MagicMix
1.0.0
Статья «Внедрение MagicMix: семантическое смешивание с моделями диффузии».
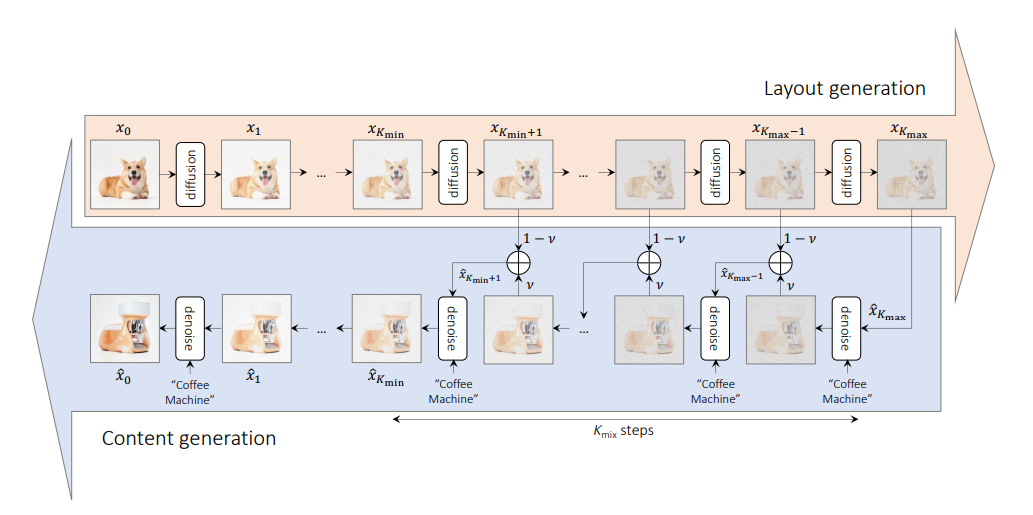
Целью метода является семантическое смешивание двух разных концепций для синтеза новой концепции, сохраняя при этом пространственную компоновку и геометрию.
Метод принимает изображение, предоставляющее семантику макета, и приглашение, предоставляющее семантику контента для процесса микширования.
У метода есть 3 параметра:
v : это константа интерполяции, используемая на этапе создания макета. Чем больше значение v, тем больше влияние подсказки на процесс создания макета.kmax и kmin : определяют диапазон макета и процесса генерации контента. Более высокое значение kmax приводит к потере большего количества информации о макете исходного изображения, а более высокое значение kmin приводит к увеличению количества шагов в процессе генерации контента. from PIL import Image
from magic_mix import magic_mix
img = Image . open ( 'phone.jpg' )
out_img = magic_mix ( img , 'bed' , kmax = 0.5 )
out_img . save ( "mix.jpg" ) python3 magic_mix.py
"phone.jpg"
"bed"
"mix.jpg"
--kmin 0.3
--kmax 0.6
--v 0.5
--steps 50
--seed 42
--guidance_scale 7.5
Кроме того, ознакомьтесь с демонстрационным блокнотом, где можно увидеть примеры использования реализации, чтобы воспроизвести примеры из статьи.
Вы также можете использовать конвейер сообщества в библиотеке диффузоров.
from diffusers import DiffusionPipeline , DDIMScheduler
from PIL import Image
pipe = DiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
custom_pipeline = "magic_mix" ,
scheduler = DDIMScheduler . from_pretrained ( "CompVis/stable-diffusion-v1-4" , subfolder = "scheduler" ),
). to ( 'cuda' )
img = Image . open ( 'phone.jpg' )
mix_img = pipe (
img ,
prompt = 'bed' ,
kmin = 0.3 ,
kmax = 0.5 ,
mix_factor = 0.5 ,
)
mix_img . save ( 'mix.jpg' )







Я не автор статьи, и это не официальная реализация.


