404 Base de conhecimento não encontrada
Última atualização: 28/06/2020
Recém-adicionado na semana passada:
- [Embalagem e publicação de projetos Python](# ferramentas)
Índice:
- noções básicas de informática
- Noções básicas de teoria da computação
- rede de computadores
- sistema operacional
- Estruturas de dados e algoritmos
- banco de dados
- Noções básicas de criptografia
- Noções básicas de tecnologia de informática
- linguagem
- quadro
- ferramenta
- tecnologia
- pesquisa subjacente
- Segurança
- tecnologia de segurança
- brechas
- Segurança na Web
- Teste de penetração
- Auditoria de código
- Segurança de dados
- Segurança na nuvem
- ferramentas de segurança
- Verificação de vulnerabilidade
- pesquisa de segurança
- Detecção de APT
- Amostras maliciosas
- Time Vermelho
- WAF
- Detecção de URL malicioso
- Luta contra o tráfego de máquinas
- Detecção de anomalias
- Números e Segurança
- IA e segurança
- Construção de segurança empresarial
- Desenvolvimento seguro
- Teste de segurança
- produtos de segurança
- Operação segura
- Gerenciamento de segurança
- Pense seguro
- arquitetura de segurança
- Confronto vermelho e azul
- Segurança da intranet
- Segurança de dados
- Nova tecnologia e nova segurança
- Visão geral
- nativo da nuvem
- computação confiável
- DevSecOps
- desenvolvimento seguro
- desenvolvimento pessoal
- Desenvolvimento da indústria
- dados
- Sistema de dados
- Análise de dados e operações
- Análise de dados de segurança
- algoritmo
- IA
- Sistema de algoritmo
- conhecimento básico
- aprendizado de máquina
- aprendizagem profunda
- aprendizagem por reforço
- Áreas de aplicação
- Desenvolvimento da indústria
- Qualidade abrangente
- Profissão
- planejamento de carreira
- pensamento
- comunicar
- gerenciar
- pensar
- Coisas a serem observadas
- apêndice
- Excelente pessoal técnico nacional
- Excelentes sites de tecnologia estrangeira
- abandonado
noções básicas de informática
Noções básicas de teoria da computação
sistema operacional
- [O vestibular de pós-graduação em informática 408 é o mais completo de toda a rede !!!!!] Sistema operacional de computador Kingly
- Interrupções e exceções
- Como entender de forma simples a paginação e segmentação do gerenciamento de memória no sistema operacional?
Granularidade, unidades lógicas de informação e unidades físicas de informação, comprimentos indeterminados e determinísticos, endereços bidimensionais e endereços unidimensionais, informação completa e alocação discreta de memória. - Resumo do estado do kernel e do usuário do sistema operacional
- Compilação de sistema operacional comum de perguntas de entrevista (obrigatório para todo desenvolvedor)
rede de computadores
- Compilação de perguntas comuns de entrevistas - rede de computadores (obrigatória para todo desenvolvedor)
A diferença entre TCP e UDP, handshake de três vias TCP e onda de quatro vias, o processo após o navegador inserir a URL, o tipo de solicitação do protocolo HTTP, a diferença entre GET e POST, protocolo de resolução de endereço ARP - Uma página completa do processo de solicitação do navegador (navegador, HTTP) de solicitação para resposta inclui uma série de processos, como handshake de três vias TCP, como resolução de nome de domínio, início de handshake de três vias TCP, início de solicitação HTTP, resposta do servidor à solicitação HTTP , e o navegador obtém o código HTML e o navegador analisa o código HTML e solicita os recursos no código HTML. O navegador renderiza a página e a apresenta ao usuário.
- O que exatamente significa a confiabilidade do tcp? - Resposta do CYS - Zhihu
A confiabilidade do TCP refere-se ao fornecimento de serviços confiáveis de transmissão de dados na camada de transporte com base na camada IP não confiável. Significa principalmente que os dados não serão danificados ou perdidos e todos os dados serão transmitidos na ordem em que foram enviados. Os seguintes mecanismos são usados para obter uma transmissão confiável do TCP: soma de verificação (para verificar se os dados estão danificados), temporizador (retransmissão se o pacote for perdido), número de sequência (usado para detectar pacotes perdidos e pacotes redundantes), confirmação (informação do receptor). o remetente de que um pacote foi recebido corretamente e o próximo pacote é esperado), confirmação negativa (o receptor notifica o remetente sobre um pacote que não foi recebido corretamente), janelas e pipeline (usado para aumentar a taxa de transferência do canal).
Estruturas de dados e algoritmos
- Algoritmo 3: A classificação rápida de classificação mais comumente usada
classificação e classificação rápida A ideia da classificação rápida é cavar buracos e preencher números + dividir e conquistar. - Uma pergunta da entrevista da Tencent: Minha xícara é tão incrível (aprendi)
Método de resolução de problemas 1: método de bissecção; método de resolução de problemas 2: método de resolução de problemas segmentado 3: método baseado em equações matemáticas; W(n, k) = 1 + min{max(W(n -1, x -1), W(n, k - x))}, x in {2, 3, ……,k} (n é o número da xícara, k é o número de andares) - Como escrever perguntas sobre algoritmos de maneira eficaz
As perguntas no LeetCode são divididas em três tipos: examinar estruturas de dados: como listas vinculadas, pilhas, filas, tabelas hash, gráficos, tentativas, árvores binárias, etc.; examinar algoritmos básicos: como profundidade primeiro, largura primeiro, binário; pesquisa, recursão, etc.; examinar ideias algorítmicas básicas: recursão, divisão e conquista, pesquisa retroativa, programação gananciosa e dinâmica. - Uma breve discussão sobre o que é o algoritmo de dividir e conquistar (aprendido)
Problema de permutação completa, problema de classificação por mesclagem, problema de classificação rápida e problema da Torre de Hanói sob a ideia de dividir para conquistar. - 2018.08 Na entrevista de emprego, o k-ésimo maior número na matriz desordenada, a mediana na matriz desordenada: ponteiro de classificação rápida, O(N).
- [Explicação do vídeo] Problema LeetCode nº 1: a soma de dois números
- Estratégias para pegar envelopes vermelhos nas reuniões anuais
Noções básicas de criptografia
- Explicação detalhada das vantagens e desvantagens da criptografia simétrica e da criptografia assimétrica A criptografia simétrica também é chamada de criptografia de chave única. Os algoritmos incluem: AES, RC4, 3DES. É rápido e pode ser usado quando uma grande quantidade de dados precisa ser criptografada. A quantidade de cálculo é pequena e a eficiência é alta. Se a chave secreta de uma das partes for revelada, toda a criptografia não será segura. Criptografia assimétrica, algoritmos incluem RSA, DSA/DSS, lentos e altamente seguros. Os algoritmos de hash incluem MD5, SHA1 e SHA256. Três tipos de algoritmos são a base da comunicação HTTPS .
banco de dados
- Entrevista Tencent: Quais são as razões pelas quais uma instrução SQL é executada lentamente?
Aprendizagem complementar : mecanismo de banco de dados (InnoDB suporta processamento de transações e chaves estrangeiras, mas é mais lento, ISAM e MyISAM usam pouco espaço e memória e inserem dados rapidamente), codificação de banco de dados ( character_set_client、character_set_connection、character_set_database、character_set_results、character_set_server、character_set_system ), banco de dados índice (índice de chave primária, índice clusterizado e índice não clusterizado) e outros pontos de conhecimento básico.
As razões pelas quais uma instrução SQL é executada lentamente são divididas em duas categorias: 1) Normal na maioria dos casos, ocasionalmente muito lento: (1) O banco de dados está atualizando páginas sujas, como refazer Quando o log está cheio, ele precisa ser sincronizado com o disco; (2) Bloqueios são encontrados durante a execução, como bloqueios de tabela e bloqueios de linha; 2) É sempre lento: (1) O índice não é usado: por exemplo; , o campo não tem índice porque o índice não pode ser usado devido a cálculos e operações de função; (2) O índice errado foi selecionado no banco de dados e compare o número de linhas verificadas do índice clusterizado com o índice de chave primária; a pesquisa direta de tabela completa É possível que o problema de amostragem seja mal avaliado e uma varredura completa da tabela seja executada. - Esta é provavelmente a solução de otimização SQL mais abrangente
Noções básicas de tecnologia de informática
linguagem
- Uma análise aprofundada dos decoradores Python em um artigo de 10.000 palavras
- Iteradores e geradores Python3
Pitão : Iteradores têm dois métodos básicos: iter() e next(). Objetos iteráveis como strings, tuplas e listas podem ser usados para criar iteradores (isso ocorre porque essas classes implementam a função __iter__() internamente. Depois de chamar iter() , torna-se um list_iterator objeto, você descobrirá que o método __next__() foi adicionado. Todos os objetos que implementam __iter__ e __next__ são iteradores). obter os elementos corretos durante a próxima iteração. __iter__ retorna o próprio iterador __next__ retorna o próximo valor no contêiner. Gerador: Uma função que usa rendimento é chamada de gerador. Quando uma função geradora é chamada, um objeto iterador é retornado. - iterador de tecnologia python black, gerador, decorador
- Quanto você sabe sobre os recursos avançados do Python? Vamos comparar
Python : função anônima lambda, a função é executar alguma expressão ou operação simples sem definir totalmente a função. A função Map é uma função python integrada que pode aplicar funções a elementos em várias estruturas de dados; Função Map, mas retorna apenas elementos para os quais a função aplicada retorna True; o módulo Itertools é uma coleção de ferramentas para processamento de iteradores, que são um tipo de dados que podem ser usados em instruções de loop for; . - Por que usar a linguagem Go? Quais são as vantagens da linguagem Go?
Go : As vantagens do go e os usos do go. As principais vantagens do go incluem: linguagem estática, simultaneidade múltipla, plataforma cruzada, compilação direta em código de máquina, biblioteca padrão rica, etc. Os principais usos do go incluem programação de servidores, programação de rede, sistemas distribuídos, bancos de dados em memória e plataformas em nuvem. - Série de prática de Gin - introdução de Golang e instalação de ambiente
Go : instalação do ambiente Go, o significado de cada pasta após a instalação do ambiente de trabalho; - ruby-on-rails - Qual é a diferença entre Ruby e JRuby
Ruby : Ruby é uma linguagem de programação. O interpretador Ruby ao qual geralmente nos referimos refere-se ao CRuby executado no ambiente do interpretador de linguagem C local.
quadro
- Gin - Introdução e uso do framework web Golang de alto desempenho
Gin : é uma estrutura de aplicação web escrita em Go. - Qual é a diferença entre inicialização de mola e mvc de mola?
Primavera -> Spring MVC -> Spring Boot.
ferramenta
- Comparação entre faísca e tempestade
Ferramentas de tecnologia de big data - tipo de computação : compare os aspectos do modelo de computação em tempo real, latência de computação em tempo real, taxa de transferência, mecanismo de transação, robustez/tolerância a falhas, ajuste dinâmico de paralelismo, etc. O streaming Spark é um modelo quase em tempo real. Ele coleta dados dentro de um período de tempo e os processa como um RDD. O atraso de cálculo em tempo real é de segundo nível e possui alto rendimento. . Possui robustez média e não suporta ajuste de grau de paralelismo. Storm é um modelo puramente em tempo real. O atraso de cálculo em tempo real é de nível de milissegundos. suporta um mecanismo de transação completo, é altamente robusto e suporta ajuste dinâmico do grau de paralelismo. Cenários de aplicação : Storm pode ser usado em cenários onde o tempo real puro não pode tolerar atrasos de mais de 1 segundo para funções de computação em tempo real que exigem mecanismos de transação e mecanismos de confiabilidade confiáveis, ou seja, o processamento de dados é completamente preciso, Storm também pode; ser considerado; se você também precisar ajustar dinamicamente o paralelismo dos programas de computação em tempo real durante os períodos de pico e baixo pico para maximizar a utilização de recursos, também poderá considerar a tempestade se o projeto for puramente computação em tempo real, não há necessidade; para executar consultas interativas SQL no meio, etc. Para outras operações, usar storm é uma escolha melhor. Por outro lado, se você não precisa de mecanismos de transação confiáveis e em tempo real ou de ajuste dinâmico de paralelismo, pode considerar o spark streaming. A maior vantagem do spark streaming é que ele está na pilha de tecnologia ecológica spark. perspectiva macro do projeto, se não for necessário apenas tempo real A computação também requer processamento em lote offline e consulta interativa e, no cálculo em tempo real, também envolverá processamento em lote de alta latência, consulta interativa e outras funções. use o spark core para desenvolver o processamento em lote offline e o spark sql para desenvolver consultas interativas, use o spark. O Streaming desenvolve computação em tempo real, integra-se perfeitamente e fornece alta escalabilidade ao sistema. Esse recurso aumenta muito as vantagens do Spark Streaming. As duas estruturas são boas em diferentes cenários de segmentação. - Tutorial de primeiros passos do Ziyu Big Data Spark (versão Python) (mais importante)
- Quais são as diferenças e conexões entre os sistemas de coleta de toras flume e kafka? Quando eles são usados, respectivamente, e quando podem ser combinados?
