CrawlerTutorial
1.0.0
Quando navegamos na Internet, muitas vezes vemos uma variedade de conteúdos interessantes, como notícias, produtos, vídeos, fotos, etc. Mas se você quiser coletar uma grande quantidade de informações específicas dessas páginas da web, as operações manuais serão demoradas e trabalhosas.
Neste momento, o web crawler (Web Crawler) vem a calhar! Simplificando, um rastreador da web é um programa que pode imitar o comportamento de um navegador humano e rastrear automaticamente informações da web. Usando os recursos de automação deste programa, podemos facilmente "rastrear" os dados de nosso interesse no site e, em seguida, armazenar esses dados para análises futuras.
A maneira como um rastreador da web geralmente funciona é primeiro enviar uma solicitação HTTP ao site de destino, depois obter a resposta HTML do site, analisar o conteúdo da página e, em seguida, extrair dados úteis. Por exemplo, se quisermos coletar o título, autor, horário e outras informações de artigos no fórum de fofocas do PTT, podemos usar a tecnologia de rastreador da web para capturar automaticamente essas informações e armazená-las. Desta forma, você pode obter as informações necessárias sem navegar manualmente no site.
Os rastreadores da Web têm muitas aplicações práticas, como:
É claro que, ao usar rastreadores da web, precisamos respeitar os termos de uso e a política de privacidade do site e não podemos rastrear informações que violem os regulamentos do site. Ao mesmo tempo, para garantir o funcionamento normal do site, também precisamos projetar estratégias de rastreamento adequadas para evitar carga excessiva no site.
Este tutorial usa Python3 e usará pip para instalar os pacotes necessários. Os seguintes pacotes precisam ser instalados:
requests : usado para enviar e receber solicitações e respostas HTTP.requests_html : usado para analisar e rastrear elementos em HTML.rich : permite que as informações sejam enviadas lindamente para o console, como exibir uma bela mesa.lxml ou PyQuery : usado para analisar elementos em HTML.Use as instruções a seguir para instalar esses pacotes:
pip install requests requests_html rich lxml PyQueryNo capítulo básico, apresentaremos brevemente como coletar informações da página PTT, como título do artigo, autor e horário.
Vamos usar os artigos de leitura de versão do PTT como alvos do rastreador!
Ao rastrear uma página da web, usamos a função requests.get() para simular o navegador enviando uma solicitação HTTP GET para “navegar” na página da web. Esta função retornará um objeto requests.Response , que contém o conteúdo da resposta da página da web. No entanto, deve-se notar que este conteúdo é apresentado na forma de código-fonte de texto puro e não é renderizado pelo navegador. Podemos obtê-lo através da propriedade response.text .
import requests
# 發送 HTTP GET 請求並獲取網頁內容
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
response = requests . get ( url )
print ( response . text )
Em usos subsequentes, precisaremos usar requests_html para expandir requests Além de navegar como um navegador, também precisaremos analisar páginas da web HTML requests_html empacotará o código-fonte de texto simples em response.text para uso requests_html.HTML . Reescrever também é muito simples. Use session.get() para substituir o requests.get() acima.
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text )Porém, quando tentamos aplicar este método à Fofoca, podemos encontrar erros. Isto porque quando navegamos pela primeira vez no fórum de fofocas, o site irá confirmar se temos mais de 18 anos, quando clicarmos para confirmar, o navegador irá gravar os cookies correspondentes para que não perguntemos novamente na próxima vez; entre novamente (você pode tentar usar o modo de navegação anônima para abrir o teste e dar uma olhada na página inicial do quadro Bagua). No entanto, para web crawlers, precisamos registrar esse cookie especial para que possamos fingir que passamos no teste dos dezoito anos enquanto navegamos.
import requests
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text ) A seguir, podemos usar o método response.html.find() para localizar o elemento e usar o seletor CSS para especificar o elemento de destino. Nesta etapa, podemos observar que na versão web do PTT, as informações do título de cada artigo estão localizadas em uma tag div com categoria r-ent . Portanto, podemos usar o seletor CSS div.r-ent para direcionar esses elementos.
