Платформа для обучения любых мультимодальных моделей фундамента.
Масштабируемый. С открытым исходным кодом. Десятки модальностей и задач.
ЭПФЛ – Apple
Website | BibTeX | ? Demo
Официальная реализация и предварительно обученные модели для:
4M: Массивно-мультимодальное маскированное моделирование , NeurIPS 2023 (В центре внимания)
Дэвид Мизрахи*, Роман Бахманн*, Огужан Фатих Кар, Тереза Йео, Мингфэй Гао, Афшин Дехган, Амир Замир
4M-21: универсальная модель видения для десятков задач и модальностей , NeurIPS 2024
Роман Бахманн*, Огужан Фатих Кар*, Дэвид Мизрахи*, Али Гарджани, Мингфэй Гао, Дэвид Гриффитс, Цзямин Ху, Афшин Дехган, Амир Замир
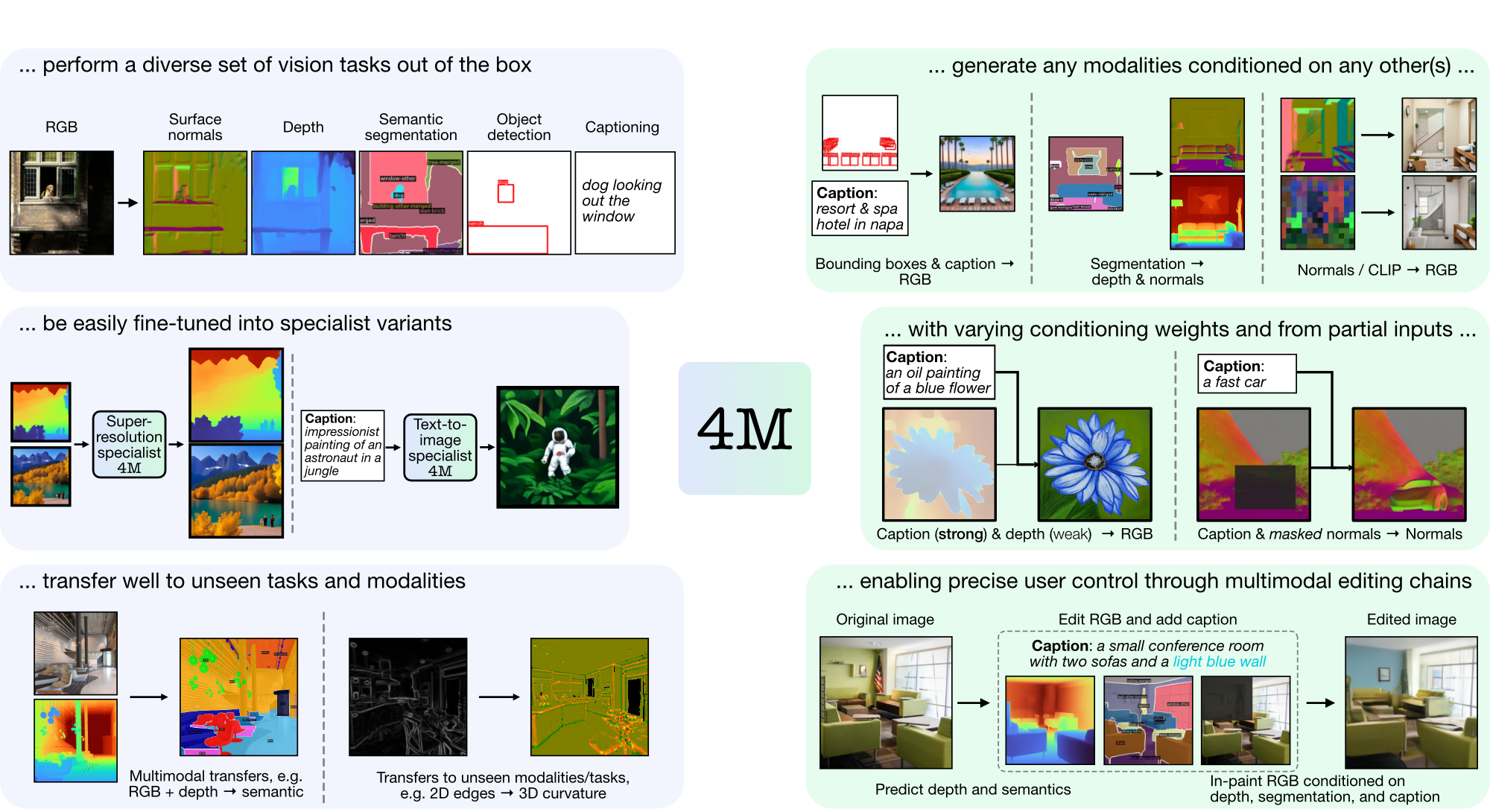
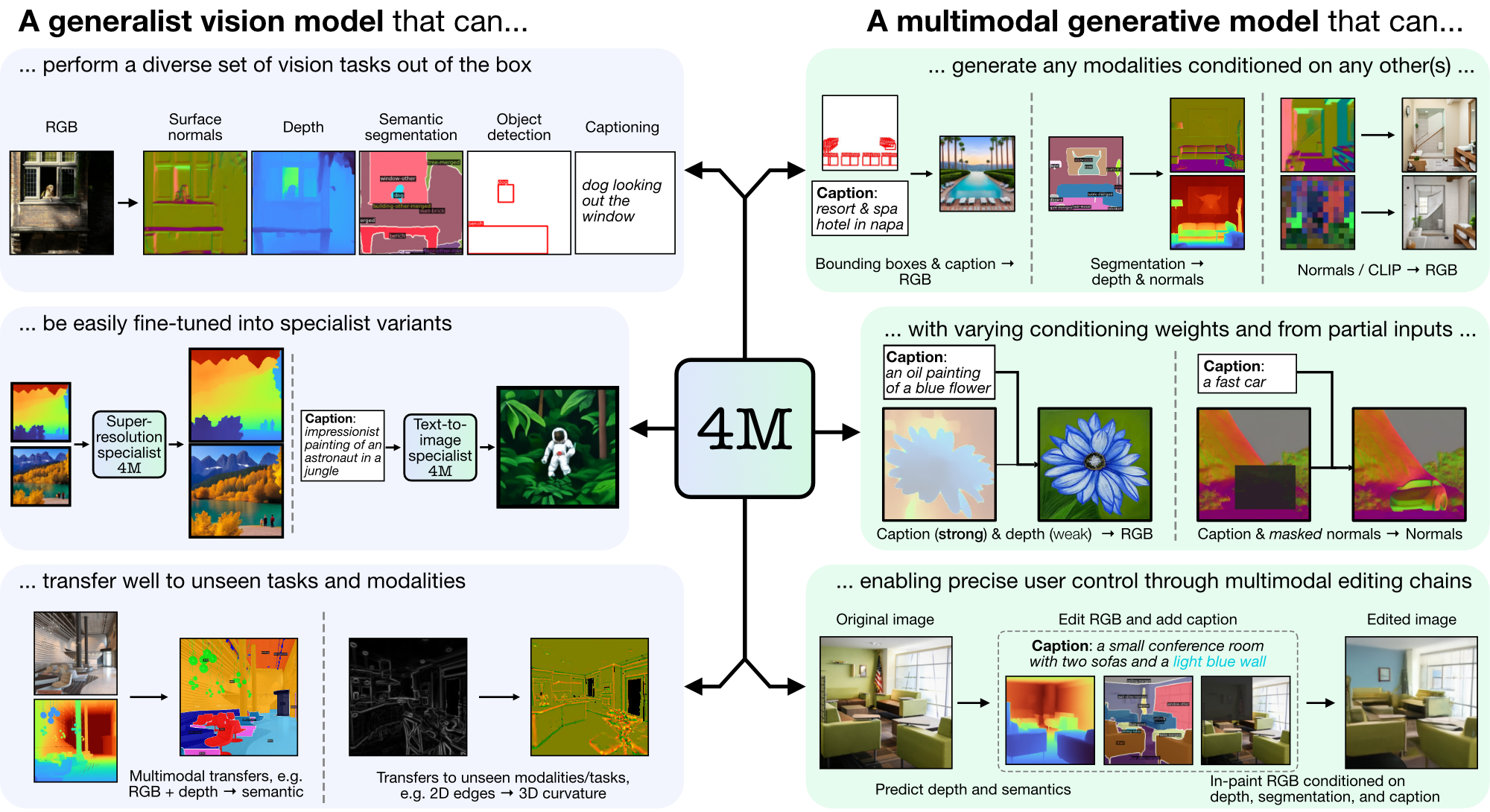
4M — это платформа для обучения базовых моделей «любой к любому», использующая токенизацию и маскирование для масштабирования для множества различных модальностей. Модели, обученные с помощью 4M, могут выполнять широкий спектр задач по зрению, хорошо переносить невидимые задачи и модальности и представляют собой гибкие и управляемые мультимодальные генеративные модели. Мы выпускаем код и модели для «4M: Массовое мультимодальное маскированное моделирование» (здесь обозначено 4M-7), а также «4M-21: Модель универсального видения для десятков задач и модальностей» (здесь обозначено 4M). -21).
git clone https://github.com/apple/ml-4m
cd ml-4m
conda create -n fourm python=3.9 -y
conda activate fourm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# Run in Python shell
import torch
print(torch.cuda.is_available()) # Should return True
Если CUDA недоступен, рассмотрите возможность переустановки PyTorch, следуя официальным инструкциям по установке. Аналогично, если вы хотите установить xFormers (необязательно, для более быстрых токенизаторов), следуйте их README, чтобы убедиться, что версия CUDA верна.