Ferramentas de tecnologia de big data - tipo middleware : Kafka pode ser entendido como middleware, ou sistema de cache, ou banco de dados, sua principal função é manter a estabilidade. Flume pode ser entendido como a coleta ativa de dados de log. Em comparação com o Kafka, é difícil promover a interface de modificação do aplicativo on-line para gravar dados no Kafka. - Quais são as vantagens e desvantagens entre logstash e flume e para quais cenários eles são adequados?
Ferramentas de tecnologia de big data - Tipo de agente : dependendo dos requisitos, tanto o logstash quanto o flume existem como agentes. O Logstash tem mais plug-ins e melhores produtos de suporte, como o elasticsearch, mas a linguagem de desenvolvimento do logstash é Ruby e o ambiente operacional é. JRuby. Além disso, os dados transmitidos podem ser perdidos; existe um mecanismo dentro do flume para garantir que uma certa quantidade de dados seja transmitida sem perda. A linguagem de desenvolvimento do flume é Java, que é fácil para o desenvolvimento secundário. que a jvm ocupa muita memória. - Lista de teclas de atalho do Mac
MAC : teclas de atalho básicas: capturas de tela, em aplicativos, processamento de texto, no finder, em navegadores, teclas de atalho para inicialização e desligamento do MAC; - Folhas de comandos Git comumente usadas
Git : Armazém remoto-"Armazém local->Área de preparação-"Espaço de trabalho, git add., git commit -m mensagem, git push. - git-lfs
Git-lfs : ferramenta de extensão de upload de arquivos grandes git. - pacote pcap de análise estatística tshark
- [Embalagem e publicação de projetos Python](# ferramentas)
Memorando : 1. setup.py: long_description e long_description_content_type (observe os problemas de renderização do formato md e rst). 2. manifest.in versus gitignore. 3. readme.rst vs readme.md. 4. .pypirc x gitconfig. 5. upload de python setup.py bdist_wheel.
tecnologia
- Decodificação e xss ( há um
\u72 no texto original "após codificação da entidade html" deveria ser -
Sequência de decodificação da tecnologia do navegador : a decodificação do navegador envolve principalmente duas partes: mecanismo de renderização e analisador js. Ordem de decodificação: A decodificação é realizada em qualquer ambiente. A ordem de decodificação é: a codificação correspondente ao ambiente mais externo é decodificada primeiro. Por exemplo: em <a href=javascript:alert(1)>click</a> alert(1) está no ambiente html->url->js. 1. Click usa codificação unicode e, que não pode ser decodificada em ambientes HTML ou URL. Ele só pode ser decodificado no caractere e em ambiente js, portanto, nenhuma janela pop-up ocorrerá.
2. Click usa codificação de URL Antes de executar js, o URL decodifica% 65, então quando o mecanismo js for iniciado, você verá o alerta completo (1).
3. Clique na decodificação da entidade HTML que é executada primeiro
4. Clique em No processo de decodificação de URL, o JavaScript não será considerado um pseudoprotocolo e ocorrerão erros.
5. Clique em htmlparser que será executado antes do analisador JavaScript, portanto, o processo de análise consiste em que os caracteres do htmlencode sejam decodificados primeiro e, em seguida, o evento JavaScript seja executado.
A ordem de decodificação do navegador é a base para ignorar no XSS . - A relação entre dockerfile e docker-compose
tecnologia docker : a relação entre arquivos e pastas. - Qual é a diferença entre dockerfile e docker-compose?
tecnologia docker : docker-compose serve para orquestrar contêineres. - O que é uma máquina bastião?
Tecnologia Bastion Host : define uma entrada para acesso ao cluster facilita o controle e monitoramento de permissões; - Sob quais aspectos a viabilidade de um produto precisa ser analisada?
Análise de viabilidade : A viabilidade do produto é dividida em: viabilidade técnica, viabilidade econômica e viabilidade social. Entre elas, foco na viabilidade técnica. A viabilidade técnica é medida principalmente a partir da comparação das funções dos concorrentes, riscos técnicos e métodos de prevenção, facilidade de uso e limite do usuário, dependência do ambiente do produto, etc. - Quais funções o Nginx e o Gunicorn desempenham no servidor?
Servidor de aplicativos : Cenário de implantação Nginx: balanceamento de carga (estruturas como tornado suportam apenas um único núcleo, portanto, a implantação de vários processos requer balanceamento de carga reverso. O próprio gunicorn é multiprocesso e não precisa dele), suporte a arquivos estáticos, pressão anti-simultaneidade , controle de acesso adicional. - Wikipédia: Cérbero
Kerberos : Descrição básica, conteúdo do protocolo e processo específico do Kerberos. - A relação entre dockerfile e docker-compose
tecnologia docker : a relação entre arquivos e pastas. - Qual é a diferença entre dockerfile e docker-compose?
tecnologia docker : docker-compose serve para orquestrar contêineres. - O que é uma máquina bastião?
Tecnologia Bastion Host : define uma entrada para acesso ao cluster facilita o controle e monitoramento de permissões; - Sob quais aspectos a viabilidade de um produto precisa ser analisada?
Análise de viabilidade : A viabilidade do produto é dividida em: viabilidade técnica, viabilidade econômica e viabilidade social. Entre elas, foco na viabilidade técnica. A viabilidade técnica é medida principalmente a partir da comparação das funções dos concorrentes, riscos técnicos e métodos de prevenção, facilidade de uso e limite do usuário, dependência do ambiente do produto, etc. - Quais funções o Nginx e o Gunicorn desempenham no servidor?
Servidor de aplicativos : Cenário de implantação Nginx: balanceamento de carga (estruturas como tornado suportam apenas um único núcleo, portanto, a implantação de vários processos requer balanceamento de carga reverso. O próprio gunicorn é multiprocesso e não precisa dele), suporte a arquivos estáticos, pressão anti-simultaneidade , controle de acesso adicional. - Wikipédia: Cérbero
Kerberos : Descrição básica, conteúdo do protocolo e processo específico do Kerberos. - O que é arquitetura de microsserviços**?
- O que é malha de serviço (malha de serviço)
Arquitetura de microsserviços : Por quê: Por que usar uma malha de serviço? Na arquitetura tradicional de aplicativos da Web de três camadas do MVC, a comunicação entre os serviços não é complicada e pode ser gerenciada dentro do aplicativo. No entanto, nos sites complexos de grande escala de hoje, os aplicativos individuais são decompostos em vários microsserviços. complexo. O que: Service mesh é a camada de infraestrutura para comunicação entre serviços. Pode ser comparada ao TCP/IP entre aplicações ou microsserviços. É responsável por chamadas de rede, limitação de corrente, interrupção de circuito e monitoramento entre serviços. Recursos do Service Mesh: camada intermediária para comunicação entre aplicativos, proxy de rede leve, independente de aplicativos, tentativas/tempos limite desacoplados de aplicativos, monitoramento, rastreamento e descoberta de serviços. Os softwares de código aberto atualmente populares são Istio e Linkerd, ambos os quais podem ser integrados no ambiente Cloud Native kubernetes. - O atualizador falha se não for executado como administrador, mesmo em uma instalação de usuário
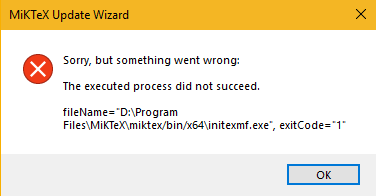
LaTeX : MiKTeX (problema de registro e problema de direitos de administrador) + TeXnicCenter (não é possível gerar problema de PDF, defina o caminho de execução do Adobe em Build para AcroRd32.exe genuíno) + Adobe Acrobat Reader DC e, em seguida, use a versão crackeada do Adobe Acrobat DC para converter para outros formatos. - Princípio HTTPS e processo de interação
HTTPS : HTTPS requer um handshake entre o navegador e o site antes de transmitir os dados. Durante o processo de handshake, as informações de senha usadas por ambas as partes para criptografar os dados transmitidos serão confirmadas. Obtenha a chave pública -> O navegador gera uma chave secreta aleatória (simétrica) -> Use a chave pública para criptografar a chave secreta simétrica -> Envie a chave secreta simétrica criptografada -> comunicação de texto cifrado criptografada pela chave secreta simétrica. Todo o processo de comunicação HTTPS utiliza criptografia simétrica, criptografia assimétrica e algoritmos HASH . - Política de Mesma Origem do Navegador
Tecnologia do navegador : A política de mesma origem é a função de segurança central e mais básica do navegador. A política de mesma origem é definida como: protocolo/host/porta. - Nove princípios de implementação entre domínios (versão completa)
Tecnologia do navegador : soluções de solicitação entre domínios: JSONP (vulnerabilidades que dependem de tags de script sem restrições entre domínios), CORS (compartilhamento de recursos entre domínios), postMessage, websocket, proxy de middleware Node, proxy reverso nginx, windows.name+iframe , localização.hash+iframe, documento.domínio+iframe.
CORS oferece suporte a todos os tipos de solicitações HTTP e é a solução fundamental para solicitações HTTP entre domínios. JSONP suporta apenas solicitações GET. A vantagem é que ele suporta navegadores antigos e pode solicitar dados de sites que não suportam CORS. Quer se trate de proxy de middleware Node ou proxy reverso nginx , o principal motivo é não impor restrições ao servidor por meio da política de mesma origem. No trabalho diário, as soluções de domínio cruzado mais comumente usadas são CORS e proxy reverso nginx. - Como usar o ambiente virtual Python no Jupyter Notebook?
Anaconda : Instale plug-ins, conda instale nb_conda - Já que existem solicitações HTTP, por que usar chamadas RPC? - Resposta do irmão Yi
RPC : Repousante VS RPC. RPC inclui: proxy reverso, serialização e desserialização, comunicação (HTTP, TCP, UDP), tratamento de exceções
pesquisa subjacente
Uma breve análise do processo de biblioteca de solicitações python
Python solicita implementação da biblioteca : socket->httplib->urllib->urllib3->requests. O processo de chamada interna de requests.get: requests.get->requests()->Session.request->Session.send->adapter.send->HTTPConnectionPool(urllib3)->HTTPConnection(httplib).
1、socket:是TCP/IP最直接的实现,实现端到端的网络传输
2、httplib:基于socket库,是最基础最底层的http库,主要将数据按照http协议组织,然后创建socket连接,将封装的数据发往服务端
3、urllib:基于httplib库,主要对url的解析和编码做进一步处理
4、urllib3:基于httplib库,相较于urllib更高级的地方在于用PoolManager实现了socket连接复用和线程安全,提高了效率
5、requests:基于urllib3库,比urllib3更高级的是实现了Session对象,用Session对象保存一些数据状态,进一步提高了效率
Análise dos princípios do XGBoost e implementação subjacente (aprendida)
XGBoost : Compreender na perspectiva da pontuação da árvore (função objetivo: função de perda (expansão de segunda ordem) + termo regular), a estrutura da árvore (decisão dividida (pré-classificação)).
Compreensão aprofundada do algoritmo de otimização de histograma Lightgbm
Lightgbm : Comparado com a pré-classificação, o lgb usa um histograma para lidar com a divisão do nó e encontrar o ponto de divisão ideal. Idéia de algoritmo: converta os valores do recurso em valores bin antecipadamente antes do treinamento, ou seja, faça uma função por partes para o valor de cada recurso, divida os valores de todas as amostras deste recurso em um determinado segmento (bin) e, finalmente, os valores dos recursos são convertidos de valores contínuos em valores discretos. Os histogramas também podem ser usados para aceleração diferencial. A complexidade do cálculo do histograma é baseada no número de intervalos.
