system design 101
1.0.0
【 ?? YouTube | ? Информационный бюллетень 】
Объясняйте сложные системы, используя наглядные изображения и простые термины.
Готовитесь ли вы к собеседованию по проектированию системы или просто хотите понять, как работают системы, мы надеемся, что этот репозиторий поможет вам в этом.
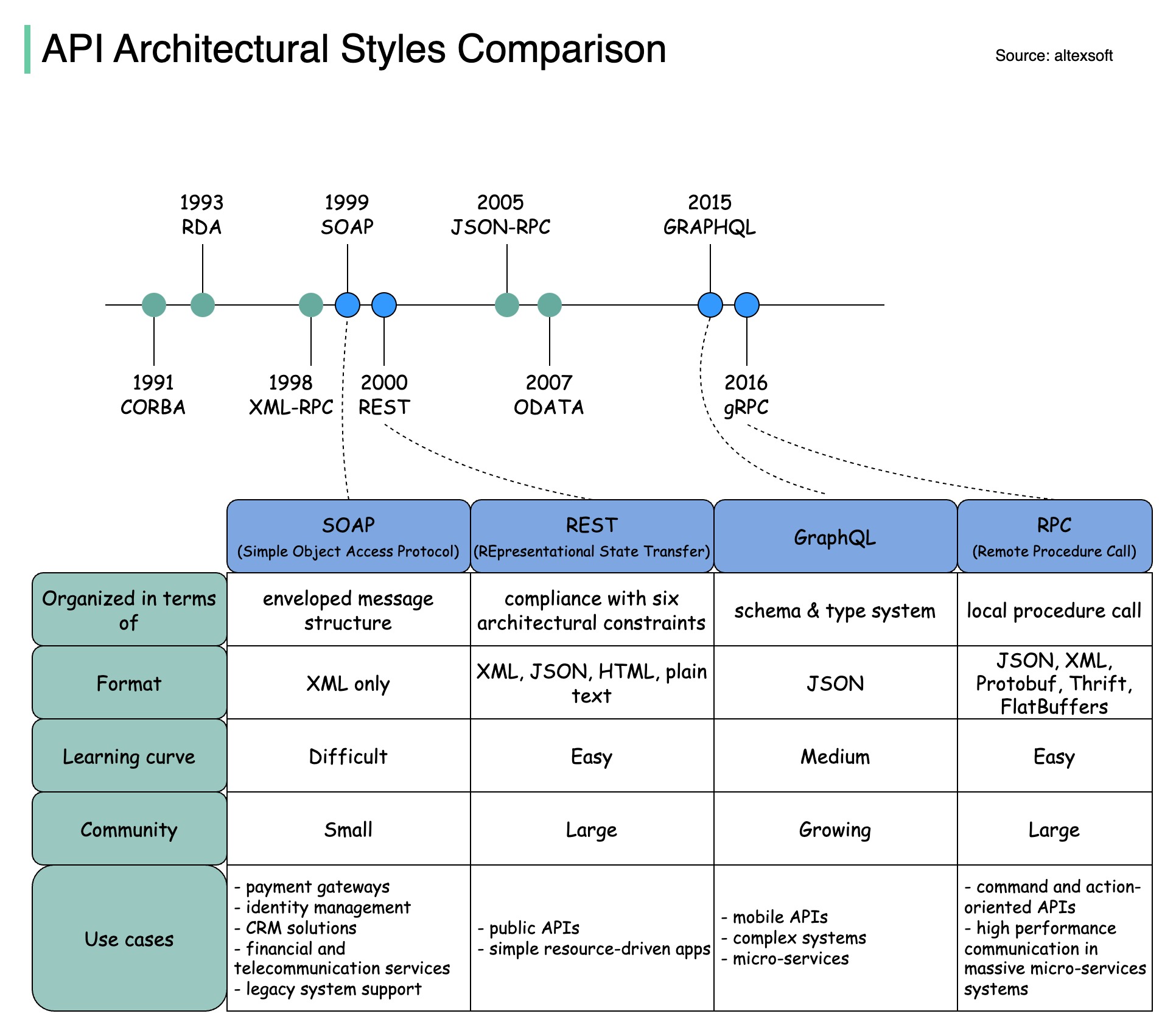
Стили архитектуры определяют, как различные компоненты интерфейса прикладного программирования (API) взаимодействуют друг с другом. В результате они обеспечивают эффективность, надежность и простоту интеграции с другими системами, предоставляя стандартный подход к проектированию и созданию API. Вот наиболее часто используемые стили:
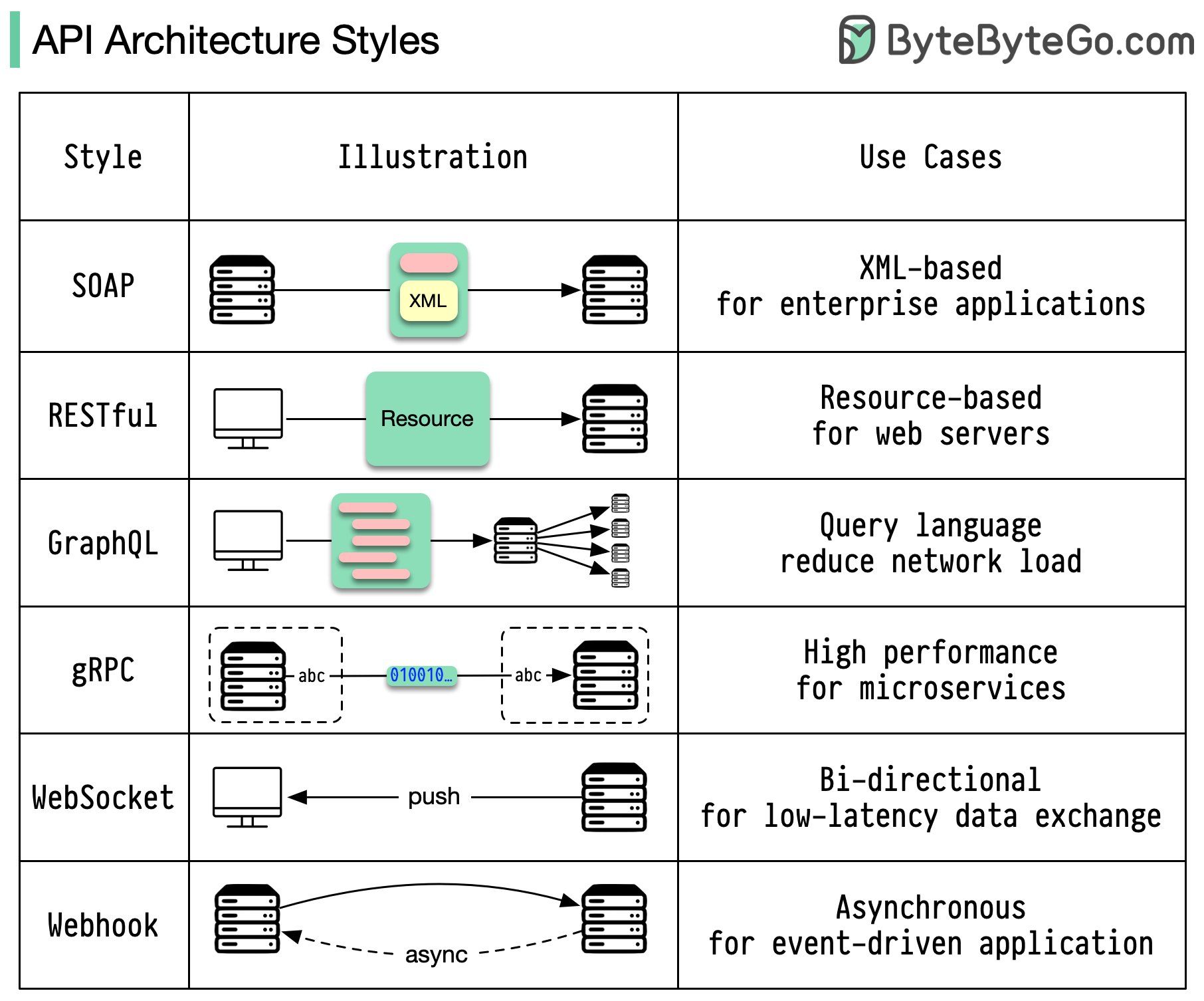
МЫЛО:
Зрелый, всеобъемлющий, основанный на XML
Лучшее для корпоративных приложений
RESTful:
Популярные и простые в реализации HTTP-методы.
Идеально подходит для веб-сервисов
ГрафQL:
Язык запроса, запрос конкретных данных
Снижает нагрузку на сеть, ускоряет реакцию
гРПК:
Современные высокопроизводительные протокольные буферы
Подходит для микросервисных архитектур.
Вебсокет:
Двунаправленные, постоянные соединения в реальном времени
Идеально подходит для обмена данными с низкой задержкой
Вебхук:
Управляемые событиями, обратные вызовы HTTP, асинхронные
Уведомляет системы о происходящих событиях
Когда дело доходит до проектирования API, REST и GraphQL имеют свои сильные и слабые стороны.
На диаграмме ниже показано быстрое сравнение REST и GraphQL.
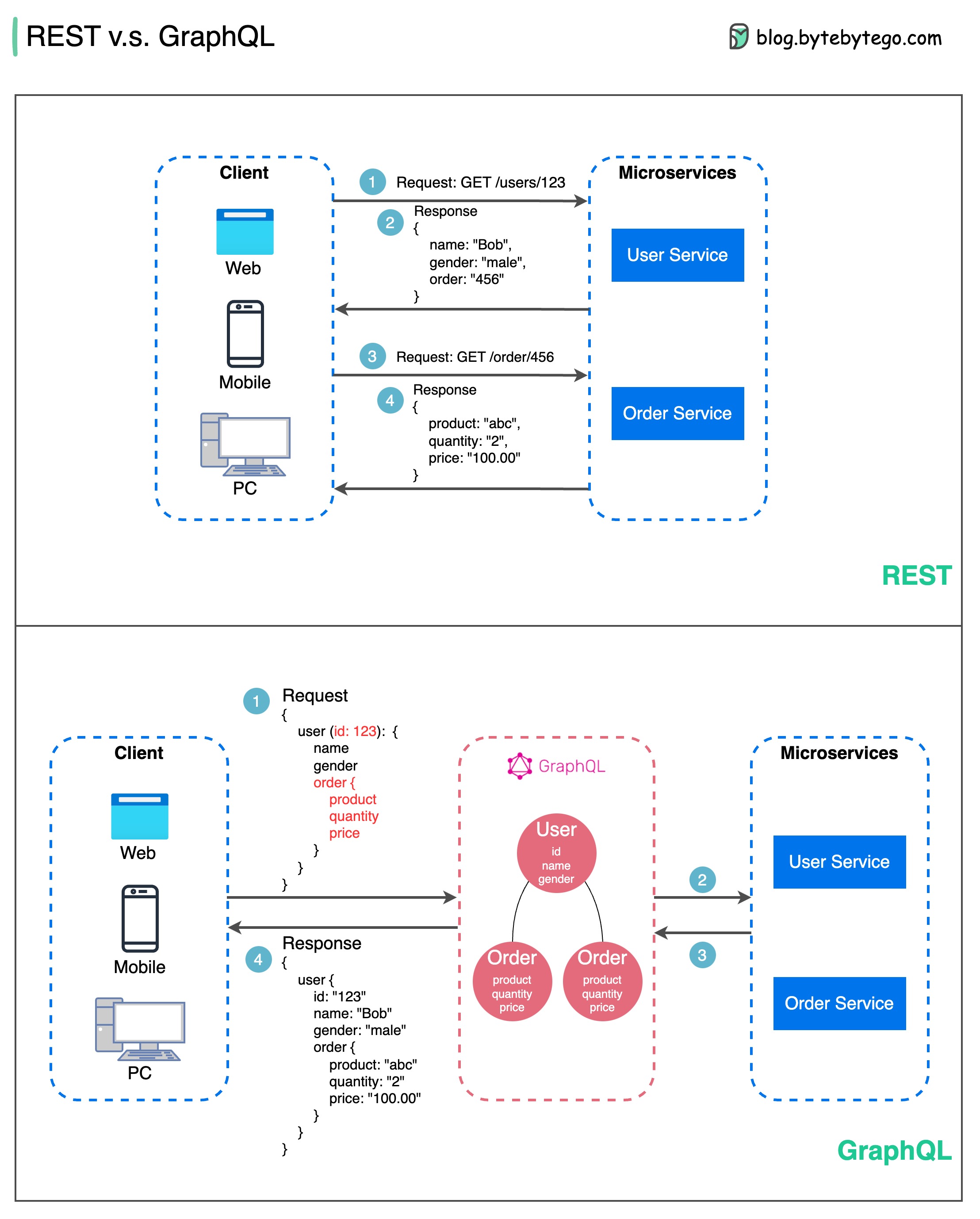
ОТДЫХ
ГрафQL
Лучший выбор между REST и GraphQL зависит от конкретных требований приложения и команды разработчиков. GraphQL хорошо подходит для сложных или часто меняющихся потребностей внешнего интерфейса, а REST подходит для приложений, где предпочтительны простые и последовательные контракты.
Ни один из подходов API не является панацеей. Чтобы выбрать правильный стиль, важно тщательно оценить требования и компромиссы. И REST, и GraphQL являются допустимыми вариантами предоставления данных и поддержки современных приложений.
RPC (вызов удаленных процедур) называется « удаленным », поскольку он обеспечивает связь между удаленными службами, когда службы развертываются на разных серверах в рамках микросервисной архитектуры. С точки зрения пользователя это действует как вызов локальной функции.
На диаграмме ниже показан общий поток данных для gRPC .
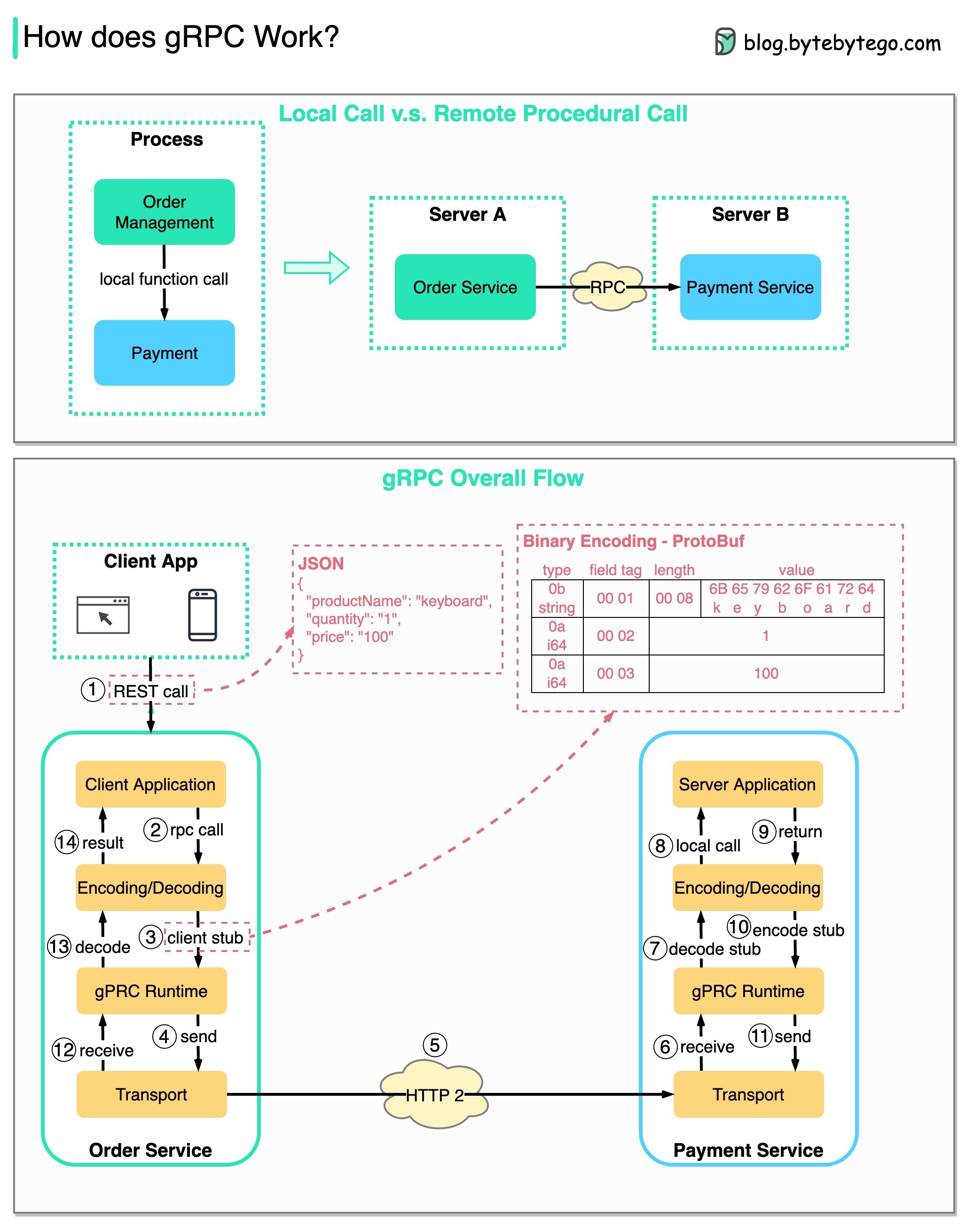
Шаг 1: От клиента выполняется вызов REST. Тело запроса обычно имеет формат JSON.
Шаги 2–4. Служба заказов (клиент gRPC) получает вызов REST, преобразует его и отправляет вызов RPC в службу платежей. gRPC кодирует заглушку клиента в двоичный формат и отправляет ее на транспортный уровень низкого уровня.
Шаг 5: gRPC отправляет пакеты по сети через HTTP2. Говорят, что благодаря двоичному кодированию и оптимизации сети gRPC в 5 раз быстрее, чем JSON.
Шаги 6–8. Платежная служба (сервер gRPC) получает пакеты из сети, декодирует их и вызывает серверное приложение.
Шаги 9–11: Результат возвращается из серверного приложения, кодируется и отправляется на транспортный уровень.
Шаги 12–14: Служба заказов получает пакеты, декодирует их и отправляет результат клиентскому приложению.
На диаграмме ниже показано сравнение опроса и Webhook.
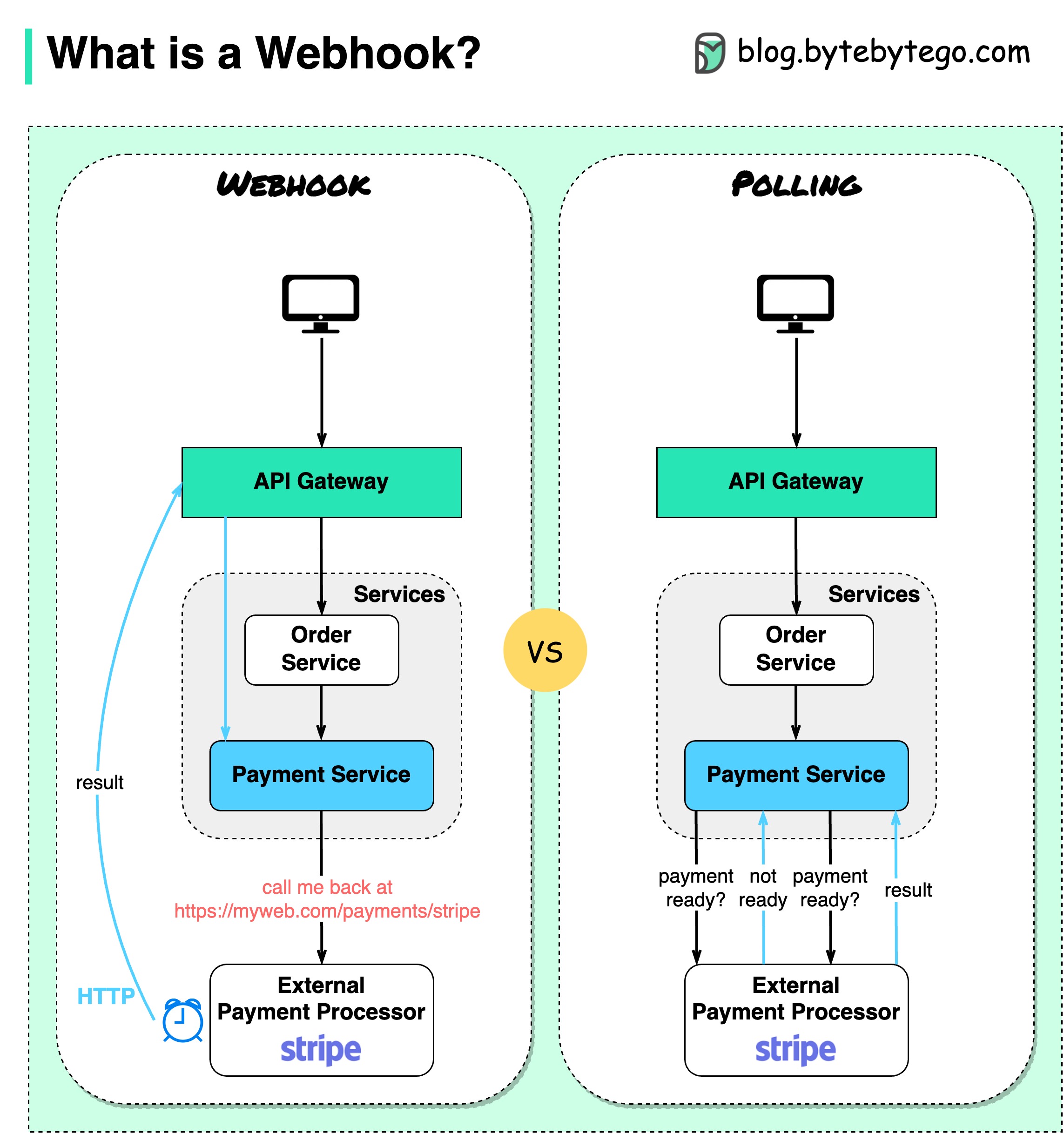
Предположим, у нас есть сайт электронной коммерции. Клиенты отправляют заказы в службу заказов через шлюз API, который поступает в платежный сервис для проведения платежных операций. Затем платежная служба обращается к внешнему поставщику платежных услуг (PSP) для завершения транзакций.
Существует два способа управления связью с внешним PSP.
1. Короткий опрос
После отправки платежного запроса PSP платежная служба продолжает спрашивать PSP о статусе платежа. После нескольких раундов PSP наконец возвращается со статусом.
Короткий опрос имеет два недостатка:
2. Вебхук
Мы можем зарегистрировать вебхук во внешнем сервисе. Это означает: перезвоните мне по определенному URL-адресу, когда у вас появятся обновления по запросу. Когда PSP завершит обработку, он вызовет HTTP-запрос для обновления статуса платежа.
Таким образом, меняется парадигма программирования, и платежному сервису больше не нужно тратить ресурсы на опрос статуса платежа.
Что, если PSP никогда не перезвонит? Мы можем настроить работу по уборке, чтобы проверять статус платежа каждый час.
Веб-перехватчики часто называют обратными API или API-интерфейсами push, поскольку сервер отправляет клиенту HTTP-запросы. При использовании вебхука нам нужно обратить внимание на 3 вещи:
На диаграмме ниже показаны 5 распространенных приемов повышения производительности API.
