reflexion
1.0.0
Este repositório contém o código, demonstrações e arquivos de log para reflexion : Agentes de linguagem com aprendizagem por reforço verbal de Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, Shunyu Yao.
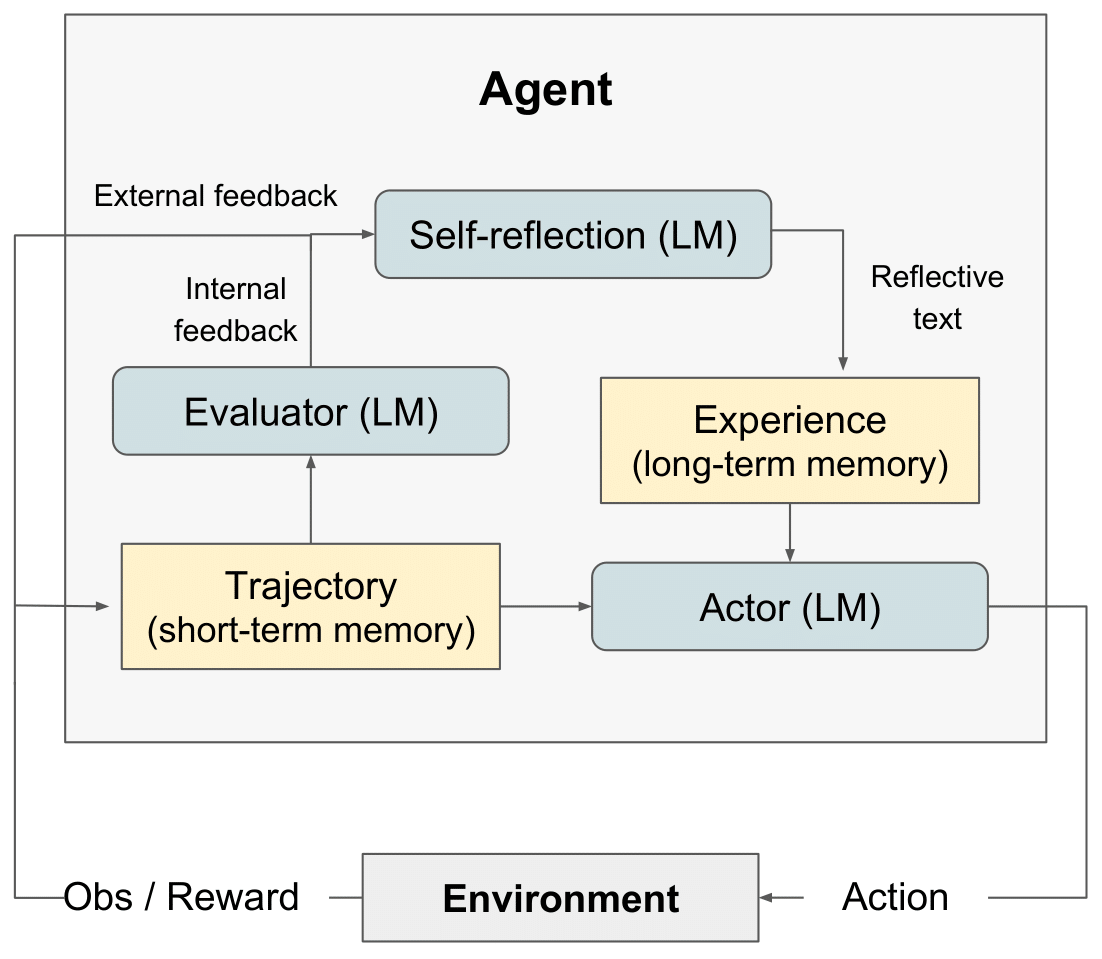 diagrama RL de reflexão" style="max-width: 100%;">
diagrama RL de reflexão" style="max-width: 100%;">
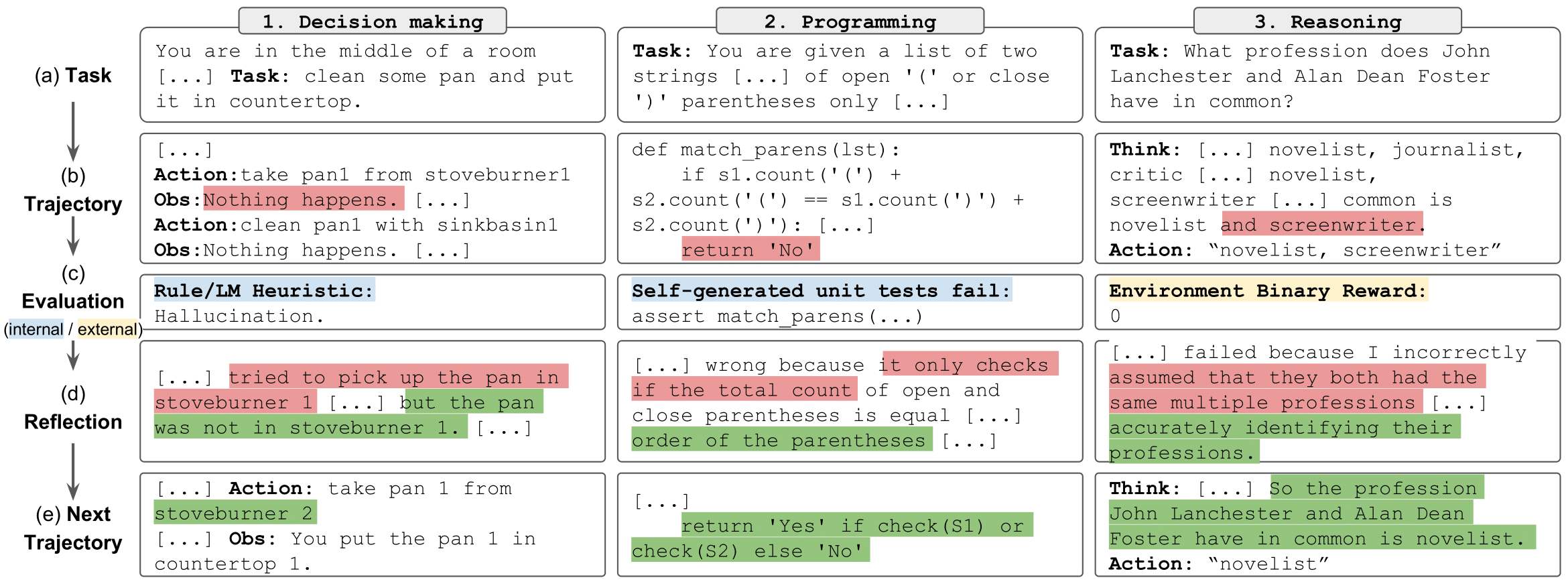 tarefas de reflexão" style="largura máxima: 100%;">
tarefas de reflexão" style="largura máxima: 100%;">
Lançamos o LeetcodeHardGym aqui
Fornecemos um conjunto de cadernos para executar, explorar e interagir facilmente com os resultados dos experimentos de raciocínio. Cada experimento consiste em uma amostra aleatória de 100 perguntas do conjunto de dados do distrator HotPotQA. Cada questão da amostra é tentada por um agente com um tipo e estratégia reflexion específicos.
Para começar:
git clone https://github.com/noahshinn/reflexion && cd ./hotpotqa_runspip install -r requirements.txtOPENAI_API_KEY como sua chave de API OpenAI: export OPENAI_API_KEY= < your key > O tipo de agente é determinado pelo notebook que você escolhe executar. Os tipos de agentes disponíveis incluem:
ReAct - Agente ReAct
CoT_context - Agente CoT dado contexto de apoio sobre a questão
CoT_no_context - Agente CoT sem contexto de apoio sobre a questão
O notebook para cada tipo de agente está localizado no diretório ./hotpot_runs/notebooks .
Cada caderno permite especificar a estratégia reflexion a ser utilizada pelos agentes. As estratégias reflexion disponíveis, definidas em um Enum , incluem:
reflexion Strategy.NONE - O agente não recebe nenhuma informação sobre sua última tentativa.
reflexion Strategy.LAST_ATTEMPT - O agente recebe o traço de raciocínio de sua última tentativa na questão como contexto.
reflexion Strategy. reflexion - O agente recebe sua autorreflexão na última tentativa como contexto.
