flash attention jax
0.3.1
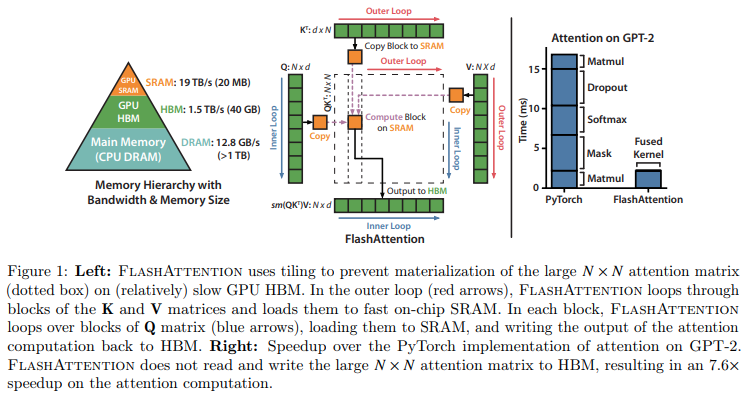
Implementação de Atenção Flash em Jax. Provavelmente não terá o mesmo desempenho da versão oficial CUDA, dada a falta de capacidade de gerenciamento preciso de memória. Mas apenas para fins educacionais e também para ver o quão inteligente o compilador XLA é (ou não).
$ pip install flash-attention-jax from jax import random
from flash_attention_jax import flash_attention
rng_key = random . PRNGKey ( 42 )
q = random . normal ( rng_key , ( 1 , 2 , 131072 , 512 )) # (batch, heads, seq, dim)
k = random . normal ( rng_key , ( 1 , 2 , 131072 , 512 ))
v = random . normal ( rng_key , ( 1 , 2 , 131072 , 512 ))
mask = random . randint ( rng_key , ( 1 , 131072 ,), 0 , 2 ) # (batch, seq)
out , _ = flash_attention ( q , k , v , mask )
out . shape # (1, 2, 131072, 512) - (batch, heads, seq, dim)Verificação rápida de sanidade
from flash_attention_jax import plain_attention , flash_attention , value_and_grad_difference
diff , ( dq_diff , dk_diff , dv_diff ) = value_and_grad_difference (
plain_attention ,
flash_attention ,
seed = 42
)
print ( 'shows differences between normal and flash attention for output, dq, dk, dv' )
print ( f'o: { diff } ' ) # < 1e-4
print ( f'dq: { dq_diff } ' ) # < 1e-6
print ( f'dk: { dk_diff } ' ) # < 1e-6
print ( f'dv: { dv_diff } ' ) # < 1e-6Atenção Flash Autoregressiva - atenção do decodificador tipo GPT
from jax import random
from flash_attention_jax import causal_flash_attention
rng_key = random . PRNGKey ( 42 )
q = random . normal ( rng_key , ( 131072 , 512 ))
k = random . normal ( rng_key , ( 131072 , 512 ))
v = random . normal ( rng_key , ( 131072 , 512 ))
out , _ = causal_flash_attention ( q , k , v )
out . shape # (131072, 512) dimensões principais para variante de atenção flash causal
descobrir o problema com jit e argnums estáticos
comentário com referências a algoritmos de papel e explicações
certifique-se de que ele pode funcionar com chaves/valores de uma só cabeça, como no PaLM
@article { Dao2022FlashAttentionFA ,
title = { FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness } ,
author = { Tri Dao and Daniel Y. Fu and Stefano Ermon and Atri Rudra and Christopher R'e } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2205.14135 }
} @article { Rabe2021SelfattentionDN ,
title = { Self-attention Does Not Need O(n2) Memory } ,
author = { Markus N. Rabe and Charles Staats } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2112.05682 }
}