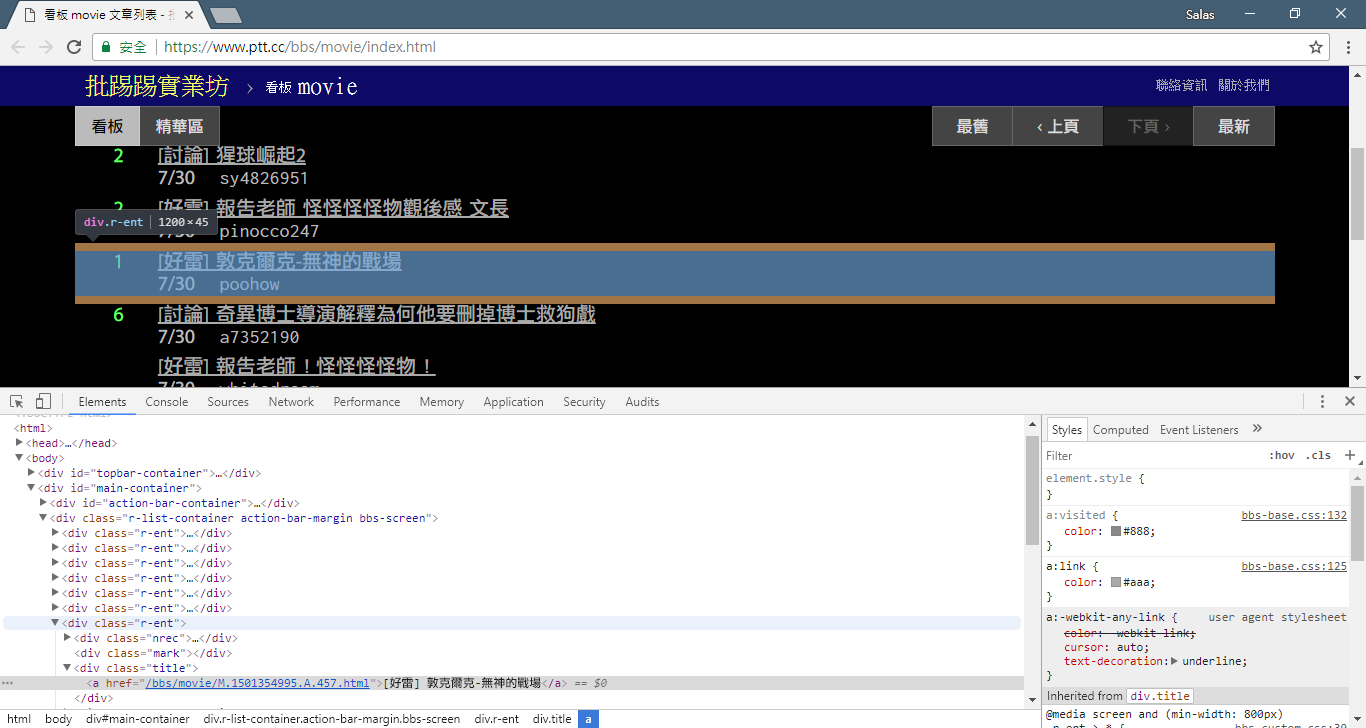
Usar o método response.html.find() retornará uma lista de elementos que atendem às condições, para que possamos usar for para processar esses elementos um por um. Dentro de cada elemento, podemos usar element.find() para analisar melhor o elemento e usar seletores CSS para especificar as informações a serem extraídas. Neste exemplo, podemos usar o seletor CSS div.title para direcionar o elemento title. Da mesma forma, podemos usar a propriedade element.text para obter o conteúdo de texto de um elemento.
Aqui está um exemplo de código usando requests_html :
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
for element in elements :
# 提取資訊... Na etapa anterior, usamos o método response.html.find() para localizar os elementos de cada artigo. Esses elementos são direcionados usando o seletor CSS div.r-ent . Você pode usar o recurso Ferramentas do desenvolvedor para observar a estrutura dos elementos de uma página da web. Após abrir a página web e pressionar a tecla F12, será exibido um painel de ferramentas do desenvolvedor, que contém a estrutura HTML da página web e outras informações.
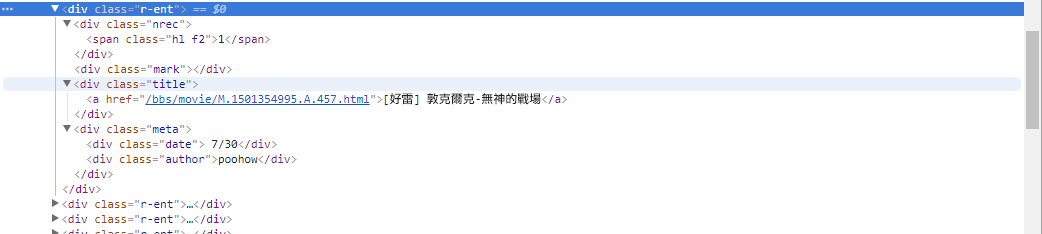
Usando as ferramentas do desenvolvedor, você pode usar o ponteiro do mouse para selecionar um elemento específico na página da web e, em seguida, visualizar a estrutura HTML do elemento, os atributos CSS e outros detalhes no painel de ferramentas do desenvolvedor. Isso ajuda a determinar qual elemento segmentar e o seletor CSS correspondente. Além disso, você pode descobrir por que o programa às vezes dá errado? ! Olhando para a versão web, descobri que quando um artigo da página era excluído, a結構do código-fonte do elemento <本文已被刪除> na página web era diferente da original! Assim, podemos fortalecê-lo ainda mais para lidar com situações em que artigos são excluídos.
Agora, vamos retornar ao código de exemplo para extração de informações usando requests_html :
import re
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
# 逐個處理每個元素
for element in elements :
# 可能會遇上文章已刪除的狀況,所以用例外處理 try-catch 包起來
try :
push = element . find ( '.nrec' , first = True ). text # 推文數
mark = element . find ( '.mark' , first = True ). text # 標記
title = element . find ( '.title' , first = True ). text # 標題
author = element . find ( '.meta > .author' , first = True ). text # 作者
date = element . find ( '.meta > .date' , first = True ). text # 發文日期
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ] # 文章網址
except AttributeError :
# 處理已經刪除的文章資訊
if '(本文已被刪除)' in title :
# e.g., "(本文已被刪除) [haudai]"
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
# e.g., "(已被cappa刪除) <edisonchu> op"
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
print ( '推文數:' , push )
print ( '標記:' , mark )
print ( '標題:' , title )
print ( '作者:' , author )
print ( '發文日期:' , date )
print ( '文章網址:' , link )
print ( '---' )Processamento de texto de saída:
Aqui podemos usar rich para exibir uma saída bonita. Primeiro, crie um objeto de tabela rich e, em seguida, substitua print no loop do código de exemplo acima por add_row na tabela. Finalmente, usamos a função print de rich para enviar corretamente a tabela para o terminal.