Análise de código-fonte de pré-processamento de texto Keras
Keras - pré-processamento de texto : 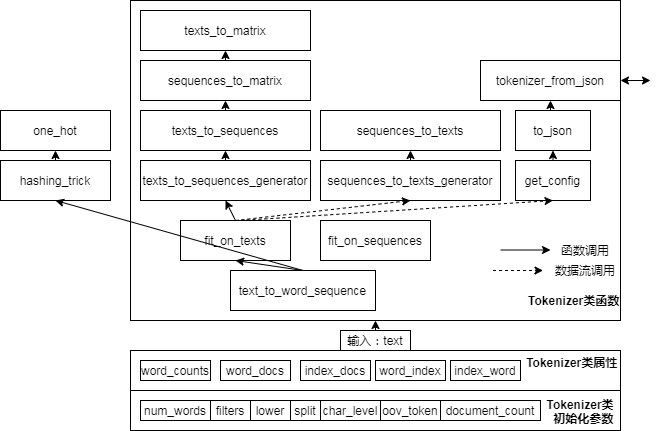
Análise de código-fonte de pré-processamento de sequência Keras
Word2Vec
- Compreendendo o modelo Skip-Gram do Word2Vec
- Implementando o modelo Skip-Gram baseado no TensorFlow - artigo de Tian Yusu
- Tutorial Word2Vec - O modelo Skip-Gram
- Tutorial Word2Vec Parte 2 - Amostragem Negativa
- Tutorial de incorporação de palavras Word2Vec em Python e TensorFlow
- análise de código-fonte do tensorlflow word2vec_basic
- Um tutorial do Word2Vec Keras
- keras_word2vec@adventures-in-ml-code
Segurança
tecnologia de segurança
brechas
- Compilação da carga útil da biblioteca de vulnerabilidades Wuyun e do plug-in auxiliar Burp
- boy-hack/wooyun-carga útil
- A perspectiva de um pesquisador sobre a pesquisa de vulnerabilidade na década de 2010
Pesquisa de vulnerabilidade: Situação atual e tendências da pesquisa de vulnerabilidade nos últimos 10 anos : 1. Na era pós-PC, a integridade do fluxo de controle tornou-se um novo mecanismo básico de proteção para a segurança do sistema. 2. Recursos surpreendentes de segurança de hardware e vulnerabilidades de segurança de hardware. 3. Vinho novo em garrafas velhas, o design seguro dos dispositivos móveis permite ultrapassagens nas curvas. 4. A batalha pelas entradas de rede está se intensificando. As entradas de rede incluem: navegadores, coprocessadores WiFi, bandas base, Bluetooth, roteadores, dispositivos de mensagens instantâneas, software social, clientes de e-mail, PCs e servidores tradicionais. 5. A mineração e exploração automatizada de vulnerabilidades ainda precisam ser melhoradas.
Segurança na Web
- Um artigo para lhe dar uma compreensão aprofundada das vulnerabilidades: Vulnerabilidades XXE
Vulnerabilidade XXE : O princípio de XXE: chamar entidades externas, a utilização de XXE: usar entidades gerais, entidades de parâmetro, entidades externas, entidades internas para ler arquivos, host de intranet e detecção de porta, RCE de intranet (o suporte da extensão expect é necessário em PHP)) - Técnicas de injeção sem vírgula do MySQL
Ataques de injeção : injeção de sql, injeção de xml (uma linguagem de marcação que representa estruturalmente os dados através de tags), injeção de código (classe eval), injeção de CRLF (rn). Injeção MySQL: Use comentários para ignorar espaços, use parênteses para ignorar espaços, use símbolos como% 20% 0a para substituir espaços na consulta de união, use join para ignorar a filtragem de vírgulas, select id,ip from client_ip where 1>2 union select * from ( (select user())a JOIN (select version())b ); Use select case when(条件) then 代码1 else 代码2 end para ignorar a filtragem por vírgula, insert into client_ip (ip) values ('ip'+(select case when (substring((select user()) from 1 for 1)='e') then sleep(3) else 0 end)); - [CRLF Utilização de vulnerabilidade de injeção e análise de exemplo]([https://wooyun.js.org/drops/CRLF%20Injection%E6%BC%8F%E6%B4%9E%E7%9A%84%E5% 88%A9%E7%94%A8%E4%B8%8E%E5%AE%9E%E4%BE%8B%E5%88%86%E6%9E%90.html](https://wooyun.js .org/drops/CRLF Utilização de vulnerabilidade de injeção e exemplo de análise.html))
CRLF é a abreviatura de "carriage return + line feed" (rn). O cabeçalho HTTP e o corpo HTTP são separados por dois CRLF. A injeção de CRLF também é chamada de HTTP Response Splitting, ou HRS, para abreviar. X-XSS-Protection:0 desativa a estratégia de proteção do navegador para filtragem XSS refletida. - Exploração de vulnerabilidade SSRF e combate getshell (selecionado)
- Resumo de vários métodos para contornar a filtragem (restrições de IP) em vulnerabilidades SSRF
SSRF : Use salto 302 (xip.io, endereço curto, serviço auto-escrito); religação de DNS (contornando restrições de IP http://[email protected]/ ; http://[email protected]/ por meio de vários protocolos não HTTP - Resumo dos métodos de bypass SSRF
SSRF : Use @; use endereço curto; use nome de domínio especial xip.io; use resolução DNS (defina um registro no nome de domínio); - Análise de vulnerabilidade ThinkPHP 5.0.0 ~ 5.0.23 RCE
- Uma breve análise de codificação de caracteres e injeção de SQL em auditoria de caixa branca (excelente, aprendido)
Ataque de injeção baseado na codificação de caracteres : um caractere chinês codificado em gbk ocupa 2 bytes e um caractere chinês codificado em utf-8 ocupa 3 bytes. A injeção ampla de bytes aproveita as características do mysql Quando o mysql usa a codificação gbk, ele pensará que dois caracteres são um caractere chinês (em gbk, o código ascii anterior deve ser maior que 128 para atingir o intervalo de caracteres chineses; a codificação. faixa de valores de gb2312: bit alto 0xA1-0xF7 , bit baixo 0xA1-0xFE e 0x5c , não está na faixa de bits baixos, então 0x5c não é a codificação em gb2312, portanto, não será usada para estender essa ideia a todas as codificações multibyte, desde que a faixa de bits baixos contenha a codificação de 0x5c , injeção de bytes largos pode ser realizada). Plano de defesa um: mysql_set_charset+mysql_real_escape_string , levando em consideração o conjunto de caracteres atual da conexão. Plano de defesa dois: Definir character_set_client como binary (binário), SET character_set_connection=gbk, character_set_results=gbk,character_set_client=binary . Quando nosso mysql receber os dados do cliente, ele pensará que sua codificação é character_set_client e, em seguida, alterará para a codificação de character_set_connection e, em seguida, inserirá a tabela e o campo específicos e, em seguida, converterá para a codificação correspondente ao campo. Então, quando os resultados da consulta forem gerados, eles serão convertidos da codificação de tabela e campo para a codificação character_set_results e retornados ao cliente. Portanto, se definirmos character_set_client como binary , não haverá problema de byte largo ou multibyte. Todos os dados são transferidos em formato binário, o que pode efetivamente evitar a injeção de caracteres largos. Também podem ocorrer problemas ao chamar iconv após a defesa. Ao usar iconv para converter utf-8 em gbk, o método de utilização é錦' , porque sua codificação utf-8 é 0xe98ca6 e sua codificação gbk é 0xe55c , que finalmente se torna %e5%5c%5c%27 , dois %5c É ' forem um número ímpar, ' escapará do limite. Por que não錦' usar este método? De acordo com as regras de codificação utf-8, (0x0000005c) não aparecerá na codificação utf-8, portanto, um erro será relatado. - Problemas de segurança causados por sessões de cliente
- Uma visão sobre DAST, SAST e IAST em um artigo – uma breve discussão sobre a comparação de tecnologias de teste de segurança de aplicações Web (aprendidas)
- Fale sobre SAST/IDAST/IAST
- Introdução aos métodos de conexão PHP e como atacar PHP-FPM
- Uma solicitação GET para obter a bandeira —— Redação final do PUBG (WEB 2) do XCTF 2018
Teste de penetração
- Um conjunto de perguntas práticas de entrevistas de emprego para testes de penetração Funções de execução de código:
eval、preg_replace+/e、assert、call_user_func、call_user_func_array、create_function funções de execução de comando: system、exec、shell_exec、passthru、pcntl_exec、popen、proc_open ; Além disso, existe alguma outra maneira de obter o caminho do administrador? src especifica um arquivo de script remoto para obter o referenciador. - Um conjunto de perguntas práticas para entrevistas de emprego sobre testes de penetração, você conhece?
- Minha experiência em entrevistas, testes de penetração
Auditoria de código
- Auditoria de código Java - avanço camada por camada
Segurança de dados
- NO.27 Bate-papo sobre segurança de dados Tecnologia e era do big data, os dados são o principal ativo de muitas empresas ; a fronteira de segurança tradicional é confusa, precisamos assumir que nossa fronteira foi penetrada e, ao mesmo tempo, ter uma defesa profunda; capacidades para proteger a segurança das informações. Portanto, ao mesmo tempo que fortalecemos os métodos de segurança tradicionais, devemos concentrar a segurança diretamente nos próprios dados. É isso que a segurança de dados faz. Antes de fazer isso, há uma premissa: devemos saber que a segurança ainda serve ao negócio (na maioria dos casos de segurança corporativa, negócio > segurança), portanto, segurança e usabilidade devem ser ponderadas. Atualmente, as medidas comumente utilizadas pelas empresas incluem principalmente: classificação de dados, gerenciamento do ciclo de vida dos dados, dessensibilização e criptografia de dados e prevenção de vazamento de dados.
- Construção de sistema de segurança de dados corporativos na Internet
Segurança na nuvem
- Segurança na nuvem, o que é exatamente?
Existem três direções principais de pesquisa em segurança em nuvem: segurança da computação em nuvem, cloudização da infraestrutura de segurança e serviços de segurança em nuvem. A colaboração de segurança de dados também é mencionada nas tendências futuras de desenvolvimento da segurança da nuvem, indicando que, independentemente do cenário, os dados são o foco da segurança. Os serviços de segurança em nuvem podem ser vistos como chefs de cozimento (ppt de cdxy), computação em nuvem (energia), algoritmos (ferramentas), dados (matérias -primas), engenheiros (chefs), que tipo de arroz pode ser feito (serviços de segurança que podem ser oferecido) ) - O futuro da segurança em nuvem (artigo aprofundado)
Idéias de escrita : tendências do mercado de segurança em nuvem -"Produtos de segurança em nuvem em nuvem (produtos de segurança da plataforma em nuvem e produtos de segurança em nuvem de terceiros CWPP, CSPM, CASB) -" A combinação de segurança em nuvem e sd -wan -"Cloud Native (DevOps, contínuo Entrega, microsserviços, contêineres) Segurança.
outro
- Informações de segurança: laboratórios corporativos, comunidades de segurança, equipes de segurança, ferramentas de segurança, etc.
ferramentas de segurança
Varredura de vulnerabilidade
- Varredura de vulnerabilidade usando o Modo de Proxy do Xray
pesquisa de segurança
Detecção adequada
- Detecção APT baseada no aprendizado de máquina
Modelo de detecção APT : Este artigo propõe um modelo de detecção de APT detectando vários links no ciclo de vida do APT, correlacionando eventos de alarme em cada link e usando o aprendizado de máquina para treinar o modelo de detecção. É um pouco semelhante à minha ideia. O objetivo disso é descrever completamente o conjunto de eventos de segurança em um cenário adequado, reduzir a taxa falsa positiva, melhorar a precisão e evitar os problemas de negativos perdidos e falsos positivos causados pela detecção tradicional de link único. No entanto, também existem alguns problemas neste artigo, como a falta de fontes de dados adequadas.