reflexion Strategy.LAST_ATTEMPT_AND_ reflexion - O agente recebe como contexto seu traço de raciocínio e auto-reflexão na última tentativa.
Clone este repositório e vá para o diretório AlfWorld
git clone https://github.com/noahshinn/reflexion && cd ./alfworld_runs Especifique os parâmetros de execução em ./run_ reflexion .sh . num_trials : número de etapas de aprendizado iterativo num_envs : número de pares tarefa-ambiente por teste run_name : o nome para esta execução use_memory : use memória persistente para armazenar autorreflexões (desative para executar uma execução de linha de base) is_resume : use o diretório de registro para retomar uma execução anterior resume_dir : o diretório de registro a partir do qual a execução anterior será retomada start_trial_num : se for retomada a execução, então o número de teste da qual para começar
Execute o teste
./run_ reflexion .sh Os logs serão enviados para ./root/<run_name> .
Devido à natureza desses experimentos, pode não ser viável para desenvolvedores individuais executar novamente os resultados, pois o GPT-4 tem acesso limitado e cobranças significativas de API. Todas as execuções do papel e resultados adicionais são registrados em ./alfworld_runs/root para tomada de decisão, ./hotpotqa_runs/root para raciocínio e ./programming_runs/root para programação
Confira o código do código original aqui
Leia uma postagem do blog aqui
Confira uma implementação interessante de previsão de tipo aqui: OpenTau
Para todas as perguntas, entre em contato com [email protected]
@misc { shinn2023 reflexion ,
title = { reflexion : Language Agents with Verbal Reinforcement Learning } ,
author = { Noah Shinn and Federico Cassano and Edward Berman and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao } ,
year = { 2023 } ,
eprint = { 2303.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.AI }
}