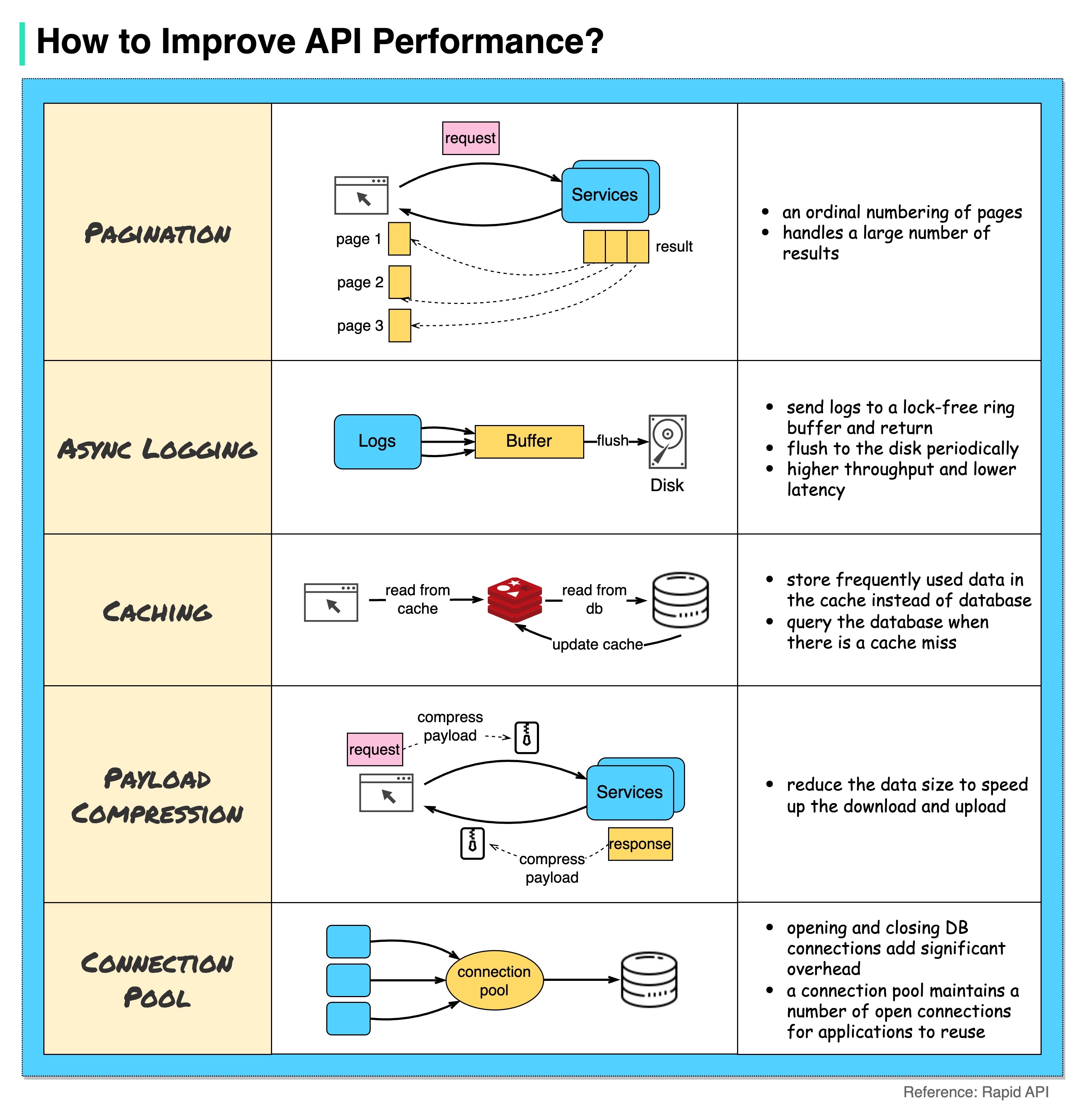
Пагинация
Это обычная оптимизация, когда размер результата велик. Результаты передаются обратно клиенту, чтобы улучшить скорость реагирования службы.
Асинхронное ведение журнала
Синхронное ведение журнала использует диск для каждого вызова и может замедлить работу системы. При асинхронном ведении журналов журналы сначала отправляются в незаблокированный буфер, а затем немедленно возвращаются. Журналы будут периодически сбрасываться на диск. Это значительно снижает накладные расходы ввода-вывода.
Кэширование
Мы можем хранить часто используемые данные в кеше. Клиент может сначала запросить кеш вместо непосредственного обращения к базе данных. Если произошел промах в кэше, клиент может запросить данные из базы данных. Кэши, такие как Redis, хранят данные в памяти, поэтому доступ к данным происходит намного быстрее, чем к базе данных.
Сжатие полезной нагрузки
Запросы и ответы могут быть сжаты с помощью gzip и т. д., чтобы размер передаваемых данных был намного меньше. Это ускоряет загрузку и загрузку.
Пул соединений
При доступе к ресурсам нам часто необходимо загрузить данные из базы данных. Открытие закрывающихся соединений с базой данных приводит к значительным накладным расходам. Поэтому нам следует подключиться к базе данных через пул открытых соединений. Пул соединений отвечает за управление жизненным циклом соединения.
Какую проблему решает каждое поколение HTTP?
На диаграмме ниже показаны ключевые особенности.
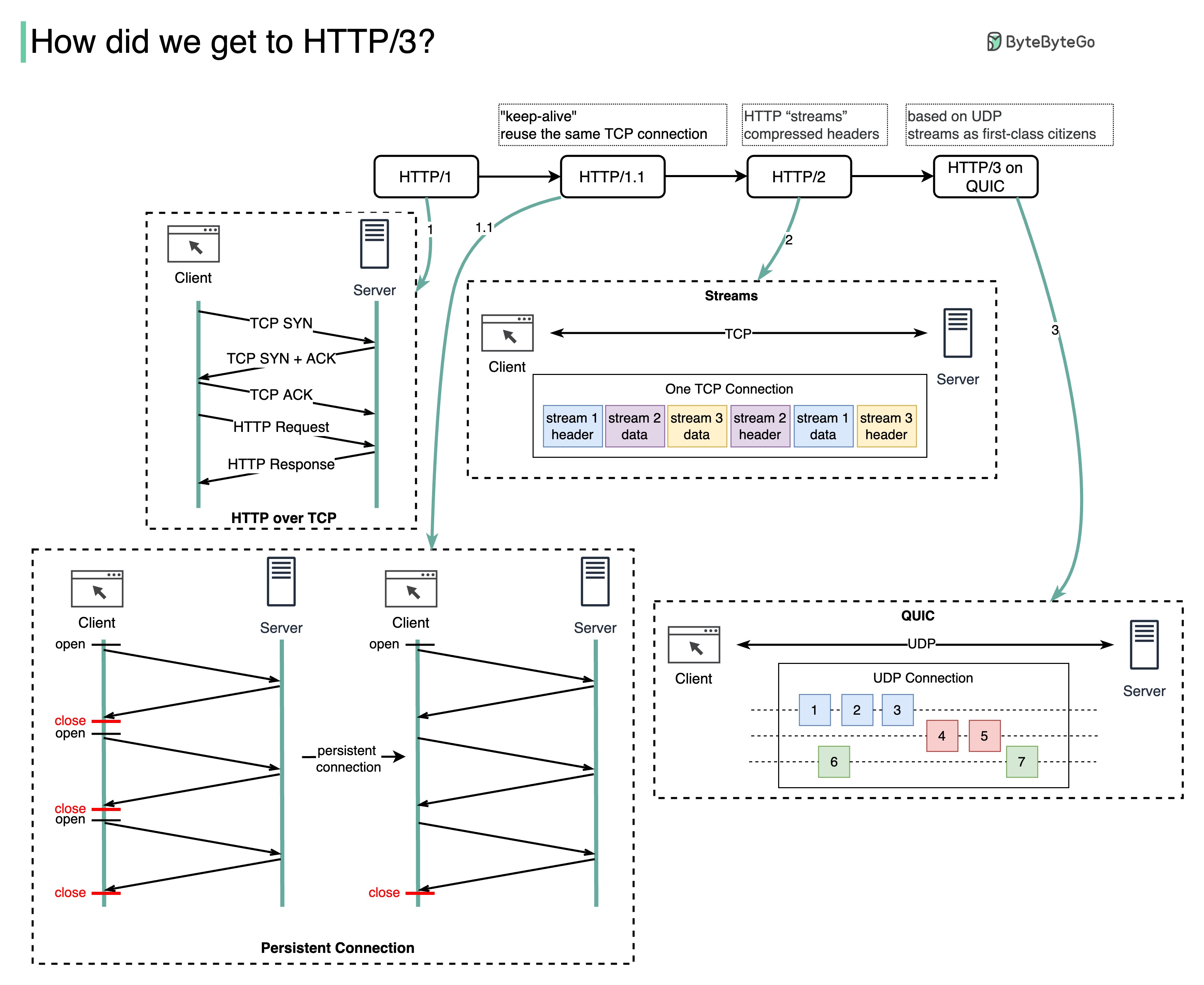
HTTP 1.0 был завершен и полностью документирован в 1996 году. Для каждого запроса к одному и тому же серверу требуется отдельное TCP-соединение.
HTTP 1.1 был опубликован в 1997 году. TCP-соединение можно оставить открытым для повторного использования (постоянное соединение), но это не решает проблему блокировки HOL (заголовка линии).
HOL-блокировка — когда количество разрешенных параллельных запросов в браузере исчерпано, последующие запросы должны дождаться завершения предыдущих.
HTTP 2.0 был опубликован в 2015 году. Он решает проблему HOL посредством мультиплексирования запросов, что устраняет блокировку HOL на уровне приложения, но HOL все еще существует на транспортном уровне (TCP).
Как вы можете видеть на диаграмме, в HTTP 2.0 появилась концепция «потоков» HTTP: абстракция, позволяющая мультиплексировать различные обмены HTTP в одном и том же TCP-соединении. Каждый поток не обязательно отправлять по порядку.
Первый проект HTTP 3.0 был опубликован в 2020 году. Это предлагаемый преемник HTTP 2.0. Он использует QUIC вместо TCP для базового транспортного протокола, тем самым устраняя блокировку HOL на транспортном уровне.
QUIC основан на UDP. Он представляет потоки как первоклассных граждан на транспортном уровне. Потоки QUIC используют одно и то же соединение QUIC, поэтому для создания новых не требуются дополнительные подтверждения и медленные запуски, но потоки QUIC доставляются независимо, так что в большинстве случаев потеря пакетов, влияющая на один поток, не влияет на другие.
На диаграмме ниже показана временная шкала API и сравнение стилей API.
Со временем выпускаются различные архитектурные стили API. Каждый из них имеет свои схемы стандартизации обмена данными.
Вы можете просмотреть варианты использования каждого стиля на диаграмме.
На диаграмме ниже показаны различия между разработкой с упором на код и разработкой с упором на API. Почему мы хотим рассматривать разработку API в первую очередь?
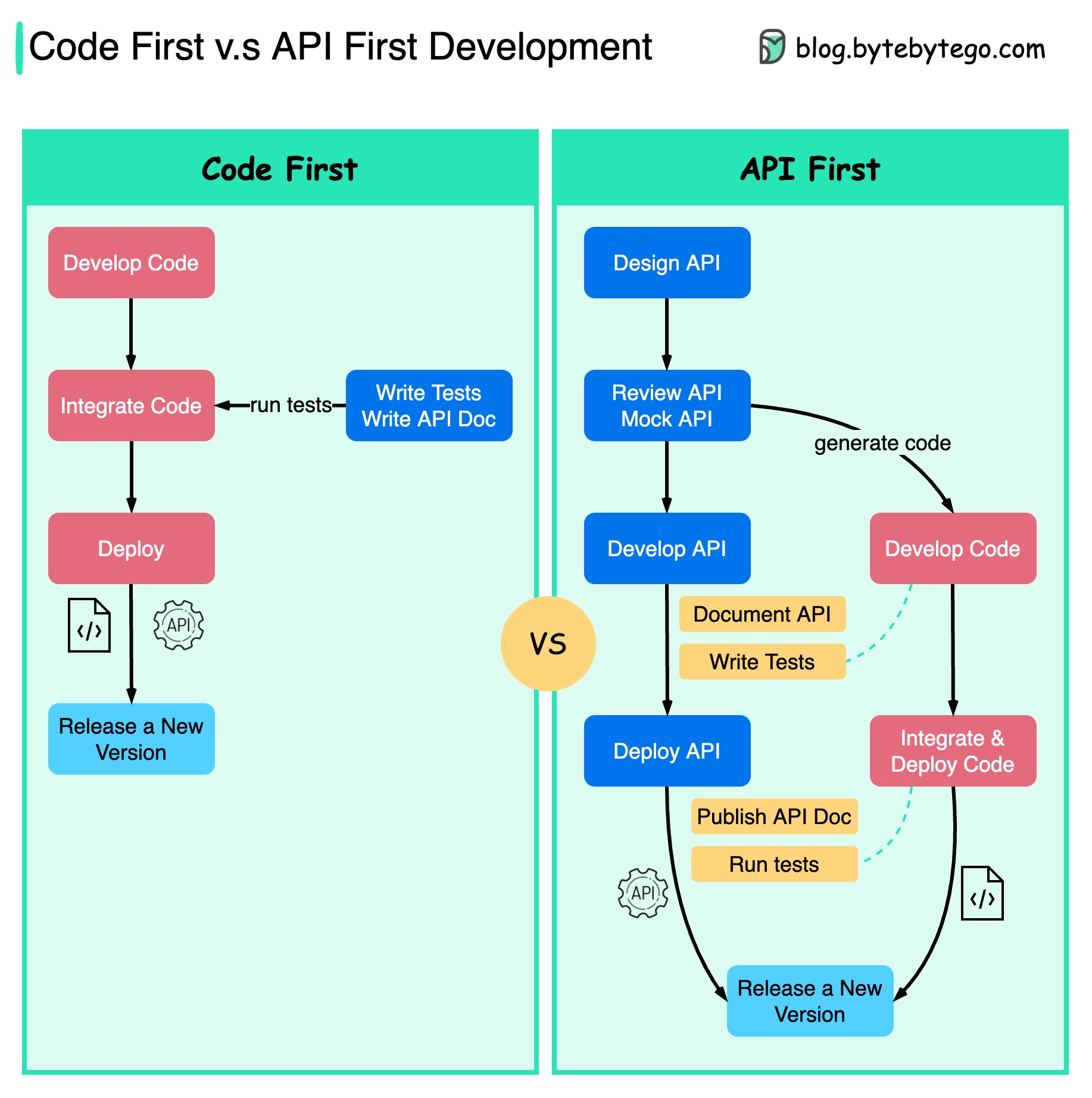
Лучше продумать сложность системы, прежде чем писать код и тщательно определять границы сервисов.
Мы можем имитировать запросы и ответы, чтобы проверить дизайн API перед написанием кода.
Разработчики также довольны этим процессом, поскольку они могут сосредоточиться на функциональной разработке, а не на согласовании внезапных изменений.
Вероятность неожиданностей к концу жизненного цикла проекта снижается.
Поскольку мы сначала разработали API, тесты можно создавать во время разработки кода. В каком-то смысле у нас также есть TDD (Test Driven Design) при первой разработке API.
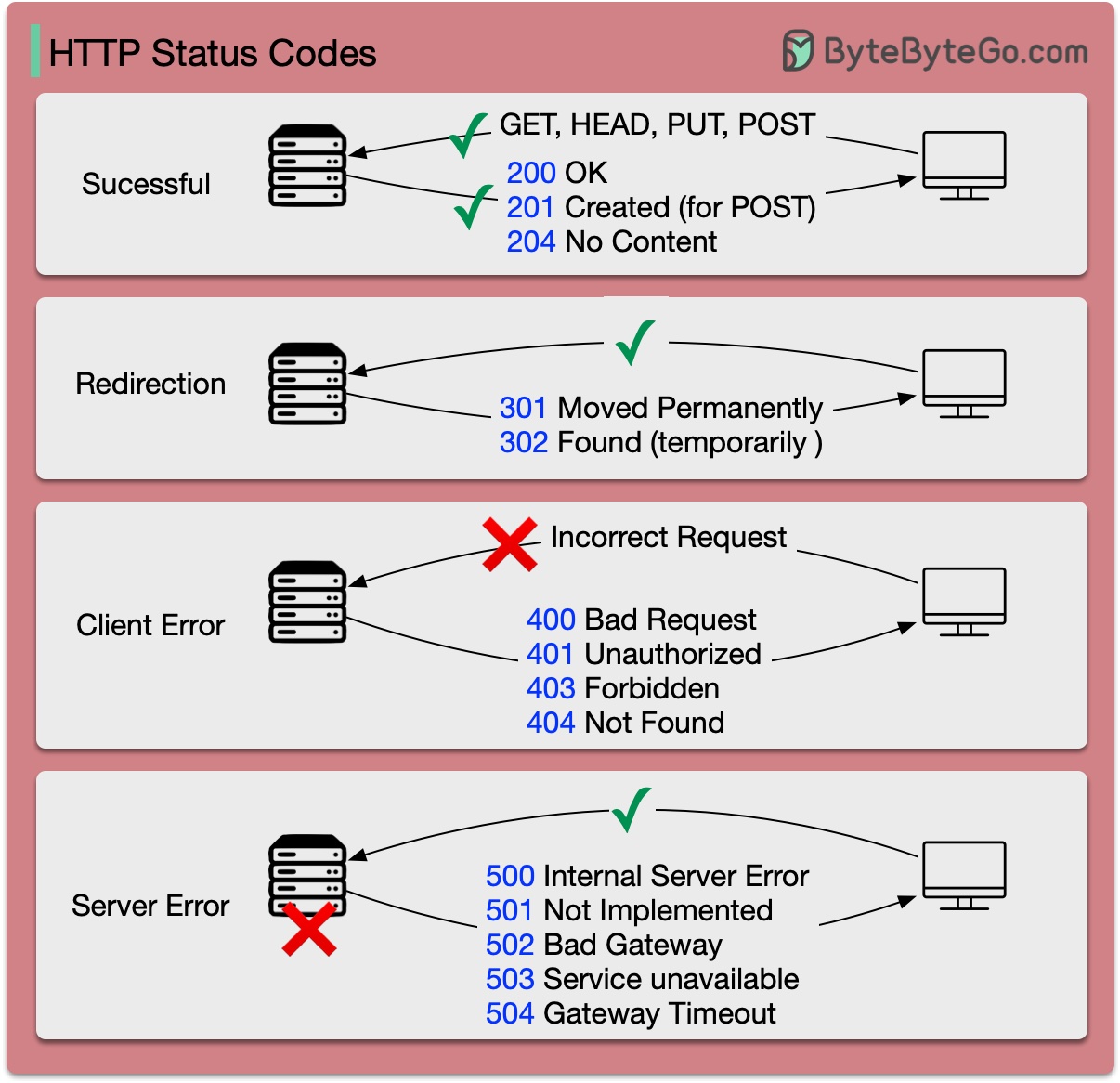
Коды ответа для HTTP разделены на пять категорий:
Информационный (100–199) Успех (200–299) Перенаправление (300–399) Ошибка клиента (400–499) Ошибка сервера (500–599)
На диаграмме ниже показаны детали.
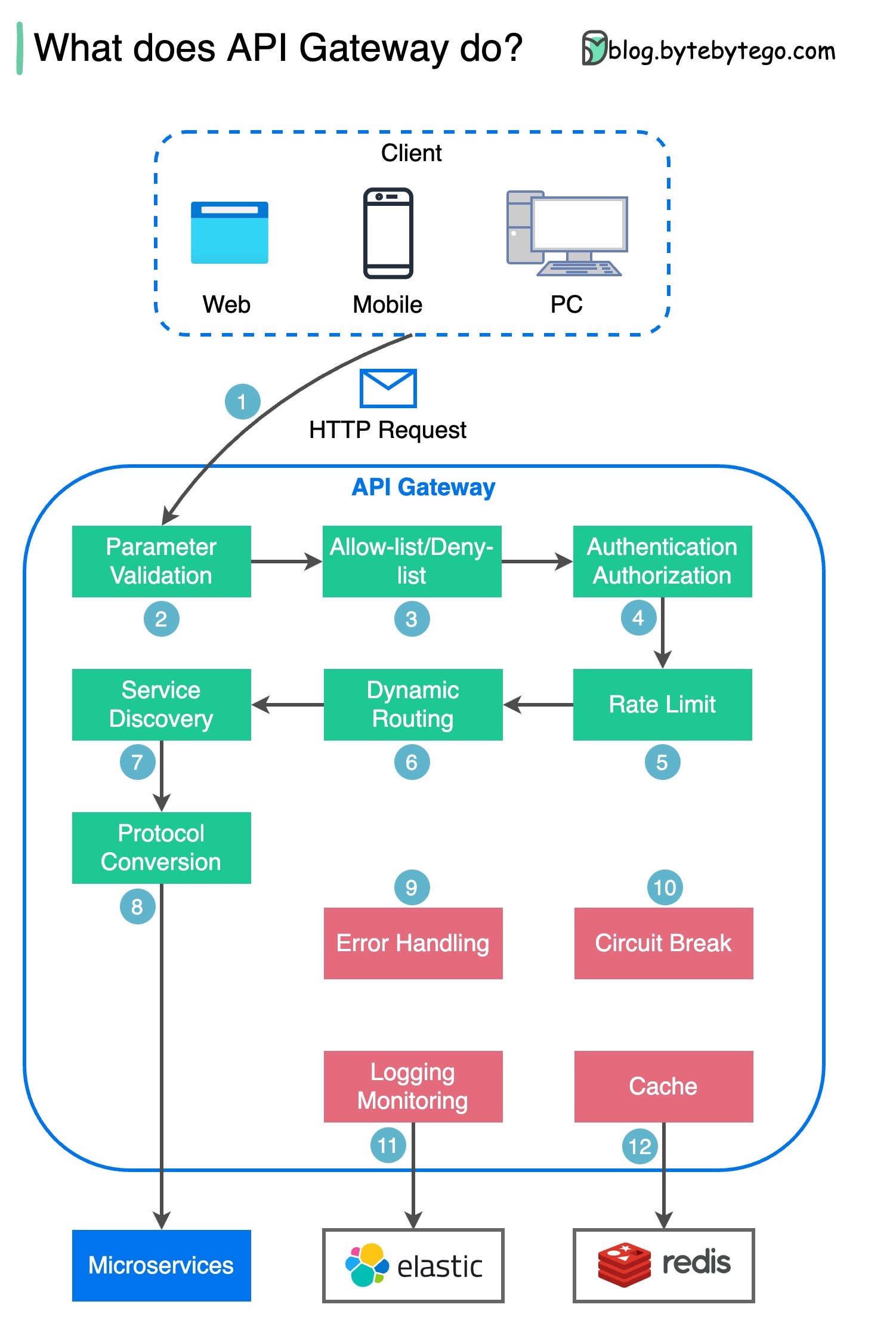
Шаг 1. Клиент отправляет HTTP-запрос на шлюз API.
Шаг 2. Шлюз API анализирует и проверяет атрибуты HTTP-запроса.
Шаг 3. Шлюз API выполняет проверки списков разрешенных и запрещенных.
Шаг 4. Шлюз API обращается к поставщику удостоверений для проверки подлинности и авторизации.
Шаг 5. К запросу применяются правила ограничения скорости. Если оно превышает лимит, запрос отклоняется.
