эффективный детектор языка
3.0.0
Эффективный детектор языка ( Nito-ELD или ELD ) — это быстрое и точное программное обеспечение для определения естественного языка, написанное на 100% на PHP, со скоростью, сравнимой с быстрыми детекторами, скомпилированными на C++, и точностью в диапазоне лучших детекторов на сегодняшний день.
У него нет зависимостей, простая установка, все что нужно — это PHP с расширением mb .
ELD также доступен (устаревшие версии) на Javascript и Python.
Установка
Как использовать
Тесты
Базы данных
Тестирование
Языки
Изменения с ELD v2 на v3:
детектор()->язык теперь возвращает строку
'und'для неопределенного значения вместоNULLБазы данных несовместимы, больше, средний v2 ≈ маленький v3.
Функция DynamicLangSubset() удалена.
Функция cleanText() теперь называется EnableTextCleanup().
$ композитору требуется nitotm/efficiency-language-detector
--prefer-dist будет пропускать тесты/ , разное/ и бенчмарк/ или использовать --prefer-source , чтобы включить все
Установите nitotm/efficient-language-detector:dev-main чтобы опробовать последние нестабильные изменения.
Альтернативно, загрузка/клонирование файлов может работать нормально.
(Только небольшая БД устанавливается в стадии разработки)
Рекомендуется использовать OPcache, особенно для больших баз данных, чтобы сократить время загрузки.
Нам нужно установить opcache.interned_strings_buffer и opcache.memory_consumption достаточно высокими для каждой базы данных.
Рекомендуемое значение в скобках. Проверьте базы данных для получения дополнительной информации.
| настройка php.ini | Маленький | Середина | Большой | Очень большой |
|---|---|---|---|---|
memory_limit | >= 128 | >= 340 | >= 1060 | >= 2200 |
opcache.interned... | >= 8 (16) | >= 16 (32) | >= 60 (70) | >= 116 (128) |
opcache.memory | >= 64 (128) | >= 128 (230) | >= 360 (450) | >= 750 (820) |
detect() ожидает строку UTF-8 и возвращает объект со свойством language , содержащий код ISO 639-1 (или другой выбранный формат) или 'und' для неопределенного языка.
// require_once 'manual_loader.php'; Загрузить ELD без автозагрузчика. Обновить path.use NitotmEld{LanguageDetector, EldDataFile, EldFormat};// LanguageDetector(databaseFile: ?string, outputFormat: ?string)$eld = new LanguageDetector(EldDataFile::SMALL, EldFormat::ISO639_1);// Файлы базы данных: ' маленький», «средний», «большой», «очень большой». Проверьте требования к памяти // Форматы: 'ISO639_1', 'ISO639_2T', 'ISO639_1_BCP47', 'ISO639_2T_BCP47' и 'FULL_TEXT'// Константы не являются обязательными, LanguageDetector('small', 'ISO639_1'); также будет работать $eld->detect('Привет, как тебе ламы?');// object( Language => string, Scores() => array, isReliable() => bool )// ( язык => 'es', оценки() => ['es' => 0,25, 'nl' => 0,05], isReliable() => true )$eld->detect('Привет, как тебе ламы?') ->язык;// 'es' Вызов langSubset() один раз установит подмножество. Первый вызов занимает больше времени, так как создает новую базу данных. Если сохранить файл базы данных (по умолчанию), он будет загружен в следующий раз, когда мы создадим то же подмножество.
Чтобы использовать подмножество без дополнительных затрат, правильным способом будет создать экземпляр детектора с файлом, сохраненным и возвращенным langSubset() . Проверьте доступные языки ниже.
