reaver
1.0.0
Status do projeto: Não é mais mantido!
Infelizmente, não posso mais desenvolver ou fornecer suporte ao projeto.
Reaver é uma estrutura modular de aprendizado por reforço profundo com foco em várias tarefas baseadas em StarCraft II, seguindo os passos da DeepMind que está promovendo o que há de mais moderno na área através das lentes de jogar um videogame moderno com interface semelhante à humana e limitações. Isso inclui observar características visuais semelhantes (embora não idênticas) às que um jogador humano perceberia e escolher ações de um conjunto semelhante de opções que um jogador humano teria. Consulte o artigo StarCraft II: Um novo desafio para aprendizado por reforço para obter mais detalhes.
Embora o desenvolvimento seja orientado pela pesquisa, a filosofia por trás da API Reaver é semelhante ao próprio jogo StarCraft II – ela tem algo a oferecer tanto para novatos quanto para especialistas na área. Para programadores amadores, o Reaver oferece todas as ferramentas necessárias para treinar agentes DRL, modificando apenas uma pequena e isolada parte do agente (por exemplo, hiperparâmetros). Para pesquisadores veteranos, o Reaver oferece uma base de código simples, mas com desempenho otimizado, com arquitetura modular: agente, modelo e ambiente são dissociados e podem ser trocados à vontade.
Embora o foco do Reaver esteja no StarCraft II, ele também tem suporte total para outros ambientes populares, principalmente Atari e MuJoCo. Os algoritmos do agente Reaver são validados em relação aos resultados de referência, por exemplo, o agente PPO é capaz de corresponder aos algoritmos de otimização de política proximal. Por favor, veja abaixo para mais detalhes.
A maneira mais fácil de instalar o Reaver é através do gerenciador de pacotes PIP :
pip install reaver
Você também pode instalar extras adicionais (por exemplo, suporte gym ) através das bandeiras auxiliares:
pip install reaver[gym,atari,mujoco]
Se você planeja modificar a base de código Reaver você pode manter a funcionalidade do módulo instalando a partir do código-fonte:
$ git clone https://github.com/inoryy/reaver-pysc2
$ pip install -e reaver-pysc2/
Ao instalar com o sinalizador -e , Python agora procurará reaver na pasta especificada, em vez do armazenamento site-packages .
Consulte a página wiki para obter instruções detalhadas sobre como configurar o Reaver no Windows.
No entanto, se possível, considere usar Linux OS - devido a considerações de desempenho e estabilidade. Se quiser ver o desempenho do seu agente com gráficos completos ativados, você pode salvar um replay do agente no Linux e abri-lo no Windows. Foi assim que foi feita a gravação do vídeo listado abaixo.
Se quiser usar o Reaver com outros ambientes suportados, você também deve instalar os pacotes relevantes:
Você pode treinar um agente DRL com vários ambientes de StarCraft II rodando em paralelo com apenas quatro linhas de código!
import reaver as rvr
env = rvr . envs . SC2Env ( map_name = 'MoveToBeacon' )
agent = rvr . agents . A2C ( env . obs_spec (), env . act_spec (), rvr . models . build_fully_conv , rvr . models . SC2MultiPolicy , n_envs = 4 )
agent . run ( env )Além disso, o Reaver vem com ferramentas de linha de comando altamente configuráveis, então esta tarefa pode ser reduzida a uma curta linha!
python -m reaver.run --env MoveToBeacon --agent a2c --n_envs 4 2> stderr.logCom a linha acima, o Reaver inicializará o procedimento de treinamento com um conjunto de hiperparâmetros predefinidos, otimizados especificamente para determinado ambiente e agente. Depois de um tempo, você começará a ver logs com várias estatísticas úteis na tela do seu terminal.
| T 118 | Fr 51200 | Ep 212 | Up 100 | RMe 0.14 | RSd 0.49 | RMa 3.00 | RMi 0.00 | Pl 0.017 | Vl 0.008 | El 0.0225 | Gr 3.493 | Fps 433 |
| T 238 | Fr 102400 | Ep 424 | Up 200 | RMe 0.92 | RSd 0.97 | RMa 4.00 | RMi 0.00 | Pl -0.196 | Vl 0.012 | El 0.0249 | Gr 1.791 | Fps 430 |
| T 359 | Fr 153600 | Ep 640 | Up 300 | RMe 1.80 | RSd 1.30 | RMa 6.00 | RMi 0.00 | Pl -0.035 | Vl 0.041 | El 0.0253 | Gr 1.832 | Fps 427 |
...