Шаги 6 и 7. Теперь, когда запрос прошел базовые проверки, шлюз API находит соответствующую службу для маршрутизации путем сопоставления пути.
Шаг 8. Шлюз API преобразует запрос в соответствующий протокол и отправляет его серверным микросервисам.
Шаги 9–12. Шлюз API может правильно обрабатывать ошибки и устранять неисправности, если для восстановления ошибки требуется больше времени (обрыв цепи). Он также может использовать стек ELK (Elastic-Logstash-Kibana) для ведения журналов и мониторинга. Иногда мы кэшируем данные в шлюзе API.
На диаграмме ниже показаны типичные конструкции API с примером корзины покупок.
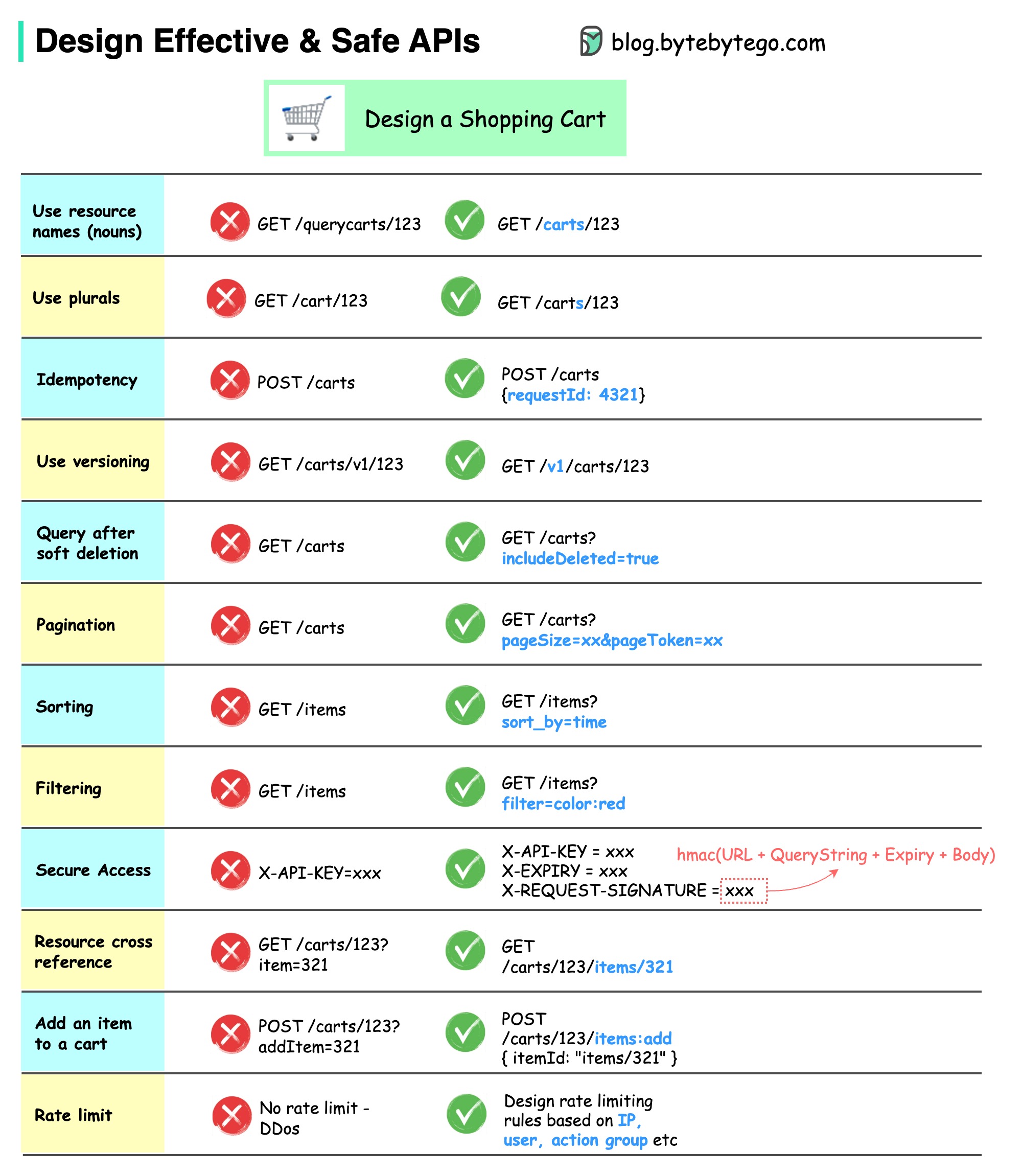
Обратите внимание, что дизайн API — это не просто дизайн URL-пути. В большинстве случаев нам необходимо выбрать правильные имена ресурсов, идентификаторы и шаблоны путей. Не менее важно разработать правильные поля заголовка HTTP или разработать эффективные правила ограничения скорости внутри шлюза API.
Как данные передаются по сети? Зачем нам нужно так много уровней в модели OSI?
На диаграмме ниже показано, как данные инкапсулируются и деинкапсулируются при передаче по сети.
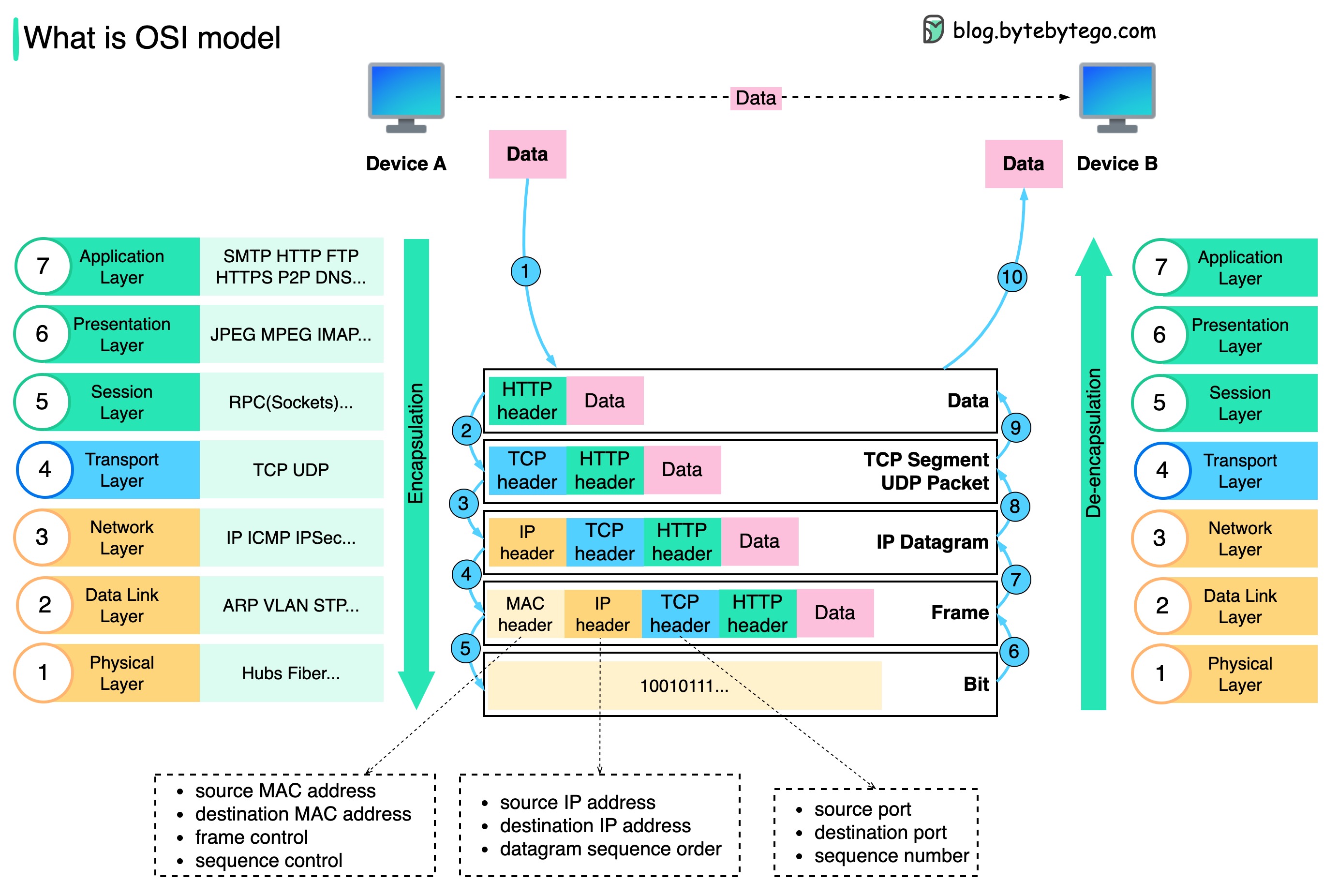
Шаг 1. Когда устройство A отправляет данные устройству B по сети через протокол HTTP, к нему сначала добавляется HTTP-заголовок на уровне приложения.
Шаг 2: Затем к данным добавляется заголовок TCP или UDP. Он инкапсулируется в сегменты TCP на транспортном уровне. Заголовок содержит порт источника, порт назначения и порядковый номер.
Шаг 3. Затем сегменты инкапсулируются с помощью IP-заголовка на сетевом уровне. Заголовок IP содержит IP-адреса источника/назначения.
Шаг 4. К IP-дейтаграмме добавляется MAC-заголовок на уровне канала передачи данных с MAC-адресами источника/назначения.
Шаг 5: Инкапсулированные кадры отправляются на физический уровень и передаются по сети в двоичных битах.
Шаги 6–10: Когда устройство B получает биты из сети, оно выполняет процесс деинкапсуляции, который является обратной обработкой процесса инкапсуляции. Заголовки удаляются слой за слоем, и в конечном итоге Устройство Б может прочитать данные.
Нам нужны уровни в сетевой модели, потому что каждый уровень ориентирован на свои обязанности. Каждый уровень может полагаться на заголовки для инструкций обработки и не обязан знать значение данных последнего уровня.
На диаграмме ниже показаны различия между ??????? ????? и ??????? ??????.
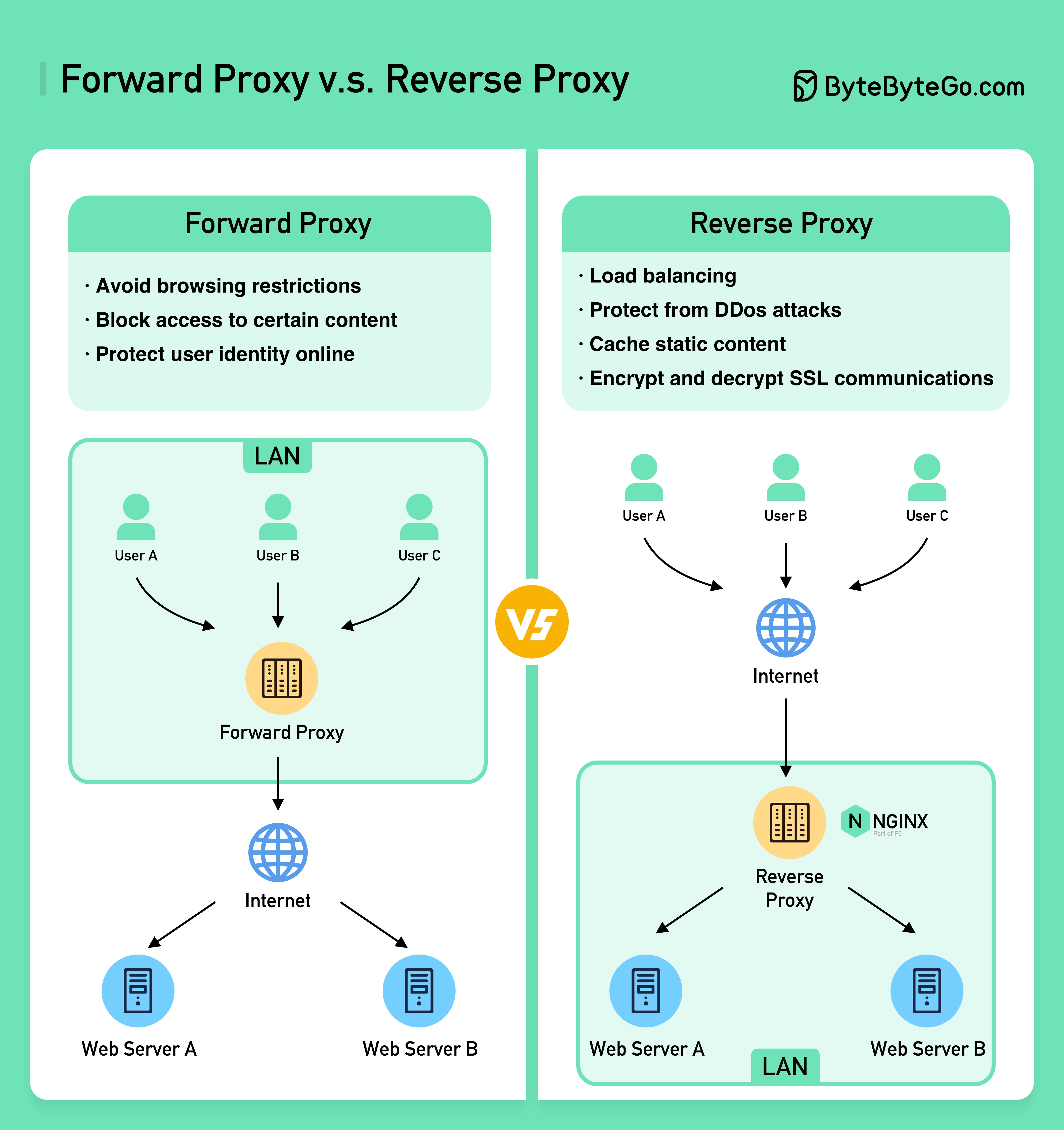
Прямой прокси — это сервер, который находится между пользовательскими устройствами и Интернетом.
Прямой прокси обычно используется для:
Обратный прокси-сервер — это сервер, который принимает запрос от клиента, перенаправляет запрос на веб-серверы и возвращает результаты клиенту, как если бы прокси-сервер обработал запрос.
Обратный прокси-сервер хорош для:
На диаграмме ниже показаны 6 распространенных алгоритмов.
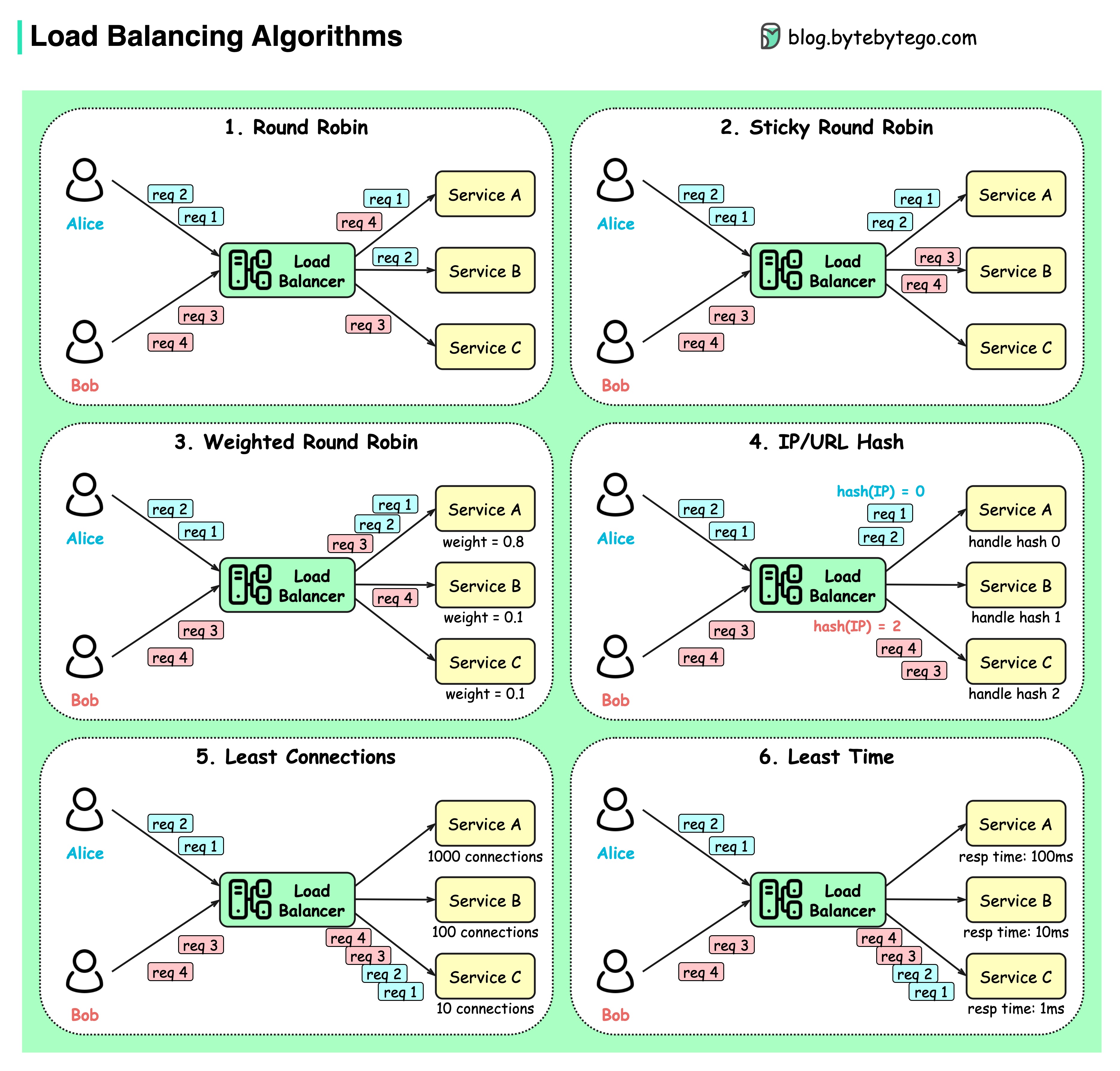
Круговая система
Клиентские запросы отправляются различным экземплярам службы в последовательном порядке. Услуги обычно должны быть без гражданства.
Липкий циклический алгоритм
Это усовершенствование алгоритма циклического перебора. Если первый запрос Алисы направляется к сервису A, последующие запросы также передаются сервису A.
Взвешенный циклический алгоритм
Администратор может указать вес для каждой услуги. Те, у которых больший вес, обрабатывают больше запросов, чем другие.
Хэш
Этот алгоритм применяет хэш-функцию к IP-адресу или URL-адресу входящих запросов. Запросы направляются в соответствующие экземпляры на основе результата хэш-функции.
Наименьшее количество соединений
Новый запрос отправляется экземпляру службы с наименьшим количеством одновременных подключений.
Наименьшее время ответа
Новый запрос отправляется экземпляру службы с самым быстрым временем ответа.
На диаграмме ниже показано сравнение URL, URI и URN.
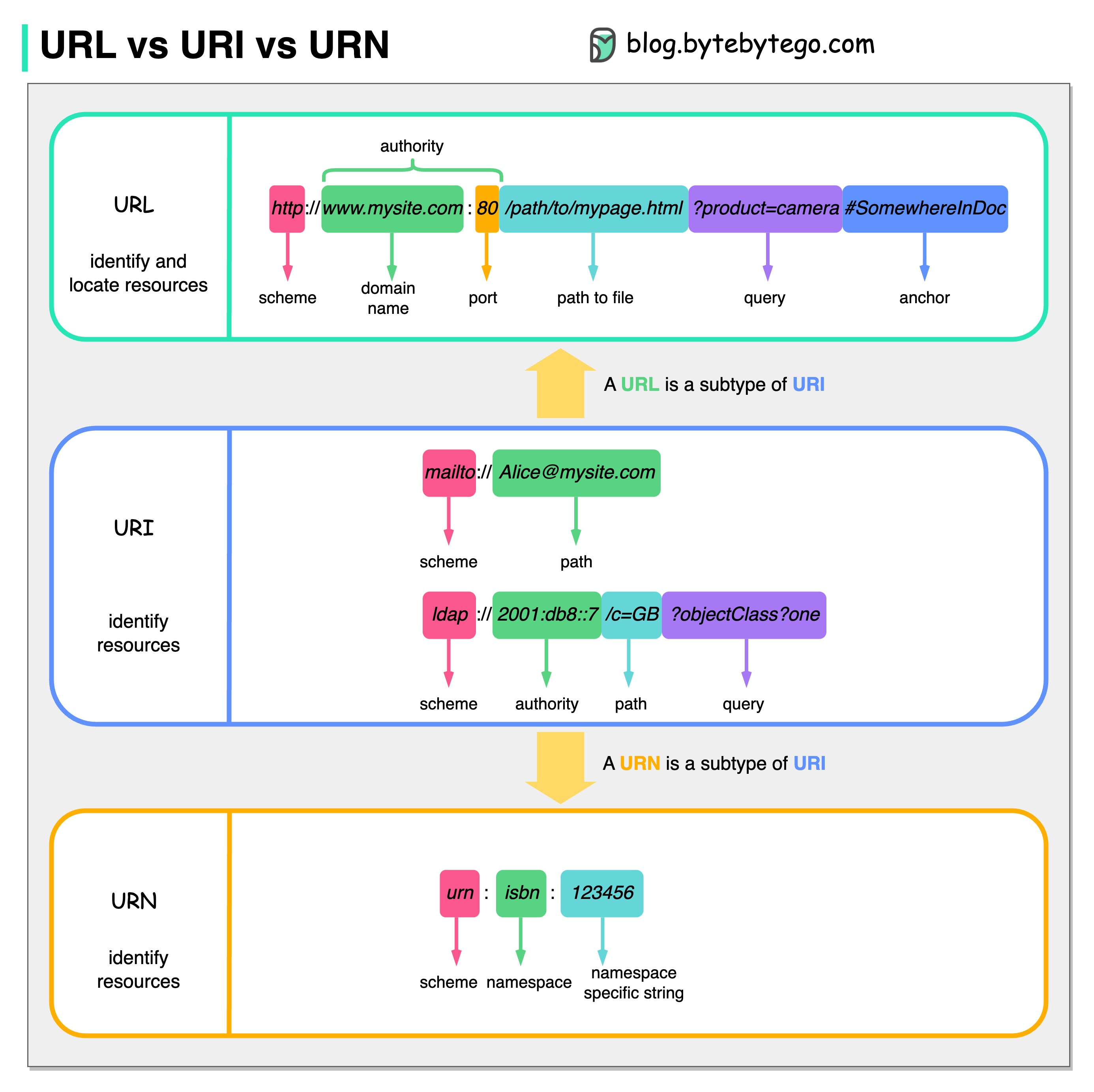
URI означает универсальный идентификатор ресурса. Он идентифицирует логический или физический ресурс в сети. URL и URN являются подтипами URI. URL определяет ресурс, а URN называет ресурс.
URI состоит из следующих частей: схема:[//authority]путь[?запрос][#фрагмент]
URL означает Uniform Resource Locator, ключевую концепцию HTTP. Это адрес уникального ресурса в сети. Его можно использовать с другими протоколами, такими как FTP и JDBC.
URN означает единое имя ресурса. Он использует схему урны. URN нельзя использовать для поиска ресурса. Простой пример, приведенный на диаграмме, состоит из пространства имен и строки, специфичной для пространства имен.
Если вы хотите узнать больше по этому вопросу, я бы порекомендовал разъяснения W3C.
