metal flash attention
v1.0.1
Este repositório transporta a implementação oficial do FlashAttention para o silício da Apple. É um conjunto mínimo e sustentável de arquivos de origem que reproduz o algoritmo FlashAttention.
Atenção unilateral apenas, para focar nos principais gargalos de diferentes algoritmos de atenção (pressão de registro, paralelismo). Com o algoritmo básico feito corretamente, deve ser comparativamente trivial adicionar personalizações como dispersão de blocos.
Tudo é compilado JIT em tempo de execução. Isso contrasta com a implementação anterior, que dependia de um executável incorporado no Xcode 14.2.
A passagem para trás usa menos memória que Dao-AILab/flash-attention. A implementação oficial aloca espaço para números atômicos e somas parciais. O hardware da Apple não possui atômicos FP32 nativos ( metal::atomic<float> é emulado). Ao tentar contornar a falta de suporte de hardware, foram revelados gargalos de largura de banda e paralelização no kernel anterior do FlashAttention-2. Uma passagem reversa alternativa foi projetada com maior custo de computação (7 GEMMs em vez de 5 GEMMs). Ele atinge 100% de eficiência de paralelização nas dimensões de linha e coluna da matriz de atenção. Mais importante ainda, é mais fácil de codificar e manter.
Muitas coisas malucas foram feitas para superar os gargalos de pressão dos registros. Em dimensões de cabeçote grandes (por exemplo, 256), nenhum dos blocos de matriz pode caber nos registros. Nem mesmo o acumulador consegue. Portanto, o derramamento intencional de registros é feito, mas de forma mais otimizada. Uma terceira dimensão de bloco foi adicionada ao algoritmo de atenção, que bloqueia ao longo D . A proporção dos blocos da matriz de atenção foi fortemente distorcida, para minimizar o custo da largura de banda do derramamento de registros. Por exemplo, 16-32 ao longo da dimensão de paralelização e 80-128 ao longo da dimensão transversal. Existe um grande arquivo de parâmetros que assume a dimensão D e determina quais operandos podem caber nos registradores. Em seguida, atribui um tamanho de bloco que equilibra muitos gargalos concorrentes.
O resultado final são consistentes 4.400 giga instruções por segundo no M1 Max (83% de utilização de ALU), com comprimento de sequência infinito e tamanho de cabeça infinito. Desde que a emulação BF16 esteja sendo usada para precisão mista ( bfloat do Metal possui arredondamento compatível com IEEE, uma grande sobrecarga em chips mais antigos sem hardware BF16).
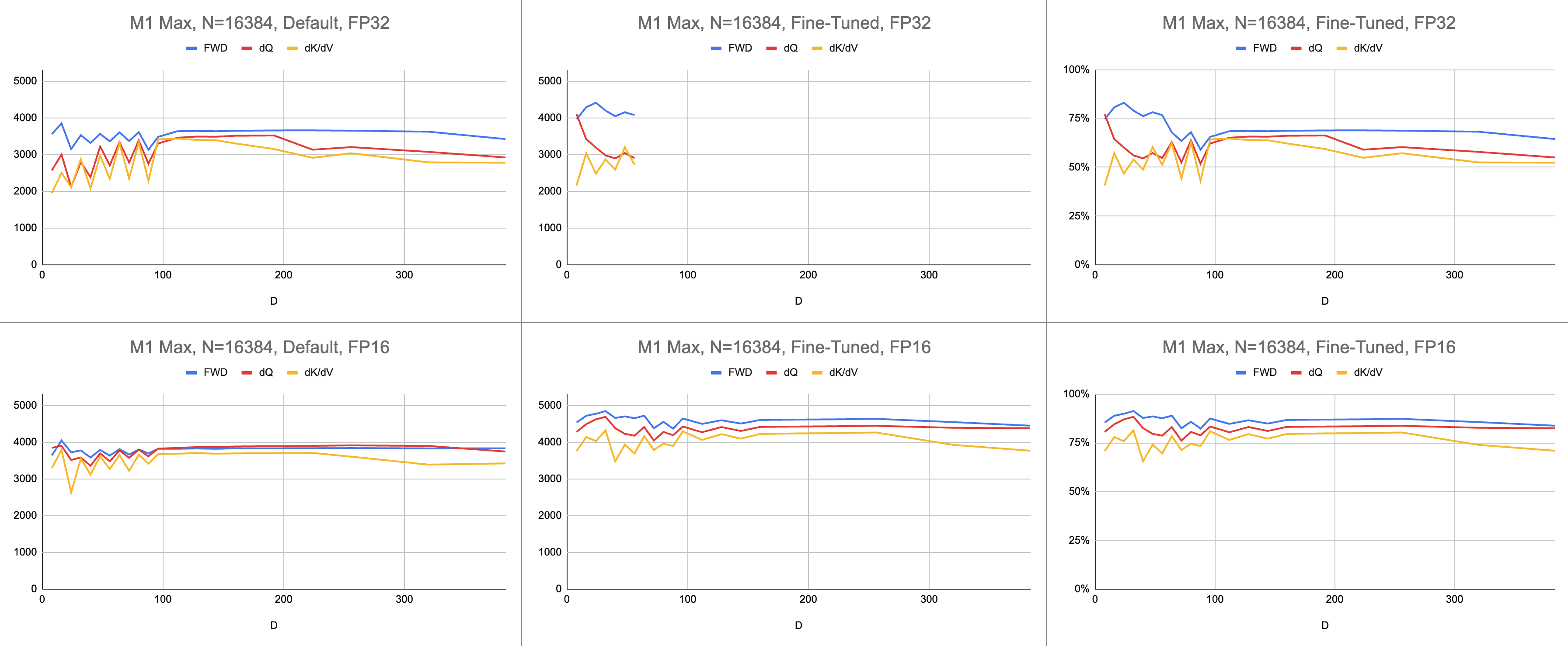
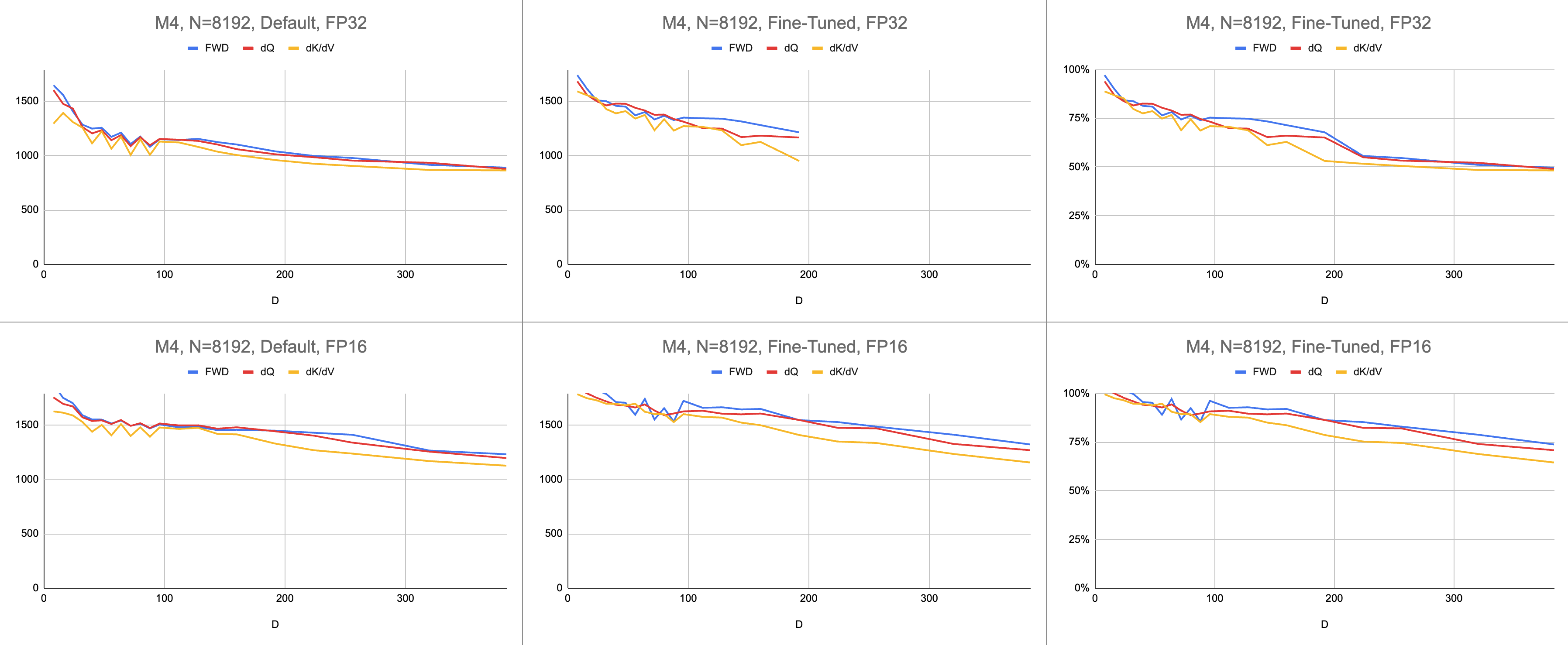
Dados brutos: https://docs.google.com/spreadsheets/d/1Xf4jrJ7e19I32J1IWIekGE9uMFTeZKoOpQ6hlUoh-xY/edit?usp=sharing
No campo da IA, o desempenho é mais frequentemente relatado em operações de ponto flutuante giga por segundo (GFLOPS). Esta métrica reflete um modelo simplificado de desempenho, em que cada instrução ocorre no GEMM. À medida que o hardware avançou desde as primeiras FPUs até os modernos processadores vetoriais, as operações de ponto flutuante mais comuns foram fundidas em uma única instrução. Adição multiplicada fundida (FMA). Quando se multiplica duas matrizes 100x100, são emitidas 1 milhão de instruções FMA. Por que devemos tratar esta FMA como duas instruções separadas?
Esta questão é relevante para atenção, onde nem todas as operações de ponto flutuante são criadas iguais. A exponenciação durante o softmax ocorre em um único ciclo de clock, desde que a maioria das outras instruções vá para a unidade FMA. Algumas das multiplicações e adições durante o softmax não podem ser fundidas com uma adição ou multiplicação próxima. Deveríamos tratá-los da mesma forma que o FMA e fingir que o hardware está executando o FMA duas vezes mais devagar? Não está claro como o modelo de desempenho GEMM pode explicar se meu shader está usando o hardware ALU de maneira eficaz.
Em vez de gigaflops, eu uso gigainstruções para entender o desempenho do shader. Ele mapeia mais diretamente para o algoritmo. Por exemplo, um GEMM são instruções N^3 FMA. A atenção direta executa duas multiplicações de matrizes, ou instruções 2 * D * N^2 FMA. A atenção para trás (pela implementação Dao-AILab/flash-attention) é 5 * D * N^2 instruções FMA. Tente comparar esta tabela com modelos de linha de telhado nos documentos Flash1, Flash2 ou Flash3.
| Operação | Trabalhar |
|---|---|
| GEMA Quadrada | N^3 |
| Atenção direta | (2D + 5) * N^2 |
| Atenção ingênua retrógrada | 4D * N^2 |
| Atenção Flash para Trás | (5D + 5) * N^2 |
| FWD + BWD combinados | (7D + 10) * N^2 |
Devido à complexidade dos átomos do FP32, o MFA usou uma abordagem diferente para a passagem para trás. Este tem custo de computação mais alto. Ele divide a passagem para trás em dois núcleos separados: dQ e dK/dV . Um menu suspenso mostra o pseudocódigo. Compare isso com um dos algoritmos dos artigos Flash1, Flash2 ou Flash3.
| Operação | Trabalhar |
|---|---|
| Avançar | (2D + 5) * N^2 |
| dQ para trás | (3D + 5) * N^2 |
| Regresso dK/dV | (4D + 5) * N^2 |
| FWD + BWD combinados | (9D + 15) * N^2 |
// Forward
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// (m, l, P) = softmax(m, l, S * scaleFactor)
//
// O *= correction
// load V[c]
// O += P * V
// }
// O /= l
//
// L = m + logBaseE(l)
//
// Backward Query
// D = dO * O
//
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// P = exp(S - L)
//
// load V[c]
// dP = dO * V^T
// dS = P * (dP - D) * scaleFactor
//
// load K[c]
// dQ += dS * K
// }
//
// Backward Key-Value
// for r in 0..<R {
// load Q[r]
// load L[r]
// S^T = K * Q^T
// P^T = exp(S^T - L)
//
// load dO[r]
// dV += P^T * dO
//
// load dO[r]
// load D[r]
// dP^T = V * dO^T
// dS^T = P^T * (dP^T - D) * scaleFactor
//
// load Q[r]
// dK += dS^T * Q
// }O desempenho é medido calculando a quantidade de trabalho de computação e dividindo-o por segundos. O resultado final são “gigainstruções por segundo”. Em seguida, precisamos de um modelo de linha de telhado. A tabela abaixo mostra as linhas do telhado para GINSTRS, calculadas como metade do GFLOPS. A utilização da ALU é (gigainstruções reais por segundo) / (gigainstruções esperadas por segundo). Por exemplo, o M1 Max normalmente atinge 80% de utilização de ALU com precisão mista.
Existem limites para este modelo. Ele quebra com a geração M3 em dimensões de cabeçote pequenas. Diferentes unidades de computação podem ser utilizadas simultaneamente, tornando a utilização aparente superior a 100%. Na maior parte, o benchmark fornece um modelo preciso de quanto desempenho resta na mesa.
var operations : Int
switch benchmarkedKernel {
case . forward :
operations = 2 * headDimension + 5
case . backwardQuery :
operations = 3 * headDimension + 5
case . backwardKeyValue :
operations = 4 * headDimension + 5
}
operations *= ( sequenceDimension * sequenceDimension )
operations *= dispatchCount
// Divide the work by the latency, resulting in throughput.
let instrs = Double ( operations ) / Double ( latencySeconds )
let ginstrs = Int ( instrs / 1e9 )| Hardware | GLOPS | GINSTRES |
|---|---|---|
| M1 máx. | 10616 | 5308 |
| M4 | 3580 | 1790 |
Quão bem a porta Metal se compara ao repositório oficial do FlashAttention? Imagine que eu usei o algoritmo "atomic dQ" e obtive 100% de desempenho. Em seguida, mudei para o repositório MFA real e descobri que o treinamento do modelo era 4x mais lento. Isso seria 25% da linha do telhado do repositório oficial. Para obter essa porcentagem, multiplique a utilização média da ALU em todos os três kernels por 7 / 9 . Um modelo mais matizado foi usado para as estatísticas do hardware da Apple, mas esta é a essência.
Para calcular a utilização do hardware Nvidia, usei GFLOPS para ALUs FP16/BF16. Dividi os GFLOPS mais altos de cada gráfico do artigo por 312.000 (A100 SXM), 989.000 (H100 SXM). Observe que, para dimensões de cabeçote maiores e núcleos com registro intensivo (passagem para trás), nenhum benchmark foi relatado. Confirmei que eles não resolveram o problema de pressão do registro em dimensões infinitas de cabeçote. Por exemplo, o acumulador é sempre mantido em registradores. No momento em que este artigo foi escrito, eu não tinha visto evidências concretas de que o gradiente reverso D = 256 fosse executado com resultados corretos.
| A100, Flash2, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avançar | 192.000 | 223.000 | 0 |
| Para trás | 170.000 | 196.000 | 0 |
| Avançar + Voltar | 176.000 | 203.000 | 0 |
| H100, Flash3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avançar | 497.000 | 648.000 | 756.000 |
| Para trás | 474.000 | 561000 | 0 |
| Avançar + Voltar | 480.000 | 585.000 | 0 |
| H100, Flash3, FP8 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avançar | 613000 | 1008000 | 1171000 |
| Para trás | 0 | 0 | 0 |
| Avançar + Voltar | 0 | 0 | 0 |
| A100, Flash2, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avançar | 62% | 71% | 0% |
| Avançar + Voltar | 56% | 65% | 0% |
| H100, Flash3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avançar | 50% | 66% | 76% |
| Avançar + Voltar | 48% | 59% | 0% |
| Arquitetura M1, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avançar | 86% | 85% | 86% |
| Avançar + Voltar | 62% | 63% | 64% |
| Arquitetura M3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avançar | 94% | 91% | 82% |
| Avançar + Voltar | 71% | 69% | 61% |
| Hardware produzido em 2020 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| A100 | 56% | 65% | 0% |
| Arquitetura M1 — M2 | 62% | 63% | 64% |
| Hardware produzido em 2023 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| H100 (usando FP8 GFLOPS) | 24% | 30% | 0% |
| H100 (usando FP16 GFLOPS) | 48% | 59% | 0% |
| M3 — Arquitetura M4 | 71% | 69% | 61% |
Apesar de emitir mais cálculos, o hardware da Apple está treinando transformadores mais rapidamente do que o hardware da Nvidia fazendo o mesmo trabalho . Normalizando a diferença de tamanho entre diferentes GPUs. Focando apenas na eficiência com que a GPU é utilizada.