| T 1578 | Fr 665600 | Ep 2772 | Up 1300 | RMe 24.26 | RSd 3.19 | RMa 29.00 | RMi 0.00 | Pl 0.050 | Vl 1.242 | El 0.0174 | Gr 4.814 | Fps 421 |
| T 1695 | Fr 716800 | Ep 2984 | Up 1400 | RMe 24.31 | RSd 2.55 | RMa 30.00 | RMi 16.00 | Pl 0.005 | Vl 0.202 | El 0.0178 | Gr 56.385 | Fps 422 |
| T 1812 | Fr 768000 | Ep 3200 | Up 1500 | RMe 24.97 | RSd 1.89 | RMa 31.00 | RMi 21.00 | Pl -0.075 | Vl 1.385 | El 0.0176 | Gr 17.619 | Fps 423 |
Reaver deve convergir rapidamente para cerca de 25-26 RMe (recompensas médias de episódios), o que corresponde aos resultados do DeepMind para este ambiente. O tempo de treinamento específico depende do seu hardware. Os logs acima são produzidos em um laptop com CPU Intel i5-7300HQ (4 núcleos) e GPU GTX 1050, o treinamento durou cerca de 30 minutos.
Depois que o Reaver terminar o treinamento, você poderá observar seu desempenho anexando os sinalizadores --test e --render ao one-liner.
python -m reaver.run --env MoveToBeacon --agent a2c --test --render 2> stderr.logUm notebook complementar do Google Colab está disponível para testar o Reaver online.
Muitos algoritmos DRL modernos dependem de serem executados em vários ambientes ao mesmo tempo e em paralelo. Como Python possui GIL, esse recurso deve ser implementado por meio de multiprocessamento. A maioria das implementações de código aberto resolve esta tarefa com uma abordagem baseada em mensagens (por exemplo, Python multiprocessing.Pipe ou MPI ), onde processos individuais se comunicam enviando dados através de IPC. Esta é uma abordagem válida e provavelmente apenas razoável para abordagens distribuídas em larga escala nas quais empresas como DeepMind e openAI operam.
No entanto, para um pesquisador ou hobbyista típico, um cenário muito mais comum é ter acesso apenas a um único ambiente de máquina, seja um laptop ou um nó em um cluster HPC. O Reaver é otimizado especificamente para este caso, fazendo uso da memória compartilhada sem bloqueios. Esta abordagem proporciona um aumento significativo de desempenho de até 1,5x de aceleração na taxa de amostragem de StarCraft II (e até 100x de aceleração no caso geral), sendo prejudicada quase exclusivamente pelo pipeline de entrada/saída da GPU.
Os três módulos principais do Reaver - envs , models e agents são quase completamente separados uns dos outros. Isso garante que a extensão da funcionalidade em um módulo seja perfeitamente integrada aos outros.
Toda a configuração é feita através do gin-config e pode ser facilmente compartilhada como arquivos .gin . Isso inclui todos os hiperparâmetros, argumentos de ambiente e definições de modelo.
Ao experimentar ideias novas, é importante obter feedback rapidamente, o que muitas vezes não é realista em ambientes complexos como StarCraft II. Como o Reaver foi construído com arquitetura modular, suas implementações de agentes não estão vinculadas ao StarCraft II. Você pode fazer substituições imediatas para muitos ambientes de jogos populares (por exemplo, openAI gym ) e verificar se as implementações funcionam com eles primeiro:
python -m reaver.run --env CartPole-v0 --agent a2c 2> stderr.log import reaver as rvr
env = rvr . envs . GymEnv ( 'CartPole-v0' )
agent = rvr . agents . A2C ( env . obs_spec (), env . act_spec ())
agent . run ( env )Atualmente os seguintes ambientes são suportados pelo Reaver:
CartPole-v0 )PongNoFrameskip-v0 )InvertedPendulum-v2 e HalfCheetah-v2 ) | Mapa | Reaver (A2C) | DeepMind SC2LE | DeepMind ReDRL | Especialista Humano |
|---|---|---|---|---|
| MoveToBeacon | 26,3 (1,8) [21, 31] | 26 | 27 | 28 |
| Coletar Fragmentos Minerais | 102,8 (10,8) [81, 135] | 103 | 196 | 177 |
| DerrotaRoaches | 72,5 (43,5) [21, 283] | 100 | 303 | 215 |
| Encontre e derrote Zergnídeos | 22,1 (3,6) [12, 40] | 45 | 62 | 61 |
| Derrote Zergnídeos e Banelings | 56,8 (20,8) [21, 154] | 62 | 736 | 727 |
| Coletar minerais e gás | 2267,5 (488,8) [0, 3320] | 3.978 | 5.055 | 7.566 |
| Construir Marinhas | -- | 3 | 123 | 133 |
Human Expert foram coletados pela DeepMind de um jogador de nível GrandMaster.DeepMind ReDRL refere-se aos resultados atuais de última geração, descritos no artigo Relational Deep Reinforcement Learning.DeepMind SC2LE são resultados publicados no artigo StarCraft II: A New Challenge for Reinforcement Learning.Reaver (A2C) são resultados obtidos pelo treinamento do agente reaver.agents.A2C , replicando a arquitetura SC2LE o mais próximo possível do hardware disponível. Os resultados são coletados executando o agente treinado no modo --test por 100 episódios, calculando as recompensas totais dos episódios. Listados estão a média, o desvio padrão (entre parênteses) e o mínimo e o máximo (entre colchetes).| Mapa | Amostras | Episódios | Aprox. Tempo (h) |
