RoboFlamingo
1.0.0
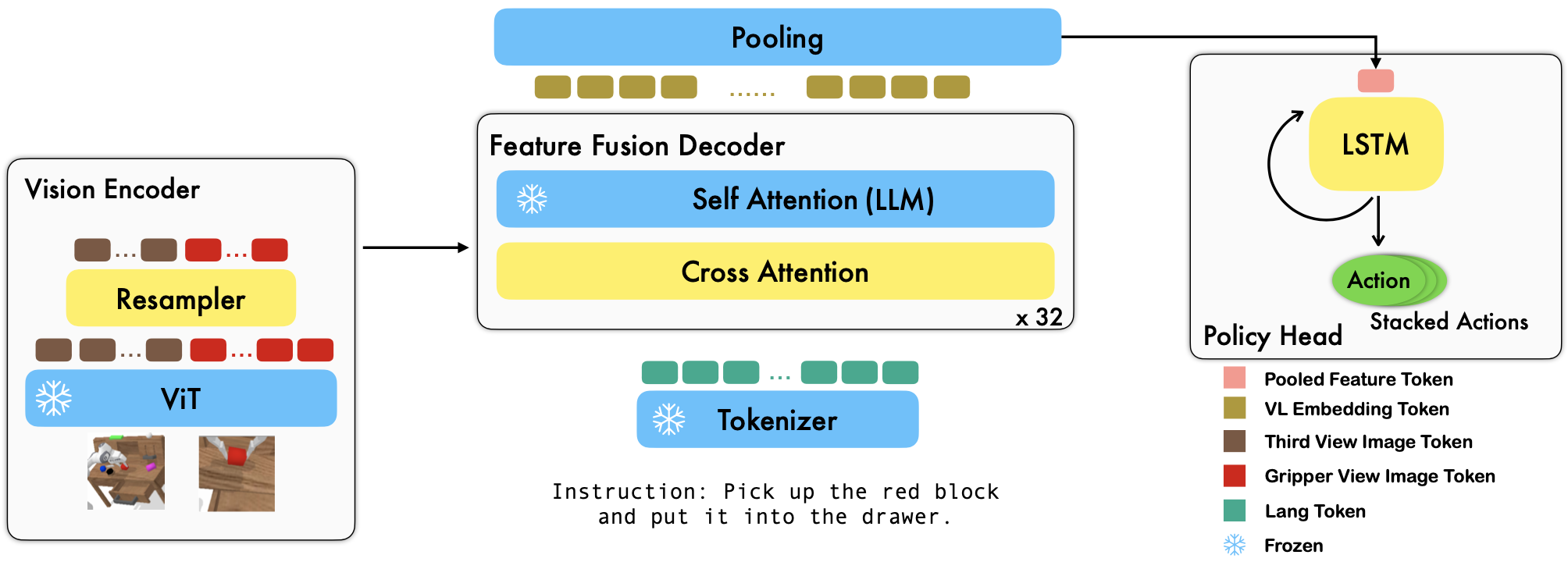
RoboFlamingo é uma estrutura de aprendizagem robótica baseada em VLM pré-treinada que aprende uma ampla variedade de habilidades de robôs condicionadas à linguagem, ajustando conjuntos de dados de imitação de formato livre off-line. Ao superar o desempenho de última geração com uma grande margem no benchmark CALVIN, mostramos que o RoboFlamingo pode ser uma alternativa eficaz e competitiva para adaptar VLMs ao controle de robôs. Nossos extensos resultados experimentais também revelam várias conclusões interessantes sobre o comportamento de diferentes VLMs pré-treinados em tarefas de manipulação. O RoboFlamingo pode ser treinado ou avaliado em um único servidor GPU (os requisitos de memória da GPU dependem do tamanho do modelo) e acreditamos que o RoboFlamingo tem potencial para ser uma solução econômica e fácil de usar para manipulação robótica, capacitando todos com o capacidade de aperfeiçoar a sua própria política de robótica.
Este também é o repositório de código oficial para o artigo Vision-Language Foundation Models as Effective Robot Imitators.
Todos os nossos experimentos são conduzidos em um único servidor GPU com 8 GPUs Nvidia A100 (80G).
Modelos pré-treinados estão disponíveis no Hugging Face.
Oferecemos suporte a codificadores de visão pré-treinados do pacote OpenCLIP, que inclui modelos pré-treinados da OpenAI. Também oferecemos suporte a modelos de linguagem pré-treinados do pacote transformers , como modelos MPT, RedPajama, LLaMA, OPT, GPT-Neo, GPT-J e Pythia.
from robot_flamingo . factor import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "PATH/TO/LLM/DIR" ,
tokenizer_path = "PATH/TO/LLM/DIR" ,
cross_attn_every_n_layers = 1 ,
decoder_type = 'lstm' ,
) O argumento cross_attn_every_n_layers controla a frequência com que as camadas de atenção cruzada são aplicadas e deve ser consistente com o VLM. O argumento decoder_type controla o tipo do decodificador, atualmente suportamos lstm , fc , diffusion (existem bugs para o dataloader) e GPT .