Resultado da execução
import rich
import rich . table
# 建立 `rich` 表格物件,設定不顯示表頭
table = rich . table . Table ( show_header = False )
# 逐個處理每個元素
for element in elements :
...
# 將每個結果新增到表格中
table . add_row ( push , title , date , author )
# 使用 rich 套件的 print 函式輸出表格
rich . print ( table )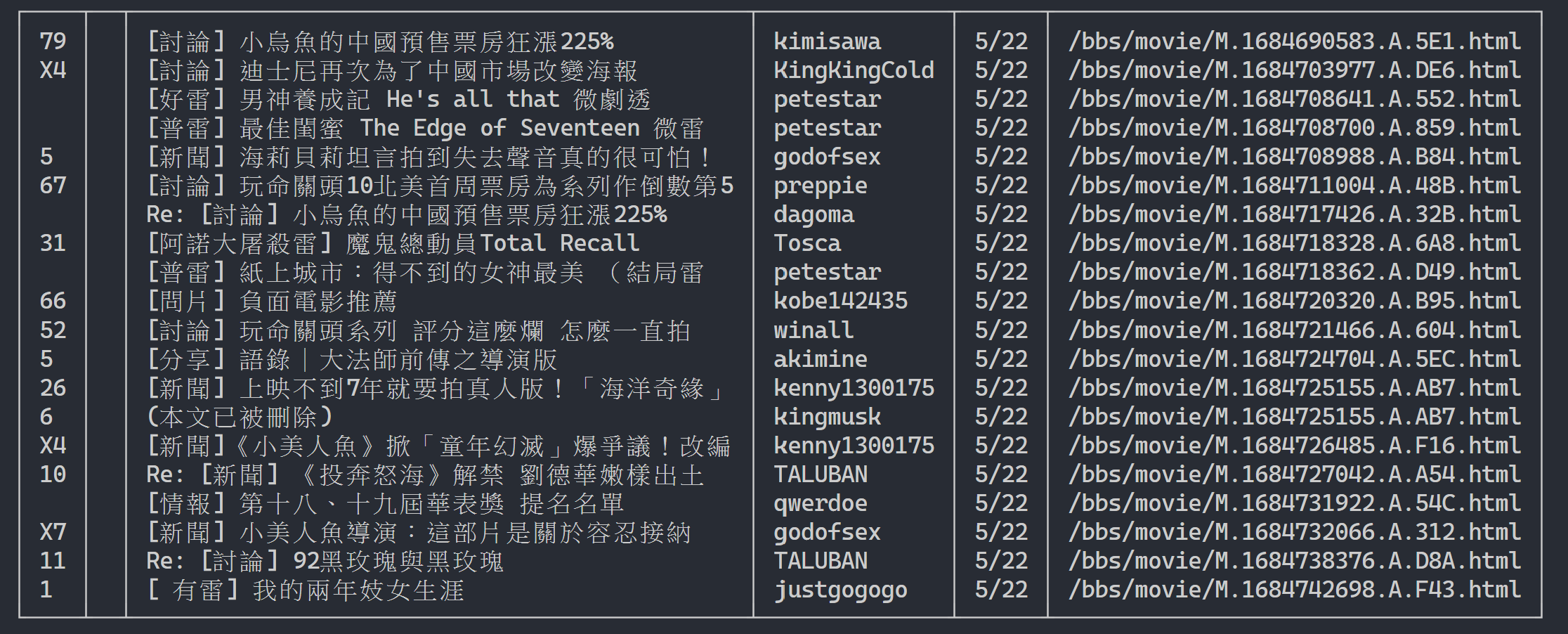
Agora usaremos o “método de observação” para encontrar o link para a página anterior. Não, não estou perguntando onde está o botão no seu navegador, mas sim a "árvore de origem" nas ferramentas do desenvolvedor. Acredito que você descobriu que o hiperlink para salto de página está localizado no elemento <a class="btn wide"> de <div class="action-bar"> . Portanto, podemos extraí-los assim:
# 控制頁面選項: 最舊/上頁/下頁/最新
controls = response . html . find ( '.action-bar a.btn.wide' )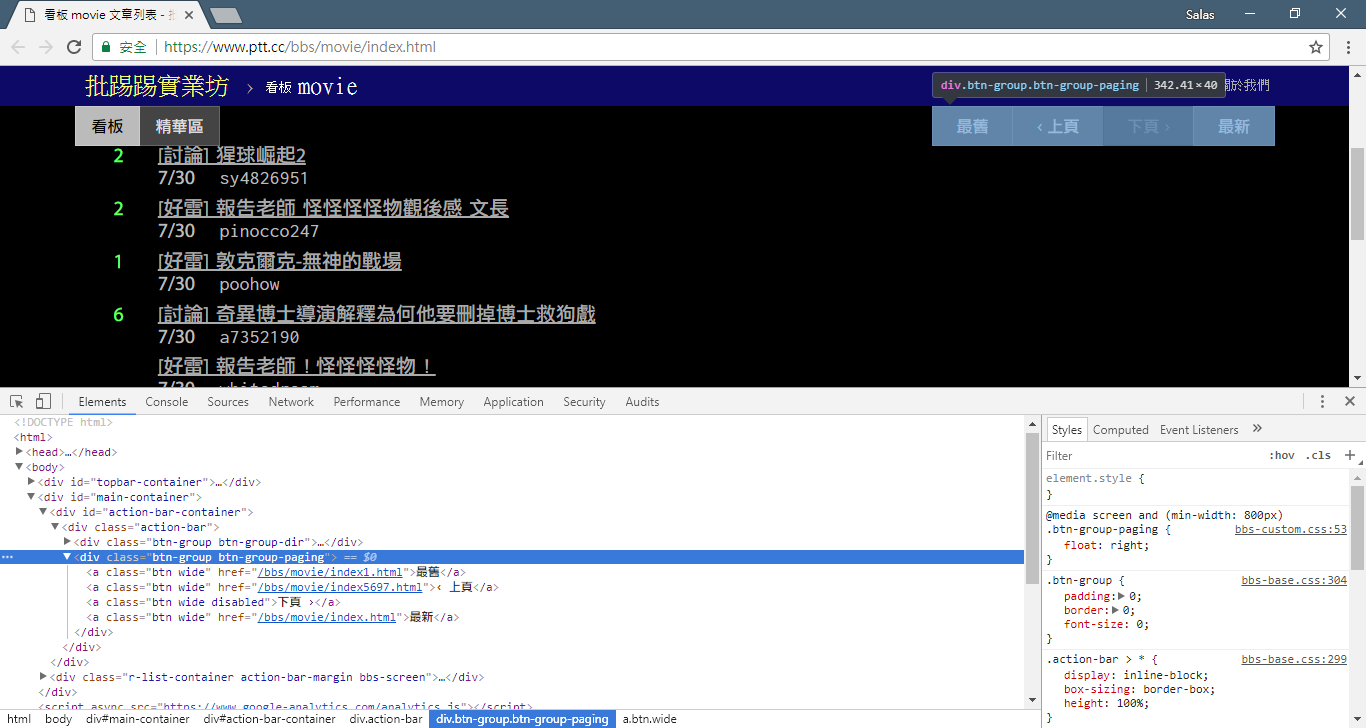
O que precisamos é da função "página anterior". Por quê? Como o PTT exibe os artigos mais recentes na frente, você deve rolar para frente se quiser obter informações.
Então, como usá-lo? Primeiro pegue o segundo href no control (o índice é 1), então pode ficar assim /bbs/movie/index3237.html e o endereço completo do site (URL) deve ser https://www.ptt.cc/ (; URL do domínio), então use urljoin() (ou conexão de string direta) para comparar e mesclar o link da página inicial do filme com o novo link em um URL completo!
import urllib . parse
def parse_next_link ( controls ):
link = controls [ 1 ]. attrs [ 'href' ]
next_page_url = urllib . parse . urljoin ( 'https://www.ptt.cc/' , link )
return next_page_url Agora vamos reorganizar a função para facilitar a explicação subsequente. Vamos mudar o exemplo de processamento de cada elemento do artigo na Etapa 3: vamos dar uma olhada nessas mensagens de título em uma função independente parse_article_entries(elements)
# 解析該頁文章列表中的元素
def parse_article_entries ( elements ):
results = []