|---|---|---|---|
| MoveToBeacon | 563.200 | 2.304 | 0,5 |
| Coletar Fragmentos Minerais | 74.752.000 | 311.426 | 50 |
| DerrotaRoaches | 172.800.000 | 1.609.211 | 150 |
| Encontre e derrote Zergnídeos | 29.760.000 | 89.654 | 20 |
| Derrote Zergnídeos e Banelings | 10.496.000 | 273.463 | 15 |
| Coletar minerais e gás | 16.864.000 | 20.544 | 10 |
| Construir Marinhas | - | - | - |
Samples referem-se ao número total de cadeias de observe -> step -> reward em um ambiente.Episodes referem-se ao número total de sinalizadores StepType.LAST retornados pelo PySC2.Approx. Time é o tempo aproximado de treinamento em um laptop com CPU Intel i5-7300HQ (4 núcleos) e GPU GTX 1050 . Observe que não dediquei muito tempo ao ajuste de hiperparâmetros, concentrando-me principalmente em verificar se o agente é capaz de aprender, em vez de maximizar a eficiência da amostra. Por exemplo, a primeira tentativa ingênua no MoveToBeacon exigiu cerca de 4 milhões de amostras, no entanto, depois de algumas brincadeiras, consegui reduzi-lo para 102.000 (redução de aproximadamente 40x) com o agente PPO.
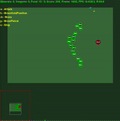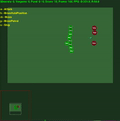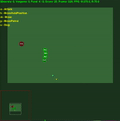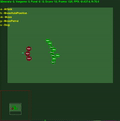
Recompensas médias do episódio com std.dev preenchido no meio. Clique para ampliar.
Uma gravação de vídeo do agente atuando em todos os seis minijogos está disponível online em: https://youtu.be/gEyBzcPU5-w. No vídeo à esquerda está o agente atuando com pesos inicializados aleatoriamente e sem treinamento, enquanto à direita ele é treinado para atingir pontuações.
O problema da reprodutibilidade da pesquisa tornou-se recentemente objeto de muitos debates na ciência em geral, e o Aprendizado por Reforço não é uma exceção. Um dos objetivos do Reaver como projeto científico é ajudar a facilitar pesquisas reproduzíveis. Para este fim, o Reaver vem com várias ferramentas que simplificam o processo:
Para liderar o caminho em termos de reprodutibilidade, Reaver vem com pesos pré-treinados e registros de resumo completos do Tensorboard para todos os seis minijogos. Basta baixar um arquivo de experimento na guia de lançamentos e descompactá-lo no diretório results/ .
Você pode usar pesos pré-treinados anexando o sinalizador --experiment ao comando reaver.run :
python reaver.run --map <map_name> --experiment <map_name>_reaver --test 2> stderr.log
Os logs do Tensorboard estarão disponíveis se você iniciar tensorboard --logidr=results/summaries .
Você também pode visualizá-los diretamente online através do Aughie Boards.
Reaver é uma unidade Protoss muito especial e subjetivamente fofa no universo do jogo StarCraft. Na versão StarCraft: Brood War do jogo, Reaver era famoso por ser lento, desajeitado e muitas vezes quase inútil se deixado sozinho devido a bugs na IA do jogo. No entanto, nas mãos de jogadores dedicados que investiram tempo no domínio da unidade, Reaver se tornou um dos ativos mais poderosos do jogo, muitas vezes desempenhando um papel fundamental na vitória de torneios.
Um antecessor do Reaver, denominado simplesmente pysc2-rl-agent , foi desenvolvido como parte prática da tese de bacharelado na Universidade de Tartu sob a supervisão de Ilya Kuzovkin e Tambet Matiisen. Você ainda pode acessá-lo na ramificação v1.0.
Se você encontrar um problema relacionado à base de código, abra um ticket no GitHub e descreva-o com o máximo de detalhes possível. Se você tiver dúvidas mais gerais ou simplesmente estiver procurando aconselhamento, sinta-se à vontade para me enviar um e-mail.
Também sou um membro orgulhoso de uma comunidade online SC2AI ativa e amigável. Usamos principalmente o Discord para comunicação. Pessoas de todas as origens e níveis de especialização são bem-vindas!
Se você achou o Reaver útil em sua pesquisa, considere citá-lo com o seguinte bibtex:
@misc{reaver,
author = {Ring, Roman},
title = {Reaver: Modular Deep Reinforcement Learning Framework},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/inoryy/reaver}},
}