Мы предоставляем демонстрационную оболочку, позволяющую быстро начать использовать модели 4M для задач генерации RGB-для всех или {caption, ограничивающие рамки}-для всех. Например, чтобы сгенерировать все модальности из заданного входа RGB, вызовите:
from fourm . demo_4M_sampler import Demo4MSampler , img_from_url
sampler = Demo4MSampler ( fm = 'EPFL-VILAB/4M-21_XL' ). cuda ()
img = img_from_url ( 'https://storage.googleapis.com/four_m_site/images/demo_rgb.png' ) # 1x3x224x224 ImageNet-standardized PyTorch Tensor
preds = sampler ({ 'rgb@224' : img . cuda ()}, seed = None )
sampler . plot_modalities ( preds , save_path = None )Вы должны ожидать увидеть следующий результат:


Для создания подписей ко всем вы можете заменить входные данные сэмплера на: preds = sampler({'caption': 'A lake house with a boat in front [S_1]'}) . Список доступных моделей 4M можно найти в зоопарке моделей ниже, а дополнительные инструкции по созданию см. в README_GENERATION.md.
См. README_DATA.md для получения инструкций о том, как подготовить согласованные мультимодальные наборы данных.
См. README_TOKENIZATION.md для получения инструкций по обучению токенизаторов, специфичных для модальности.
См. README_TRAINING.md для получения инструкций по обучению моделей 4M.
См. README_GENERATION.md для получения инструкций о том, как использовать модели 4M для вывода/генерации. Мы также предоставляем блокнот для генерации, который содержит примеры вывода 4M, в частности, для выполнения задач генерации условных изображений и задач общего зрения (например, RGB-to-All).
Мы предоставляем контрольно-пропускные пункты 4M и токенизатора в качестве защитных датчиков, а также предлагаем удобную загрузку через Hugging Face Hub.
| Модель | # Мод. | Наборы данных | # Параметры | Конфигурация | Веса |
|---|---|---|---|---|---|
| 4М-Б | 7 | СС12М | 198М | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
| 4М-Б | 7 | КОЙО700М | 198М | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
| 4М-Б | 21 | CC12M+КОЙО700М+C4 | 198М | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
| 4М-Л | 7 | СС12М | 705М | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
| 4М-Л | 7 | КОЙО700М | 705М | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
| 4М-Л | 21 | CC12M+КОЙО700М+C4 | 705М | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
| 4М-XL | 7 | СС12М | 2,8Б | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
| 4М-XL | 7 | КОЙО700М | 2,8Б | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
| 4М-XL | 21 | CC12M+КОЙО700М+C4 | 2,8Б | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
Чтобы загрузить модели из Hugging Face Hub:
from fourm . models . fm import FM
fm7b_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_CC12M' )
fm7b_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_COYO700M' )
fm21b = FM . from_pretrained ( 'EPFL-VILAB/4M-21_B' )
fm7l_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_CC12M' )
fm7l_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_COYO700M' )
fm21l = FM . from_pretrained ( 'EPFL-VILAB/4M-21_L' )
fm7xl_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_CC12M' )
fm7xl_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_COYO700M' )
fm21xl = FM . from_pretrained ( 'EPFL-VILAB/4M-21_XL' )Чтобы загрузить чекпоинты вручную, сначала загрузите файлы Safetensors по указанным выше ссылкам и вызовите:
from fourm . utils import load_safetensors
from fourm . models . fm import FM
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
fm = FM ( config = config )
fm . load_state_dict ( ckpt )Эти модели были инициализированы со стандартными моделями 4M-7 CC12M, но продолжили обучение, используя смесь модальностей, сильно ориентированную на ввод текста. Они по-прежнему способны выполнять все остальные задачи, но лучше справляются с преобразованием текста в изображение по сравнению с моделями без точной настройки.
| Модель | # Мод. | Наборы данных | # Параметры | Конфигурация | Веса |
|---|---|---|---|---|---|
| 4М-Т2И-Б | 7 | СС12М | 198М | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
| 4М-Т2И-Л | 7 | СС12М | 705М | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
| 4М-Т2И-XL | 7 | СС12М | 2,8Б | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
Чтобы загрузить модели из Hugging Face Hub:
from fourm . models . fm import FM
fm7b_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_B_CC12M' )
fm7l_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_L_CC12M' )
fm7xl_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_XL_CC12M' )Загрузка вручную с контрольных точек производится так же, как указано выше для базовых моделей 4М.