for element in elements :
try :
push = element . find ( '.nrec' , first = True ). text
mark = element . find ( '.mark' , first = True ). text
title = element . find ( '.title' , first = True ). text
author = element . find ( '.meta > .author' , first = True ). text
date = element . find ( '.meta > .date' , first = True ). text
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ]
except AttributeError :
# 處理文章被刪除的情況
if '(本文已被刪除)' in title :
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
# 將解析結果加到回傳的列表中
results . append ({ 'push' : push , 'mark' : mark , 'title' : title ,
'author' : author , 'date' : date , 'link' : link })
return resultsA seguir, podemos lidar com conteúdo de várias páginas
# 起始首頁
url = 'https://www.ptt.cc/bbs/movie/index.html'
# 想要收集的頁數
num_page = 10
for page in range ( num_page ):
# 發送 GET 請求並獲取網頁內容
response = session . get ( url )
# 解析文章列表的元素
results = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一個連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 建立表格物件
table = rich . table . Table ( show_header = False , width = 120 )
for result in results :
table . add_row ( * list ( result . values ()))
# 輸出表格
rich . print ( table )
# 更新下面一位 URL~
url = next_page_urlResultado de saída:
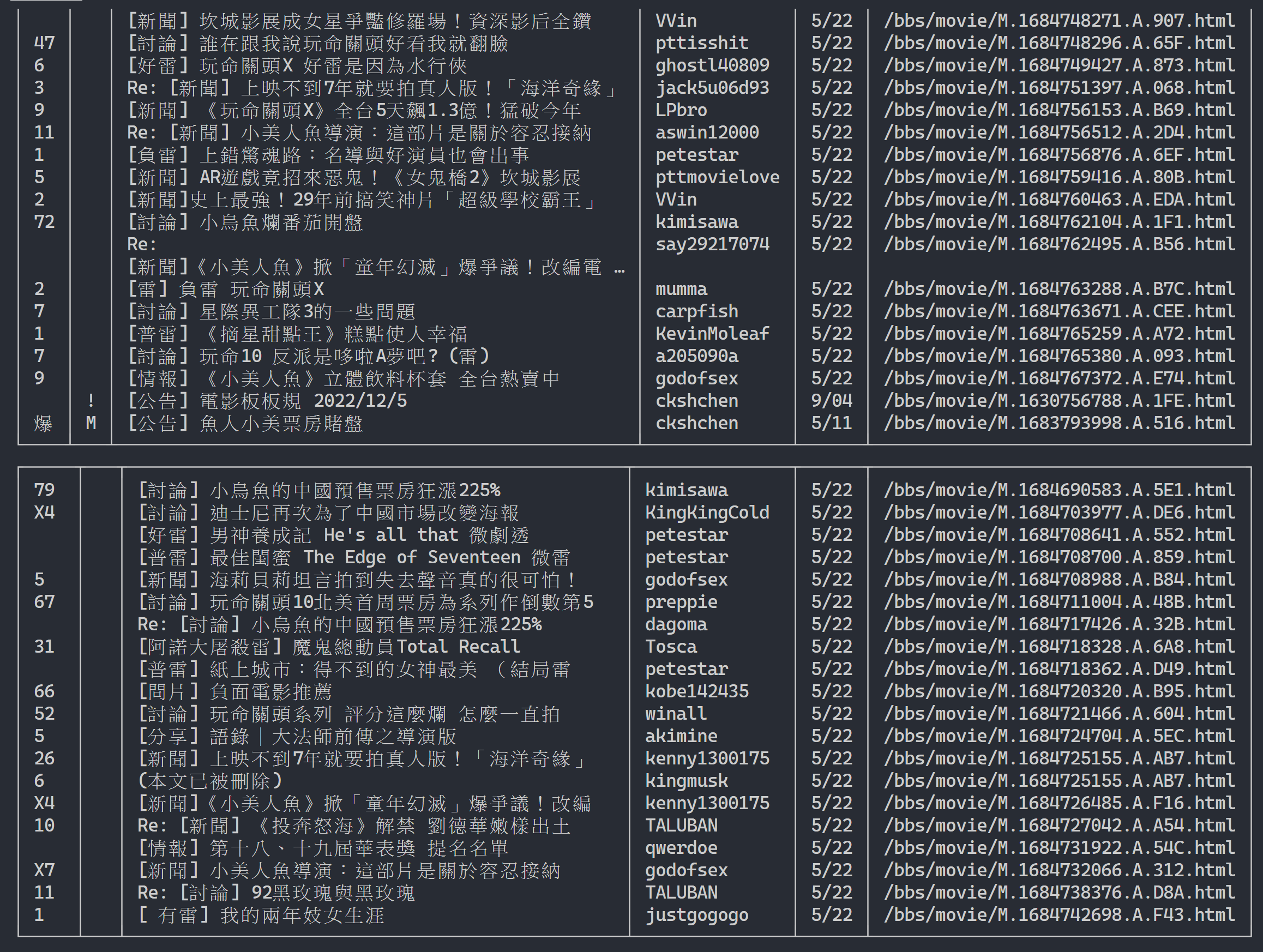
Depois de obter as informações da lista de artigos, o próximo passo é obter o conteúdo do artigo (artigo PO) (conteúdo da postagem)! link nos metadados é o link de cada artigo. Também usamos urllib.parse.urljoin para concatenar a URL completa e depois emitir HTTP GET para obter o conteúdo do artigo. Podemos observar que a tarefa de capturar o conteúdo de cada artigo é altamente repetitiva e muito adequada para processamento através de um método de paralelização.