Amostras maliciosas
- Use o aprendizado de máquina para detectar tráfego externo malicioso HTTP (excelente)
Detecção de tráfego externo de HTTP malicioso : IDEA GERAL : 1. Coleta de dados , execute amostras maliciosas na caixa de areia, colete tráfego malicioso, distinguem manualmente o tráfego malicioso do tráfego branco e, em seguida, classificam o tráfego malicioso em famílias com base na inteligência de ameaças. 2. Análise de dados (engenharia de recursos): Para a semelhança do tráfego externo malicioso da mesma família, você pode considerar usar um algoritmo de agrupamento para agrupar o tráfego da mesma família em uma categoria, extrair seus pontos em comum, formar um modelo e, em seguida, Use o modelo para detectar tráfego desconhecido. 3. Algoritmo: Fase de treinamento : Extrair tráfego de conexão externa HTTP ---> Extrair campos de cabeçalho de solicitação ---> Generalização ---> Cálculo de similaridade ( ponderação específica do campo no cabeçalho da solicitação e calcule a similaridade ) ---> hierárquica Clustering ---> Gere modelo de tráfego externo malicioso (a união deste campo no cluster é usada como o valor desse campo no modelo). Fase de detecção : tráfego externo desconhecido HTTP ---> Extrair campos de cabeçalho de solicitação ---> generalização ---> Combinar com modelos maliciosos ---> Determine se a similaridade excede o limiar (determinação do limiar) - Construção da plataforma de análise automatizada de malware cuco
- Ambiente de análise de malware cuco
- Brincando com cuco
Sandbox Cuckoo: Encontrei muitas armadilhas no processo de construção do ambiente de análise de amostras maliciosas. PY para a pasta de inicialização; No host físico, o Windows 10 é instalado com o VMware, o VMware é instalado com o Ubuntu16, o Ubuntu16 é instalado com o VirtualBox e o Cuckoo Server e o VirtualBox é instalado com o Windows7 como agente. - Resumo dos recursos de análise de amostra maliciosos
Lutar contra o tráfego da máquina
- Relatório de Bot Bad 2018
Tráfego da máquina de combate : o confronto de segurança promoveu a evolução dos métodos de ataque e entrou no estágio de confronto automatizado O tráfego de máquinas é gerado, enquanto os rastreadores maliciosos e outros rastreadores maliciosos imitam solicitações de usuário normais para gerar tráfego de máquinas maliciosas. sem cabeça. Navegador, os mais avançados podem simular movimentos e cliques do mouse. O tráfego da máquina pode ser distinguido com base no ambiente de rede (ISP da Amazon, data centers, provedores de hospedagem global), as ferramentas utilizadas (navegadores do tráfego de máquinas gostam de se disfarçar como Chrome, Firefox, Internet Explorer, Safari) e se imitam humanos Interações, como trajetórias e cliques do mouse. Depois de detectar nossas tentativas de detê-los, os APBs avançados de tráfego de máquinas maliciosos se tornam persistentes e adaptáveis, realizando transformações multimodais. Defesa: Entenda nossas operações e objetivos inimigos. Suprimir o UA desatualizado/navegador; Tentativas de login com falha;
Detecção maliciosa de URL
- Detectando URLs maliciosos
Depois de ler algoritmos de segurança doméstica e materiais de análise de dados de segurança até o fim, eles começaram a voltar sua atenção para países estrangeiros e rastrear o processo de desenvolvimento de aplicações de aprendizado de máquina estrangeiras no campo da segurança da rede. Tomando a detecção de URL como exemplo, muitos cenários aplicáveis podem ser derivados, incluindo detecção de páginas da Web maliciosa, atividades de comunicação maliciosa e software Web malicioso. - Além das listas negras: aprendendo a detectar sites maliciosos de URLs suspeitos
Use a detecção de URL maliciosa como um método suplementar para detecção de páginas da Web maliciosa. Dados: Amostras de URL em preto e branco de código aberto, sem recursos especiais; Não há recursos, análise e comparação de cada subcategoria, este modelo não possui características; Afinal, era um artigo escrito há dez anos. - Identificando URLs suspeitos: uma aplicação de aprendizado on-line em larga escala
- Explorando a covariância do recurso em aprendizado on-line de alta dimensão
Equipe vermelha
- Prática e pensamento da equipe vermelha de 0 a 1 (aprendida)
Definição da equipe vermelha ---> O objetivo da equipe vermelha (aprenda e use TTPs de atacantes reais conhecidos para atacar, avaliar a eficácia das capacidades de defesa existentes, identificar fraquezas no sistema de defesa e propor contra-medidas específicas, usar ataques simulados reais e eficazes Para avaliar o potencial impacto nos negócios causado por questões de segurança) --- quem precisa de equipe vermelha ---> Como a equipe vermelha funciona (composição básica: reserva de conhecimento, infraestrutura, capacidades de pesquisa técnica; processo de trabalho: simulação de ataque de estágio completo, ataques encenados simulação; Quantificação e avaliação da equipe (cobertura de TTPs conhecidos, taxa de detecção/tempo de detecção/estágio de detecção, taxa de bloqueio/tempo de bloqueio/estágio de bloqueio) ---> Crescimento e melhoria da equipe vermelha (treinamento em meio ambiente de simulação, análise de vulnerabilidades e pesquisa técnica, comunicação externa e compartilhar) - Resumo da Organização ATT e CK APT TTPS
- Resumo da tecnologia ATT & CK Full Platform Ataque
- Resumo dos relatórios reais de análise de organização apt
WAF
- Discussão Técnica |
- Use a transferência em pedaços para derrotar todos os WAFs
- Ignorar o WAF do nível do protocolo HTTP e nível de banco de dados
- Quatro níveis de Pesquisa de Ataque e Defesa WAF: Ignorar WAF
- Algum conhecimento sobre waf
Detecção de anomalia
- N Métodos de detecção de anomalia (aprendida)
Uma das dificuldades na detecção de anomalia é a falta de verdade. Um método comum é primeiro usar métodos não supervisionados para minar amostras anormais e depois usar modelos supervisionados para fundir vários recursos para extrair mais anomalias. De séries temporais (média móvel, ano a ano e mês a mês, STL+GESD), estatísticas (distância Mahalanobis, BoxPlot), ângulo de distância (KNN), método linear (decomposição da matriz e redução de dimensionalidade do PCA), distribuição (A entropia relativa KL detecta anomalias de ângulos como divergência, teste do qui-quadrado), árvores, gráficos, sequências comportamentais e modelos supervisionados (que podem combinar automaticamente mais recursos, como GBDT). - Algoritmo de detecção de anomalia do aprendizado de máquina (1): floresta de isolamento
- Algoritmo de detecção de anomalia do aprendizado de máquina (2): fator externo local
- Algoritmo de detecção de anomalia de aprendizado de máquina (3): análise de componentes principais
- O que é uma máquina vetorial de suporte de uma classe (uma classe SVM)?
- Algoritmo de detecção de anomalia
- Mineração de anomalia, floresta de isolamento
- Primeira tentativa de detecção de anomalia
- Monitoramento inteligente de anomalias de dados de séries temporais alimentadas pelo aprendizado de máquina
- Exceções de mineração em toras de operação e manutenção maciças
- Identificação de pré-processamento de dados
- Um estudo preliminar sobre a aplicação de detecção anormal e aprendizado supervisionado em detecção de anomalia
- Quais são os algoritmos comuns de "detecção de anomalia" na mineração de dados? - Resposta ajustada - Zhihu
1. Introduzir algoritmos e experimentos de detecção não supervisionados não supervisionados; 1.1) Modelos de estatísticas e probabilidade: Distribuição de hipóteses e testes de hipóteses, unidimensional e multidimensional, independência e correlação de recursos, distância euclidiana e distância de Mahalanobis; Distância euclidiana e distância Mahalanobis, PCA e PCA macio e SVM de uma classe; 1.2) Verifique a conexão entre algoritmos a partir do limite de decisão do gráfico de resultados experimentais. 2.1) Comparação dos efeitos de detecção do modelo, floresta de isolamento e KNN realizam de forma estável; 3.1) O volume de dados e as dimensões de dados também têm um impacto na sobrecarga do algoritmo. O isolamento é mais adequado para espaços de alta dimensão. 4.1) Os resultados experimentais trazem idéias para a seleção do modelo de detecção de anomalias: KNN e MCD para conjuntos de dados de pequeno e médio porte são relativamente estáveis, e a floresta de isolamento para conjuntos de dados médio e grande é estável; Como PCA e MCD; 4.2) Para um novo problema de detecção de anomalia, você pode seguir as seguintes etapas para analisar: A. Entenda os dados, a distribuição de dados e a distribuição de anomalia e selecione um modelo com base em suposições; , se assim for, deve ser que não possa ser desperdiçado; Algoritmo de seleção de pontos; Características das anomalias geralmente mudam. As regras manuais ainda são muito úteis, não tente substituir as regras existentes por estratégias de dados em uma etapa. - Penteado |
- Floresta e visualização de isolamento de detecção de anomalias
- Detecção de anomalia com previsão de séries temporais
Figuras e segurança
- Figura/Louvain/DGA Alega Talk O gráfico carrega informações topológicas e informações topológicas podem ser consideradas uma dimensão característica. O ponto -chave do algoritmo Louvain é o peso das bordas do gráfico, que requer estudo especial em cenários específicos de ataques e defesa. dos IPs que visitaram os nomes de domínio A e B ao mesmo tempo. O mestre CDXY implementou essa lógica usando o SQL.
- Algoritmo de descoberta comunitária-um estudo preliminar sobre desdobramento rápido (Louvian) algoritmo
- Uma análise DGA DGA DGA DGA Odyssey
- A computação gráfica aprendeu sobre a implementação da segurança básica: a implementação de gráficos na detecção de intrusões, resposta à intrusão, inteligência de ameaças e UEBA. Detecção de intrusões: a direção de desenvolvimento da detecção de intrusões corporativas e o histórico de desenvolvimento dos recursos de análise de dados. Resposta de intrusão: problemas resolvidos durante o processo (integridade e riqueza de toras, análise de correlação de dados maciços e janelas de longa data, construção em tempo real e consulta de gráficos, interação e visualização). UEBA: O desenvolvimento da confiança nativa em nuvem e da confiança zero -"Seguro por padrão -" Obtenção de credenciais para serviços confiáveis ", ataques da cadeia de suprimentos" -"Detecção de intrusões construída com autenticação -" Análise de comportamento e perfil. Resumo: Questões de negócios -> Problemas de dados.
AI e segurança
- Compilação de materiais de aprendizagem para cenários de segurança, algoritmos de segurança baseados em IA e análise de dados de segurança
- Rumo à privacidade e segurança de sistemas de aprendizado profundo: uma pesquisa
Superfície de ataque da segurança da IA : em termos de dados e modelos na fase de treinamento e na fase de teste, os ataques incluem envenenamento por dados e amostras adversárias, extração de modelos e inversão de modelos, etc. - Detecção de ameaças inteligente: plataforma de detecção de aprendizado de máquina baseada em faísca
Construção de segurança corporativa
Desenvolvimento seguro
- Construção da plataforma de detecção automatizada de varredura de segurança (Web Black Box)
- Leve você para ler a análise do código -fonte Kunpeng do artefato
Teste de segurança
- Planeje a criação de um controle de controle de risco e um sistema de alerta precoce
Controle de risco de segurança dos negócios : detecta rapidamente anomalias e define com precisão os riscos. Descubra fragmentos e entidades anormais através de alterações nos indicadores principais e descubra todas as entidades sob o cluster anormal através de métodos de agrupamento; - A jornada de mudar da segurança tradicional para o campo de controle de risco e discutir as tendências na indústria negra e de controle de riscos
Controle de risco de negócios : A luta no campo de controle de risco está se tornando cada vez mais feroz. Com a repressão judicial com a repressão de alta pressão do governo em produtos pretos e cinzentos, as grandes empresas prestarão atenção às capacidades do produto e à conformidade da legitimidade dos fornecedores de controle de risco no futuro. - Modelo de controle de risco Preparação de entrevistas-capítulo técnico
- Prática do modelo de controle de risco-Competição de algoritmo de controle de risco "Magic Mirror Cup"
- Método de identificação do usuário de controle de risco
- Github: Sladesha
- Vários algoritmos identificam usuários anormais, como recheio de credenciais e fraude de cupom
- Experiência de comunicação encoberta do túnel DNS && tenta reproduzir detecção de modo de pensamento de vetorização de recursos
- HIDS para construção de segurança corporativa
- Garantir a segurança do IDC: design de arquitetura de cluster hids distribuído
- Dianrong Open Source Agentsmith Hids --- Um sistema leve HIDS
- Construção de segurança corporativa-algumas idéias sobre o design do sistema HIDS baseado em agentes
Sistema de detecção de intrusões de detecção de intrusões : vale a pena aprender a prática sistemática de Meituan. A partir da descrição da demanda, o gerente do produto apresenta a demanda -> analisa a demanda, resume as características de que a arquitetura do produto deve cumprir com -> Dificuldades técnicas, analisa os desafios técnicos encontrados -> Design de arquitetura e seleção de tecnologia -> cluster distribuído HIDs Diagrama de arquitetura -> Seleção da linguagem de programação-> Implementação do produto. - Método de detecção de túnel ICMP e implementação com base na análise estatística
produtos de segurança
- Colete alguns excelentes projetos de segurança de código aberto para ajudar os profissionais de segurança da Party A a criar recursos de segurança de segurança corporativa (aprendidos) de segurança de código aberto : incluindo gerenciamento de ativos, desenvolvimento de segurança, auditoria automatizada de código, operação e manutenção de segurança, host de bastião, HIDs e análise de tráfego de rede , Honeypot, WAF, Disco de Cloud Enterprise, Sistema de Sites de Phishing, Monitoramento do Github, Controle de Riscos, Gerenciamento de Vulnerabilidades, SIEM/SOC.