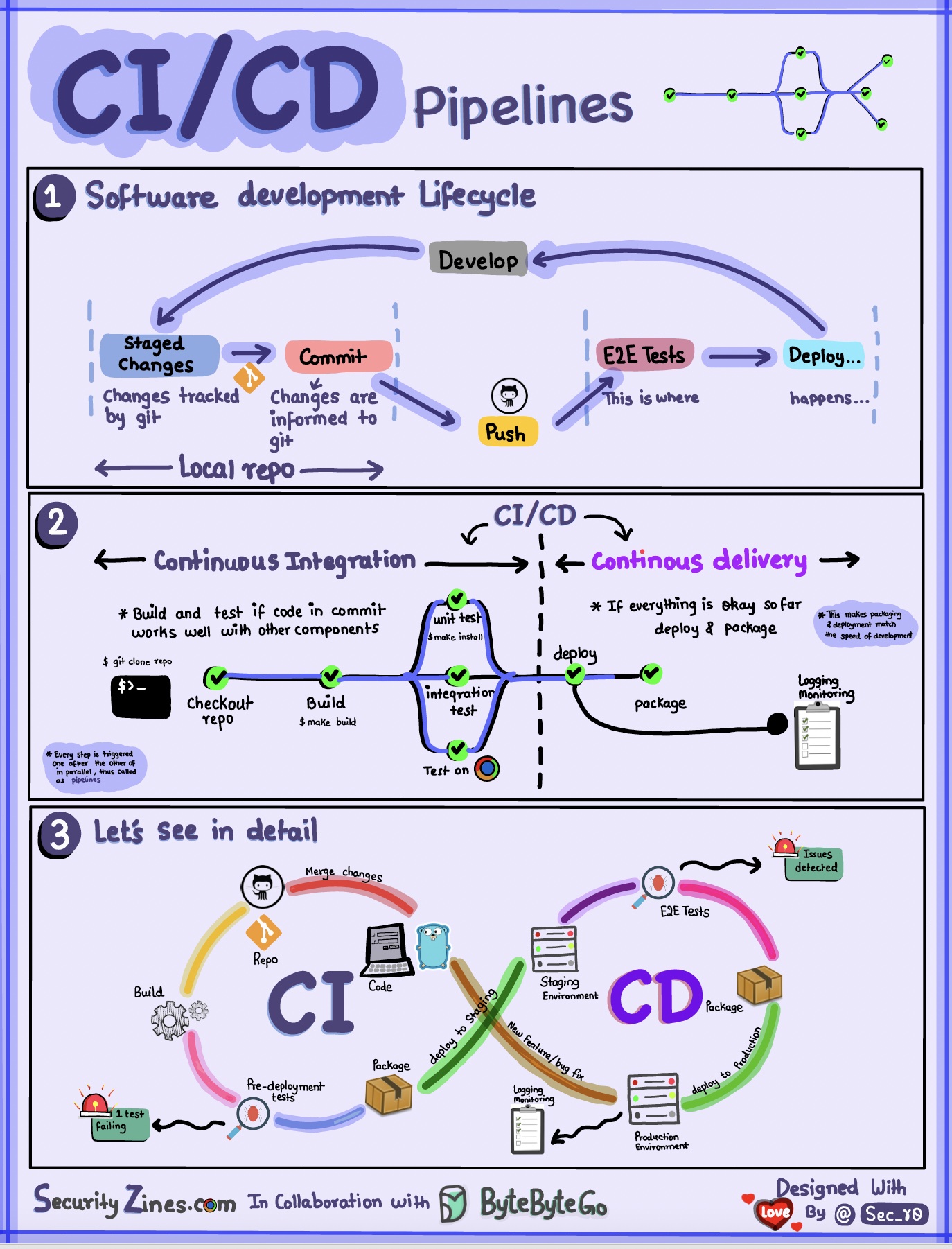
Раздел 1. SDLC с CI/CD
Жизненный цикл разработки программного обеспечения (SDLC) состоит из нескольких ключевых этапов: разработка, тестирование, развертывание и обслуживание. CI/CD автоматизирует и интегрирует эти этапы, чтобы обеспечить более быстрые и надежные выпуски.
Когда код отправляется в репозиторий git, он запускает автоматический процесс сборки и тестирования. Сквозные тестовые сценарии (e2e) запускаются для проверки кода. Если тесты пройдены, код можно автоматически развернуть в промежуточной/производственной среде. Если обнаруживаются проблемы, код отправляется обратно в разработку для исправления ошибок. Эта автоматизация обеспечивает быструю обратную связь с разработчиками и снижает риск ошибок в производстве.
Раздел 2. Разница между CI и CD
Непрерывная интеграция (CI) автоматизирует процессы сборки, тестирования и слияния. Он запускает тесты всякий раз, когда код используется для раннего обнаружения проблем интеграции. Это поощряет частые коммиты кода и быструю обратную связь.
Непрерывная доставка (CD) автоматизирует процессы выпуска, такие как изменения инфраструктуры и развертывание. Это гарантирует, что программное обеспечение может быть надежно выпущено в любое время посредством автоматизированных рабочих процессов. CD также может автоматизировать этапы ручного тестирования и утверждения, необходимые перед развертыванием в рабочей среде.
Раздел 3. Конвейер CI/CD
Типичный конвейер CI/CD состоит из нескольких связанных между собой этапов:
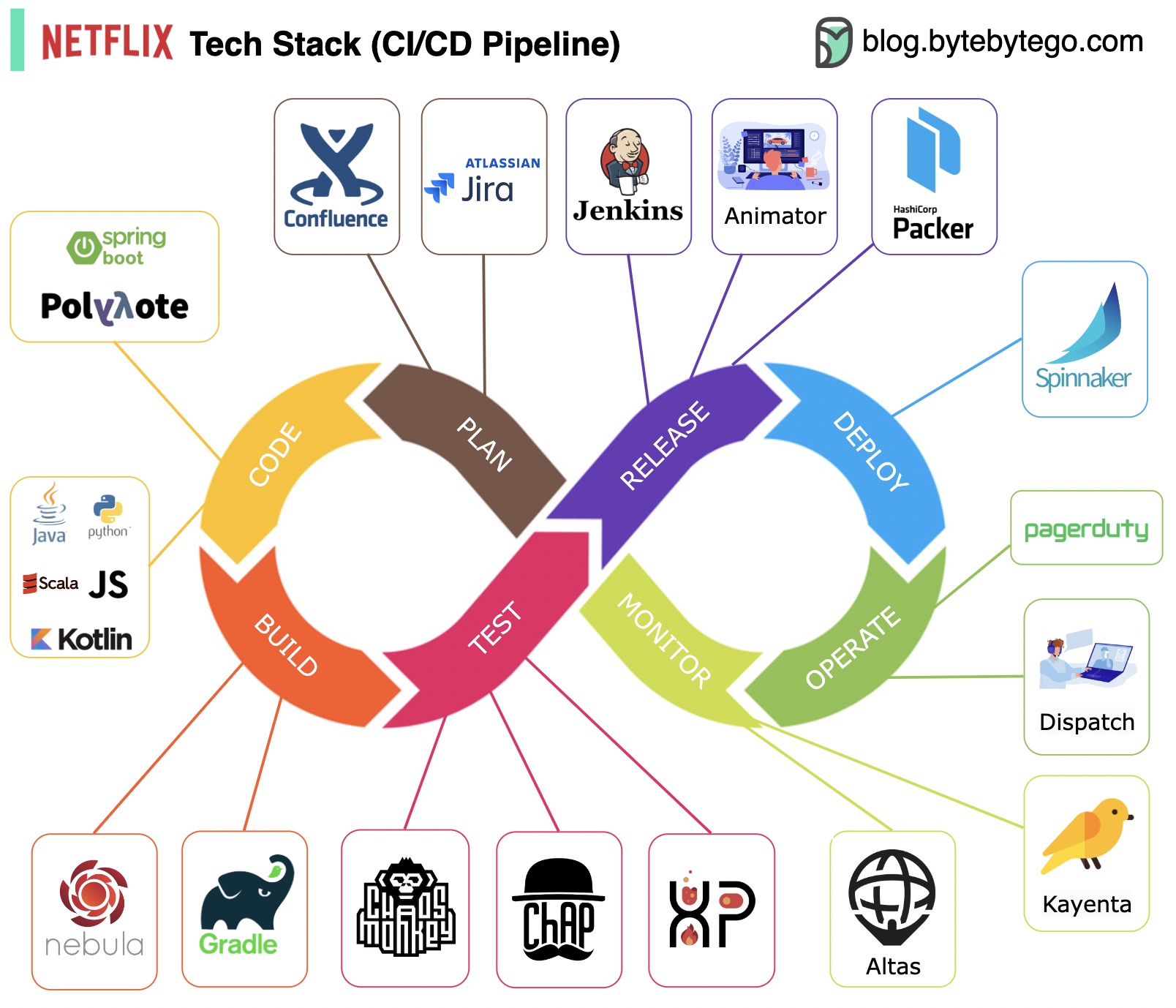
Планирование: Netflix Engineering использует JIRA для планирования и Confluence для документации.
Кодирование: Java является основным языком программирования для серверной службы, тогда как другие языки используются для разных случаев использования.
Сборка: Gradle в основном используется для сборки, а плагины Gradle созданы для поддержки различных вариантов использования.
Упаковка: пакет и зависимости упаковываются в образ машины Amazon (AMI) для выпуска.
Тестирование. Тестирование подчеркивает фокус производственной культуры на создании инструментов хаоса.
Развертывание: Netflix использует собственный Spinnaker для развертывания Canary.
Мониторинг. Показатели мониторинга централизованы в Atlas, а Kayenta используется для обнаружения аномалий.
Отчет об инцидентах: инциденты отправляются в соответствии с приоритетом, а для обработки инцидентов используется PagerDuty.
Эти архитектурные шаблоны являются одними из наиболее часто используемых при разработке приложений на платформах iOS или Android. Разработчики ввели их, чтобы преодолеть ограничения более ранних шаблонов. Итак, чем они отличаются?
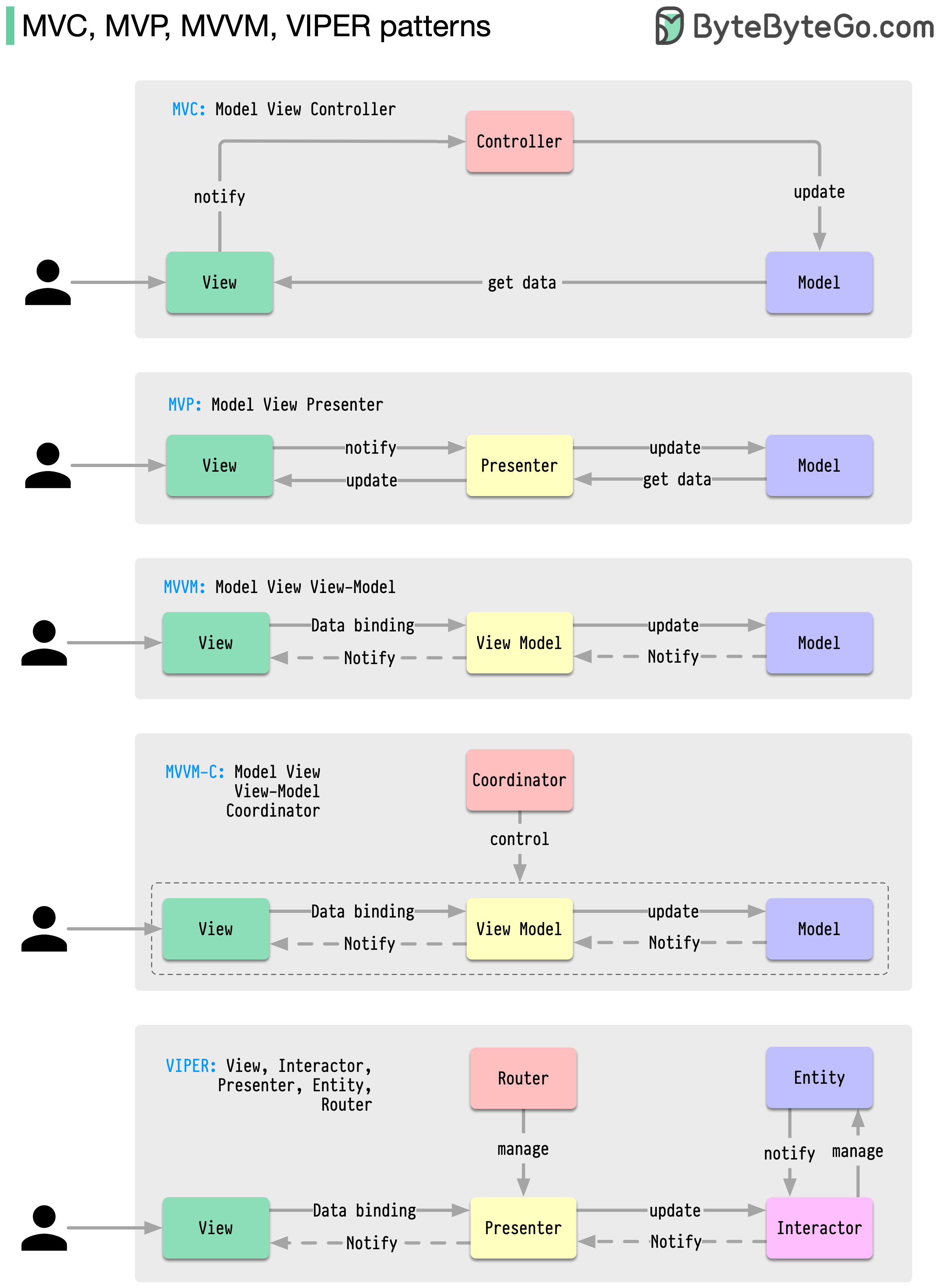
Шаблоны — это многократно используемые решения распространенных проблем проектирования, что позволяет сделать процесс разработки более плавным и эффективным. Они служат образцом для создания более совершенных структур программного обеспечения. Вот некоторые из самых популярных моделей:

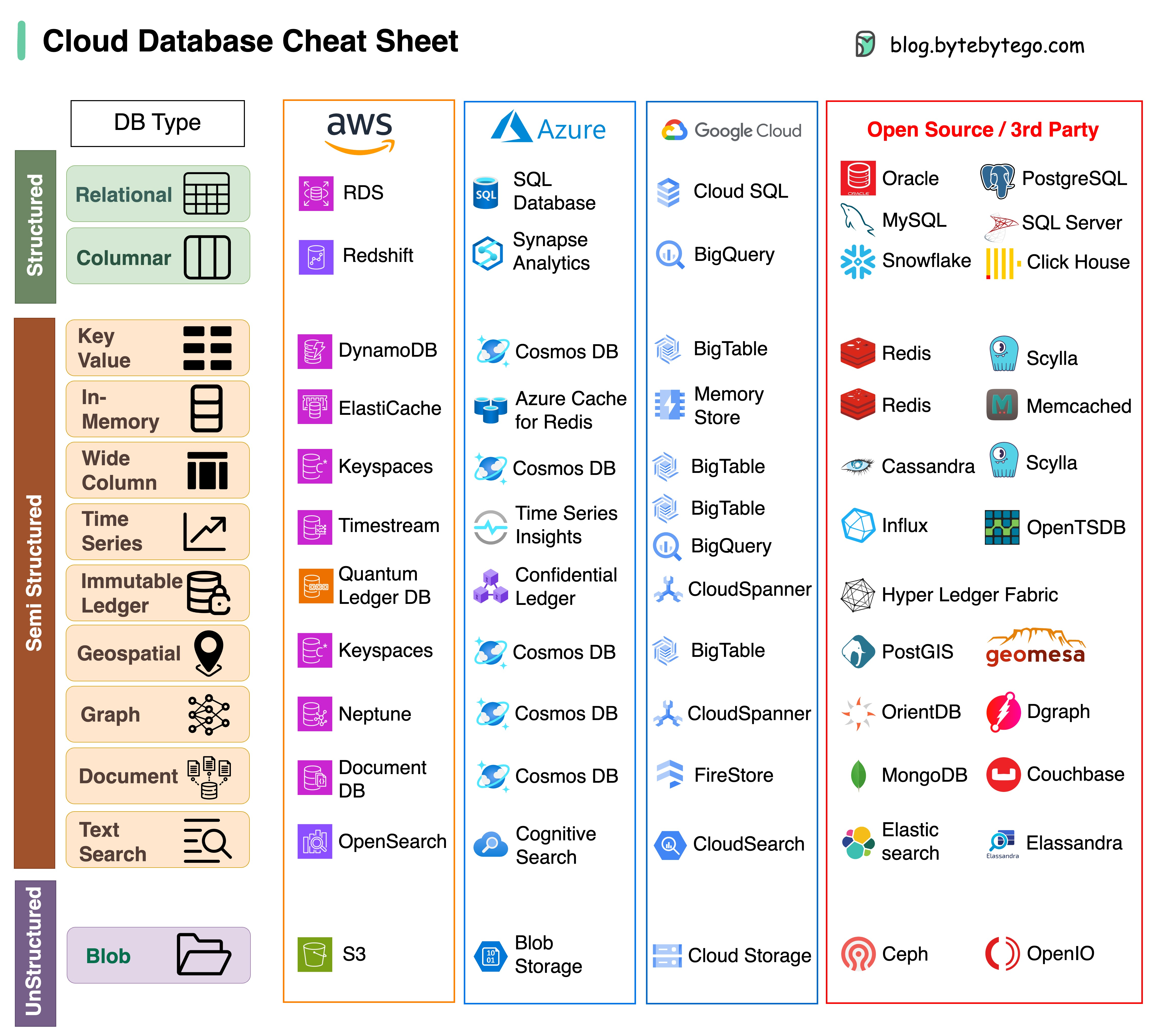
Выбор подходящей базы данных для вашего проекта — сложная задача. Множество вариантов баз данных, каждый из которых подходит для различных вариантов использования, может быстро привести к утомлению принятия решений.
Мы надеемся, что эта шпаргалка предоставит общие рекомендации, позволяющие определить правильную услугу, соответствующую потребностям вашего проекта, и избежать потенциальных ошибок.
Примечание. Google имеет ограниченную документацию по вариантам использования своих баз данных. Несмотря на то, что мы приложили все усилия, чтобы просмотреть то, что было доступно, и пришли к лучшему варианту, некоторые записи, возможно, должны быть более точными.
Ответ будет зависеть от вашего варианта использования. Данные могут индексироваться в памяти или на диске. Точно так же различаются форматы данных, например числа, строки, географические координаты и т. д. Система может быть требовательна к записи или чтению. Все эти факторы влияют на выбор формата индекса базы данных.
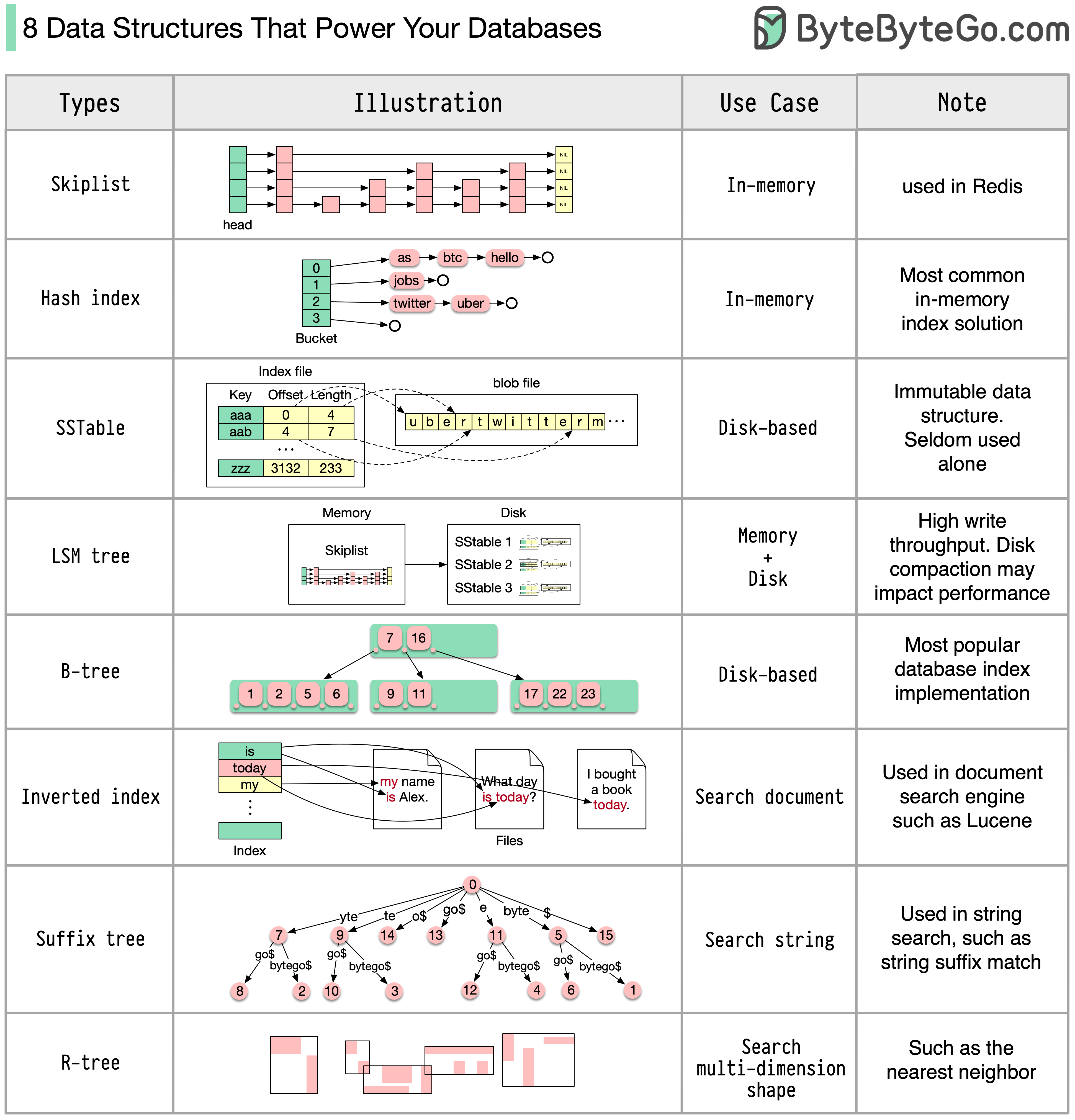
Ниже приведены некоторые из наиболее популярных структур данных, используемых для индексации данных:
На диаграмме ниже показан процесс. Обратите внимание, что архитектуры для разных баз данных различны, на схеме показаны некоторые общие конструкции.