Em Python, você pode usar multiprocessing.Pool para fazer programação de multiprocessamento de alto nível ~ Esta é a maneira mais fácil de usar multiprocessos em Python! É muito adequado para este cenário de aplicação SIMD (Dados Múltiplos de Instrução Única). Use a sintaxe da instrução with para liberar automaticamente os recursos do processo após o uso. O uso de ProcessPool também é muito simples, pool.map(function, items) , que é um pouco como o conceito de programação funcional Aplicar função a cada item e, finalmente, obter o mesmo número de listas de resultados que itens.
Usado na tarefa de rastrear o conteúdo do artigo apresentado anteriormente:
from multiprocessing import Pool
def get_posts ( post_links ):
with Pool ( processes = 8 ) as pool :
# 建立 processes pool 並指定 processes 數量為 8
# pool 中的 processes 將用於同時發送多個 HTTP GET 請求,以獲取文章內容
responses = pool . map ( session . get , post_links )
# 使用 pool.map() 方法在每個 process 上都使用 session.get(),並傳入文章連結列表 post_links 作為參數
# 每個 process 將獨立地發送一個 HTTP GET 請求取得相應的文章內容
return responses
response = session . get ( url )
# 解析文章列表的元素
metadata = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一頁的連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 一串文章的 URL
post_links = [ urllib . parse . urljoin ( url , meta [ 'link' ]) for meta in metadata ]
results = get_posts ( post_links ) # list(requests_html.HTML)
rich . print ( results ) import time
if __name__ == '__main__' :
post_links = [...]
...
start_time = time . time ()
results = get_posts ( post_links )
print ( f'花費: { time . time () - start_time :.6f }秒,共 { len ( results ) } 篇文章' )Em anexo estão os resultados experimentais:
# with 1-process
花費: 15.686177秒,共 202 篇文章
# with 8-process
花費: 3.401658秒,共 202 篇文章Percebe-se que a velocidade geral de execução foi acelerada quase cinco vezes, mas quanto mais Process melhor. Além das especificações de hardware como a CPU, depende principalmente das limitações de dispositivos externos como placas de rede e. velocidades da rede.
O código acima pode ser encontrado em ( src/basic_crawler.py )!