Reportamos resultados no benchmark CALVIN.
| Método | Dados de treinamento | Divisão de teste | 1 | 2 | 3 | 4 | 5 | Lento médio |
|---|---|---|---|---|---|---|---|---|
| MCIL | ABCD (completo) | D | 0,373 | 0,027 | 0,002 | 0,000 | 0,000 | 0,40 |
| HULC | ABCD (completo) | D | 0,889 | 0,733 | 0,587 | 0,475 | 0,383 | 3.06 |
| HULC (retreinado) | ABCD (Lang) | D | 0,892 | 0,701 | 0,548 | 0,420 | 0,335 | 2,90 |
| RT-1 (retreinado) | ABCD (Lang) | D | 0,844 | 0,617 | 0,438 | 0,323 | 0,227 | 2,45 |
| Nosso | ABCD (Lang) | D | 0,964 | 0,896 | 0,824 | 0,740 | 0,66 | 4.09 |
| MCIL | ABC (completo) | D | 0,304 | 0,013 | 0,002 | 0,000 | 0,000 | 0,31 |
| HULC | ABC (completo) | D | 0,418 | 0,165 | 0,057 | 0,019 | 0,011 | 0,67 |
| RT-1 (retreinado) | ABC (Lang) | D | 0,533 | 0,222 | 0,094 | 0,038 | 0,013 | 0,90 |
| Nosso | ABC (Lang) | D | 0,824 | 0,619 | 0,466 | 0,331 | 0,235 | 2,48 |
| HULC | ABCD (completo) | D (enriquecer) | 0,715 | 0,470 | 0,308 | 0,199 | 0,130 | 1,82 |
| RT-1 (retreinado) | ABCD (Lang) | D (enriquecer) | 0,494 | 0,222 | 0,086 | 0,036 | 0,017 | 0,86 |
| Nosso | ABCD (Lang) | D (enriquecer) | 0,720 | 0,480 | 0,299 | 0,211 | 0,144 | 1,85 |
| Nosso (congelar-emb) | ABCD (Lang) | D (enriquecer) | 0,737 | 0,530 | 0,385 | 0,275 | 0,192 | 2.12 |
Siga as instruções no OpenFlamingo e CALVIN para baixar o conjunto de dados necessário e os modelos pré-treinados do VLM.
Baixe o conjunto de dados CALVIN, escolha uma divisão com:
cd $HULC_ROOT /dataset
sh download_data.sh D | ABC | ABCD | debugBaixe os modelos OpenFlamingo lançados:
| # parâmetros | Modelo de linguagem | Codificador de visão | Intervalo Xattn* | COCO CIDE de 4 doses | Precisão de 4 disparos VQAv2 | Lento médio | Pesos |
|---|---|---|---|---|---|---|---|
| 3B | anas-awadalla/mpt-1b-redpajama-200b | openai CLIP ViT-L/14 | 1 | 77,3 | 45,8 | 3,94 | Link |
| 3B | anas-awadalla/mpt-1b-redpajama-200b-dolly | openai CLIP ViT-L/14 | 1 | 82,7 | 45,7 | 4.09 | Link |
| 4B | computador juntos/RedPajama-INCITE-Base-3B-v1 | openai CLIP ViT-L/14 | 2 | 81,8 | 49,0 | 3,67 | Link |
| 4B | computador juntos/RedPajama-INCITE-Instruct-3B-v1 | openai CLIP ViT-L/14 | 2 | 85,8 | 49,0 | 3,79 | Link |
| 9B | anas-awadalla/mpt-7b | openai CLIP ViT-L/14 | 4 | 89,0 | 54,8 | 3,97 | Link |
Substitua ${lang_encoder_path} e ${tokenizer_path} do dicionário de caminho (por exemplo, mpt_dict ) em robot_flamingo/models/factory.py para cada VLM pré-treinado por seus próprios caminhos.