// Он всегда принимает коды ISO 639-1, а также выбранный формат вывода, если он отличается. // langSubset(languages: [], save: true, encode: true); Возвращает имя файла подмножества, если оно сохранено$eld->langSubset(['en', 'es', 'fr', 'it', 'nl', 'de']);// Object ( Success => bool, Languages => ?array, error => ?string, file => ?string )// ( успех => true, языки => ['en', 'es'...], error => NULL, file => ' small_6_mfss...' )// чтобы удалить подмножество $eld->langSubset();// Лучший и самый быстрый способ использовать подмножество — загрузить его так же, как базу данных по умолчанию $eld_subset = new NitotmEldLanguageDetector('small_6_mfss5z1t' );// если EnableTextCleanup(True), методDetect() удаляет URL-адреса, домены .com, электронные письма, буквенно-цифровые символы...// Не рекомендуется, так как URL-адреса и домены содержат намеки на язык, что может повысить точность $eld->enableTextCleanup(true ); // По умолчанию — false// При необходимости мы можем получить информацию об экземпляре ELD: языки, тип базы данных и т. д. $eld->info();
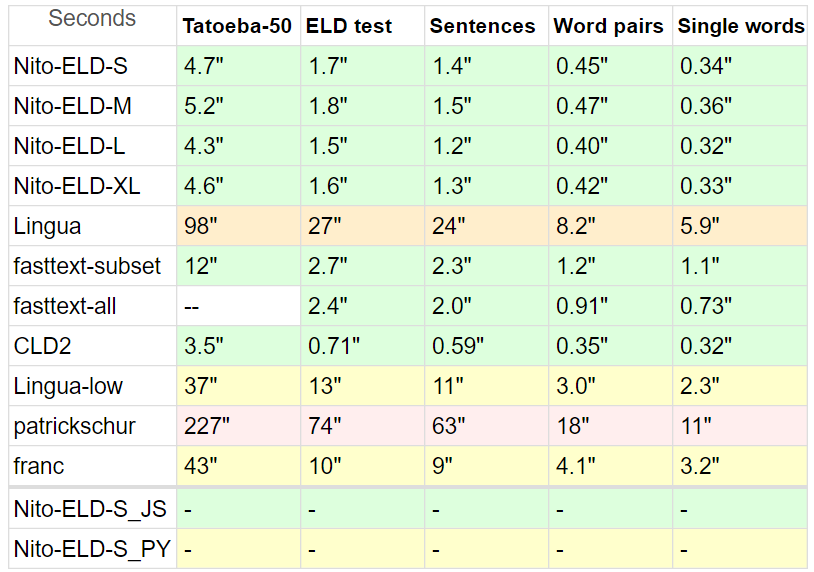
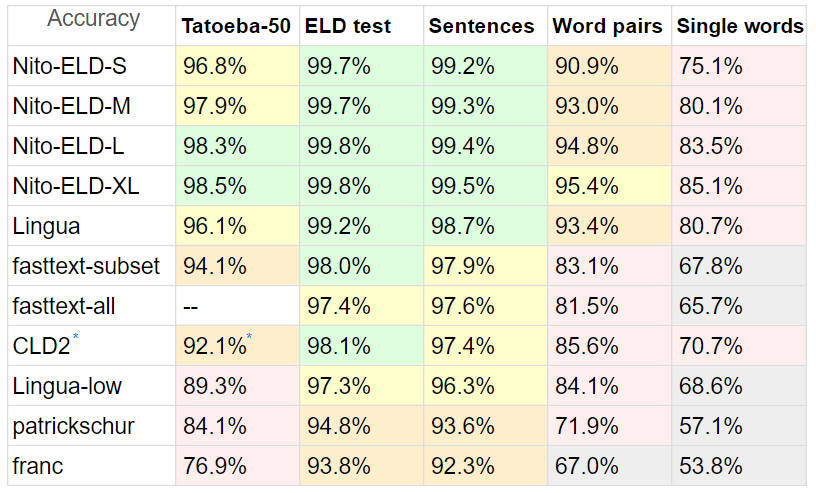
Я сравнивал ELD с разными детекторами, так как в PHP их не так много.
| URL-адрес | Версия | Язык |
|---|---|---|
| https://github.com/nitotm/efficient-language-detector/ | 3.0.0 | PHP |
| https://github.com/pemistahl/lingua-py | 2.0.2 | Питон |
| https://github.com/facebookresearch/fastText | 0.9.2 | С++ |
| https://github.com/CLD2Owners/cld2 | 21 августа 2015 г. | С++ |
| https://github.com/patrickschur/language-detection | 5.3.0 | PHP |
| https://github.com/wooorm/franc | 7.2.0 | Javascript |
Тесты:
Tatoeba : 20 МБ , короткие предложения с Tatoeba, 50 языков, поддерживаемых всеми претендентами, до 10 тысяч строк каждый.
Для Tatoeba я ограничил все детекторы 50 языками, чтобы сделать сравнение максимально объективным.
Кроме того, Tatoeba не является частью набора обучающих данных ELD (и не настраивается), но предназначен для быстрого текста.
ELD Test : 10 МБ , предложения с 60 языков, поддерживаемых ELD, по 1000 строк каждое. Извлечено из 60 ГБ данных обучения ELD.
Предложения : 8 МБ , предложения из теста Lingua , за исключением неподдерживаемых языков и йоруба, в которых были неработающие символы.
Пары слов 1,5 МБ и отдельные слова 870 КБ , также из Lingua, на тех же 53 языках.


Lingua участвует с 54 языками, франк - с 58, патриксур - с 54.
У fasttext нет встроенной опции подмножества, поэтому, чтобы показать его точность и потенциал скорости, я сделал два теста: fasttext — все они не ограничиваются каким-либо подмножеством ни в одном тесте.
* В Google CLD2 также отсутствует параметр подмножества, и сложно создать подмножество даже с его параметром bestEffort = True , поскольку обычно возвращает только один язык, поэтому он имеет сравнительный недостаток.