Novo recurso no PTT Web: Pesquisa! Finalmente disponível na versão web
Vamos também usar a versão cinematográfica do PTT como alvo do rastreador! O conteúdo pesquisável no novo recurso inclui:
Os três primeiros podem encontrar regras da nova versão do código-fonte da página e enviar solicitações, mas a pesquisa de contagem de tweets não parece ter aparecido na interface da UI da versão web, então aqui estão os parâmetros extraídos pelo autor do PTT 網站原始碼; PTT 網站原始碼. O PTT que normalmente navegamos inclui, na verdade, o servidor BBS (ou seja, BBS) e o servidor Web front-end (versão web). O servidor Web front-end é escrito em linguagem Go (Golang) e pode acessar diretamente o back-end. Dados BBS e uso O modo geral de interação do site renderiza o conteúdo em uma página da web para navegação.
Na verdade, é muito simples usar essas novas funções. Você só precisa obter essas informações por meio de uma solicitação HTTP GET e do método de string de consulta padrão. O URL endpoint que fornece a função de pesquisa é /bbs/{看板名稱}/search . Basta usar a consulta correspondente para obter os resultados da pesquisa aqui. Primeiro, tome a palavra-chave title como exemplo,
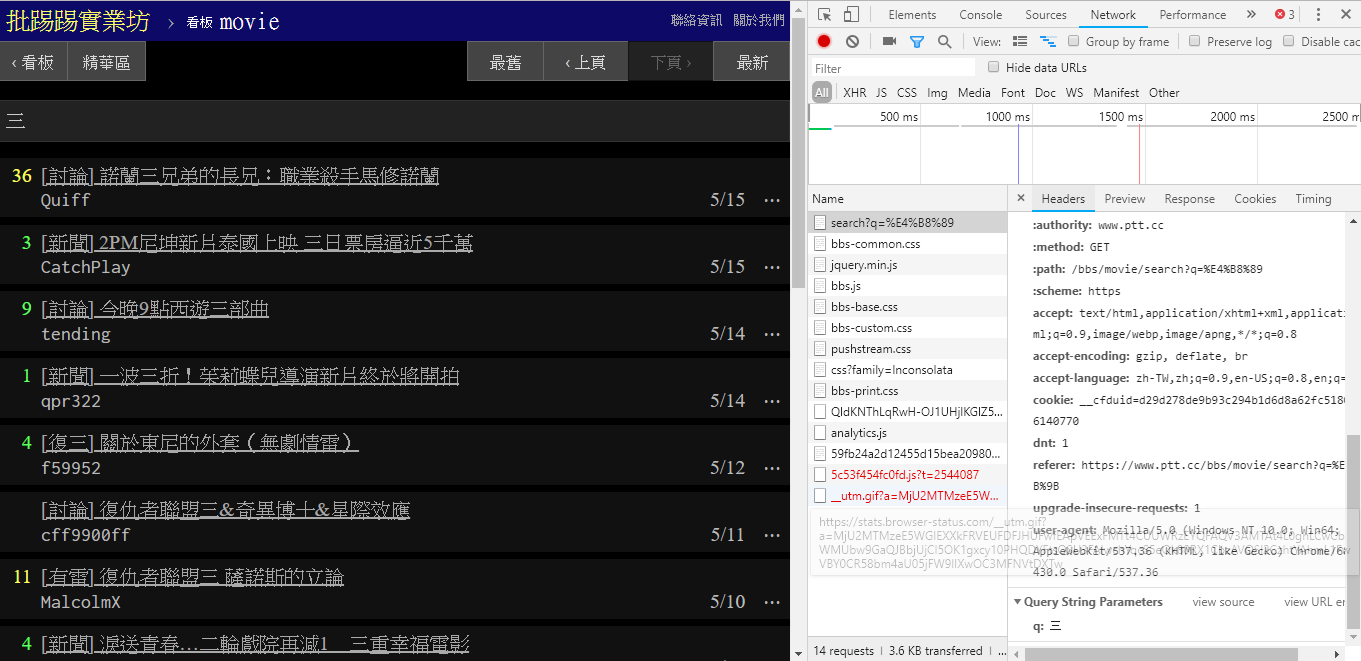