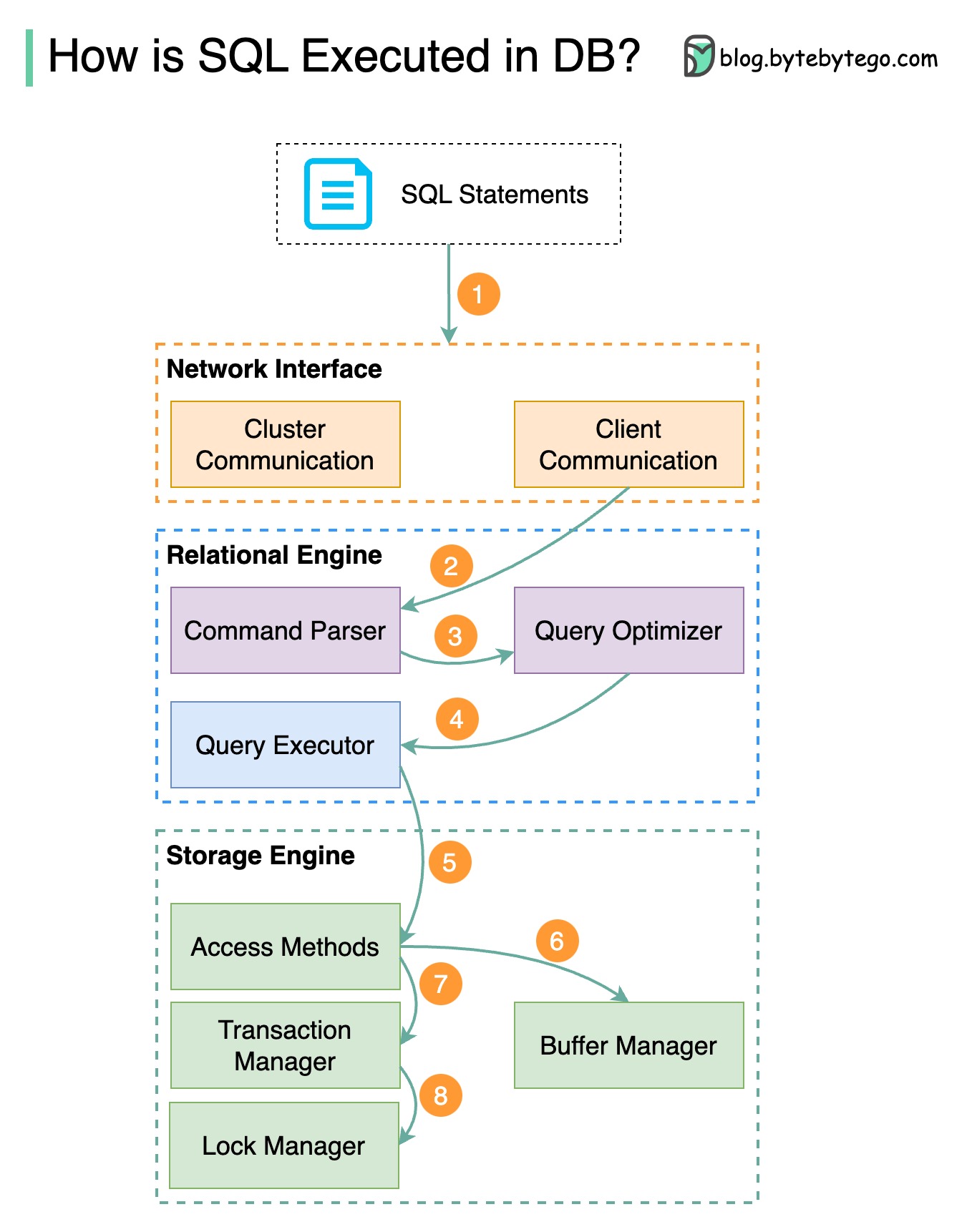
Шаг 1. Оператор SQL отправляется в базу данных через протокол транспортного уровня (например, TCP).
Шаг 2. Оператор SQL отправляется в синтаксический анализатор команд, где он проходит синтаксический и семантический анализ, после чего генерируется дерево запроса.
Шаг 3. Дерево запросов отправляется оптимизатору. Оптимизатор создает план выполнения.
Шаг 4 – План выполнения передается исполнителю. Исполнитель извлекает данные из выполнения.
Шаг 5. Методы доступа обеспечивают логику выборки данных, необходимую для выполнения, извлекая данные из механизма хранения.
Шаг 6. Методы доступа решают, доступен ли оператор SQL только для чтения. Если запрос доступен только для чтения (оператор SELECT), он передается диспетчеру буферов для дальнейшей обработки. Менеджер буферов ищет данные в кэше или файлах данных.
Шаг 7. Если оператор является UPDATE или INSERT, он передается менеджеру транзакций для дальнейшей обработки.
Шаг 8. Во время транзакции данные находятся в режиме блокировки. Это гарантируется менеджером блокировок. Он также обеспечивает свойства ACID транзакции.
Теорема CAP — один из самых известных терминов в информатике, но я готов поспорить, что разные разработчики понимают ее по-разному. Давайте разберемся, что это такое и почему это может сбивать с толку.
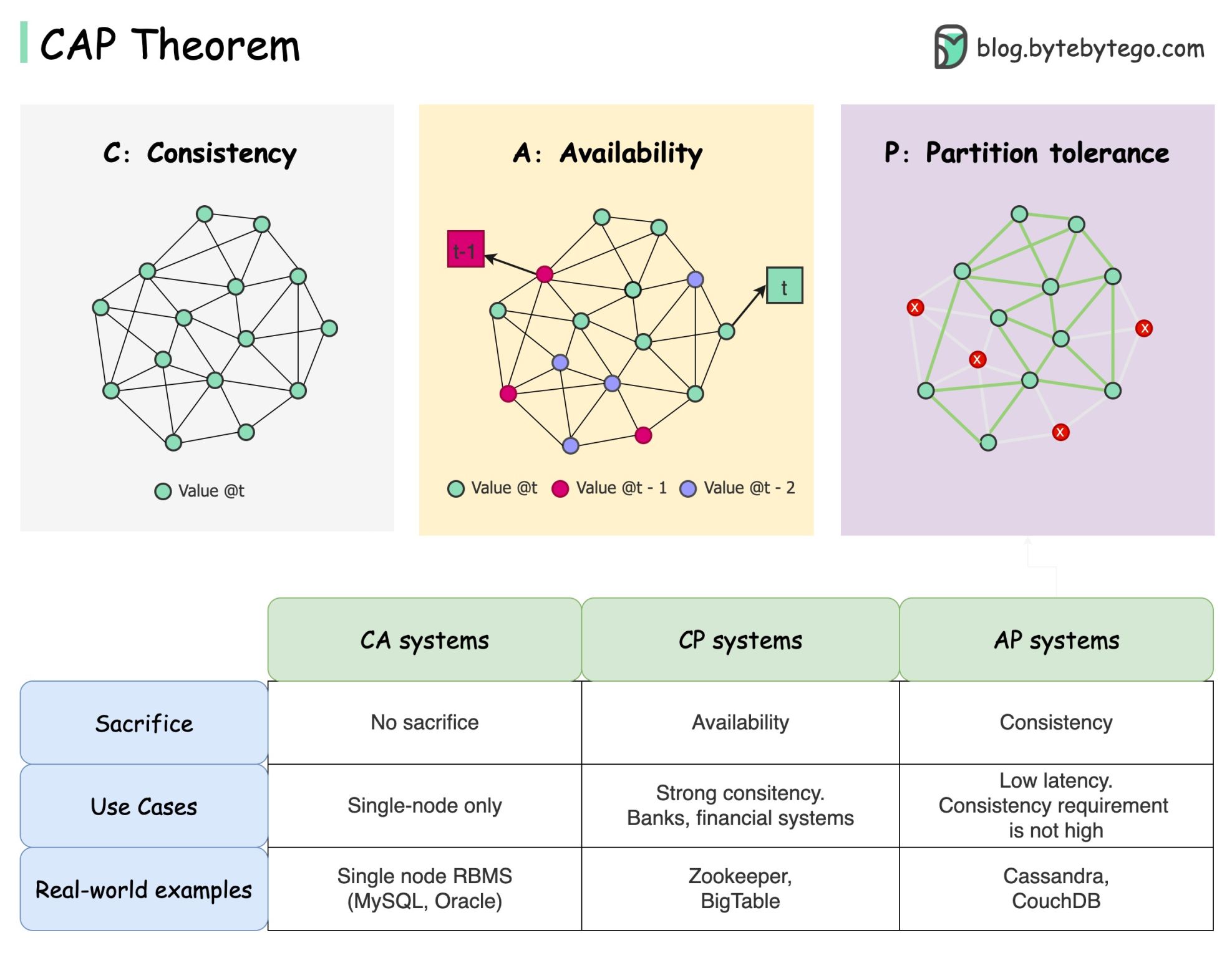
Теорема CAP утверждает, что распределенная система не может обеспечить одновременно более двух из этих трех гарантий.
Согласованность : согласованность означает, что все клиенты видят одни и те же данные одновременно, независимо от того, к какому узлу они подключаются.
Доступность : доступность означает, что любой клиент, запрашивающий данные, получает ответ, даже если некоторые узлы не работают.
Допуск раздела : раздел указывает на разрыв связи между двумя узлами. Толерантность к разделам означает, что система продолжает работать, несмотря на наличие сетевых разделов.
Формулировка «2 из 3» может быть полезной, но такое упрощение может ввести в заблуждение .
Выбрать базу данных непросто. Оправдать наш выбор исключительно теоремой CAP недостаточно. Например, компании не выбирают Cassandra для приложений чата просто потому, что это система AP. Существует список хороших характеристик, которые делают Cassandra желательным вариантом для хранения сообщений чата. Нам нужно копать глубже.
«CAP запрещает лишь небольшую часть проектного пространства: идеальная доступность и согласованность при наличии перегородок, которые встречаются редко». Цитата из статьи: CAP «Двенадцать лет спустя: как изменились «правила».
Теорема — о 100% доступности и непротиворечивости. Более реалистичным обсуждением был бы компромисс между задержкой и согласованностью при отсутствии разделения сети. Более подробную информацию см. в теореме PACELC.
Действительно ли теорема CAP полезна?
Я думаю, что это по-прежнему полезно, поскольку открывает нам ряд дискуссий о компромиссных решениях, но это только часть истории. Нам нужно копнуть глубже, выбирая правильную базу данных.
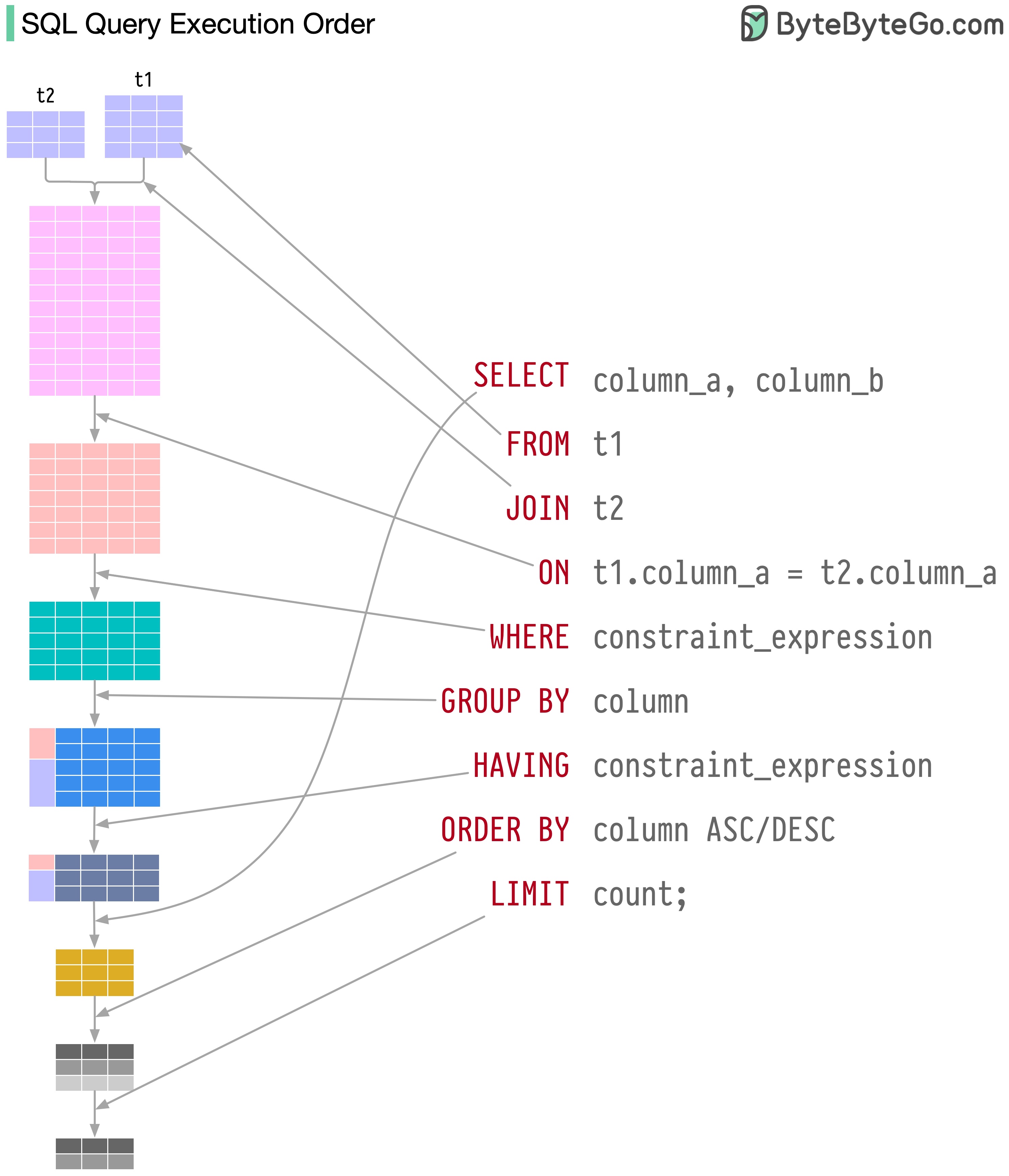
Операторы SQL выполняются системой базы данных в несколько этапов, включая:
Выполнение SQL очень сложно и требует множества факторов, таких как:
В 1986 году SQL (язык структурированных запросов) стал стандартом. В течение следующих 40 лет он стал доминирующим языком систем управления реляционными базами данных. Чтение последнего стандарта (ANSI SQL 2016) может занять много времени. Как я могу этому научиться?
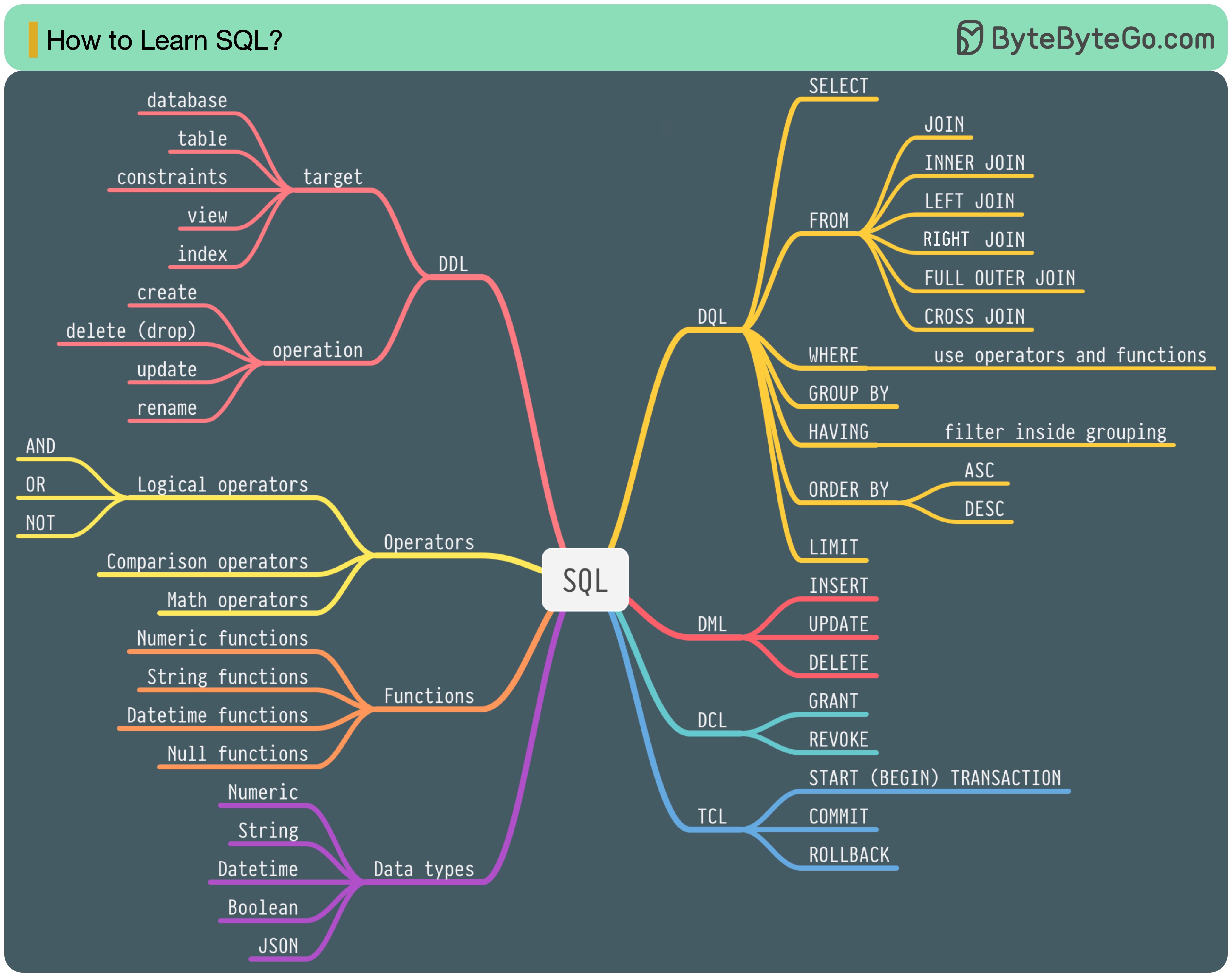
Существует 5 компонентов языка SQL:
Для бэкэнд-инженера вам, возможно, придется знать большую часть этого. Как аналитику данных, вам может потребоваться хорошее понимание DQL. Выберите темы, которые наиболее актуальны для вас.
Эта диаграмма показывает, где мы кэшируем данные в типичной архитектуре.
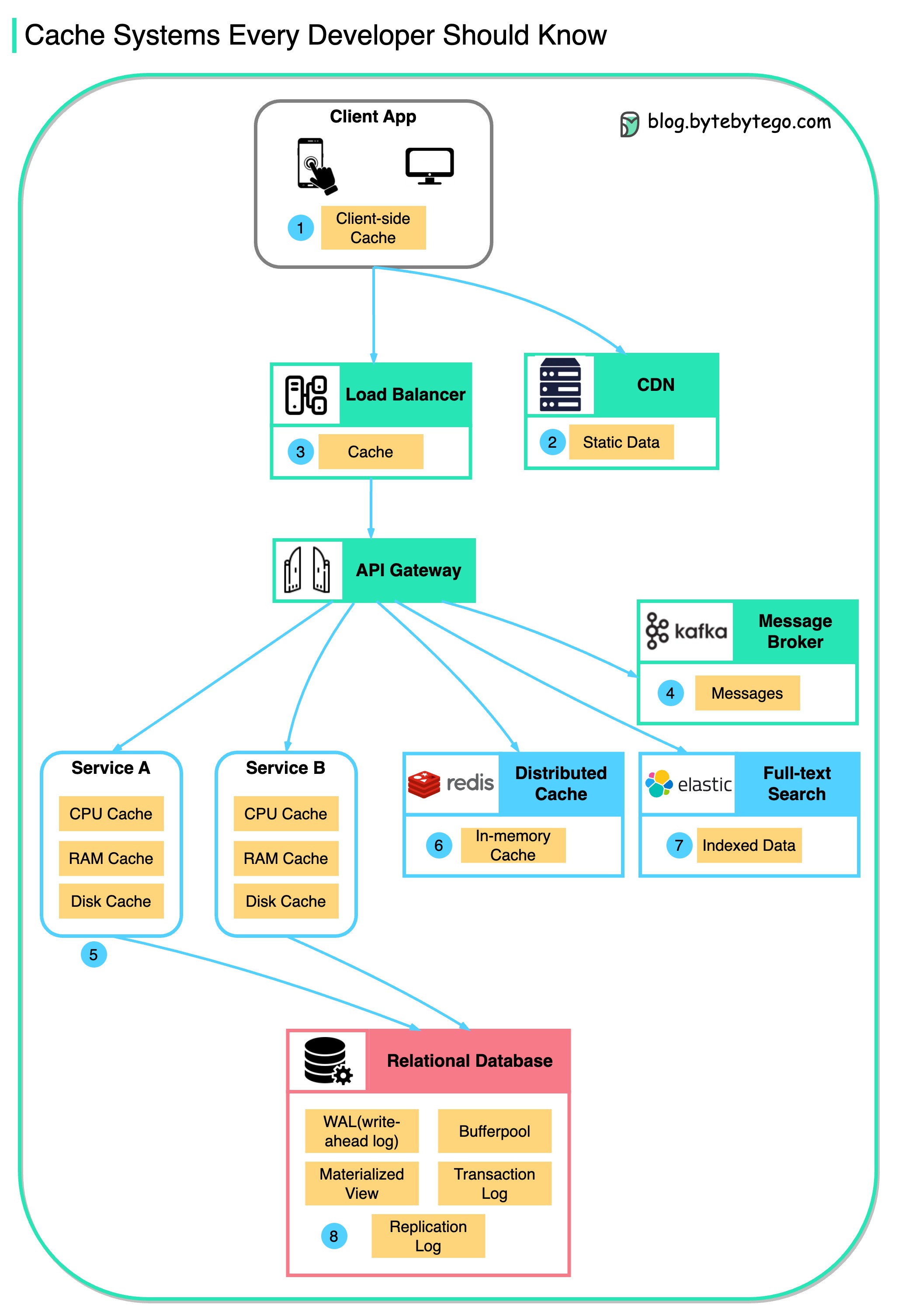
В потоке имеется несколько слоев .
Есть 3 основные причины, как показано на диаграмме ниже.
