributos url, título e corpo. O formato é chamado ndjson ("JSON delimitado por nova linha").
Baixe o corpus da Wikipédia
Descompacte o corpus da Wikipedia.
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
Mova o wiki-articles.json descompactado para o diretório de lançamento
Inicie o servidor SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Indexação
Digite 'ingest' na linha de comando do servidor SeekStorm em execução:
ingest
Isso cria o índice de demonstração e indexa o arquivo local da Wikipedia.
Comece a pesquisar na WebUI incorporada
Abra a UI da Web incorporada no navegador: http://127.0.0.1
Insira uma consulta na caixa de pesquisa
Testando os terminais da API REST
Abra src/seekstorm_server/test_api.rest no VSC junto com a extensão VSC "Rest client" para executar chamadas de API e inspecionar respostas
exemplos de endpoints de API interativos
Defina a 'chave de API individual' em test_api.rest para a chave de API exibida no console do servidor quando você digitou 'índice' acima.
Remover índice de demonstração
Digite 'delete' na linha de comando do servidor SeekStorm em execução:
delete
Servidor de desligamento
Digite 'quit' na linha de comando do servidor SeekStorm em execução.
quit
Personalização
Você quer usar algo semelhante para o seu próprio projeto? Dê uma olhada na documentação de ingestão e UI da web.
Um rápido tutorial passo a passo sobre como construir um mecanismo de pesquisa de PDF a partir de um diretório que contém arquivos PDF usando o servidor SeekStorm.
Torne todos os seus artigos científicos, e-books, currículos, relatórios, contratos, documentação, manuais, cartas, extratos bancários, faturas, notas de entrega pesquisáveis - em casa ou na sua organização.
Construir SeekStorm
Instale o Rust (se ainda não estiver presente): https://www.rust-lang.org/tools/install
No terminal do Visual Studio Code digite:
cargo build --release
Baixar PDFium
Baixe e copie a biblioteca Pdfium para a mesma pasta que seekstorm_server.exe: https://github.com/bblanchon/pdfium-binaries
Inicie o servidor SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Indexação
Escolha um diretório que contenha os arquivos PDF que você deseja indexar e pesquisar, por exemplo, seus documentos ou diretório de download.
Digite 'ingest' na linha de comando do servidor SeekStorm em execução:
ingest C:UsersJohnDoeDownloads
Isso cria o pdf_index e indexa todos os arquivos PDF do diretório especificado, incluindo subdiretórios.
Comece a pesquisar na WebUI incorporada
Abra a UI da Web incorporada no navegador: http://127.0.0.1
Insira uma consulta na caixa de pesquisa
Remover índice de demonstração
Digite 'delete' na linha de comando do servidor SeekStorm em execução:
delete
Servidor de desligamento
Digite 'quit' na linha de comando do servidor SeekStorm em execução.
quit
Pesquisa de texto completo em 30 milhões de postagens do Hacker News E páginas da web vinculadas
DeepHN.org
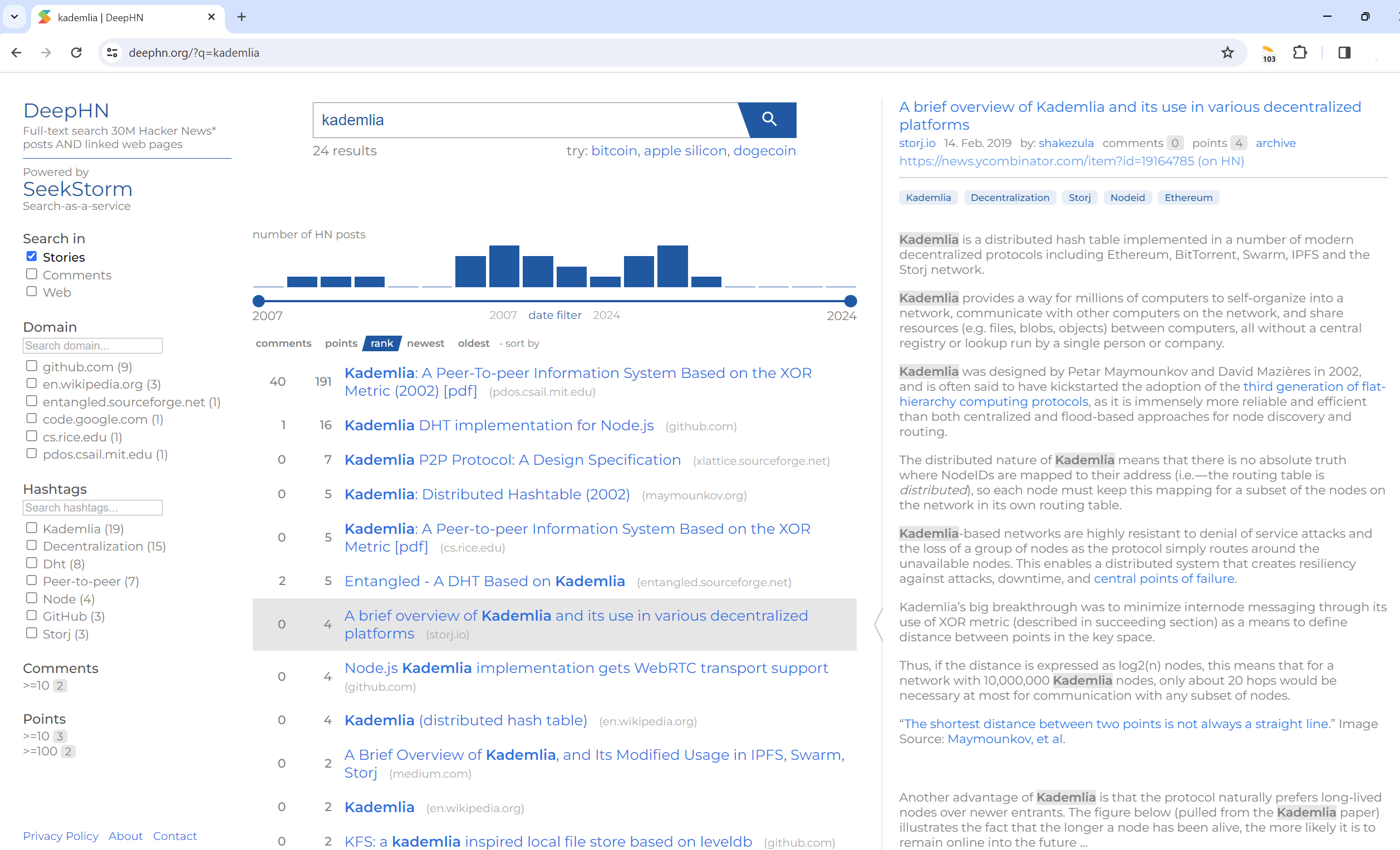
A demonstração do DeepHN ainda é baseada na base de código SeekStorm C#.
No momento, estamos portando todos os recursos ausentes necessários.
Veja o roteiro abaixo.
A porta Rust ainda não está completa. Os seguintes recursos estão atualmente portados.
Portando
Melhorias
Novos recursos


