Страница проекта | Бумага | Модель карты?
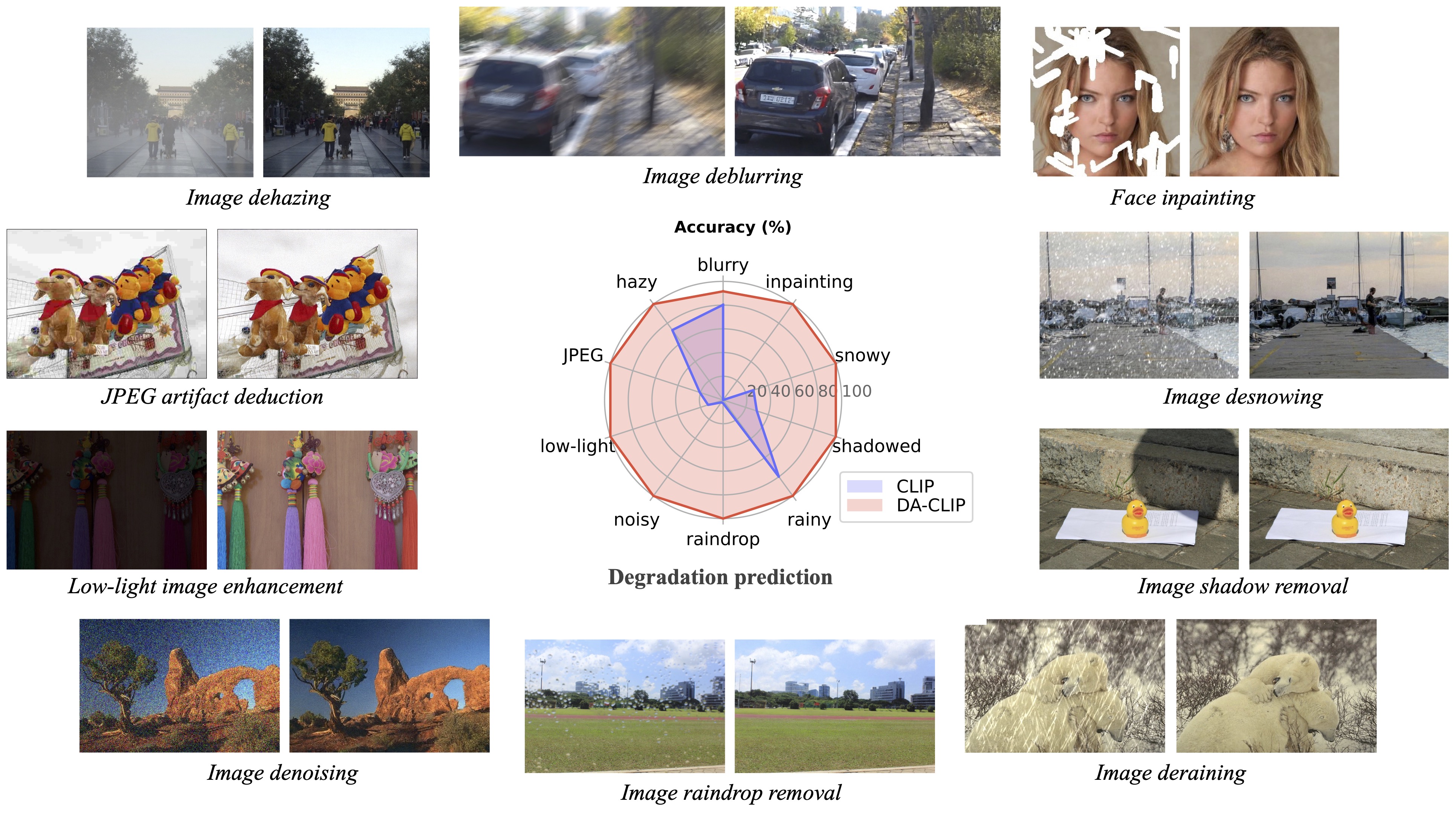
Наша последующая работа «Восстановление фотореалистичного изображения в дикой природе с помощью управляемых моделей визуального языка» (CVPRW 2024) представляет апостериорную выборку для лучшего создания изображений и обрабатывает реальные изображения со смешанной деградацией, аналогичные Real-ESRGAN.
[ 2024.04.16 ] Наша следующая статья «Восстановление фотореалистичного изображения в дикой природе с помощью управляемых моделей языка видения» теперь доступна на ArXiv!
[ 2024.04.15 ] Обновлена модель дикого ИК-спектра для реальных ухудшений и апостериорная выборка для лучшего создания изображений. Для wild-ir также предусмотрены предварительно обученные веса wild-ir.pth и wild-daclip_ViT-L-14.pt.
[ 20.01.2024 ] ??? Наша статья DA-CLIP была принята ICLR 2024 ??? Кроме того, мы предоставляем более надежную модель на карточке модели.