Como pode ser visto no canto inferior direito da imagem, ao pesquisar, uma solicitação GET com q=三é realmente enviada para endpoint , portanto, todo o URL completo deve ser como https://www.ptt.cc/bbs/movie/search?q=三, o URL copiado da barra de endereço pode estar no formato https://www.ptt.cc/bbs/movie/search?q=%E4%B8%89 porque o chinês foi HTML codificado, mas representa o mesmo significado. Em requests , se você quiser adicionar parâmetros de consulta adicionais, você não precisa construir manualmente o formulário de string. Você só precisa colocá-los nos parâmetros da função por meio de dict() de param= , assim:
search_endpoint_url = 'https://www.ptt.cc/bbs/movie/search'
resp = requests . get ( search_endpoint_url , params = { 'q' : '三' })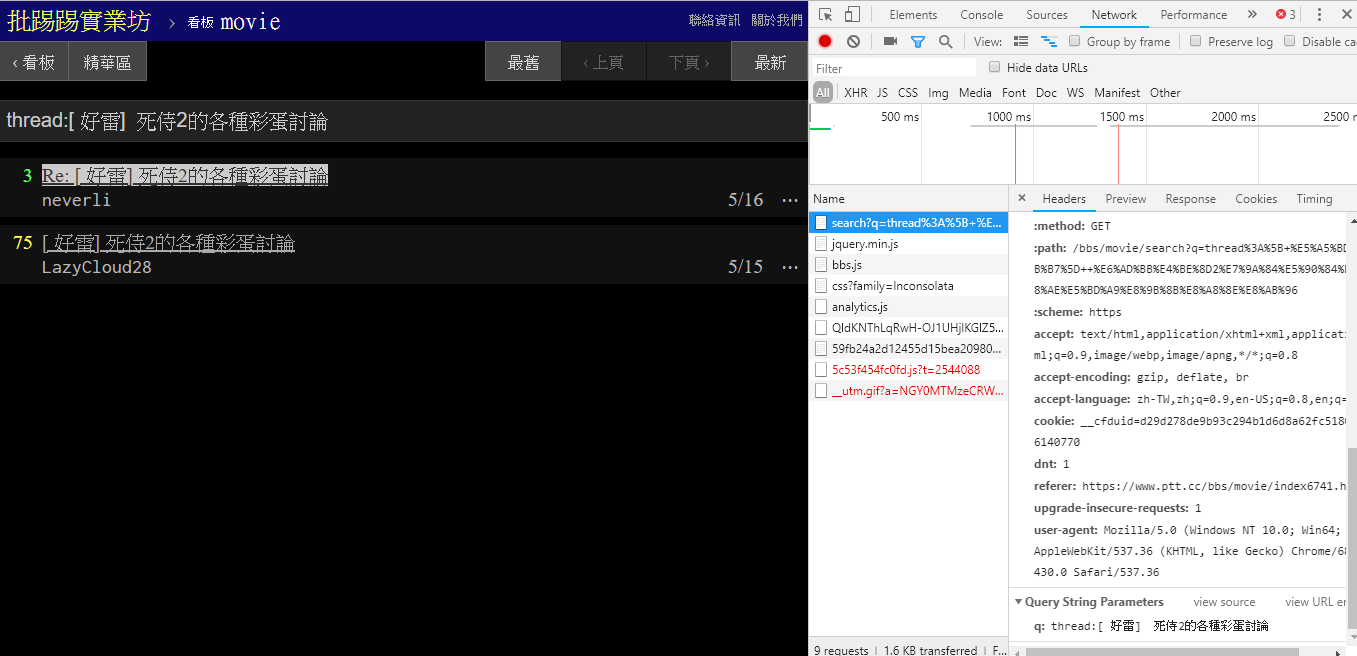
Ao pesquisar o mesmo artigo (tópico), você pode ver pelas informações no canto inferior direito que você realmente encadeia a string thread: na frente do título e envia a consulta.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'thread:[ 好雷] 死侍2的各種彩蛋討論' })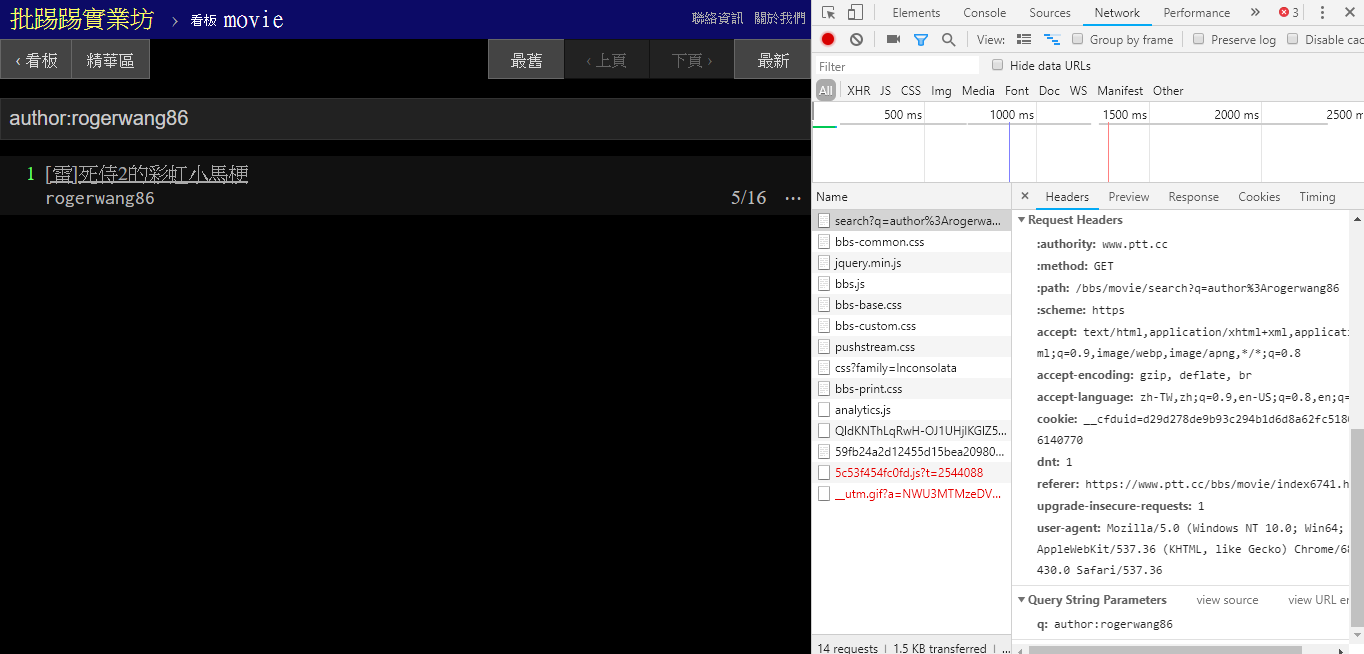
Ao pesquisar artigos com o mesmo autor (autor), também é possível perceber pelas informações no canto inferior direito que author: é concatenada com o nome do autor e em seguida a consulta é enviada.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'author:rogerwang86' })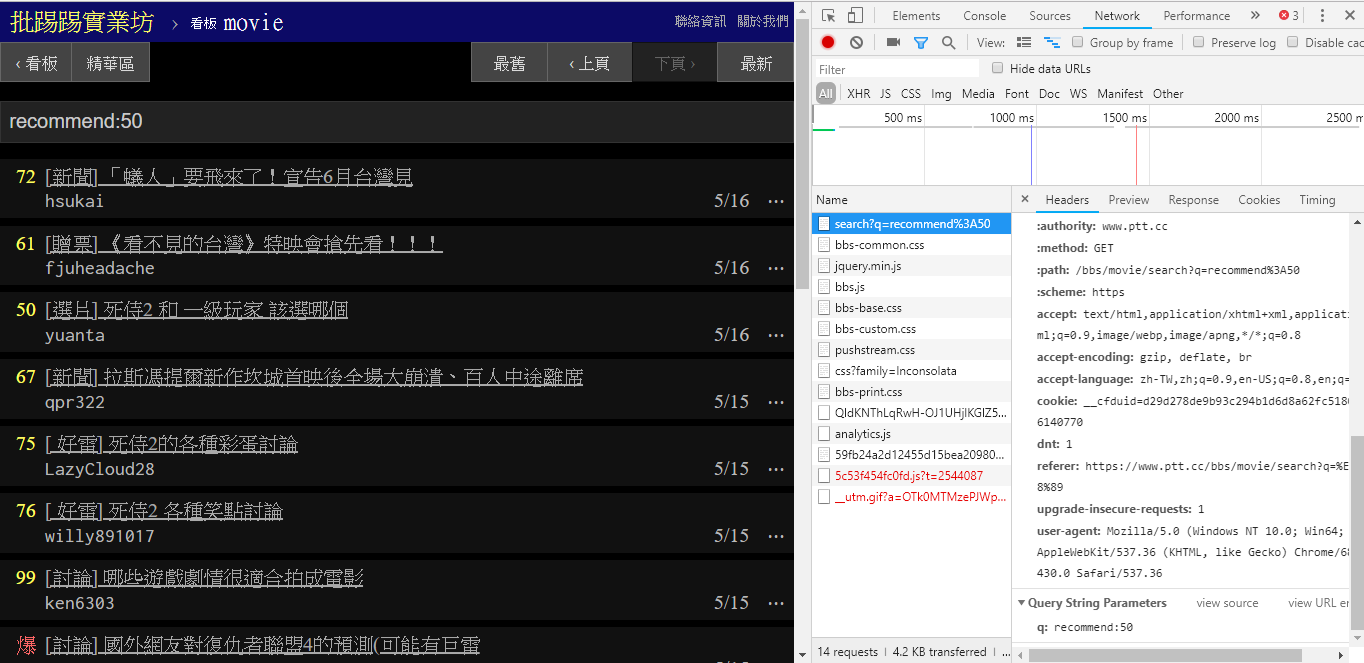
