ndvr
1.0.0
2ª posição no Hackathon de Pesquisa Neural?
Temos testemunhado um crescimento explosivo de dados de vídeo em uma variedade de sites de compartilhamento de vídeo, com bilhões de vídeos disponíveis na Internet. Torna-se um grande desafio realizar recuperação de vídeo quase duplicada (NDVR) a partir de um banco de dados de vídeo em grande escala. O NDVR visa recuperar vídeos quase duplicados de um enorme banco de dados de vídeos, onde vídeos quase duplicados são definidos como vídeos visualmente próximos dos vídeos originais.
Os usuários têm um forte incentivo para copiar um vídeo curto em alta e enviar uma versão aumentada para chamar a atenção. Com o crescimento dos vídeos curtos, surgem novas dificuldades e desafios para a detecção de vídeos curtos quase duplicados.
Aqui, construímos uma solução de Pesquisa Neural usando Jina para resolver o desafio do NDVR.
Índice

Exemplo de vídeos de candidatos fortemente positivos. Linha superior: lateralmente manchada, filtrada por cor e lavada com água. Linha do meio: tela horizontal alterada para tela vertical com grandes margens pretas. Linha inferior: girada
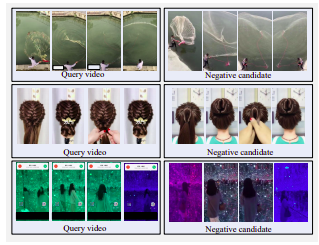
Exemplo de vídeos fortemente negativos. Todos os candidatos são visualmente semelhantes à consulta, mas não são quase duplicados.
Existem três estratégias para selecionar vídeos candidatos:
Decidimos adotar a estratégia de Recuperação Transformada devido à restrição de tempo e recursos. Em aplicações reais, os usuários copiariam vídeos de tendências para incentivos pessoais. Os usuários geralmente optam por modificar ligeiramente seus vídeos copiados para ignorar a detecção. Essas modificações contêm corte de vídeo, inserção de bordas e assim por diante.
Para imitar esse comportamento do usuário, definimos uma transformação temporal, ou seja, aceleração de vídeo, e três transformações espaciais, ou seja, corte de vídeo, inserção de borda preta e rotação de vídeo.
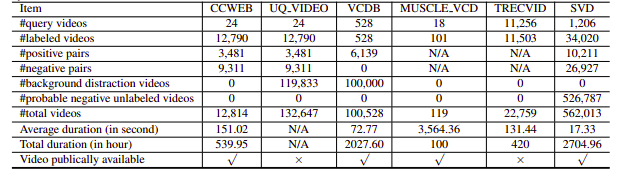
Infelizmente, os conjuntos de dados NDVR pesquisados eram de baixa resolução ou enormes, ou específicos de domínio ou não estavam disponíveis publicamente (também contatamos alguns pessoalmente). Portanto, decidimos criar nosso pequeno conjunto de dados personalizado para fazer experiências.
pip install --upgrade -r requirements.txtbash ./get_data.shpython app.py -t indexO índice Flow é definido da seguinte forma:
!Flow
with :
logserver : false
pods :
chunk_seg :
uses : craft/craft.yml
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
tf_encode :
uses : encode/encode.yml
needs : chunk_seg
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
doc_idx :
uses : index/doc.yml
needs : gateway
join_all :
uses : _merge
needs : [doc_idx, chunk_idx]
read_only : trueIsso se divide nas seguintes etapas:
Aqui usamos um arquivo YAML para definir um fluxo e usá-lo para indexar os dados. A função index usa um parâmetro input_fn que usa um Iterator para passar caminhos de arquivo, que serão posteriormente agrupados em um IndexRequest e enviados ao Flow.
DATA_BLOB = "./index-videos/*.mp4"
if task == "index" :
f = Flow (). load_config ( "flow-index.yml" )
with f :
f . index ( input_fn = input_index_data ( DATA_BLOB , size = num_docs ), batch_size = 2 ) def input_index_data ( patterns , size ):
def iter_file_exts ( ps ):
return it . chain . from_iterable ( glob . iglob ( p , recursive = True ) for p in ps )
d = 0
if isinstance ( patterns , str ):
patterns = [ patterns ]
for g in iter_file_exts ( patterns ):
yield g . encode ()
d += 1
if size is not None and d > size :
break python app.py -t query Você pode então abrir o Jinabox com o endpoint personalizado http://localhost:45678/api/search
A consulta Flow é definida da seguinte forma:
!Flow
with :
logserver : true
read_only : true # better add this in the query time
pods :
chunk_seg :
uses : craft/index-craft.yml
parallel : $PARALLEL
tf_encode :
uses : encode/encode.yml
parallel : $PARALLEL
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
polling : all
uses_reducing : _merge_all
timeout_ready : 100000 # larger timeout as in query time will read all the data
ranker :
uses : BiMatchRanker
doc_idx :
uses : index/doc.ymlO fluxo de consulta se divide nas seguintes etapas:


