make a video pytorch
0.4.0
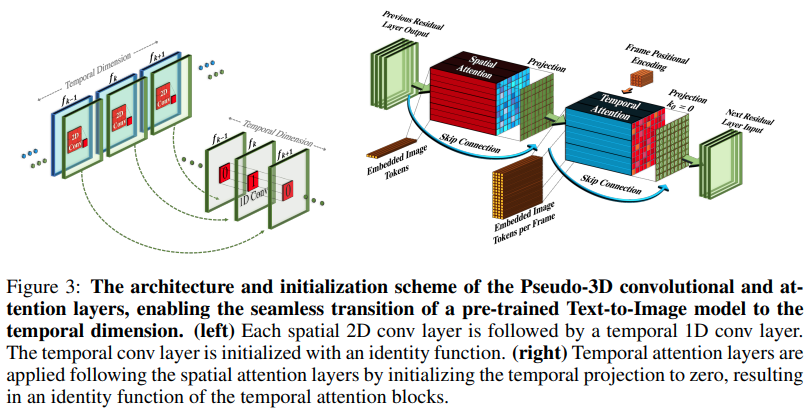
Implementação do Make-A-Video, novo gerador de texto para vídeo SOTA da Meta AI, em Pytorch. Eles combinam convoluções pseudo-3D (convoluções axiais) e atenção temporal e mostram uma fusão temporal muito melhor.
As convoluções pseudo-3D não são um conceito novo. Já foi explorado antes em outros contextos, digamos, para predição de contato de proteínas como "redes residuais híbridas dimensionais".
A essência do artigo se resume a pegar um modelo SOTA de texto para imagem (aqui eles usam DALL-E2, mas os mesmos pontos de aprendizagem se aplicariam facilmente ao Imagen), fazer algumas pequenas modificações para chamar a atenção ao longo do tempo e de outras maneiras. para economizar no custo de computação, faça a interpolação de quadros corretamente e obtenha um ótimo modelo de vídeo.
Explicação do AI Coffee Break
Stability.ai pelo generoso patrocínio para trabalhar em pesquisas de ponta em inteligência artificial
Jonathan Ho por trazer uma revolução na inteligência artificial generativa através de seu artigo seminal
Alex para einops, uma abstração simplesmente genial. Nenhuma outra palavra para isso.
$ pip install make-a-video-pytorchPassando recursos de vídeo
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
conv_out = conv ( video ) # (1, 256, 8, 16, 16)
attn_out = attn ( video ) # (1, 256, 8, 16, 16)Ao passar imagens (se alguém pré-treinar as imagens primeiro), tanto a convolução temporal quanto a atenção serão automaticamente ignoradas. Em outras palavras, você pode usar isso diretamente em sua Unet 2D e depois transferi-lo para uma Unet 3D assim que essa fase do treinamento for concluída. Os módulos temporais são inicializados para gerar identidade como o artigo fez.
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
images = torch . randn ( 1 , 256 , 16 , 16 ) # (batch, features, height, width)
conv_out = conv ( images ) # (1, 256, 16, 16)
attn_out = attn ( images ) # (1, 256, 16, 16)Você também pode controlar os dois módulos para que, quando alimentado com recursos tridimensionais, ele treine apenas espacialmente
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
# below it will not train across time
conv_out = conv ( video , enable_time = False ) # (1, 256, 8, 16, 16)
attn_out = attn ( video , enable_time = False ) # (1, 256, 8, 16, 16) SpaceTimeUnet completo que é independente de imagens ou treinamento em vídeo e onde, mesmo que o vídeo seja transmitido, o tempo pode ser ignorado
import torch
from make_a_video_pytorch import SpaceTimeUnet
unet = SpaceTimeUnet (
dim = 64 ,
channels = 3 ,
dim_mult = ( 1 , 2 , 4 , 8 ),
resnet_block_depths = ( 1 , 1 , 1 , 2 ),
temporal_compression = ( False , False , False , True ),
self_attns = ( False , False , False , True ),
condition_on_timestep = False ,
attn_pos_bias = False ,
flash_attn = True
). cuda ()
# train on images
images = torch . randn ( 1 , 3 , 128 , 128 ). cuda ()
images_out = unet ( images )
assert images . shape == images_out . shape
# then train on videos
video = torch . randn ( 1 , 3 , 16 , 128 , 128 ). cuda ()
video_out = unet ( video )
assert video_out . shape == video . shape
# or even treat your videos as images
video_as_images_out = unet ( video , enable_time = False )dê atenção ao melhor que a pesquisa de embeddings posicionais tem a oferecer
aumentar a atenção
adicione atenção instantânea
certifique-se de que dalle2-pytorch pode aceitar SpaceTimeUnet para treinamento
@misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @article { Dong2021AttentionIN ,
title = { Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth } ,
author = { Yihe Dong and Jean-Baptiste Cordonnier and Andreas Loukas } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2103.03404 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { shleifer2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Sam Shleifer and Myle Ott } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
}