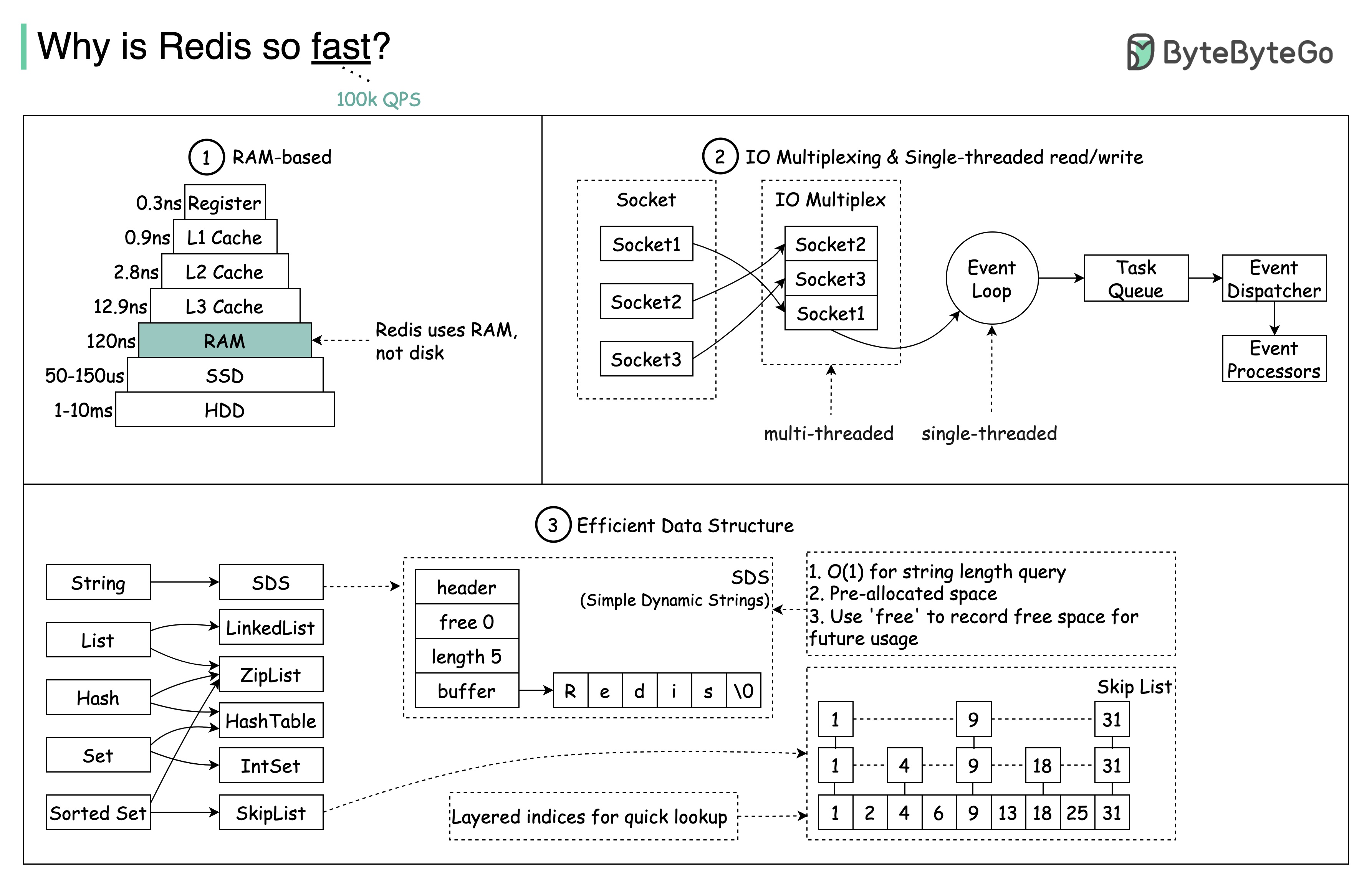
Вопрос: Еще одно популярное хранилище данных в памяти — Memcached. Вы знаете различия между Redis и Memcached?
Возможно, вы заметили, что стиль этой диаграммы отличается от моих предыдущих постов. Пожалуйста, дайте мне знать, какой вы предпочитаете.
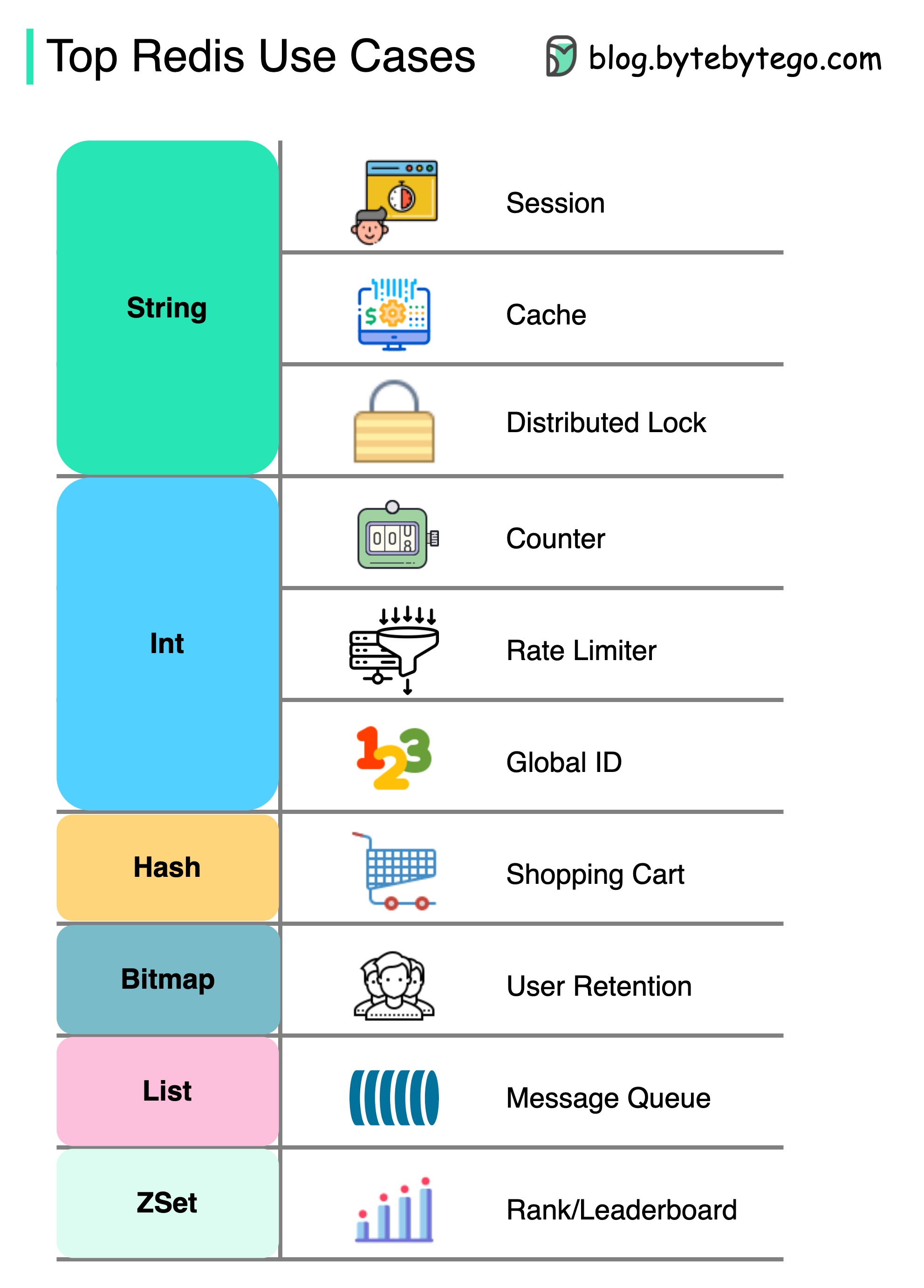
Редис есть нечто большее, чем просто кэширование.
Redis можно использовать в различных сценариях, как показано на диаграмме.
Сессия
Мы можем использовать Redis, чтобы обмениваться данными сеанса пользователя между различными службами.
Кэш
Мы можем использовать Redis для кэша объектов или страниц, особенно для данных горячих точек.
Распределенная блокировка
Мы можем использовать строку Redis для приобретения замков между распределенными услугами.
Прилавок
Мы можем подсчитать, сколько лайков или сколько читает для статей.
Ограничитель тарифов
Мы можем применить ограничитель скорости для определенных пользовательских IPS.
Глобальный генератор ID
Мы можем использовать Redis Int для Global Id.
Корзина
Мы можем использовать Redis Hash, чтобы представлять пары ключевых значений в корзине.
Рассчитайте удержание пользователей
Мы можем использовать растровый карту, чтобы представлять пользовательский вход ежедневно и вычислить удержание пользователей.
Очередь сообщений
Мы можем использовать список для очереди сообщений.
Рейтинг
Мы можем использовать ZSET для сортировки статей.
Проектирование крупномасштабных систем обычно требует тщательного рассмотрения кэширования. Ниже приведены пять стратегий кэширования, которые часто используются.
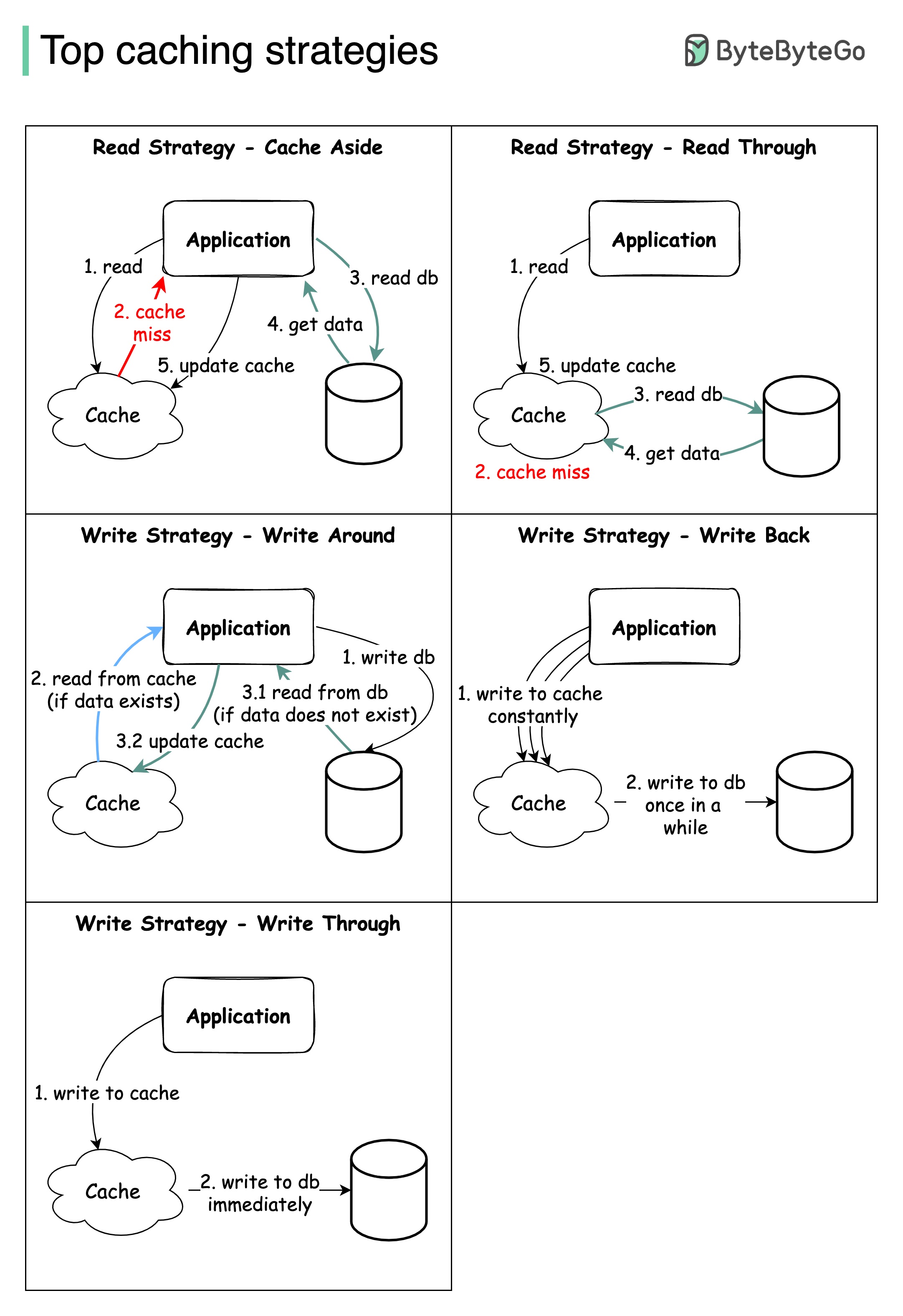
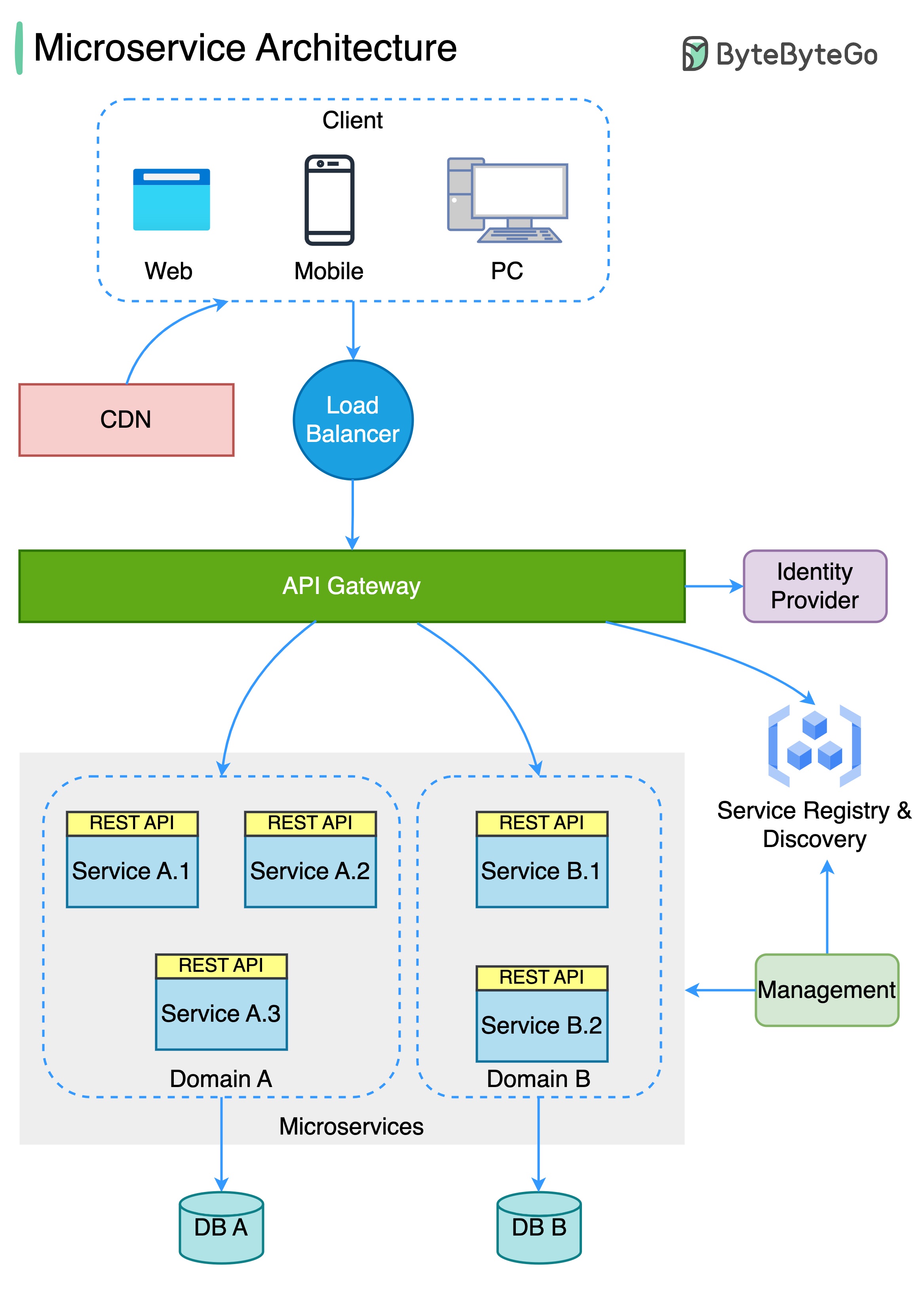
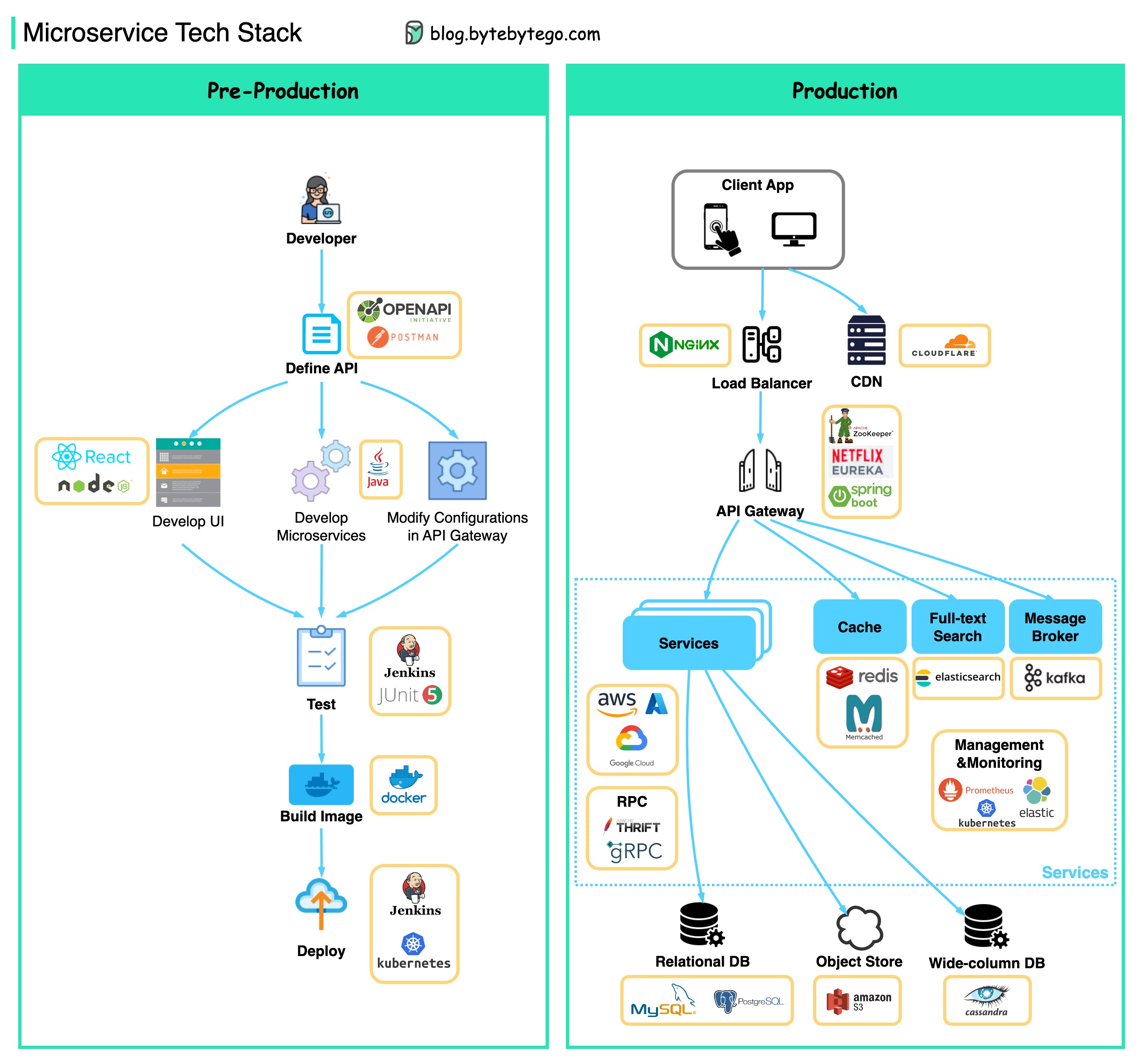
Диаграмма ниже показывает типичную архитектуру микросервиса.
Преимущества микросервисов:
Картина стоит тысячи слов: 9 лучших практик для разработки микросервисов.
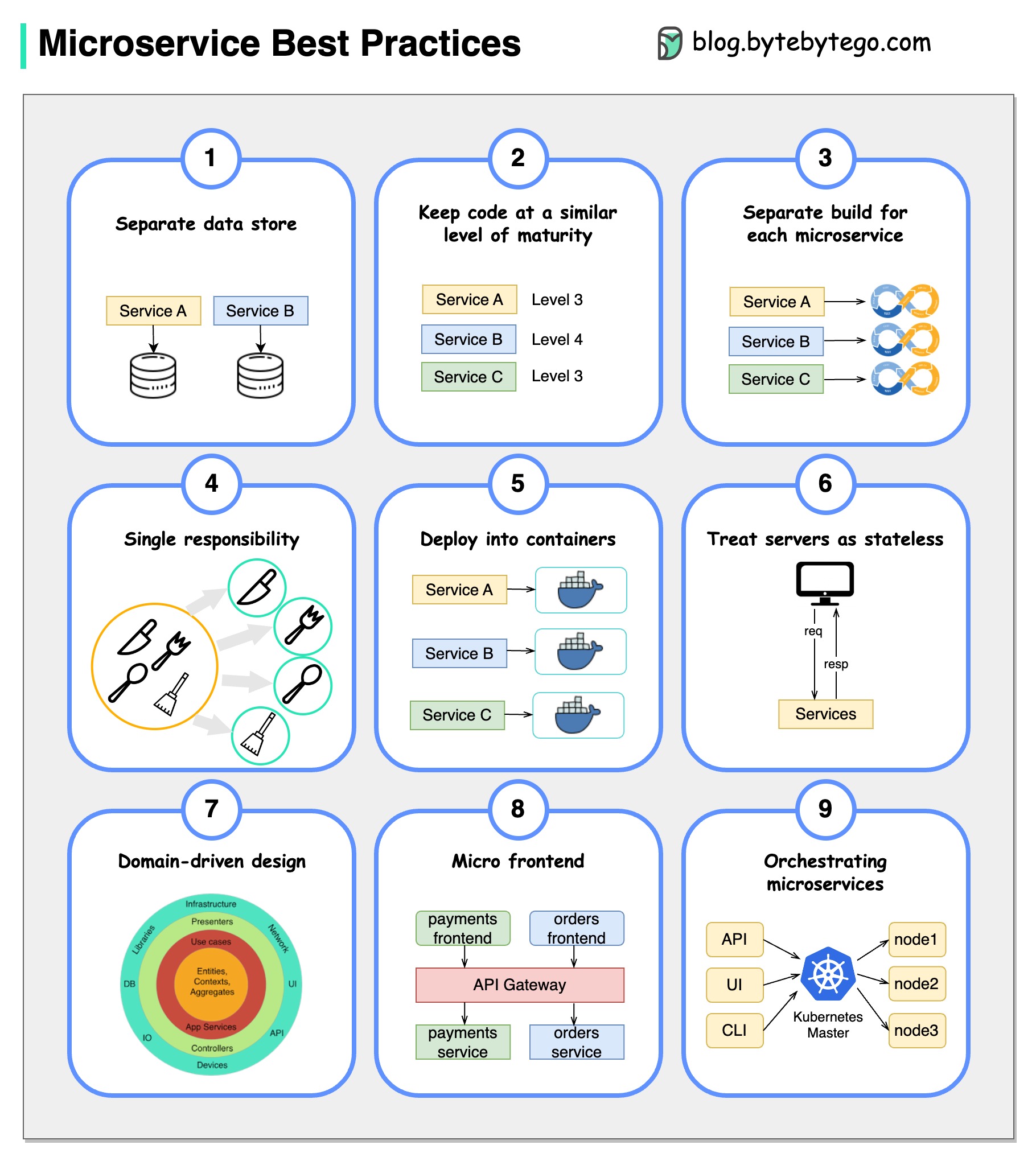
Когда мы разрабатываем микросервисы, мы должны следовать следующим лучшим практикам:
Ниже вы найдете диаграмму, показывающую технологический стек MicroService, как для фазы разработки, так и для производства.
Есть много дизайнерских решений, которые способствовали производительности Кафки. В этом посте мы сосредоточимся на двух. Мы думаем, что эти двое носили наибольший вес.
