VSA
1.0.0
[Página do projeto] [?Papel] [?Hugging Face Space] [Model Zoo] [Introdução] [?Vídeo]

git clone https://github.com/cnzzx/VSA.git
cd VSA
conda create -n vsa python=3.10
conda activate vsa
cd models/LLaVA
pip install -e .
pip install -r requirements.txt
A demonstração local é baseada em gradio e você pode simplesmente executar:
python app.py
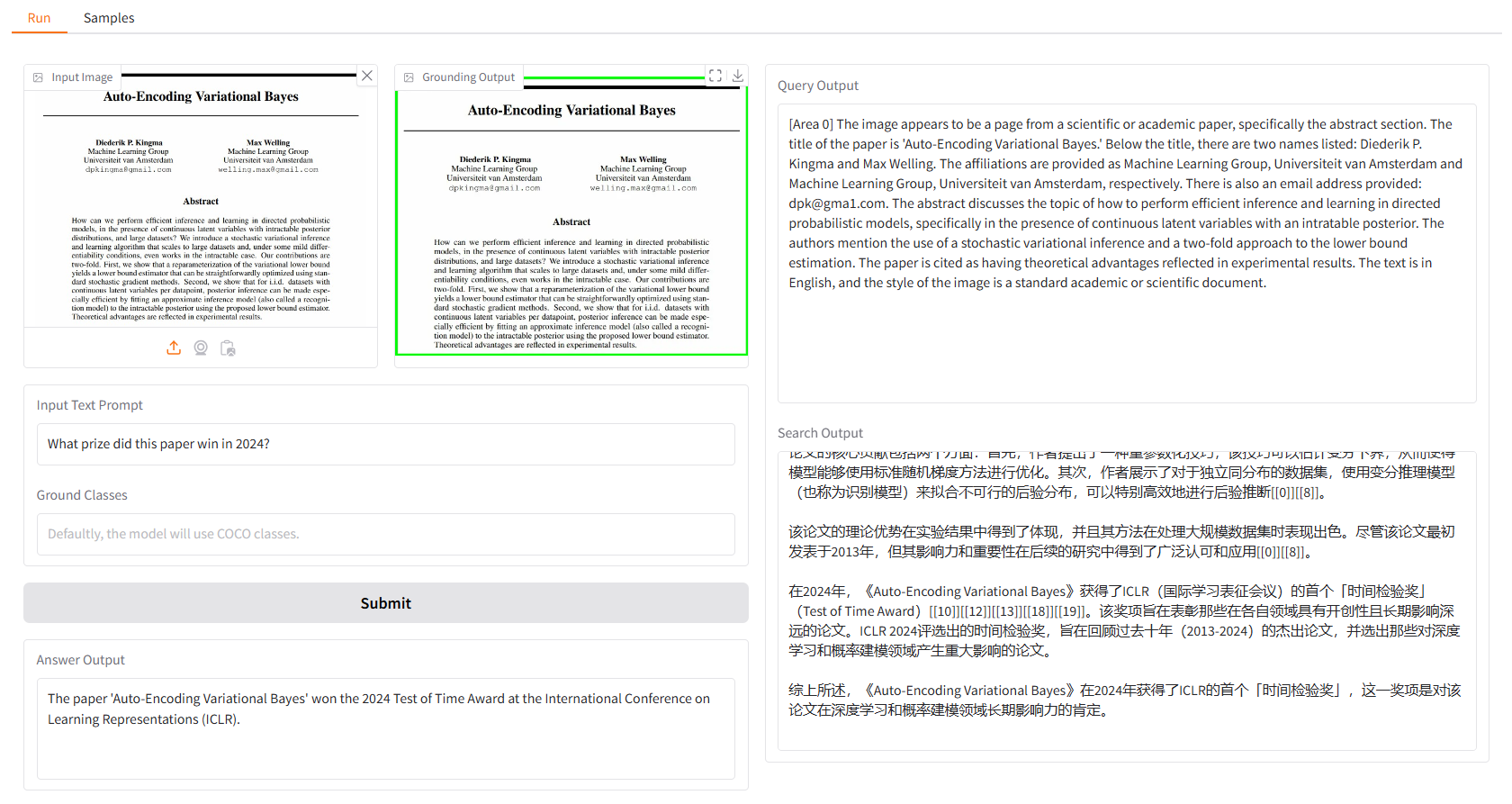
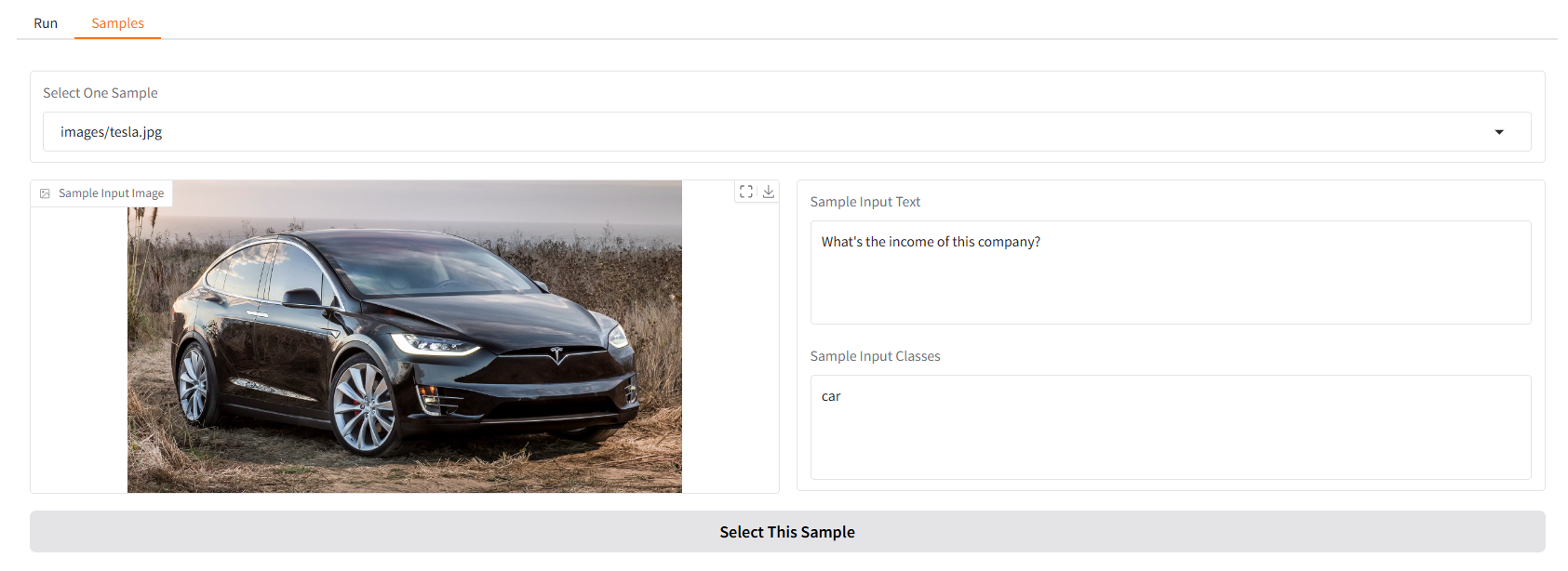
Fornecemos alguns exemplos para você começar. Na IU "Amostras", você pode selecionar uma no painel "Amostras", clicar em "Selecionar esta amostra" e você descobrirá que a entrada da amostra já foi preenchida na IU "Executar".
Você também pode conversar com nosso Vision Search Assistant no terminal executando.
python cli.py
--vlm-model "liuhaotian/llava-v1.6-vicuna-7b"
--ground-model "IDEA-Research/grounding-dino-base"
--search-model "internlm/internlm2_5-7b-chat"
--vlm-load-4bit
Em seguida, selecione uma imagem e digite sua pergunta.
Este projeto é lançado sob a licença Apache 2.0.
O Vision Search Assistant é muito inspirado nas seguintes contribuições notáveis para a comunidade de código aberto: GroundingDINO, LLaVA, MindSearch.
Se você achar este projeto útil em sua pesquisa, considere citar:
@article{zhang2024visionsearchassistantempower,
title={Vision Search Assistant: Empower Vision-Language Models as Multimodal Search Engines},
author={Zhang, Zhixin and Zhang, Yiyuan and Ding, Xiaohan and Yue, Xiangyu},
journal={arXiv preprint arXiv:2410.21220},
year={2024}
}