Operação segura
- O que eu entendo sobre operações de segurança
As empresas pagam pela produção, não pelo conhecimento . As operações de segurança são orientadas para a solução de problemas. Principais responsabilidades e requisitos de habilidades para operações de segurança: segurança, R&D, Operação e Manutenção . - Vamos falar sobre o porquê das operações seguras: os riscos de segurança são visualizados e a aparência é exposta;
O que e como as operações seguras: aproveite as principais contradições e contradições secundárias e tente o seu melhor para resolvê -las.
Gerenciamento de segurança
- A liberação da árvore de habilidades de construção de segurança corporativa v1.0 inclui seis partes: descrição, conceito de segurança, governança de segurança, habilidades gerais, habilidades profissionais e recursos de alta qualidade.
Pense seguro
- Fale sobre a direção de desenvolvimento da segurança da Internet
Direção de Desenvolvimento da Segurança da Empresa : Do mais raso ao mais profundo, é dividido em quatro objetivos: 1. Impulsionado pela eliminação de vulnerabilidades, o primeiro objetivo é tornar a linha de código escrita por engenheiros. Pesquisa e tecnologia técnicas derivadas. 2. O SDL não pode ser 100% seguro, portanto, o segundo objetivo é permitir que todos os ataques conhecidos e desconhecidos sejam descobertos pela primeira vez e alertados e rastreados rapidamente. Desafios: dados maciços e requisitos complexos: poder de computação super e modelos tridimensionais. 3. O terceiro objetivo é tornar a segurança a competitividade central da empresa e aprofundar os recursos de cada produto para orientar melhor os hábitos de uso da Internet dos usuários. 4. O último objetivo é ser capaz de observar mudanças em toda a tendência de segurança da Internet e fornecer alerta precoce de riscos no futuro. Ao fazer segurança em uma empresa de internet, você deve ter imaginação e prestar muita atenção ao desenvolvimento de outros campos técnicos. ser feito. - Promovendo a defesa através do ataque: pensamentos sobre a construção de um exército azul corporativo
- Zhao Yan's Ciso Blitz |
Objetos de escopo (negócios da empresa, desafios e necessidades de segurança (defesa em profundidade, segurança da cadeia de suprimentos, capacitando a segurança de terceiros)) ---> Configuração de metas (configuração de demanda atual e desenvolvimento futuro) ---> Desafios (em toda a equipe Stack (estrutura e habilidades de conhecimento correspondentes aos principais negócios), recursos de engenharia, recursos de gerenciamento) ---> Decomposição Sistema de segurança (Sandbox de construção de segurança em campos gerais: segurança de P&D, segurança de TI, segurança de infraestrutura, segurança de dados, segurança do terminal, segurança de negócios, conformidade com privacidade e segurança) ---> Implementação e resposta (estrutura de governança de segurança, benchmarking da indústria (implementação real habilidade, a demonstração não conta como essa habilidade), pesquisa de segurança). Em geral, é uma visão técnica de pilha completa (se esforça para subir do nível de habilidades para o nível de visão técnica) + recursos de gerenciamento de segurança.
arquitetura de segurança
- Arquitetura de segurança de rede | melhorando a segurança através da arquitetura de segurança] (https://mp.weixin.qq.com/s/m90wyaevhzfsdgnfhmgxcw)
Confronto vermelho e azul
- [Confronto vermelho e azul] Construção da equipe de segurança do Exército Azul para grandes empresas da Internet (aprendida)
O porquê do confronto vermelho e azul : teste o sistema de proteção de segurança corporativo;
O que é o confronto azul-vermelho : Taxa de descoberta de intrusão;
O confronto do Blue Red : simule a equipe azul precisa desenvolver uma base sistemática de base e biblioteca de armas de técnicas de ataque ---> ATT && CK Matrix Framework.
Desafios no confronto azul vermelho com : eficiência/benefício;
O futuro do confronto azul-vermelho : o Exército Azul de vários níveis e multi-escopo; - Construindo confronto vermelho-azul na era da segurança do ciberespaço (existem artigos relacionados ao confronto vermelho-azul no apêndice)
O combate real é o único critério para testar os recursos de proteção de segurança . O teste de penetração é adequado para o estágio inicial da construção do sistema de segurança corporativo ou para o estágio de exaustão, e o confronto vermelho-azul é uma versão atualizada do teste de penetração. Sistema de Construção de Segurança . /Peeping e outros campos de uma perspectiva de segurança do ciberespaço .
Segurança da intranet
- Simulação de ataque de segurança da intranet e prática de regra de detecção de anomalia
A idéia de escrita : Coleção de informações externas -> Remutação de limites -> Coleção de informações, escalada de privilégios -> Manutenção de privilégios -> Coleta de informações, extração de credenciais -> Movimento lateral -> Roubo de dados -> Limpe os traços.
Segurança de dados
- A Tencent Security lança o "mapa de capacidade de segurança de dados" no nível corporativo "mapa de capacidade de segurança"
Idéias de redação : O mapa de capacidade de segurança de dados inclui seis aspectos principais: gerenciamento de ativos de dados e recursos de controle, recursos de operação de segurança de dados, gerenciamento de segurança de negócios e recursos de controle, gerenciamento e controle de segurança do ambiente de suporte ao meio ambiente, operação de dados e gerenciamento de segurança de manutenção e controle Recursos e recursos de percepção de segurança de dados.
Nova tecnologia e nova segurança
Visão geral
- Modernização de aplicativos e mudança de segurança deixada na transformação digital
Idéias de escrita : nova infraestrutura -> Transformação digital -> A informatização tradicional enfrenta desafios -> Modernização de aplicativos orientada por negócios -> Native em nuvem, contêinerização, DevOps, microsserviços de aplicativos, orquestração e outras novas tecnologias -> Arquitetura de modernização de aplicativos -> Segurança endógena (todos -Percepção, confiabilidade, intervenção de segurança de processo completo e operação segura da rede em nuvem).
Native em nuvem
- Interpretação da rede nativa da nuvem Proxy MOSN Tecnologia de seqüestro transparente |
A ideia de escrita : malha de serviço-> istio-> plano de dados> Proxy de rede-> Mosn-> seqüestro de tráfego eficiente e transparente. Problema: aquisição do tráfego. Resolvendo problemas: adaptação ambiental, gerenciamento de configuração, desempenho do plano de dados. - Observação da tendência de detecção de intrusão nativa em nuvem
A idéia de escrever : diversificação de ativos, fragmentação de serviços, explosão de middleware, segurança de infraestrutura por padrão -> detecção de intrusões "orientada para os negócios", a análise comportamental se tornará a capacidade principal. - Wang Renfei (Avfisher): Red Teaming for Cloud (ofensa em nuvem e defesa) (Mark)
computação confiável
- Zhang OU: prática de rede confiável do Banking Digital
Ideias de escrita : A questão essencial é: Defesa em profundidade no nível da rede. Por que fazer isso (desafio) -> idéias e planos de implementação -> Desafios e pensamentos no processo . - Ele yi: o caminho para a prática da arquitetura de segurança zero confiante
Ponto do núcleo : o núcleo do Zero Trust é o estabelecimento de cadeias de confiança, como usuários + dispositivos + aplicativos, verificação dinâmica segura e contínua e estreitando a superfície de ataque. Trabalho realizado: gateway de rede, gateway host, gateway de aplicativos, soc .
DevSecOps
- "A segurança requer a participação de todos os engenheiros" -DevSecops Philosophy and Thinking (Mark)
desenvolvimento seguro
desenvolvimento pessoal
entrevista
- Entrevistas de segurança, estágios, etc.
Entrevistas : Didi, Baidu (2), 360 (2), Alibaba (6), Tencent (3), Bilibili, Huawei, Tonghuashun, Mogujie. De um modo geral, os caras grandes são tão fortes que a maioria de suas escolhas são o departamento de segurança do Party A. Meu entendimento: depois de ler as entrevistas e perguntas feitas pelos grandes caras, é realmente diversificado, incluindo orientação para a lixeira, orientação para segurança de dados, orientação para operação de segurança etc., que tem algum valor de referência, mas porque as direções são diferentes, então você Não pode copiá -los rigidamente. - 2018 Spring Recruitment Safety Post estágio Resumo da entrevista
- TENCENT 2016 Recrutamento de estágio Detonado Explicação das respostas para as perguntas do teste por escrito do Post Security
Teste escrito : Design A Solução de autenticação da Web segura: Front-end: Código de verificação + CSRF_TOKEN + Gere números aleatórios com base na criptografia de registro de data e hora; , porta, protocolo); - Entrevistas para posições de tecnologia de segurança em grandes empresas
Entrevista : básicos da tecnologia de segurança ---> Detalhes do projeto (profundidade do conhecimento, sobrecarregando o entrevistador em áreas de especialização, impedindo que o entrevistador faça perguntas detalhadas) ---> Como lidar com perguntas desafiadoras (conhecimento e cognitivo da indústria A habilidade geralmente não se desvia do campo de especialização e requer leitura e pensamento diário) ---> Capacidade cognitiva profunda da indústria e planejamento de carreira - Qual é a situação atual de referências internas para estagiários do Alibaba em 2019? - Resposta de Zuo Zuo Vera - Zhihu (aprendido)
- Dez rostos de Ali, sete rostos de manchetes, você acha que eu entrei em Ali?
Entrevista : versão Java da excelente experiência em entrevista, um must-have para Java. - Livro de espadas e inimigos: eu e o Alibaba (muito forte)
- Perguntas de entrevista de recrutamento de segurança (aprendida)
Ideias de escrita : teste de penetração (direção da Web), pesquisa e desenvolvimento de segurança (direção Java), operações de segurança (direção da auditoria de conformidade), arquitetura de segurança (direção de gerenciamento de segurança)
Aprendizagem suplementar : CRLF, as diferenças, vantagens e desvantagens da criptografia simétrica e criptografia assimétrica, processo de interação HTTPS, política de origem, solicitações de domínio cruzado. - Como é um bom currículo para o recrutamento seguro?
- Recrutamento de segurança: situação atual do setor de segurança
- Qualidades essenciais dos profissionais de segurança para recrutamento de segurança
Ideia de escrita: qualidade básica = habilidade básica (auto-acionada + aprendizado independente) + habilidade profissional (ataque de penetração e defesa + desenvolvimento de software). Qualidades avançadas = inteligência (QI + inteligência emocional) + bravura e otimismo + introspecção . - O processo de entrevista para recrutamento seguro é preguiçoso agora e custará mais para compensar isso mais tarde.