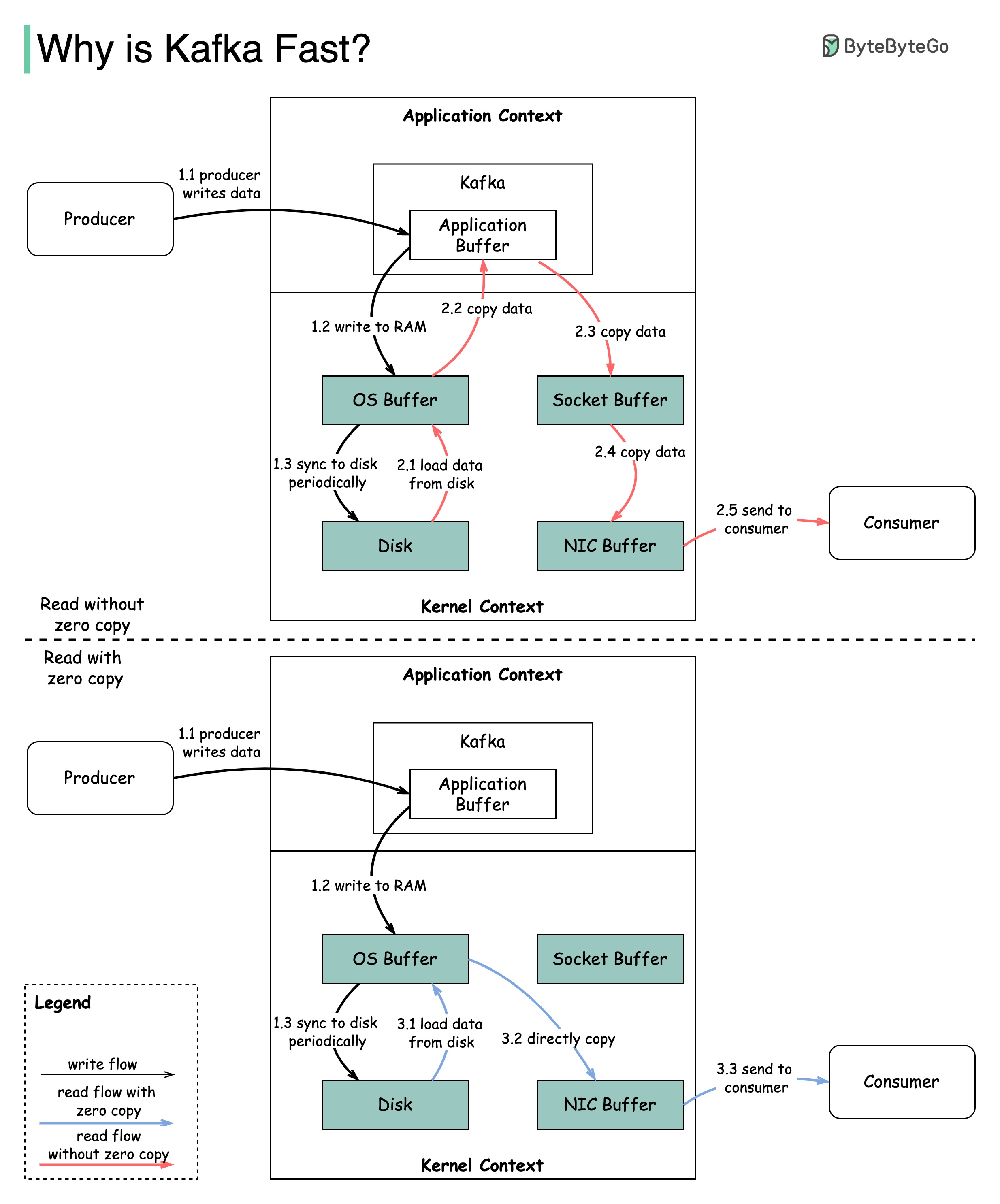
Диаграмма иллюстрирует, как данные передаются между производителем и потребителем, и что означает нулевая копия.
2.1 Данные загружаются с диска в кэш ОС
2.2 Данные копируются из кэша ОС в приложение KAFKA
2.3 Приложение KAFKA копирует данные в буфер сокета
2.4 Данные копируются из буфера сокета в сетевую карту
2.5 Сетевая карта отправляет данные потребителю
3.1: Данные загружаются из диска в ОС Cache 3.2 Cache ОС.
Zero Copy - это ярлык для сохранения нескольких копий данных между контекстом приложения и контекстом ядра.
На приведенной ниже диаграмме показана экономика потока оплаты кредитных карт.
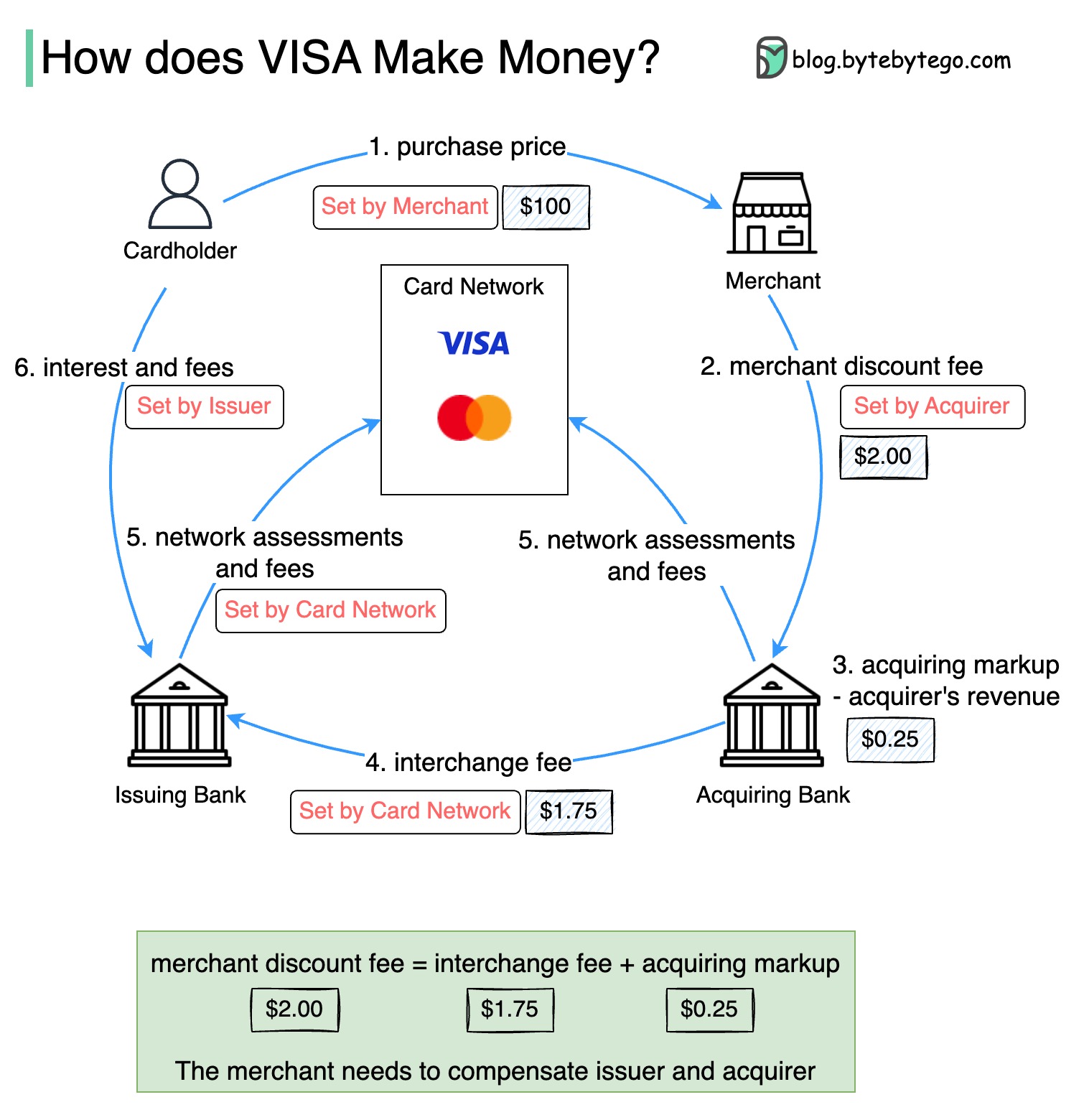
1. Владелец карты платит продавцу 100 долларов за покупку продукта.
2. Торговый средство выгоды от использования кредитной карты с более высоким объемом продаж и необходимы для компенсации эмитенту и карточной сети для предоставления платежной услуги. Банк приобретает плату с продавцом, названный «Плата за скидку продавца».
3 - 4. Банк -приобретающий удерживает 0,25 долл. США в качестве наценки приобретения, а 1,75 долл. США выплачивается Банку -эмитенте в качестве платы за размен. Плата за скидку продавца должна покрыть плату за обмен.
Плата за обмен установлена карточной сетью, поскольку для каждого банка -эмитента он является менее эффективным договориться о плате с каждым продавцом.
5. Карточная сеть устанавливает оценки сети и сборы с каждым банком, который каждый месяц платит карточной сети за свои услуги. Например, виза взимает 0,11% оценку, плюс плата за использование в размере 0,0195 долл. США за каждый удар.
6. Владелец карты платит банку эмитента за свои услуги.
Почему Банк -эмитент должен быть компенсирован?
Visa, MasterCard и American Express Acte Action как карточные сети для очистки и поселения средств. Банк, приобретающий карту, и банк эмитентов карт могут быть - и часто - разные. Если бы банки будут урегулировать транзакции один за другим без посредника, каждый банк должен был бы урегулировать транзакции со всеми другими банками. Это довольно неэффективно.
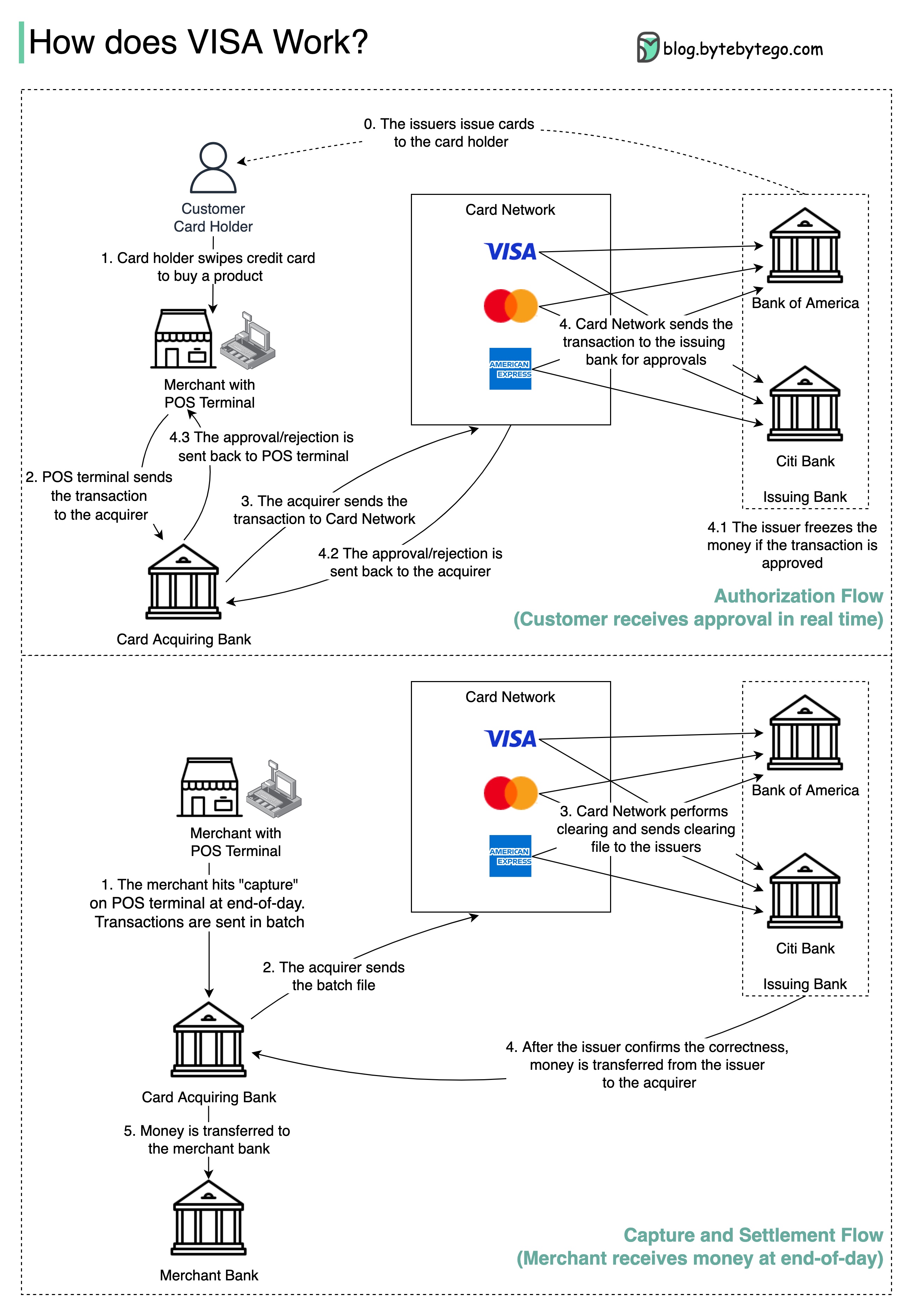
На приведенной ниже диаграмме показана роль Visa в процессе оплаты кредитной карты. Есть два потока. Поток авторизации происходит, когда клиент смахивает кредитную карту. Поток захвата и урегулирования происходит, когда торговец хочет получить деньги в конце дня.
Шаг 0: Банк -эмитент карт выпускает кредитные карты своим клиентам.
Шаг 1: Владелец карты хочет купить продукт и пропустить кредитную карту на терминале точки продажи (POS) в магазине торговца.
Шаг 2: POS -терминал отправляет транзакцию в банк приобретения, который предоставил POS -терминал.
Шаги 3 и 4: Банк приобретения отправляет транзакцию в сеть карт, также называемую схемой карт. Card Network отправляет транзакцию в банк эмитентов для утверждения.
Шаги 4.1, 4.2 и 4.3: Банк -эмитент замораживает деньги, если транзакция одобрена. Утверждение или отказ отправляются обратно в приобретатель, а также терминал POS.
Шаги 1 и 2: торговец хочет собрать деньги в конце дня, поэтому он ударил «захват» на терминале POS. Транзакции отправляются приобретателю в партии. Приобретатель отправляет пакетный файл с транзакциями в сеть карт.
Шаг 3: Карточная сеть выполняет клиринговую передачу для транзакций, собранных от разных приобретателей, и отправляет файлы очистки в различные банки эмитентов.
Шаг 4: Банки -эмитенты подтверждают правильность очистки и передают деньги соответствующим приобретающим банкам.
Шаг 5: Приобретающий банк затем передает деньги в банк торговцев.
Шаг 4: Карточная сеть очищает транзакции из разных банков приобретения. Очистка - это процесс, в котором транзакции взаимного смещения встраиваются, поэтому количество общих транзакций уменьшается.
В процессе карт сеть берет на себя бремя разговора с каждым банком и получает плату за обслуживание взамен.
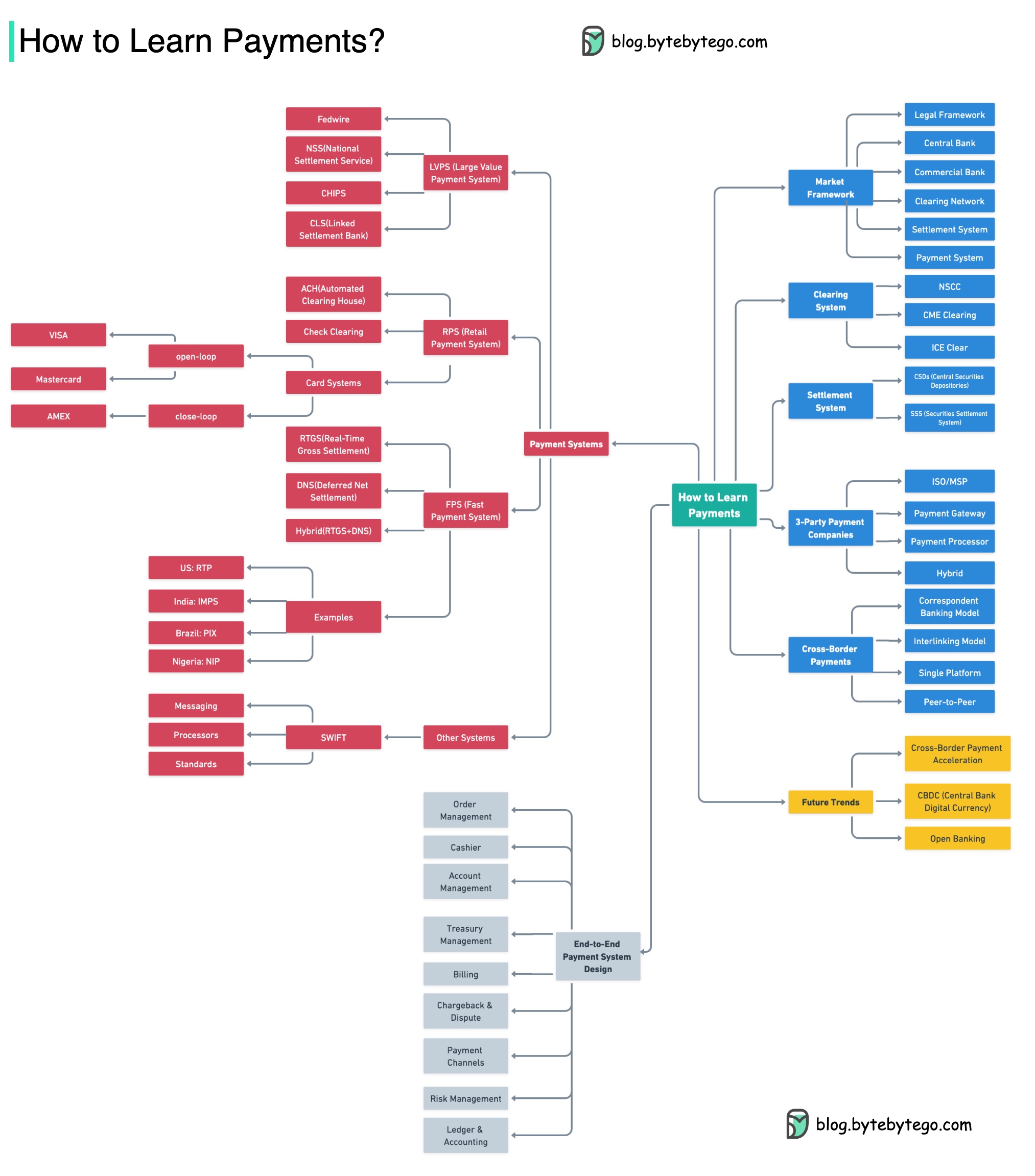
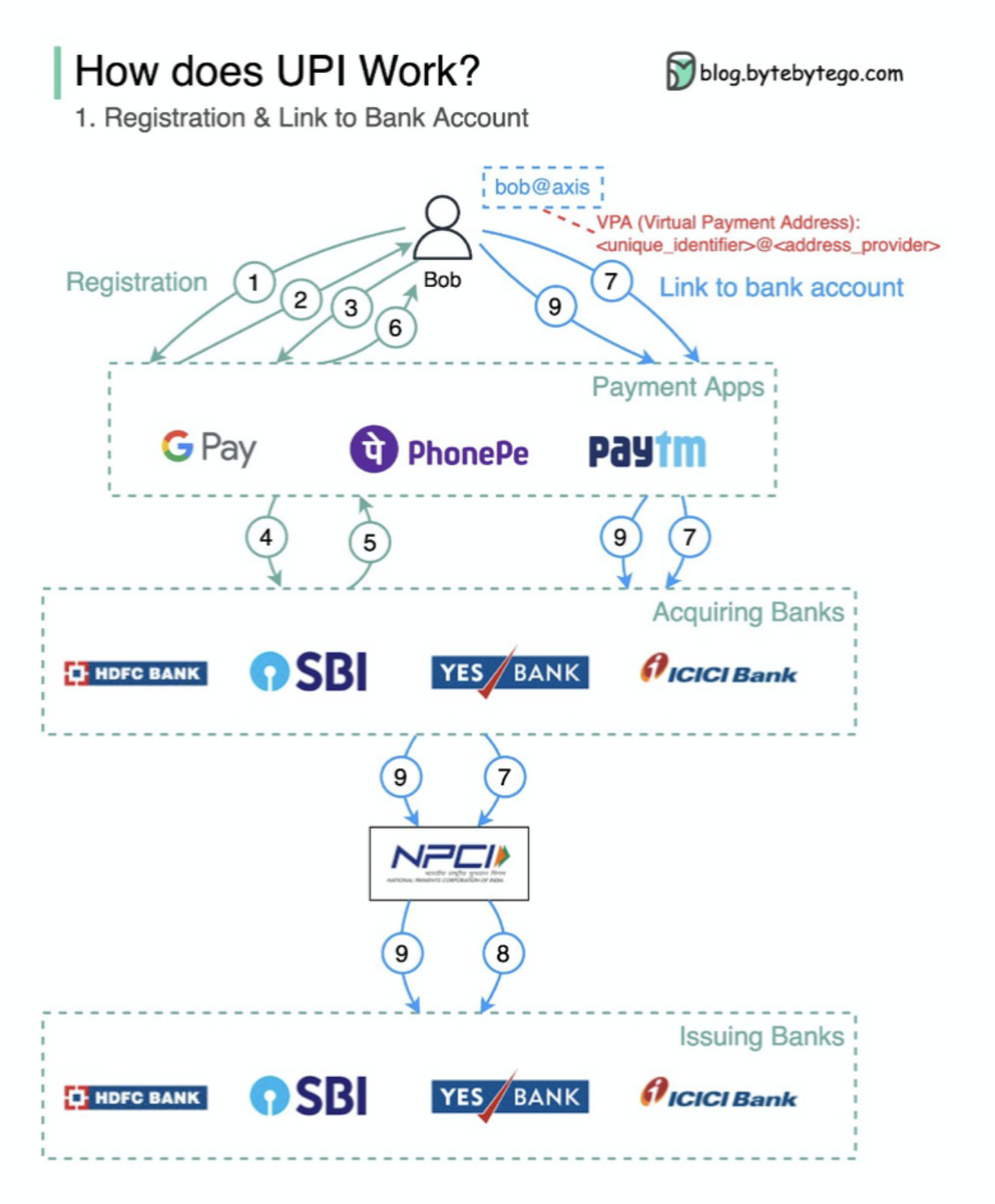
Что такое UPI? UPI-это мгновенная платежная система в реальном времени, разработанная Национальной платежной корпорацией Индии.
Сегодня на него приходится 60% цифровых розничных транзакций в Индии.
UPI = язык разметки платежей + стандарт для совместимых платежей
Концепции DevOps, SRE и Platform Engineering появились в разное время и были разработаны различными людьми и организациями.
