auctus
1.0.0
Este projeto é um rastreador da web e mecanismo de busca para conjuntos de dados, destinado especificamente a tarefas de aumento de dados em aprendizado de máquina. É capaz de encontrar conjuntos de dados em diferentes repositórios e indexá-los para recuperação posterior.
A documentação está disponível aqui
Está dividido em vários componentes:
datamart_geo . Contém dados sobre áreas administrativas extraídos do Wikidata e do OpenStreetMap. Ele reside em seu próprio repositório e é usado aqui como um submódulo.datamart_profiler . Isso pode ser instalado por clientes e permitirá que a biblioteca cliente crie perfis de conjuntos de dados localmente em vez de enviá-los ao servidor. Também é usado pelos serviços apiserver e profiler.datamart_materialize . Isso é usado para materializar o conjunto de dados das várias fontes que o Auctus suporta. Pode ser instalado por clientes, o que lhes permitirá materializar conjuntos de dados localmente em vez de usar o servidor como proxy.datamart_augmentation . Isso realiza a junção ou união de dois conjuntos de dados e é usado pelo serviço apiserver, mas poderia ser usado de forma independente.datamart_core . Contém código comum para serviços. Usado apenas para os componentes do servidor. O código de bloqueio do sistema de arquivos é separado como datamart_fslock por motivos de desempenho (é necessário importar rapidamente).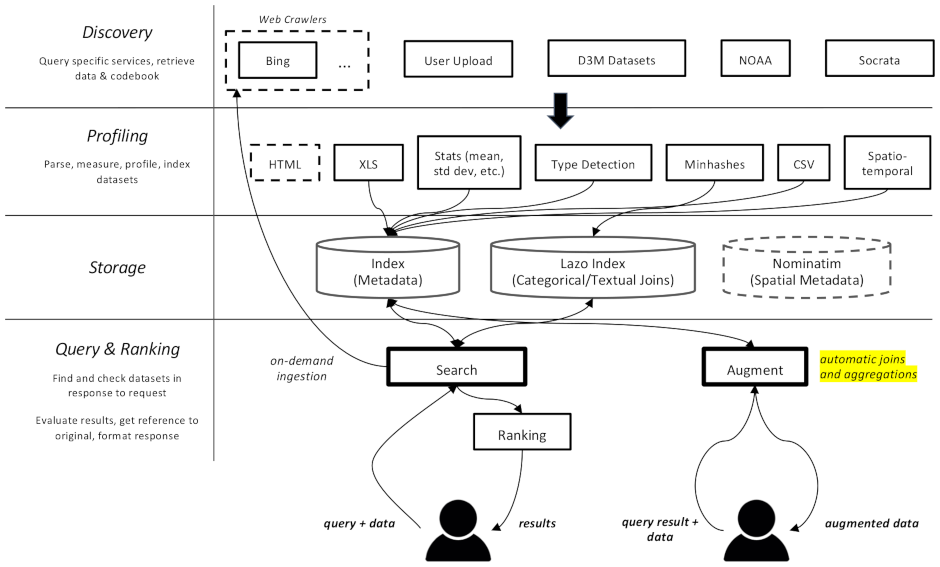
Elasticsearch é usado como índice de pesquisa, armazenando um documento por conjunto de dados conhecido.
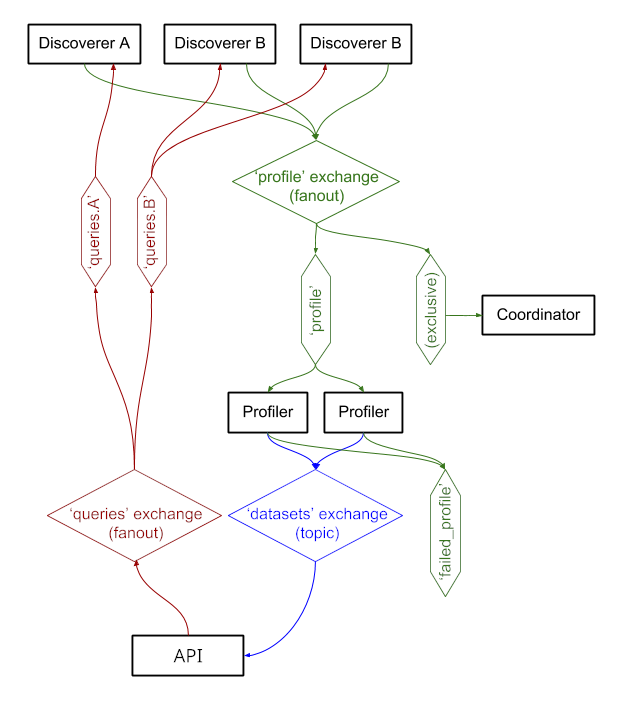
Os serviços trocam mensagens por meio do RabbitMQ , permitindo-nos ter padrões complexos de mensagens com semântica de enfileiramento e novas tentativas, e padrões complexos, como consulta sob demanda.
O sistema está atualmente em execução em https://auctus.vida-nyu.org/. Você pode ver o status do sistema em https://grafana.auctus.vida-nyu.org/.
Para implantar o sistema localmente usando docker-compose, siga estas etapas:
Certifique-se de ter verificado o submódulo com git submodule init && git submodule update
Certifique-se de ter o Git LFS instalado e configurado ( git lfs install )
Copie env.default para .env e atualize as variáveis lá. Talvez você queira atualizar a senha para uma implantação de produção.
Certifique-se de que seu nó esteja configurado para executar o Elasticsearch. Você provavelmente terá que aumentar o limite do mmap.
O API_URL é o URL no qual os contêineres do apiserver ficarão visíveis para os clientes. Em uma implantação de produção, esta é provavelmente uma URL HTTPS pública. Pode ser a mesma URL em que o componente "coordenador" será servido se estiver usando um proxy reverso (consulte nginx.conf).
Para executar scripts localmente, você pode carregar as variáveis de ambiente em seu shell executando: . scripts/load_env.sh (são scripts de espaço de ponto... )
Execute scripts/setup.sh para inicializar os volumes de dados. Isso definirá as permissões corretas nos volumes/ subdiretórios.
Se você quiser começar do zero, você pode excluir volumes/ mas certifique-se de executar scripts/setup.sh novamente depois para definir as permissões.
$ docker-compose build --build-arg version=$(git describe) apiserver
$ docker-compose up -d elasticsearch rabbitmq redis minio lazo
Isso levará alguns segundos para começar a funcionar. Então você pode iniciar os outros componentes:
$ docker-compose up -d cache-cleaner coordinator profiler apiserver apilb frontend
Você pode usar a opção --scale para iniciar mais contêineres de perfil ou apiserver, por exemplo:
$ docker-compose up -d --scale profiler=4 --scale apiserver=8 cache-cleaner coordinator profiler apiserver apilb frontend
Portas:
$ scripts/docker_import_snapshot.sh
Isso fará download de um dump do Elasticsearch de auctus.vida-nyu.org e o importará para seu contêiner local do Elasticsearch.
$ docker-compose up -d socrata zenodo
$ docker-compose up -d elasticsearch_exporter prometheus grafana
O Prometheus está configurado para localizar automaticamente os contêineres (consulte prometheus.yml)
Uma imagem RabbitMQ personalizada é usada, com plug-ins adicionados (gerenciamento e prometheus).