[ 2023.10.25 ] Добавлены ссылки на наборы данных для обучения и тестирования.
[ 2023.10.13 ] Добавлена демо-версия репликации и API. Спасибо @chenxwh!!! Мы обновили демоверсию Hugging Face и онлайн-демонстрацию Colab. Спасибо @fffiloni и @camenduru!!! Мы также сделали карточку модели в Hugging Face? и предоставил больше примеров для тестирования.
[ 2023.10.09 ] Предварительно обученные веса DA-CLIP и универсальной модели IR опубликованы в ссылках link1 и link2 соответственно. Кроме того, мы также предоставляем файл приложения Gradio на тот случай, если вы захотите протестировать свои собственные изображения.
ОС: Убунту 20.04.
нвидия:
куда: 11,4
питон 3.8
Мы советуем вам сначала создать виртуальную среду с:
python3 -m venv.envsource.env/bin/activate пип установить -U пип pip install -r требования.txt
Войдите в каталог universal-image-restoration и запустите:
импортировать факел из PIL import Imageimport open_clipcheckpoint = 'pretrained/daclip_ViT-B-32.pt'model, preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=checkpoint)tokenizer = open_clip.get_tokenizer('ViT-B-32) ')изображение = preprocess(Image.open("haze_01.png")).unsqueeze(0)degradations = ['размытие в движении','мутный','jpeg-сжатый','низкая освещенность','шумный','капля дождя' ,'дождливый','затененный','снежный','незавершенный']text = tokenizer(degradations)with torch.no_grad(), torch.cuda.amp.autocast():text_features = model.encode_text(text)image_features, degra_features = model.encode_image(image, control=True)degra_features /= degra_features.norm(dim=-1, Keepdim=True)text_features / = text_features.norm(dim=-1, Keepdim=True)text_probs = (100.0 * degra_features @ text_features.T).softmax(dim=-1)index = torch.argmax(text_probs[0])print(f"Task: {task_name}: {degradations[index]} - {text_probs[0][индекс]}")Подготовка наборов данных для поездов и испытаний в соответствии с нашим разделом «Создание набора данных»:
#### для набора обучающих данных ######## (незавершенное означает зарисовку) ####datasets/universal/train|--motion-blurry| |--LQ/*.png| |--GT/*.png|--туманный|--jpeg-сжатый|--слабое освещение|--шумный|--дождевая капля|--дождливый|--затененный|--снежный|--незавершенный## ## для набора данных тестирования ######## (та же структура, что и у поезда) ####datasets/universal/val ...#### для чистых подписей ####datasets/universal/daclip_train.csv наборы данных/универсальные/daclip_val.csv
Затем перейдите в каталог universal-image-restoration/config/daclip-sde и измените пути к наборам данных в файлах параметров в options/train.yml и options/test.yml .
Вы можете добавить больше задач или наборов данных в каталоги train и val и добавить слово деградации к distortion .
| Деградация | размытое движение | туманный | сжатый в формате JPEG* | слабое освещение | шумно* (то же, что и в формате JPEG) |
|---|---|---|---|---|---|
| Наборы данных | Гопро | РЕЗАЙД-6к | DIV2K+Flickr2K | РЖУ НЕ МОГУ | DIV2K+Flickr2K |
| Деградация | капля дождя | дождливый | затененный | снежный | незавершенный |
|---|---|---|---|---|---|
| Наборы данных | Капля Дождя | Rain100H: поезд, тест | СРД | Снег100К | СелебаHQ-256 |
Вам следует извлекать только наборы данных поездов для обучения , а все наборы проверочных данных можно загрузить на диск Google. Для наборов данных в формате jpeg и зашумленных вы можете создавать изображения LQ с помощью этого скрипта.
Подробности смотрите на DA-CLIP.md.
Основной код для обучения находится в universal-image-restoration/config/daclip-sde , а базовая сеть для DA-CLIP — в universal-image-restoration/open_clip/daclip_model.py .
Поместите предварительно обученные веса DA-CLIP в pretrained каталог и проверьте путь daclip .
Затем вы можете обучить модель, следуя приведенным ниже сценариям bash:
cd Universal-image-restoration/config/daclip-sde# Для одного графического процессора: python3 train.py -opt=options/train.yml# Для распределенного обучения необходимо изменить gpu_ids в опции filepython3 -m torch.distributed.launch - -nproc_per_node=2 --master_port=4321 train.py -opt=options/train.yml --launcher pytorch
Модели и журналы обучения будут сохраняться в log/universal-ir . Вы можете распечатать журнал в любое время, запустив tail -f log/universal-ir/train_universal-ir_***.log -n 100 .