Clonar este repositório
git clone https://github.com/RoboFlamingo/RoboFlamingo.git
Instale os pacotes necessários:
cd RoboFlamingo
conda create -n RoboFlamingo python=3.8
source activate RoboFlamingo
pip install -r requirements.txt
torchrun --nnodes=1 --nproc_per_node=8 --master_port=6042 robot_flamingo/train/train_calvin.py
--report_to_wandb
--llm_name mpt_dolly_3b
--traj_cons
--use_gripper
--fusion_mode post
--rgb_pad 10
--gripper_pad 4
--precision fp32
--num_epochs 5
--gradient_accumulation_steps 1
--batch_size_calvin 6
--run_name RobotFlamingoDBG
--calvin_dataset ${calvin_dataset_path}
--lm_path ${lm_path}
--tokenizer_path ${tokenizer_path}
--openflamingo_checkpoint ${openflamingo_checkpoint}
--cross_attn_every_n_layers 4
--dataset_resampled
--loss_multiplier_calvin 1.0
--workers 1
--lr_scheduler constant
--warmup_steps 5000
--learning_rate 1e-4
--save_every_iter 10000
--from_scratch
--window_size 12 > ${log_file} 2>&1
${calvin_dataset_path} é o caminho para o conjunto de dados CALVIN;
${lm_path} é o caminho para o LLM pré-treinado;
${tokenizer_path} é o caminho para o tokenizer VLM;
${openflamingo_checkpoint} é o caminho para o modelo pré-treinado do OpenFlamingo;
${log_file} é o caminho para o arquivo de log.
Também fornecemos robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b.bash para iniciar o treinamento. Este bash ajusta a versão MPT-3B-IFT do modelo OpenFlamingo, que contém os hiperparâmetros padrão para treinar o modelo e corresponde aos melhores resultados do artigo.
python eval_ckpts.py
Ao adicionar o nome do ponto de verificação e o diretório em eval_ckpts.py , o script carregaria automaticamente o modelo e o avaliaria. Por exemplo, se você quiser avaliar o ponto de verificação no caminho 'your-checkpoint-path', você pode modificar as variáveis ckpt_dir e ckpt_names em eval_ckpts.py, e os resultados da avaliação serão salvos como 'logs/your-checkpoint-prefix. registro'.
Os resultados mostrados abaixo indicam que o co-treinamento poderia preservar a maior parte da capacidade do backbone do VLM em tarefas de VL, enquanto perde um pouco de desempenho em tarefas de robô.
usar
bash robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b_co_train.bash
para lançar o co-treinamento RoboFlamingo com CoCO, VQAV2 e CALVIN. Você deve atualizar os caminhos CoCO e VQA em get_coco_dataset e get_vqa_dataset em robot_flamingo/data/data.py .
| Dividir | RS 1 | RS 2 | RS 3 | RS 4 | RS 5 | Lento médio |
|---|---|---|---|---|---|---|
| Co-treinar | ABC->D | 82,9% | 63,6% | 45,3% | 32,1% | 23,4% |
| Afinar | ABC->D | 82,4% | 61,9% | 46,6% | 33,1% | 23,5% |
| Co-treinar | ABCD->D | 95,7% | 85,8% | 73,7% | 64,5% | 56,1% |
| Afinar | ABCD->D | 96,4% | 89,6% | 82,4% | 74,0% | 66,2% |
| Co-treinar | ABCD->D (Enriquecer) | 67,8% | 45,2% | 29,4% | 18,9% | 11,7% |
| Afinar | ABCD->D (Enriquecer) | 72,0% | 48,0% | 29,9% | 21,1% | 14,4% |
| coco | Controle de Qualidade de Qualidade | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| AZUL-1 | AZUL-2 | AZUL-3 | AZUL-4 | METEORO | ROUGE_L | Cidra | ESPECIARIA | Conta | |
| Ajuste fino (3B, tiro zero) | 0,156 | 0,051 | 0,018 | 0,007 | 0,038 | 0,148 | 0,004 | 0,006 | 4.09 |
| Ajuste fino (3B, 4 fotos) | 0,166 | 0,056 | 0,020 | 0,008 | 0,042 | 0,158 | 0,004 | 0,008 | 3,87 |
| Co-treinamento (3B, tiro zero) | 0,225 | 0,158 | 0,107 | 0,072 | 0,124 | 0,334 | 0,345 | 0,085 | 36,37 |
| Flamingo Original (80B, ajustado) | - | - | - | - | - | - | 1.381 | - | 82,0 |
O logotipo é gerado usando MidJourney
Este trabalho usa código dos seguintes projetos e conjuntos de dados de código aberto:
Original: https://github.com/mees/calvin Licença: MIT
Original: https://github.com/openai/CLIP Licença: MIT
Original: https://github.com/mlfoundations/open_flamingo Licença: MIT
@article{li2023vision,
title = {Vision-Language Foundation Models as Effective Robot Imitators},
author = {Li, Xinghang and Liu, Minghuan and Zhang, Hanbo and Yu, Cunjun and Xu, Jie and Wu, Hongtao and Cheang, Chilam and Jing, Ya and Zhang, Weinan and Liu, Huaping and Li, Hang and Kong, Tao},
journal={arXiv preprint arXiv:2311.01378},
year={2023}