Ao pesquisar artigos com número de tweets maior que (recomendar), coloque a string recommend: com o número mínimo de tweets que deseja pesquisar e depois envie a consulta. Além disso, pode-se verificar no código-fonte do servidor Web PTT que o número de tweets só pode ser definido dentro de ±100.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })Código-fonte da função de análise da Web PTT desses parâmetros
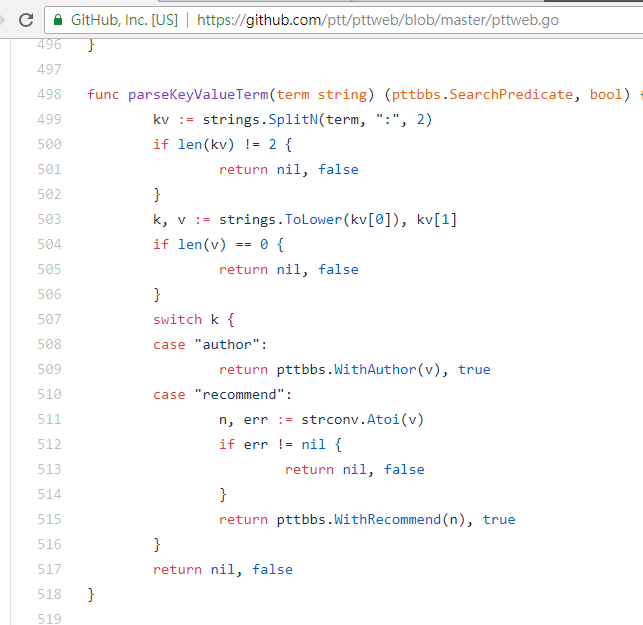
Vale ressaltar também que a apresentação final dos resultados da pesquisa é igual ao layout geral mencionado no básico, portanto você pode Don't do it again! diretamente as funções anteriores.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })
post_entries = parse_article_entries ( resp . text ) # [沿用]
metadata = [ parse_article_meta ( entry ) for entry in post_entries ] # [沿用] Existe outro parâmetro na pesquisa. O número de page é igual à pesquisa do Google. A coisa pesquisada pode ter muitas páginas, então você pode usar este parâmetro adicional para controlar qual página de resultados deseja obter sem ter que analisar o link. a página.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' , 'page' : 2 }) A integração de todas as funções anteriores no ptt-parser pode fornecer funções de linha de comando e爬蟲na forma de APIs que podem ser chamadas programaticamente.
scrapy para rastrear dados PTT de maneira estável.
Este trabalho foi produzido por leVirve e é lançado sob uma licença Creative Commons Atribuição 4.0 Internacional.