- 2019 de um engenheiro de segurança
Idéias de escrita : faixa antiga e nova jornada - "Explorador da indústria ou seguidor -" Exchange transparente de informações do setor - "Adicione um pouco de sal à vida".
desenvolvimento de carreira
- Autocultivação de pesquisadores de segurança
- Autocultivação de pesquisadores de segurança (continuação)
- Discussão sobre a direção de desenvolvimento do pessoal de segurança
Rota de desenvolvimento de segurança do Party A : Tipo de tecnologia dura ---> Laboratórios de Dachang e pesquisa de segurança Postações de tecnologia não-hard-core ---> Internet Segurança Empresa Construção Vermelha e Azul, Operações Técnicas, Gerenciamento de Segurança - O significado da existência de profissionais de segurança
Desenvolvimento pessoal : o objetivo é ajudar a produtividade avançada a resolver problemas de segurança. A questão da segurança é uma questão de confiança (suporte de confiança, suporte de origem), uma ciência que os estudos confrontam (confronto entre pessoas) e uma questão de probabilidade (arquitetura de segurança). Segurança é uma ciência aplicada. , incluindo inteligência de máquina e tecnologia blockchain. - Várias identidades da equipe de segurança na empresa
团队发展:安全团队应该以服务者和协作者的身份,用专业的安全能力给出一类安全问题的解决思路和方案并解决,防止安全问题发生多次。
行业发展
安全格局
- 最新统计2005-2017年国内科研单位在国际安全顶级会议中发表文章量统计
- 从内容产出看安全领域变化
技术格局:企鹅等互联网巨头开始进行流量封锁,对安全从业人员影响很大,爬不到数据,api又有限,只能上升到app hook了;技术上安全分析、数据挖掘、威胁情报的比重越来越重, AI已经不仅仅是噱头了,智能安全势不可挡;安全的职业发展方面,越来越多大佬们开始转型业务安全、数据安全。 - 网络安全行业竞争格局浅析
市场格局:基础安全防护(传统安全防护能力),中级安全防护(海量数据建模与分析能力),高级安全防护(云端威胁情报与分析能力),中高级安全防护市场广阔。此外,全文在多处凸显了人工智能技术,智能安全开始迈入开悟之坡了吗? !半数以上的人看好智能安全,也有人不看好智能安全,未来会怎么样,让我们拭目以待! - ZoomEye 网络空间测绘——委内瑞拉停电事件对其网络关键基础设施和重要信息系统影响
- 2020安全工作展望
Logic of writing : Major events in 2019 : HW action changes safety from implicit to explicit, low frequency to high frequency, exposes problems, and promotes management to pay attention to safety. This is the background; Classification Protection 2.0 safety compliance is becoming more stringent . 2019大变化:领导重视了;实战化了。 2020甲方安全关注技术点:安全运营(覆盖率和正常率等指标、是否有验证思路:能否在一定时间内主动发现安全措施失效)和安全资产管理(CMDB、主机上数据、流量、扫描、人工添加)。 2020关注“人”的需求。 2020展望行业:甲方安全团队组织架构会发生剧烈变化,安全团队能否承受变化;甲乙两方相处之道;安全黑天鹅事件越来越多。
安全产品
- C端安全产品的未来之路
C端安全产品:移动端安全产品是否会像前几天PC端安全产品一样迎来春天?PC时代windows是一家独大的完全开放的平台,这让第三方安全公司能够在平台和用户之间产生价值的空间足够的大,但在移动端,安卓开始封闭,就不好说了。传统安全软件围绕病毒和欺诈,而围绕个人信息安全的C端安全产品有一线生机。 - 下一座圣杯- 2019
API安全:应用安全的发展:2015年预测,数据是新中心,身份是新边界,行为是新控制,情报是新服务。基础设施演进->交付方式的改变。2015年,应用安全领域的WAF产品是良机,由市场决定。新形势与新机遇:微服务、Serverless、边缘计算。市场中的交付方式发生变化。跨细分领域且跨基础设施:API安全横跨应用安全、数据安全和身份安全三大领域。API使用场景广泛,需要产品有全面覆盖多种不同基础设施的能力。
dados
数据体系
- 数据分析师如何搭建数据运营指标体系? - 张溪梦Simon的回答
Core point : Collaboration process empowerment : Implementing the data-driven XX indicator system construction process requires cross-team collaboration. The processes include: demand collection, program planning, data collection, collection program evaluation, data collection and data verification online, and effect evaluation .规划数据指标体系的两个模型:OSM和UJM。 OSM强调业务目标,UJM强调用户旅程。指标分级体系:一二三级指标联动。 - 如何在企业中从0-1建立一个数据/商业分析部门? ( Aprendido )
部门的定位和价值——>里程碑设计——->团队搭建——->构建IT数据——->前期管理。
定位和价值是一个部门立足公司的根本:做报表的部门VS做战略的部门;业务其他公司的定位和公司内其他部门的认可;一定要会放大部门的价值和一定要走高层路线。
设立长期目标并拆解里程碑:公司业务目标--->公司战略--->部门目标--->部门里程碑--->工作计划;设立里程碑的技巧?借势、共赢、取巧、筑基;借老板势,寻找1-2个老板的痛点问题解决;寻找利益相同的部门共建共赢;取巧摘已有的“桃子”;筑基数据链路梳理、数据清洗、系统互联、数据仓库设计、数据集市设计。
基于里程碑进行团队搭建:切忌一步到位;审慎拉帮结派;遇到人才不可错过;学会“画饼”;注意团队文化建设。
构建公司的数据IT能力:搭建基础且通用的数据流框架:应用层、归集层、加工层、分析层、展示层; 同时根据各种数据库选型指标选择对应的数据库存储产品,数据库选型指标比如容量、水平扩展性、查询实时性、查询灵活性、写入速度、事务、数据存储、处理数据规模、列扩展性。在搭建数据框架中需要注意的点是:需要实现公司级别的业务数据架构。基于业务对整个公司的数据进行体系化的梳理,任何的业务变化都会体现在数据之上,实现数据充分体现业务现状的目的。要完成这一步的关键是完成公司级别的主数据管理:明确各项数据的业务含义和口径、明确每个数据的职责单位、打通数据链路,推动数据共享。
引领团队走向胜利:做“排长”而不要做“军长”;让合适的人做合适的事;明确规则,及时兑现。
数据分析与运营
- 数据分析与可视化:谁是安全圈的吃鸡第一人(学到了)
数据分析与可视化:收集数据集--->观察数据集--->社群发现与社区关系--->玩家画像。 - 请分享一下数据分析方面的思路,如何做好数据分析?
核心点:数据分析的问题:业务的数据分析指标体系(点线面体)。数据分析的方法:分类和对比。
安全数据分析
- Data-Knowledge-Action: 企业安全数据分析入门(优秀,学到了)
综述: 1、让模型理解业务,基于业务历史行为建立异常基线,在异常的基础上检测威胁;将运营结果反馈到模型,将误报视作正常行为回流。2、安全运营可运营,降低事件调查成本,自动化信息收集与聚合。3、随着数据的积累,安全数据分析将向基于图结构的高级知识表达方式发展。(这点深表赞同)4、对场景、攻击模式、数据的认识深度,远比选择工具重要。 - Security Data Science Learning Resources
综述:作者的研究点也是安全数据科学,整理了一些学习方法和学习资源。学习方法主要分为三个方面:谷歌学术、Twitter、安全会议。谷歌学术关注知名研究者以及他们新出的文章,关注引用了你关注的文章的文章,Twitter关注细分安全领域的人群,关注安全会议以及会议议程。学习资源:书籍和课程。 - 快速搭建一个轻量级OpenSOC架构的数据分析框架(一)(学到了)
框架:行文思路:由粗变细(由框架到举例子(由框架到场景到实际架构))。OpenSOC介绍(框架组成和工作流程)---》构建轻量级OpenSOC(聚焦具体场景和工具及具体架构)---》搭建步骤(每一步的环境搭建及配置)---》效果展示。 - 先知talk:从数据视角探索安全威胁
- 大数据威胁建模方法论(学到了很多)
- 安全日志维度随想
- 数据安全分析思想探索
- DataCon 2019: 1st place solution of malicious DNS traffic & DGA analysis(学到了)
我的理解:涉及的知识点有:安全场景:DNS安全;数据处理:tshark工具的使用,MaxCompute和SQL的使用,PAI预分析和可视化;特征工程:DNS_type、src_ip维度的特征;异常检测算法:单特征3sigma检测;人工提取特征规则。
第一小题DNS恶意流量的异常检测:个人吸收80%,整理流程无障碍,每步流程中的细节和工具还未完全掌握,比如DNS安全场景了解不全面、tshark的大量数据解析、统计特征的全面提取、SQL语句做特征化;
第二小题DGA的多分类:个人吸收50%,流程搞懂了,但是对一些问题的理解还不到位,比如社区算法 - 基于大数据企业网络威胁发现模型实践
我的理解:问题:多源安全分析设备和服务(威胁数据)的横向和纵向联动。
algoritmo
IA
算法体系
- 机器学习算法集锦:从贝叶斯到深度学习及各自优缺点
算法知识框架:主要从算法的定义、过程、代表性算法、优缺点解释回归、正则化算法、人工神经网络、深度学习||决策树算法、集成算法||支持向量机||降维算法、聚类算法||基于实例的算法||贝叶斯算法||关联规则学习算法||图模型。
个人理解:回归系列主要基于线性回归和逻辑回归衍生,包括回归、正则化算法、人工神经网络、深度学习;树系列主要基于决策树衍生,包括决策树和基于树的集成学习算法;支持向量机属于老牌算法;降维算法和聚类算法主要基于数据的内在结构描述数据;基于实例的算法实际上并没有训练的过程,代表性算法是KNN,基于记忆的学习;贝叶斯算法利用贝叶斯定理计算输出概率;关联规则学习算法能够提取数据中变量之间的关系的最佳解释;图模型是一种概率模型,可以表示随机变量之间的条件依赖结构。 - Categories of algorithms non exhaustive (学到了)
算法知识框架:学到了搭建自己的算法体系。
conhecimento básico
- HTTP DATASET CSIC 2010
Security Data Set-CSIC2010 : A security data set automatically generated based on e-Commerce Web application, including 36,000 normal requests and 25,000 abnormal requests. Abnormal requests include: SQL injection, buffer overflow, information collection, file leakage, CRLF injection, XSS etc . - 分类模型的性能评估——以SAS Logistic 回归为例(3): Lift 和Gain
- 机器学习中非均衡数据集的处理方法?
非均衡数据集:上采样和下采样、正负样本的惩罚权重(scikit-learn的SVM为例:class_weight:{dict,'balanced'})、组合/集成方法(从大样本中抽取多个小样本训练模型再集成)、特征选择(小样本量具有一定规模的时候,选择显著型的特征) - 机器学习算法中GBDT 和XGBOOST 的区别有哪些?
算法比较:GBDT基分类器为CART,XGB的分类器可以是多种基分类器,比如线性分类器,这时候就相当于L1、L2正则项的逻辑回归或线性回归;传统的GBDT在优化时用到的是一阶导数,XGB则对损失函数进行了二阶泰勒公式的展开,精度变高;XGB并行处理(特征粒度的并行,对特征值进行预排序存储为block结构,在进行节点分类的时候,需要计算每个特征的增益,最终选择增益最大的那个特征去做分类,那么各个特征的增益计算就可以开多线程进行),相对于GBM速度飞跃;剪枝时,当新增分类带来负增益时,GBM会停止分裂,而XGB一直分类到指定的最大深度,然后进行后全局剪枝;从最优化的角度来看,GBDT采用的是数值优化的思维,用的最速下降法去求解Loss function的最优解,其中用CART决策树去拟合负梯度,用牛顿法求步长,而XGB用的是解析的思维,对Loss function展开到二阶近似,求得解析解,用解析解作为Gain来建立决策树,使得Loss function最优。 - SVM和logistic回归分别在什么情况下使用?
算法使用场景-SVM和逻辑回归使用场景:需要根据特征数量和训练样本数量来确定。如果特征数相对于训练样本数已经够大了,使用线性模型就能取得不错的效果,不需要过于复杂的模型,则使用LR或线性核函数的SVM。 If the training samples are large enough and the number of features is small, better prediction performance can be obtained through SVM with complex kernel functions. If the samples do not reach millions, SVM with complex kernel functions will not cause the operation to be too slow .如果训练样本特别大,使用复杂核函数的SVM已经会导致运算过慢了,因此应该考虑引入更多特征,然后使用线性SVM或者LR来构造模型。 - gbdt的残差为什么用负梯度代替?
- 欧氏距离与马氏距离
- 机器学习算法常用指标总结
- 分类模型评估之ROC-AUC曲线和PRC曲线
aprendizado de máquina
- 平均数编码:针对高基数定性特征(类别特征)的数据预处理/特征工程
- Mean Encoding
- kaggle编码categorical feature总结
- Python target encoding for categorical features
- Mean (likelihood) encodings: a comprehensive study
- 如何在Kaggle 首战中进入前10%
- kaggle竞赛总结
- 分享一波关于做Kaggle比赛,Jdata,天池的经验,看完我这篇就够了
- 为什么在实际的kaggle比赛中,GBDT和Random Forest效果非常好?