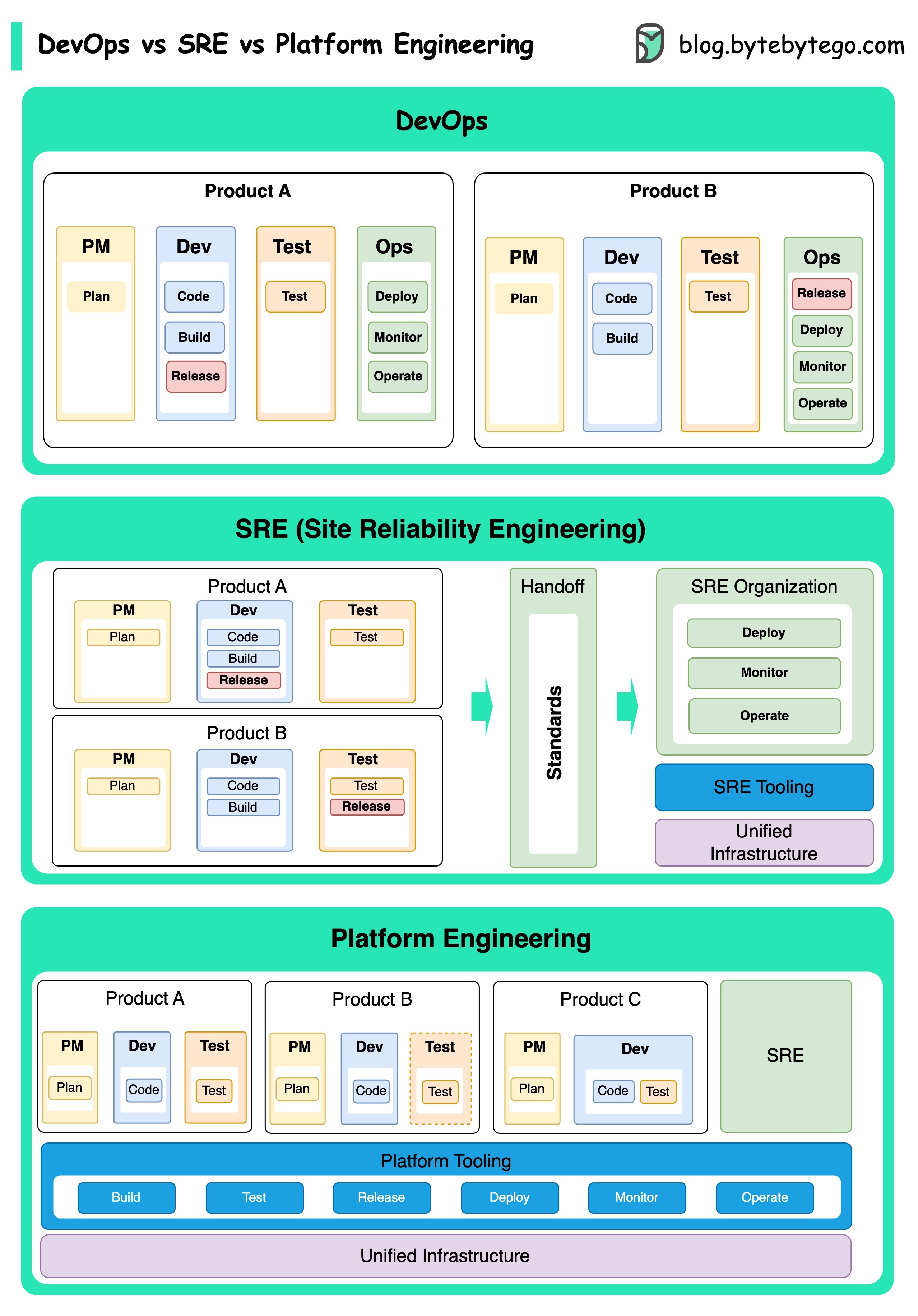
DevOps как концепция была представлена в 2009 году Патриком Дебусом и Эндрю Шафером на Agile Conference. Они стремились преодолеть разрыв между разработкой программного обеспечения и операциями, продвигая совместную культуру и общую ответственность за весь жизненный цикл разработки программного обеспечения.
SRE, или инженерия по надежности сайта, в начале 2000-х годов был впервые привлечен к решению оперативных проблем при управлении крупномасштабными сложными системами. Google разработал практики и инструменты SRE, такие как система управления кластером Borg и система мониторинга монарха, для повышения надежности и эффективности их услуг.
Платформа Engineering - более недавняя концепция, основанная на основе SRE Engineering. Точное происхождение инженерии платформы менее четко, но, как правило, это считается расширением практик DevOps и SRE, с акцентом на предоставление комплексной платформы для разработки продукта, которая поддерживает всю перспективу бизнеса.
Стоит отметить, что в то время как эти концепции появлялись в разное время. Все они связаны с более широкой тенденцией улучшения сотрудничества, автоматизации и эффективности разработки и операций программного обеспечения.
K8S - это система оркестровки контейнера. Он используется для развертывания контейнеров и управления ими. На его дизайн во многом повлияла внутренняя система Google Borg.
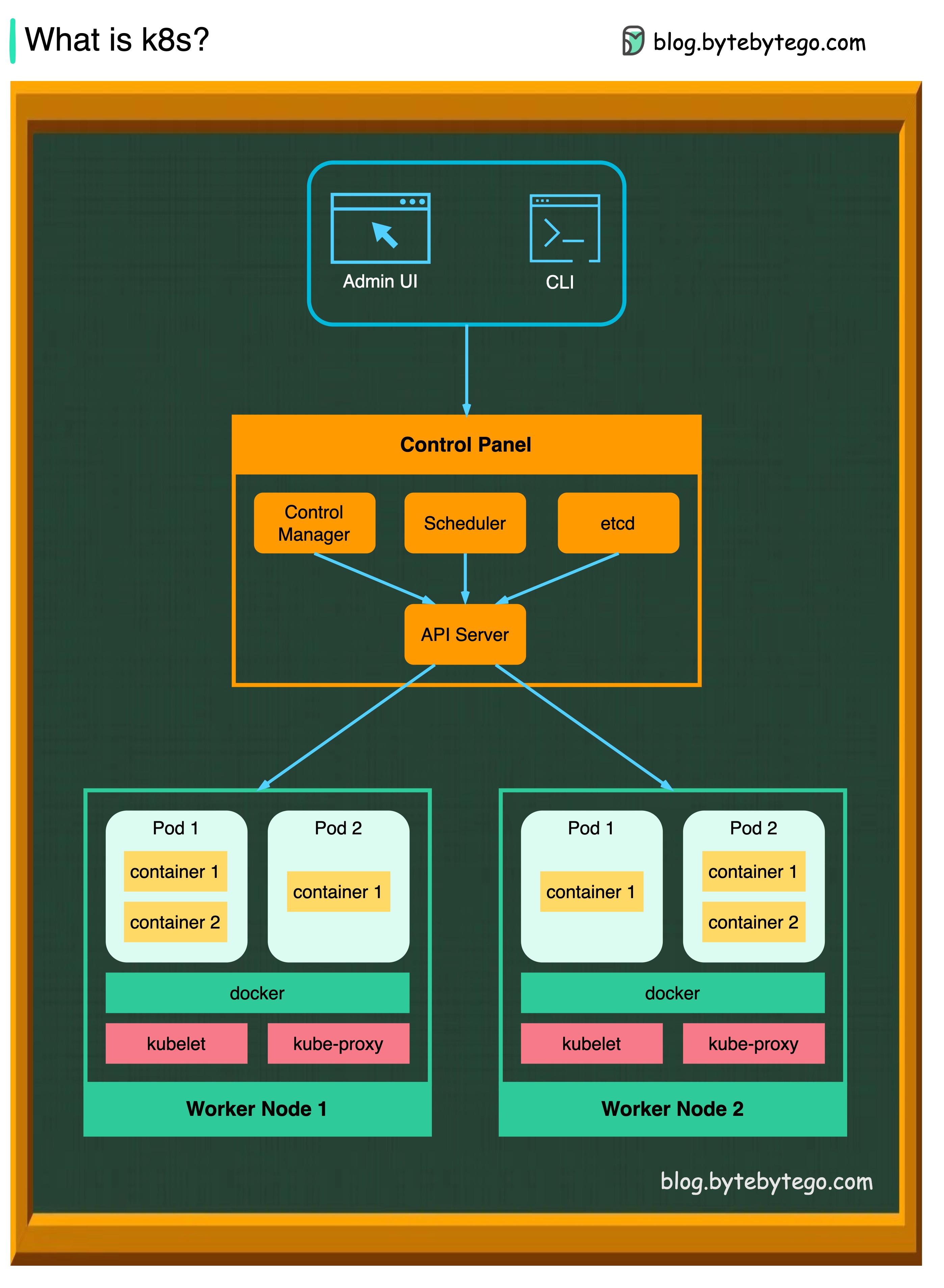
Кластер K8S состоит из набора рабочих машин, называемых узлами, которые запускают контейнерные приложения. У каждого кластера есть хотя бы один рабочий узел.
Узел работников проводит стручки, которые являются компонентами рабочей нагрузки приложения. Плона управления управляет рабочими узлами и стручками в кластере. В производственных средах плоскость управления обычно работает по нескольким компьютерам, а кластер обычно запускает несколько узлов, обеспечивая устойчивость к разлому и высокую доступность.
API -сервер
Сервер API общается со всеми компонентами в кластере K8S. Все операции на стручках выполняются путем разговора с сервером API.
Планировщик
Планировщик наблюдает за рабочими нагрузками POD и назначает нагрузки на недавно созданные капсулы.
Менеджер контроллера
Диспетчер контроллеров запускает контроллеры, включая контроллер узлов, контроллер задания, контроллер Endpointslice и контроллер ServiceAccount.
И т.д.
ETCD-это хранилище ключа, используемое в качестве хранилища поддержки Kubernetes для всех данных кластера.
Стручки
POD - это группа контейнеров и является наименьшей единицей, которую управляет K8S. Стручки имеют один IP -адрес, применяемый к каждому контейнеру в капсуле.
Кубелет
Агент, который работает на каждом узле в кластере. Это гарантирует, что контейнеры работают в стручке.
Kube Proxy
Kube-Proxy-это сетевой прокси, который работает на каждом узле в вашем кластере. Он направляет трафик, поступающий в узел из службы. Он пересылает запросы на работу в правильные контейнеры.

Что такое Docker?
Docker-это платформа с открытым исходным кодом, которая позволяет упаковать, распространять и запускать приложения в изолированных контейнерах. Он фокусируется на контейнеризации, предоставляя легкие среды, которые инкапсулируют приложения и их зависимости.
Что такое kubernetes?
Kubernetes, часто называемые K8S, представляет собой платформу для оркестровки с открытым исходным кодом. Он обеспечивает основу для автоматизации развертывания, масштабирования и управления контейнерными приложениями в кластере узлов.
Чем отличаются друг от друга?
Docker: Docker работает на индивидуальном уровне контейнера на одном хосте операционной системы.
Вы должны вручную управлять каждым хостом и настройка сетей, политик безопасности и хранения для нескольких связанных контейнеров, может быть сложной.
Kubernetes: Kubernetes работает на уровне кластера. Он управляет несколькими контейнерными приложениями на нескольких хостах, обеспечивая автоматизацию для таких задач, как баланс нагрузки, масштабирование и обеспечение желаемого состояния приложений.
Короче говоря, Docker фокусируется на контейнеризации и запуска контейнеров на отдельных хостах, в то время как Kubernetes специализируется на управлении и оркестровании контейнеров в масштабе через кластер хостов.
На диаграмме ниже показана архитектура Docker и то, как она работает, когда мы запускаем «Docker Build», «Docker Pull» и «Docker Run».
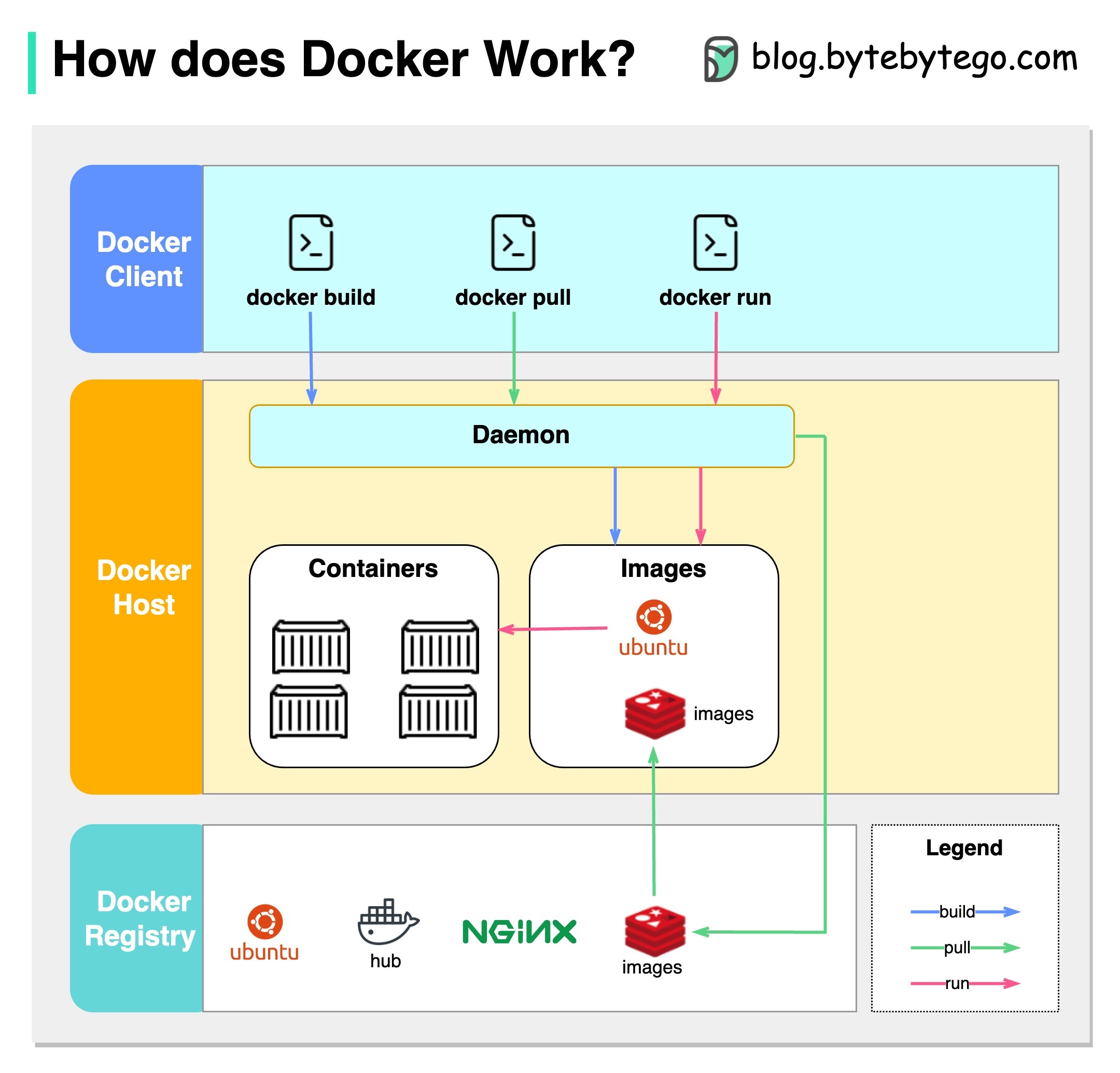
В архитектуре Docker есть 3 компонента:
Docker Client
Клиент Docker разговаривает с Docker Daemon.
Докер -хозяин
Docker Daemon прослушивает запросы Docker API и управляет объектами Docker, такими как изображения, контейнеры, сети и объемы.
Docker Registry
Реестр Docker хранит изображения Docker. Docker Hub - это общественный реестр, который может использовать каждый.
Давайте возьмем команду «Docker Run» в качестве примера.
Начнем с того, что важно определить, где хранится наш код. Распространенным предположением является то, что есть только два места - одно на удаленном сервере, таком как GitHub, а другой на нашей локальной машине. Однако это не совсем точно. GIT поддерживает три локальных стерала на нашей машине, что означает, что наш код можно найти в четырех местах:
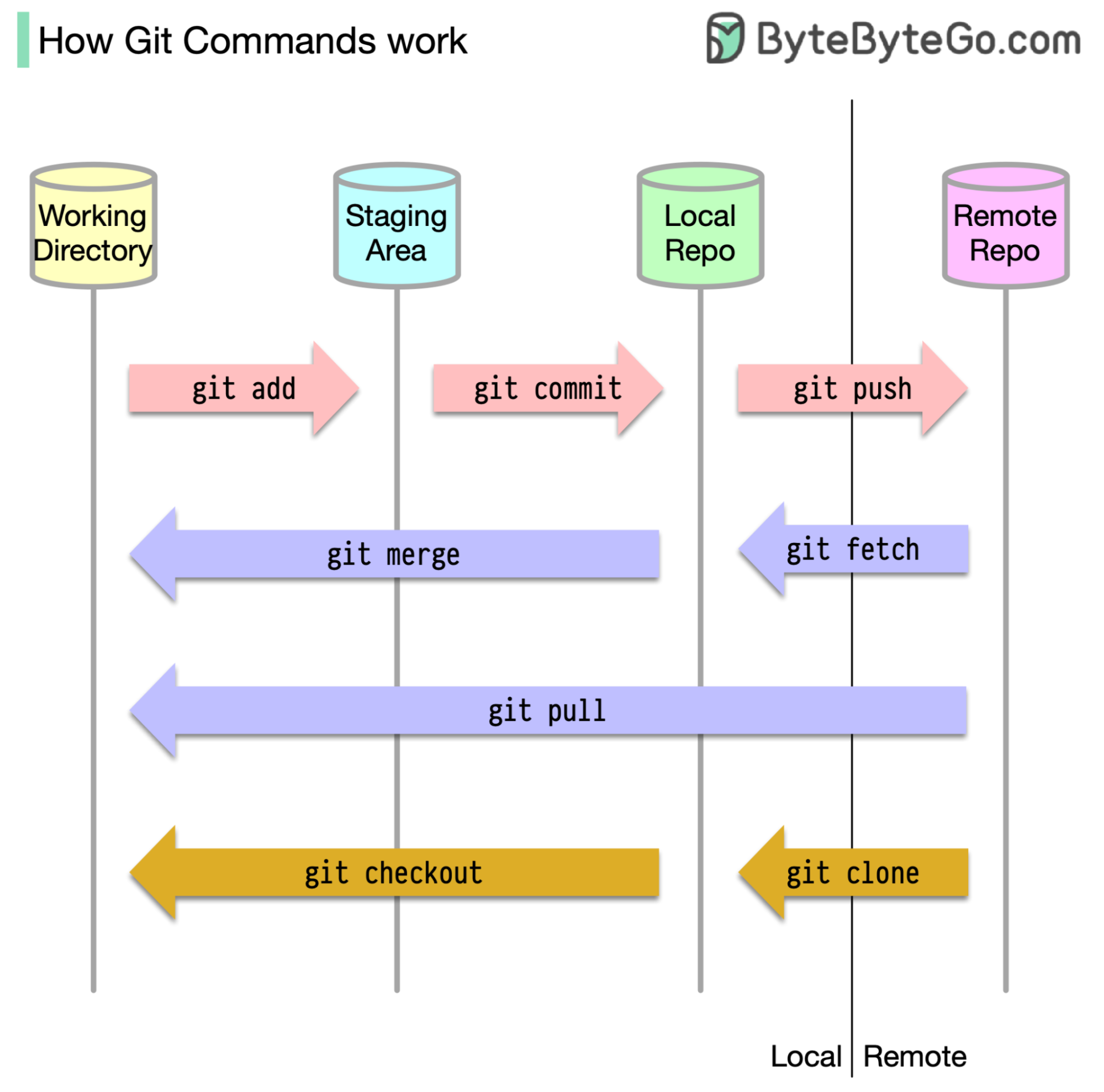
Большинство команд GIT в основном перемещают файлы между этими четырьмя местами.
Диаграмма ниже показывает рабочий процесс GIT.
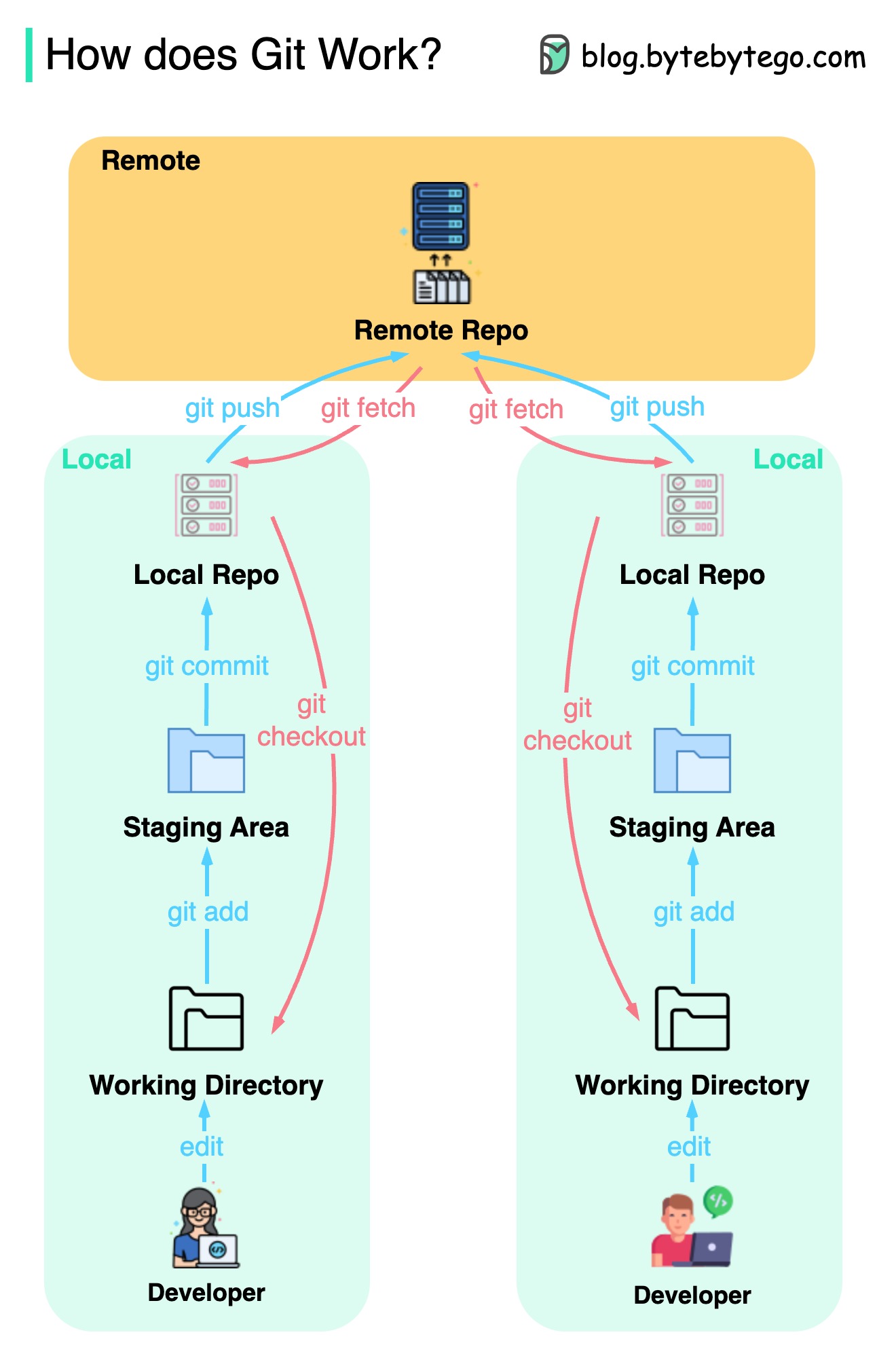
GIT - это система управления распределенной версией.
Каждый разработчик сохраняет локальную копию основного репозитория и редактирует и отправляется в локальную копию.
Коммит очень быстрый, потому что операция не взаимодействует с удаленным репозиторием.
Если удаленный репозиторий вылетает, файлы могут быть восстановлены из локальных репозитории.
В чем различия?