Время нормализуется: (общее количество строк * время)/обработанные строки
| Маленький | Середина | Большой | Очень большой | |
|---|---|---|---|---|
| Плюсы | Самая низкая память | Уравновешенный | Самый быстрый | Самый точный |
| Минусы | Наименее точный | Самый медленный (но быстрый) | Высокая память | Самая высокая память |
| Размер файла | 3 МБ | 10 МБ | 32 МБ | 71 МБ |
| Использование памяти | 76 МБ | 280 МБ | 977 МБ | 2083 МБ |
| Использование памяти Кэшировано | 0,4 МБ + ОП | 0,4 МБ + ОП | 0,4 МБ + ОП | 0,4 МБ + ОП |
| OPcache использовал память | 21 МБ | 69 МБ | 244 МБ | 539 МБ |
| OPcache используется интернировано | 4 МБ | 10 МБ | 45 МБ | 98 МБ |
| Время загрузки | 0,14 секунды | 0,5 секунды | 1,5 секунды | 3,4 сек. |
| Время загрузки Кэшировано | 0,0002 секунды | 0,0002 секунды | 0,0002 секунды | 0,0002 секунды |
| Настройки (рекомендуется) | ||||
memory_limit | >= 128 | >= 340 | >= 1060 | >= 2200 |
opcache.interned... * | >= 8 (16) | >= 16 (32) | >= 60 (70) | >= 116 (128) |
opcache.memory | >= 64 (128) | >= 128 (230) | >= 360 (450) | >= 750 (820) |
* Я рекомендую использовать более чем достаточное количество interned_strings_buffer , поскольку ошибка переполнения буфера может задержать ответ сервера.
Для использования всех баз данных opcache.interned_strings_buffer должен иметь размер минимум 160 МБ (170 МБ).
При выборе объема памяти помните opcache.memory_consumption включает opcache.interned_strings_buffer .
Если память OPcache равна 230 МБ, interned_strings — 32 МБ, а средняя БД — 69 МБ кэшированной, у нас есть в общей сложности (230-32-69) = 129 МБ OPcache для всего остального.
Кроме того, если вы собираетесь использовать подмножество языков в дополнение к основной базе данных или несколько подмножеств, соответственно увеличьте opcache.memory , если вы хотите, чтобы они загружались мгновенно. Для удобного кэширования всех баз данных по умолчанию вам следует установить размер 1200 МБ.
Установка композитора по умолчанию может не включать эти файлы. Используйте --prefer-source чтобы включить их.
Для среды разработки с композитором «autoload-dev» (только root) следующие тесты будут выполняться:
новый NitotmEldTestsTestsAutoload();
Или вы также можете запустить тесты, выполнив следующий файл:
$ php эффективный-language-detector/tests/tests.php # Путь обновления
Чтобы запустить тесты точности, запустите файл benchmark/bench.php .
Это коды ISO 639-1 , которые включают 60 языков. Плюс 'und' для неопределенного
Это формат языка ELD по умолчанию. outputFormat: 'ISO639_1'
am, ar, az, be, bg, bn, ca, cs, da, de, el, en, es, et, eu, fa, fi, fr, gu, he, hi, hr, hu, hy, is, it, ja, ka, kn, ko, ku, lo, lt, lv, ml, mr, ms, nl, no, or, pa, pl, pt, ro, ru, sk, sl, sq, sr, sv, та, тэ, ч, тл, тр, великобритания, ур, ви, йо, ж
Это 60 поддерживаемых языков для Nito-ELD . outputFormat: 'FULL_TEXT'
Амхарский, арабский, азербайджанский (латиница), белорусский, болгарский, бенгальский, каталанский, чешский, датский, немецкий, греческий, английский, испанский, эстонский, баскский, персидский, финский, французский, гуджарати, иврит, хинди, хорватский, венгерский, армянский , исландский, итальянский, японский, грузинский, каннада, корейский, курдский (арабский), лаосский, литовский, латышский, малаялам, маратхи, малайский (латиница), голландский, норвежский, ория, пенджабский, польский, португальский, румынский, русский, словацкий , словенский, албанский, сербский (кириллица), шведский, тамильский, телугу, тайский, тагальский, турецкий, украинский, урду, вьетнамский, йоруба, китайский
Коды ISO 639-1 с тегом имени сценария IETF BCP 47. outputFormat: 'ISO639_1_BCP47'
am, ar, az-Latn, be, bg, bn, ca, cs, da, de, el, en, es, et, eu, fa, fi, fr, gu, he, hi, hr, hu, hy, is, it, ja, ka, kn, ko, ku-араб, lo, lt, lv, ml, mr, ms-Latn, nl, no, или, pa, pl, pt, ro, ru, sk, sl, sq, sr-Cyrl, sv, ta, te, th, tl, tr, uk, ur, vi, yo, zh
Коды ISO 639-2/T (которые также действительны 639-3 ) outputFormat: 'ISO639_2T' . Также доступен с BCP 47 ISO639_2T_BCP47
amh, ara, aze, bel, bul, ben, cat, ces, dan, deu, ell, eng, spa, est, eus, fas, fin, fra, guj, heb, hin, hrv, hun, hye, isl, ita, япония, кат, кан, кор, кур, лао, лит, лав, мал, мар, мса, нлд, нор, ори, пан, поль, пор, рон, рус, slk, slv, sqi, srp, swe, там, тел, та, тгл, тур, укр, урд, вие, йор, жо
Если вы хотите сделать пожертвование на улучшения открытого исходного кода, нанять меня для частных модификаций, запросить обучение альтернативным наборам данных или связаться со мной, воспользуйтесь следующей ссылкой: https://linktr.ee/nitotm