Talvez o repositório principal deva tentar o algoritmo que evita atômicos FP32 e derrama deliberadamente registros quando eles não cabem no núcleo da GPU. Isso parece improvável, pois eles têm suporte codificado para um pequeno subconjunto de possíveis tamanhos de problemas. A motivação parece ser o suporte aos modelos mais comuns, onde D é uma potência de 2 e menor que 128. Para qualquer outra coisa, os usuários precisam contar com implementações alternativas de fallback (por exemplo, o repositório MFA), que pode usar um subjacente completamente diferente. algoritmo.
No macOS, baixe o pacote Swift e compile com -Xswiftc -Ounchecked . Esta opção do compilador é necessária para código de CPU sensível ao desempenho. O modo de liberação não pode ser usado porque força toda a base de código a ser recompilada do zero, sempre que houver uma única alteração. Navegue até o repositório Git no Finder e clique duas vezes em Package.swift . Uma janela do Xcode deve aparecer. À esquerda deve haver uma hierarquia de arquivos. Se você não consegue desvendar a hierarquia, algo deu errado.
git clone https://github.com/philipturner/metal-flash-attention
swift build -Xswiftc -Ounchecked # Does it even compile?
swift test -Xswiftc -Ounchecked # Does the test suite finish in ~10 seconds?
Alternativamente, crie um novo projeto Xcode com o modelo SwiftUI. Substitua o "Hello, world!" string com uma chamada para uma função que retorna um String . Esta função executará o script de sua escolha e, em seguida, chamará exit(0) , para que o aplicativo trave antes de renderizar qualquer coisa na tela. Você usará a saída no console Xcode como feedback sobre seu código. Este fluxo de trabalho é compatível com macOS e iOS.
Adicione a opção -Xswiftc -Ounchecked através de Project > your project's name > Build Settings > Swift Compiler - Code Generation > Optimization Level . A segunda coluna da tabela lista o nome do seu projeto. Clique em Outro no menu suspenso e digite -Ounchecked no painel que aparece. A seguir, adicione este repositório como uma dependência do pacote Swift. Veja alguns dos testes em Tests/FlashAttention . Copie o código-fonte bruto de um desses testes em seu projeto. Invoque o teste da função do parágrafo anterior. Examine o que ele exibe no console.
Para modificar a geração de código Metal (por exemplo, adicionar suporte a vários cabeçotes ou máscaras), copie o código Swift bruto em seu projeto Xcode. Use git clone em uma pasta separada ou baixe os arquivos brutos no GitHub como um ZIP. Também existe uma maneira de vincular ao seu fork de metal-flash-attention e salvar automaticamente suas alterações na nuvem, mas isso é mais difícil de configurar. Remova a dependência do pacote Swift do parágrafo anterior. Execute novamente o teste de sua escolha. Ele compila e exibe algo no console?
Localize um dos literais de string multilinha em uma destas pastas:
Sources/FlashAttention/Attention/AttentionKernel
Sources/FlashAttention/GEMM/GEMMKernel
Adicione texto aleatório a um deles. Compile e execute o projeto novamente. Algo deveria dar terrivelmente errado. Por exemplo, o compilador Metal pode gerar um erro. Se isso não acontecer, tente bagunçar uma linha de código diferente em outro lugar. Se o teste ainda passar, o Xcode não está registrando suas alterações.
Prossiga com a codificação da dispersão de blocos ou algo assim. Obtenha feedback sobre se o código funciona, se funciona rápido, se funciona rápido em qualquer tamanho de problema. Integre o código-fonte bruto ao seu aplicativo ou traduza-o para outra linguagem de programação.