| Модель | # Мод. | Наборы данных | # Параметры | Конфигурация | Веса |
|---|---|---|---|---|---|
| 4М-СР-Л | 7 | СС12М | 198М | Конфигурация | Контрольно-пропускной пункт / ВЧ-концентратор |
Чтобы загрузить модели из Hugging Face Hub:
from fourm . models . fm import FM
fm7l_sr_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-SR_L_CC12M' )Загрузка вручную с контрольных точек производится так же, как указано выше для базовых моделей 4М.
| модальность | Разрешение | Количество токенов | Размер кодовой книги | Диффузионный декодер | Веса |
|---|---|---|---|---|---|
| RGB | 224-448 | 196-784 | 16 тыс. | ✓ | Контрольно-пропускной пункт / ВЧ-концентратор |
| Глубина | 224-448 | 196-784 | 8к | ✓ | Контрольно-пропускной пункт / ВЧ-концентратор |
| Нормальные | 224-448 | 196-784 | 8к | ✓ | Контрольно-пропускной пункт / ВЧ-концентратор |
| Эджи (Кэнни, СЭМ) | 224-512 | 196-1024 | 8к | ✓ | Контрольно-пропускной пункт / ВЧ-концентратор |
| Семантическая сегментация COCO | 224-448 | 196-784 | 4к | ✗ | Контрольно-пропускной пункт / ВЧ-концентратор |
| КЛИП-Б/16 | 224-448 | 196-784 | 8к | ✗ | Контрольно-пропускной пункт / ВЧ-концентратор |
| ДИНОВ2-Б/14 | 224-448 | 256-1024 | 8к | ✗ | Контрольно-пропускной пункт / ВЧ-концентратор |
| DINOv2-B/14 (глобальный) | 224 | 16 | 8к | ✗ | Контрольно-пропускной пункт / ВЧ-концентратор |
| ИзображениеBind-H/14 | 224-448 | 256-1024 | 8к | ✗ | Контрольно-пропускной пункт / ВЧ-концентратор |
| ImageBind-H/14 (глобальный) | 224 | 16 | 8к | ✗ | Контрольно-пропускной пункт / ВЧ-концентратор |
| Экземпляры SAM | - | 64 | 1 тыс. | ✗ | Контрольно-пропускной пункт / ВЧ-концентратор |
| 3D Человеческие позы | - | 8 | 1 тыс. | ✗ | Контрольно-пропускной пункт / ВЧ-концентратор |
Чтобы загрузить модели из Hugging Face Hub:
from fourm . vq . vqvae import VQVAE , DiVAE
# 4M-7 modalities
tok_rgb = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_rgb_16k_224-448' )
tok_depth = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_depth_8k_224-448' )
tok_normal = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_normal_8k_224-448' )
tok_semseg = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_semseg_4k_224-448' )
tok_clip = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_CLIP-B16_8k_224-448' )
# 4M-21 modalities
tok_edge = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_edge_8k_224-512' )
tok_dinov2 = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14_8k_224-448' )
tok_dinov2_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14-global_8k_16_224' )
tok_imagebind = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14_8k_224-448' )
tok_imagebind_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14-global_8k_16_224' )
sam_instance = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_sam-instance_1k_64' )
human_poses = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_human-poses_1k_8' )Чтобы загрузить контрольные точки вручную, сначала загрузите файлы Safetensors по указанным выше ссылкам и вызовите:
from fourm . utils import load_safetensors
from fourm . vq . vqvae import VQVAE , DiVAE
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
tok = VQVAE ( config = config ) # Or DiVAE for models with a diffusion decoder
tok . load_state_dict ( ckpt )Код в этом репозитории выпущен под лицензией Apache 2.0, указанной в файле LICENSE.
Веса моделей в этом репозитории выпускаются под лицензией примера кода, которая находится в файле LICENSE_WEIGHTS.
Если этот репозиторий окажется для вас полезным, пожалуйста, процитируйте нашу работу:
@inproceedings{4m,
title={{4M}: Massively Multimodal Masked Modeling},
author={David Mizrahi and Roman Bachmann and O{u{g}}uzhan Fatih Kar and Teresa Yeo and Mingfei Gao and Afshin Dehghan and Amir Zamir},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
@article{4m21,
title={{4M-21}: An Any-to-Any Vision Model for Tens of Tasks and Modalities},
author={Roman Bachmann and O{u{g}}uzhan Fatih Kar and David Mizrahi and Ali Garjani and Mingfei Gao and David Griffiths and Jiaming Hu and Afshin Dehghan and Amir Zamir},
journal={arXiv 2024},
year={2024},
}