Те же этапы обучения можно использовать для восстановления изображений в естественных условиях (wild-ir).
| Название модели | Описание | ГуглДиск | ОбниматьЛицо |
|---|---|---|---|
| ДА-КЛИП | Модель CLIP с учетом деградации | скачать | скачать |
| Универсал-ИК | Универсальная модель восстановления изображений на основе DA-CLIP | скачать | скачать |
| DA-CLIP-микс | Модель CLIP с учетом деградации (добавление размытия по Гауссу + закрашивание лица и размытие по Гауссу + дождливый) | скачать | скачать |
| Универсал-ИК-микс | Универсальная модель восстановления изображений на основе DA-CLIP (добавить надежное обучение и смешивание ухудшений) | скачать | скачать |
| Wild-DA-CLIP | Модель CLIP с учетом деградации в дикой природе (ViT-L-14) | скачать | скачать |
| Wild-IR | Модель восстановления изображений на основе DA-CLIP в реальных условиях | скачать | скачать |
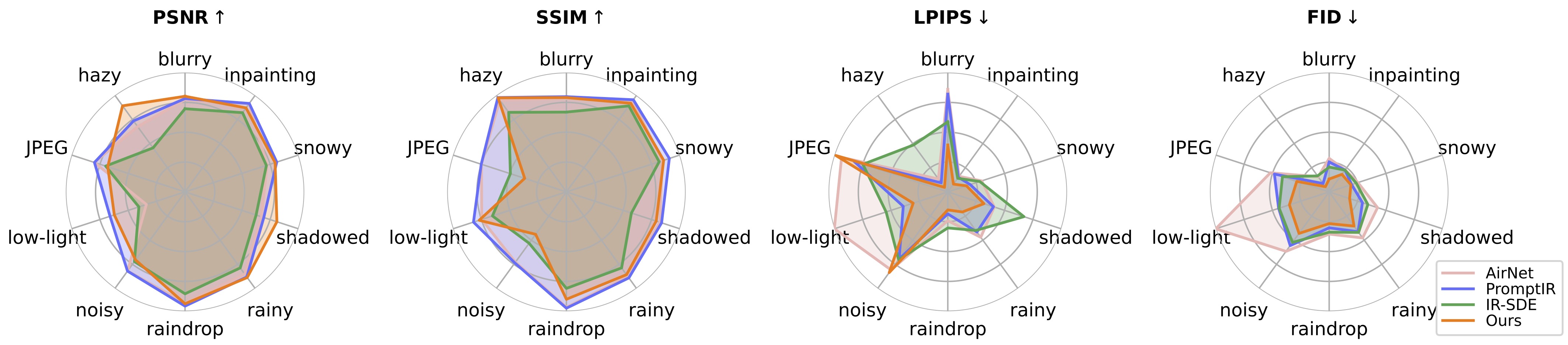
Чтобы оценить наш метод восстановления изображений, измените путь к тесту и путь к модели и запустите
cd Universal-image-Restore/config/universal-ir python test.py -opt=options/test.yml
Здесь мы предоставляем файл app.py для тестирования ваших собственных изображений. Перед этим вам необходимо загрузить предварительно обученные веса (DA-CLIP и UIR) и изменить путь модели в options/test.yml . Затем, просто запустив python app.py , вы можете открыть http://localhost:7860 чтобы протестировать модель. (Мы также предоставляем несколько изображений с различным ухудшением качества в каталоге images ). Мы также предоставляем дополнительные примеры из нашего набора тестовых данных на диске Google.
Те же шаги можно использовать для восстановления изображения в естественных условиях (wild-ir).



? В ходе тестирования мы обнаружили, что текущая предварительно обученная модель по-прежнему с трудом обрабатывает некоторые реальные изображения, распределение которых может иметь сдвиги в нашем наборе обучающих данных (снятые с разных устройств или с разным разрешением или ухудшением качества). Мы рассматриваем это как будущую работу и постараемся сделать нашу модель более практичной! Мы также призываем пользователей, заинтересованных в нашей работе, обучать свои собственные модели с использованием более крупных наборов данных и большего количества типов деградации.
? Кстати, мы также обнаружили, что прямое изменение размера входных изображений приводит к снижению производительности для большинства задач . Мы могли бы попытаться добавить в обучение шаг изменения размера, но это всегда ухудшает качество изображения из-за интерполяции.
? Для задачи рисования наша текущая модель поддерживает только рисование лица из-за ограничений набора данных. Мы предоставляем примеры наших масок, и вы можете использовать скриптgenerate_masked_face для создания незавершенных лиц.
Благодарность: наш DA-CLIP основан на IR-SDE и open_clip. Спасибо за их код!
Если у вас есть вопросы, обращайтесь: [email protected].
Если наш код поможет вашим исследованиям или работе, рассмотрите возможность цитирования нашей статьи. Ниже приведены ссылки на BibTeX:
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}
@article{luo2024photo,
title={Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2404.09732},
year={2024}
}