有监督学习-树系列算法:单模型,gradient boosting machine和deep learning是首选。gbm不需要复杂的特征工程,不需要太多时间去调参数,dl则需要比较多的时间去调网络结构。从overfit角度理解,两者都有overfit甚至perfect fit的能力,overfit能力越强,可塑性越强,然后我们要解决的问题就是如果把模型训练的“恰好”,比如gbm里有early_stopping功能。线性回归模型就缺乏overfit能力,如果实际数据符合线性模型的关系,那可以得到很好的结果,如果不符合的话,就需要做特征工程,可特征工程又是一个比较主观的过程。树的优势,非参数模型,gbm的overfit能力强。而random forest的perfact fit能力很差,这是因为rf的树是独立训练的,没有相互协作,虽然是非参数型模型,但是浪费了这个先天优势。 - 【总结】树类算法认知总结
有监督学习-树类算法:分类树和回归树的区别;避免决策树过拟合的方法;随机森林怎么应用到分类和回归问题上;kaggle上为啥GBDT比RF更优;RF、GBDT、XGBoost的认知(原理、优缺点、区别、特性)。 - LightGBM
- LightGBM算法总结
- 『我爱机器学习』集成学习(四)LightGBM
- 如何玩转LightGBM(官方slides讲解)
有监督学习-LightGBM-个人理解: LightGBM几大特性及原理:直方图分割及直方图差加速(直方图两大改进:直方图复杂度=O(#feature×#data),GOSS降低样本数,EFB降低特征数)-》效率和内存提升。Leaf-wise with max depth limitation取代Level-wise-》准确率提升。支持原生类别特征。并行计算:数据并行(水平划分数据)、特征并行(垂直划分数据)、PV-Tree投票并行(本质上是数据并行)。 - 快速弄懂机器学习里的集成算法:原理、框架与实战
- 时间序列数据的聚类有什么好方法?
无监督学习-时间序列问题:传统的机器学习数据分析领域:提取特征,使用聚类算法聚集;在自然语言处理领域:为了寻找相似的新闻或是把相似的文本信息聚集到一起,可以使用word2vec把自然语言处理成向量特征,然后使用KMeans等机器学习算法来作聚类;另一种做法是使用Jaccard相似度来计算两个文本内容之间的相似性,然后使用层次聚类的方法来作聚类。常见的聚类算法:基于距离的机器学习聚类算法(KMeans)、基于相似性的机器学习聚类算法(层次聚类)。对时间序列数据进行聚类的方法:时间序列的特征构造、时间序列的相似度方法。如果使用深度学习的话,要么就提供大量的标签数据;要么就只能使用一些无监督的编码器的方法。 - 凝聚式层次聚类算法的初步理解
无监督学习-层次聚类:算法步骤:计算邻近度矩阵--->(合并最接近的两个簇--->更新邻近度矩阵)(repeat),直到达到仅剩一个簇或达到终止条件。 - 推荐算法入门(1)相似度计算方法大全
无监督学习-层次聚类-相似性计算:曼哈顿距离、欧式距离、切比雪夫距离、余弦相似度、皮尔逊相关系数、Jaccard系数。
aprendizagem profunda
CPU环境搭建
- tensorflow issues#22512
Nature of the problem : Error: ImportError: DLL load failed, reason: missing dependencies, solution: pip install --index-url https://pypi.douban.com/simple tensorflow==2.0.0, dependencies will be installed automatically .
GPU环境搭建
- Tensorflow和Keras 常见问题(持续更新~)(坑点)
- Tested build configurations(版本对应速查表)
- windows tensorflow-gpu的安装(靠谱)
- windows下安装配置cudn和cudnn
问题本质:总的来说,是英伟达显卡驱动版本、cuda、cudnn和tensorflow-gpu之间版本的对应问题。最好装tensorflow-gpu==1.14.0,tensorflow-gpu==2.0需要cuda==10.0,10.2会报错,tensorflow-gpu==2.0不支持。 - win10搭建tensorflow-gpu环境
问题本质:CUDA的各种环境变量添加。
深度学习基础知识
- 深度学习中的batch的大小对学习效果有何影响?
- Batch Normalization原理与实战(还没完全看懂)
神经网络基本部件
- 如何计算感受野(Receptive Field)——原理感受野:卷积层越深,感受野越大,计算公式为(N-1)_RF = f(N_RF, stride, kernel) = (N_RF - 1) * stride + kernel,思路为倒推法。
- 如何理解空洞卷积(dilated convolution)谭旭的回答空洞卷积:池化层减小图像尺寸同时增大感受野,空洞卷积的优点是不做pooling损失信息的情况下,增大感受野。3层3*3的传统卷积叠加起来,stride为1的话,只能达到(kernel_size-1)layer+1=7的感受野,和层数layer成线性关系,而空洞卷积的感受野是指数级的增长,计算公式为(2^layer-1)(kernel_size-1)+kernel_size=15。
- 空洞卷积(dilated convolution)感受野计算
- 空洞卷积(dilated Convolution)
- 直观理解神经网络最后一层全连接+Softmax(便于理解)
全连接层:可以理解为对特征的加权求和。
神经网络基本结构
- 一组图文,读懂深度学习中的卷积网络到底怎么回事?
卷积神经网络:卷积层参数:内核大小(卷积视野3乘3)、步幅(下采样2)、padding(填充)、输入和输出通道。卷积类型:引入扩张率参数的扩张卷积、转置卷积、可分离卷积。 - 卷积神经网络(CNN)模型结构
- 总结卷积神经网络发展历程- 没头脑的文章(很全面)
- 三次简化一张图:一招理解LSTM/GRU门控机制(很清晰)
循环神经网络:文中电路图的形式好理解。RNN:输入状态、隐藏状态。LSTM:输入状态、隐藏状态、细胞状态、3个门。GRU:输入状态、隐藏状态、2个门。LSTM和GRU通过设计门控机制缓解RNN梯度传播问题。 - gcn
- GRAPH CONVOLUTIONAL NETWORKS
图神经网络:相较于CNN,区别是图卷积算子计算公式。 - keras-attention-mechanism
神经网络应用
- [AI识人]OpenPose:实时多人2D姿态估计| 附视频测试及源码链接
- 使用生成对抗网络(GAN)生成DGA
- GAN_for_DGA
- 详解如何使用Keras实现Wassertein GAN
- Wasserstein GAN in Keras
- WassersteinGAN
- keras-acgan
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题- 综述和实践
NLP :传统的高维稀疏->现在的低维稠密。注意事项:类目不均衡、理解数据(badcase)、fine-tuning(只用word2vec训练的词向量作为特征表示,可能会损失很大效果,预训练+微调)、一定要用dropout、避免训练震荡、超参调节、未必一定要softmax loss、模型不是最重要的、关注迭代质量(为什么?结论?下一步?)
强化学习
- 深度强化学习的弱点和局限
- 关于强化学习的局限的一些思考
强化学习的局限性:采样效率很差、很难设计一个合适的奖励函数。
Áreas de aplicação
- 全球最全?的安全数据网站(有时间得好好整理一下)
- 初探机器学习检测PHP Webshell
- 基于机器学习的Webshell 发现技术探索
- 网络安全即将迎来机器对抗时代?
智能安全-智能攻击:国外已经在研究利用机器学习打造更智能的攻击工具,比如深度强化学习,就是深度学习和强化学习的结合,可以感知环境,做出最优决策,可能被应用到漏洞扫描器里,使扫描器能够自动化地入侵目标。
个人理解:国外已有案例Deep Exploit就是利用深度强化学习结合metasploit进行自动化地渗透测试,国内还没有看到过相关公开案例。由于学习门槛高、安全本身攻击场景需要精细化操作、弱智能化机器学习导致的机器学习和安全场景结合深度不够等一系列的问题,已有的机器学习+安全的大多数研究主要集中在安全防护方面,机器学习+攻击方面的研究较少且局限,但是我相信这个场景很有潜力,或许以后就成为蓝方的攻击利器。 - 人工智能反欺诈三部曲之:设备指纹
智能安全-业务安全-设备指纹:ip、cookie、设备ID ;主动式设备指纹:使用JS或SDK从客户端抓取各种各样的设备属性值,然后组合,通过hash算法得到设备ID;优点:Web内或者App内准确率高。 Disadvantages : Active device fingerprinting will generate different device IDs between Web and App and between different browsers, and cannot achieve device association across Web and App, and between different browsers; due to reliance on client code, fingerprinting It is less confrontational in anti-fraud cenários.被动式设备指纹:从数据报文中提取设备OS、协议栈和网络状态的特征集,并结合机器学习算法识别终端设备。优点:弥补了主动式设备指纹的缺点。缺点:占用处理资源多;响应时延比主动式长。 - 风险大脑支付风险识别初赛经验分享【谋杀电冰箱-凤凰还未涅槃】
智能安全-业务安全-风控:个人理解见:https://github.com/404notf0und/Risk-Operation-Detection/blob/master/atec.ipynb。 - 机器学习在互联网巨头公司实践
入侵检测:机器学习和统计建模的主要区别:机器学习主要依赖数据和算法,统计建模依赖建模者对数据特征的了解。两者的优缺点:机器学习:打标数据难获取,如果采用非监督学习,则性能不足以运维;机器学习结果不可解释。所以现在机器学习在做入侵检测的时候,一般都要限定一个特定的场景。统计建模:数据预处理阶段移除正常数据的干扰(重点关注查全率,强调过正常数据的过滤能力,尽可能筛除正常数据),构建能够识别恶意可疑行为的攻击模型(重点关注precision,强调模型对异常攻击模式判断的准确性,攻击链模型),缺点是泛化能力不足、在入侵检测一些场景中,模型易被干扰。我们的最终目的:大数据场景下安全分析可运维。 - Web安全检测中机器学习的经验之谈
Web安全:从文本分类的角度解决Web安全检测的问题。数据样本的多样性,短文本分类,词向量,句向量,文本向量。文本分类+多维度特征。与传统方法做对比得出更好的检测方式:传统方法+机器学习:传统waf/正则规则给数据打标;传统方法先进行过滤。 - 词嵌入来龙去脉(学到了)
PNL :DeepNLP的核心关键:语言表示--->NLP词的表示方法类型:词的独热表示和词的分布式表示(这类方法都基于分布假说:词的语义由上下文决定,方法核心是上下文的表示以及上下文与目标词之间的关系的建模)--->NLP语言模型:统计语言模型--->词的分布式表示:基于矩阵的分布表示、基于聚类的分布表示、基于神经网络的分布表示,词嵌入--->词嵌入(word embedding是神经网络训练语言模型的副产品)--->神经网络语言模型与word2vec。 - 深入浅出讲解语言模型
NLP :NLP统计语言模型:定义(计算一个句子的概率的模型,也就是判断一句话是否是人话的概率)、马尔科夫假设(随便一个词出现的概率只与它前面出现的有限的一个或几个词有关)、N元模型(一元语言模型unigram、二元语言模型bigram)。 - 有谁可以解释下word embedding? - YJango的回答- 知乎
NLP :单词表达:one hot representation、distributed representation。Word embedding:以神经网络分析one hot representation和distributed representation作为例子,证明用distributed representation表达一个单词是比较好的。word embedding就是神经网络分析distributed representation所显示的效果,降低训练所需的数据量,就是要从数据中自动学习出输入空间到distributed representation空间的映射f(相当于加入了先验知识,相同的东西不需要分别用不同的数据进行学习)。训练方法:如何自动寻找到映射f,将one hot representation转变成distributed representation呢?思想:单词意思需要放在特定的上下文中去理解,例子:这个可爱的泰迪舔了我的脸和这个可爱的京巴舔了我的脸,用输入单词x 作为中心单词去预测其他单词z 出现在其周边的可能性(至此我才明白为什么说词嵌入是神经网络训练语言模型的副产品这句话)。用输入单词作为中心单词去预测周边单词的方式叫skip-gram,用输入单词作为周边单词去预测中心单词的方式叫CBOW。 - Chars2vec: character-based language model for handling real world texts with spelling errors and…
- Character Level Embeddings
- 使用TextCNN模型探究恶意软件检测问题
恶意软件检测:改进分为两个方面:调参和结构。调参:Embedding层的inputLen、output_dim,EarlyStopping,样本比例参数class_weight,卷积层和全连接层的正则化参数l2,适配硬件(GPU、TPU)的batch_size。结构:增加了全局池化层。
学到了:一个trick,通过训练集和评价指标logloss计算测试集的各标签数量,以此调整训练阶段的参数class_weight,还可以事先达到“对答案”的效果。和一个T大大佬在datacon域名安全检测比赛中使用的trick如出一辙。 - 基于海量url数据识别视频类网页
CV-行文思路:问题:视频类网页识别。解决方式:url粗筛->视频网页规则粗筛->视频网页截屏及CNN识别。
行业发展
- 认知智能再突破,阿里18 篇论文入选AI 顶会KDD
认知智能:计算智能->感知智能->认知智能。快速计算、记忆、存储->识别处理语言、图像、视频->实现思考、理解、推理和解释。认知智能的三大关键技术:知识图谱是底料、图神经网络是推理工具、用户交互是目的。 - 未来3~5 年内,哪个方向的机器学习人才最紧缺? - 王喆的回答
要点简记:站在机器学习“工程体系”之上,综合考虑“模型结构”,“工程限制”,“问题目标”的算法“工程师”。我的理解:红利的迁移,模型结构单点创新带来的收益->体系结构协同带来的收益。 阿里技术副总裁贾扬清:我对人工智能的一点浅见
AI发展:神经网络和深度学习的成功与局限,成功原因是大数据和高性能计算,局限原因是结构化的理解和小数据上的有效学习算法。 AI这个方向会怎么走?传统的深度学习应用,比如图像、语音等,应该如何输出产品和价值?而不仅仅是停留在安防这个层面,要深入到更广阔的领域。除了语音和图像之外,如何解决更多问题?而不仅仅是停留在解决语音图像等几个领域内的问题。
综合素质
- 算法工程师必须要知道的面试技能雷达图(学到了)
个人发展-必备技术素质:算法工程师必备技术素质拆分:知识、工具、逻辑、业务。 On the basis of meeting the minimum requirements, algorithm engineers have relatively comprehensive capabilities in these four aspects, including both "algorithm" and "engineering", while big data engineers focus on "tools" and researchers focus on "knowledge" and "logic" .
