Статья: Обобщение моделей визуального языка с нулевым выстрелом во время тестирования: действительно ли нам нужно быстрое обучение? .
Авторы: Максим Занелла, Исмаил Бен Айед.
Это официальный репозиторий GitHub для нашей статьи, принятой на CVPR '24. В этой работе представлен метод увеличения времени тестирования (MTA) MeanShift, использующий модели Vision-Language без необходимости быстрого обучения. Наш метод случайным образом дополняет одно изображение до N расширенных представлений, а затем чередует два ключевых шага (см. mta.py и Подробности в разделе кода):
Этот шаг включает в себя расчет оценки для каждого расширенного представления для оценки его релевантности и качества (оценка искажённости).
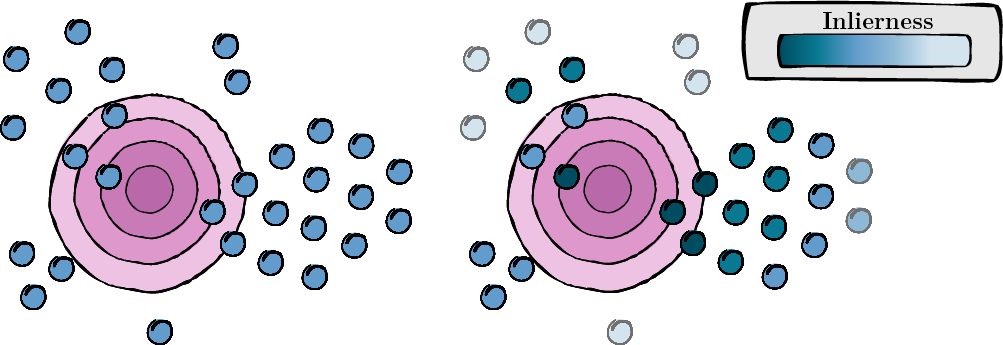
Рисунок 1. Подсчет баллов для каждого расширенного представления.
На основе оценок, вычисленных на предыдущем шаге, мы ищем режим точек данных (MeanShift).
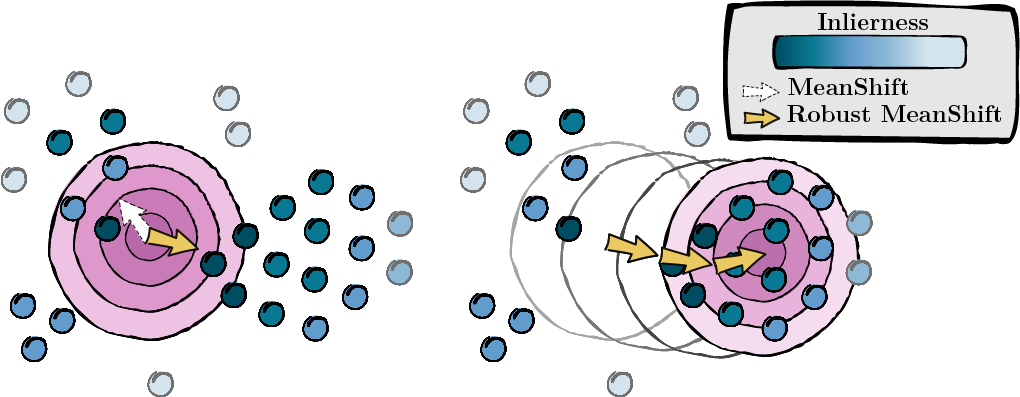
Рисунок 2: Поиск режима, взвешенный по показателям искажённости.
Мы следим за установкой и предварительной обработкой TPT. Это гарантирует, что ваш набор данных отформатирован соответствующим образом. Вы можете найти их репозиторий здесь. Если вам удобнее, вы можете изменить имена папок каждого набора данных в словаре ID_to_DIRNAME в data/datautils.py (строка 20).
Выполните MTA в наборе данных ImageNet со случайным начальным числом 1 и приглашением «фотография», введя следующую команду:
python main.py --data /path/to/your/data --mta --testsets I --seed 1Или 15 наборов данных одновременно:
python main.py --data /path/to/your/data --mta --testsets I/A/R/V/K/DTD/Flower102/Food101/Cars/SUN397/Aircraft/Pets/Caltech101/UCF101/eurosat --seed 1Дополнительная информация о процедуре в mta.py.
gaussian_kernelsolve_mtay ) равномерно.Если вы считаете этот проект полезным, пожалуйста, укажите его следующим образом:
@inproceedings { zanella2024test ,
title = { On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? } ,
author = { Zanella, Maxime and Ben Ayed, Ismail } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 23783--23793 } ,
year = { 2024 }
}Мы выражаем благодарность авторам TPT за их вклад в открытый исходный код. Вы можете найти их репозиторий здесь.