针对安全业务的算法工程师就是安全算法工程师。为了便于理解,举个例子,如果用XGBoost解决某个安全问题,那么可以由浅入深理解,把知识、工具、逻辑、业务四个方面串起来:
1.GBDT的原理(知识)
2.决策树节点分裂时是如何选择特征的? (Conhecimento)
3.写出Gini Index和Information Gain的公式并举例说明(知识)
4.分类树和回归树的区别是什么(知识)
5.与Random Forest对比,理解什么是模型的偏差和方差(知识)
6.XGBoost的参数调优有哪些经验(工具)
7.XGBoost的正则化和并行化分别是如何实现的(工具)
8.为什么解决这个安全问题会出现严重的过拟合问题(业务)
9.如果选用一种其他模型替代XGBoost或改进XGBoost你会怎么做? Por que? (业务、逻辑、知识)。
以上,就是以“知识”为切入点,不仅深度理解了“知识”,也深度理解了“工具”、“逻辑”、“业务”。
- [校招经验] BAT机器学习算法实习面试记录(学到了)
个人发展-面试经验:根据面试常遇到的问题再深入理解机器学习,储备自己的算法知识库。 - 机器学习如何才能避免「只是调参数」? (Aprendido)
个人发展-职业发展:机器学习工程师分为三种:应用型(能力:保持算法全栈,即数据、建模、业务、运维、后端,重点在建模能力,流程是遇到一个指定的业务场景应该迅速知道用什么数据做特征,用什么模型,这个模型在工程上的时效性和鲁棒性,最终会不会产生业务风险等一整套链路。预期目标:锻炼得到很强的业务敏感性,快速验证提出的需求)、造轮子型(多读顶会跟上时代节奏,且拥有超强的功能能力,打造ML框架,提供给应用型机器学习工程师使用)、研究型(AI Lab,读论文+试验性复现)。 Personal development: Develop business and engineering capabilities. The growth plan for the next few years is still the full-stack algorithm route. I will be independent in technology and bring KPIs in business. I will be promoted quickly + lead the team in the future .同时保持阅读习惯,多学习新知识。 - 做机器学习算法工程师是什么样的工作体验?
个人发展-工作体验:业务理解、数据清洗和特征工程、持续学习(增强解决方案的判断力)、编程能力、常用工具(XGB、TensorFlow、ScikitLearn、Pandas(表格类数据或时间序列数据)、Spark、SQL、FbProphet(时间序列)) - 大三实习面经(学到了)
- 如果你是面试官,你怎么去判断一个面试者的深度学习水平?
个人发展-心得体会:深度学习擅长处理具有局部相关性的问题和数据,在图像、语音、自然语言处理方面效果显著,因为图像是由像素构成,语音是由音位构成,语言是由单词构成,都有局部相关性,可以构造高级特征。 - 面试官如何判断面试者的机器学习水平? - 微调的回答- 知乎
个人发展-心得体会:考虑方法优点和局限性,培养独立思考的能力;正确判断机器学习对业务的影响力;学会分情况讨论(比如深度学习相对于机器学习而言);学习机器学习不能停留在“知道”的层次,要从原理级学习,甚至可以从源码级学习,知其然知其所以然,要做安全圈机器学习最6的。 - 两年美团算法大佬的个人总结与学习建议
个人发展-心得体会:算法的基本认识(知识)、过硬的代码能力(工具)、数据处理和分析能力(业务和逻辑)、模型的积累和迁移能力(业务和逻辑)、产品能力、软实力。
Profissão
职业规划
pensamento
- 如何解决思维混乱、讲话没条理的情况? (Aprendido)
结构化思维->讲话有条理。 - 哪些思维方式是你刻意训练过的? (Aprendido)
结构化思维
金字塔思维:结论先行,以上统下,归类分组,逻辑递进。
金字塔结构:纵向延伸,横向分类。
如何得出金字塔结论:归纳法,演绎推理法。实际生活中,不是每时每刻都有相关的模型套用和演绎法的,这时候就用归纳法,自下而上进行梳理,得出结论,比如头脑风暴把闪过的碎片想法全部写下来,再抽象与分类,最后得出结论。 - 厉害的人是怎么分析问题的? (Aprendido)
Define the problem/describe the problem: The essence of the problem is the gap between reality and expectations ; clarify the expected value B', accurately locate the current situation B, and use the gap B--->B' to accurately describe the problema.
分析问题/解决问题:不能从现状B出发,找寻一条B--->B'的路径,要透过现象看本质。方法A,现实B,期望B',变量C。校准期望B',重构方法A,消除变量C。
comunicar
gerenciar
- “我是技术总监,你干嘛总问我技术细节?”
(快速发展期、平稳期、衰退期等业务发展时期作为时间轴)(中高层管理者)(需要掌握)(应用场景、技术基础、技术栈中的技术细节)。技术基础要扎实,技术栈了解程度深(对技术原理和细节清楚),应用场景不能浮于表面。总的来说就是一句话:技术细节与技术深度。 - 阿里巴巴高级算法专家威视:组建技术团队的一些思考(学到了)
行文思路:团队的定位(定位(能力、业务、服务)、壁垒(以不变应万变沉淀风险管控知识作为壁垒)和价值(提供不同层次的服务形式))-》团队的能力(连接、生产、传播、服务)-》组织与个人的关系-》招人-》用人-》对内管理模式(找对前进的方向、绩效的考核(3个维度:业务结果、能力进步、技术影响力))
学到了:建设技术体系解决某一类问题,而不是某个技术点去解决某一个问题。 - 26岁当上数据总监,分享第一次做Leader的心得
团队管理方面的基本功和方法论:定策略、建团队、立规矩、拿结果。
定策略:要明确公司高层的真实目的;对自己的团队了如指掌;管理者专精的行业知识和经验。
建团队:避免嫉贤妒能、职场近亲、玻璃心。
立规矩:立规矩守规矩。
拿结果:注意吃相。
管理中常见的误区:做管理后放弃原来专业(要关注行业发展方向和前沿技术);过度管理(要自循环的稳定成熟团队);过度追求团队稳定(衡量团队稳定的核心标准不是人员的稳定,而是团队的效率和产出是否能够有持续稳定的增长) - 什么特质的员工容易成为管理者
公司内部晋升管理者:天时:企业/行业所处的阶段;地利:部门/业务所处的阶段;人和:人际关系+自身能力。
跳槽成为管理者:大公司跳槽到小公司,寻找职业突破,弊端是跳出去容易跳回来难;成为行业内有影响力的人物,被大公司挖角。大部分人都是第一种情况,在大公司的同学要多一点耐心,通过努力在公司内晋升,因为曲线救国式的跳槽已经没有市场了。 - 技术部门Leader是不是一定要技术大牛担任?
核心点:Manager vs Tech Leader、方法论、软技能、赋能成员、综合。
pensar
- 好的研究想法从哪里来
研究的本质是对未知领域的探索,是对开放问题的答案的追寻。“好”的定义-》区分好与不好的能力-》全面了解所在研究方向的历史和现状-》实践法/类比法/组合法。这就好比是机器学习的训练和测试阶段,训练:全面了解所在研究方向的历史和现状,判断不同时期的研究工作的好与不好。测试:实践法/类比法/组合法出的idea,判断自己的研究工作好与不好。 - 科研论文如何想到不错的idea?
模块化学习、交叉、布局可预期的趋势。 - 人在年轻的时候,最核心的能力是什么?
核心点:达到以前从未达到的高度:基本的事情做到极致、专注、坚持长久做一件事、延迟满足、认清自己+了解环境->准确定位、
Coisas a serem observadas
- 领域点-线-面体系:点:自己focus的领域;线:上游和下游;面:大领域。不要过度focus在自己工作的领域,要有全局化的眼光,特别是自己的上游和下游。
- 日常学习点-线-面体系:点:自己focus的安全数据分析领域;线:安全/数据分析;面:全局安全内容/行业发展/职业规划。 Study a small field for at least one hour every day; read intensively for at least half an hour every day/at least one quality article on security/data analysis/industry development/career planning; browse a large number of incremental articles/stock articles diariamente.保持学习与思考的敏感性。
apêndice
国外优质技术站点
- https://resources.distilnetworks.com
站点概况:专注于机器流量对抗与缓解。 - http://www.covert.io
技术栈:Jason Trost,专注于安全研究、大数据、云计算、机器学习,即安全数据科学。 - http://cyberdatascientist.com
站点概括:专注于安全数据科学,提供网络安全、统计学和AI等学习资料,并提供14个安全数据集,包括:垃圾邮件、恶意网站、恶意软件、Botnet等。没有secrepo.com提供的资料全面。 - https://towardsdatascience.com
站点概括:专注于数据科学。
国内优秀技术人
- michael282694
技术栈:数据分析挖掘产品开发、爬虫、Java、Python。 - LittleHann
技术栈:我也不知道该怎么描述,Han师傅会的太多了,C++、Java、Python、PHP、Web安全、系统安全,不过目前好像做算法多一些。 - FeeiCN
技术栈:专注自动化漏洞发现和入侵检测防御。 - xiaojunjie
技术栈:专注于代码审计、CTF。 - 云雷
技术栈:阿里云存储技术专家,专注于日志分析与业务,日志计算驱动业务增长。 - Iami
技术栈:主要研究Web安全、机器学习,喜欢Python和Go。一直偷学师傅的博客。 - cdxy
技术栈:早先主要做Web安全,CTF,代码审计,现在主要做安全研究与数据分析,初步估算技术领先我1~2年,师傅别学了。 - csuldw
技术栈:专注于机器学习、数据挖掘、人工智能。 - molunerfinn
技术栈:专注于前端,北邮大佬,和404notfound同级。 - 刘建平Pinard
技术栈:机器学习、深度学习、强化学习、自然语言处理、数学统计学、大数据挖掘,相关tutorial非常棒。
abandonado
- Efficient and Flexible Discovery of PHP Vulnerability译文
- Efficient and Flexible Discovery of PHP Application Vulnerabilities原文
- The Code Analysis Platform "Octopus"
- A Code Intelligence System:The Octopus Platform


