meme search engine
1.0.0
У вас есть большая папка мемов, которую вы хотите выполнить семантический поиск? У вас есть сервер Linux с графическим процессором Nvidia? Вы делаете; теперь это обязательно.
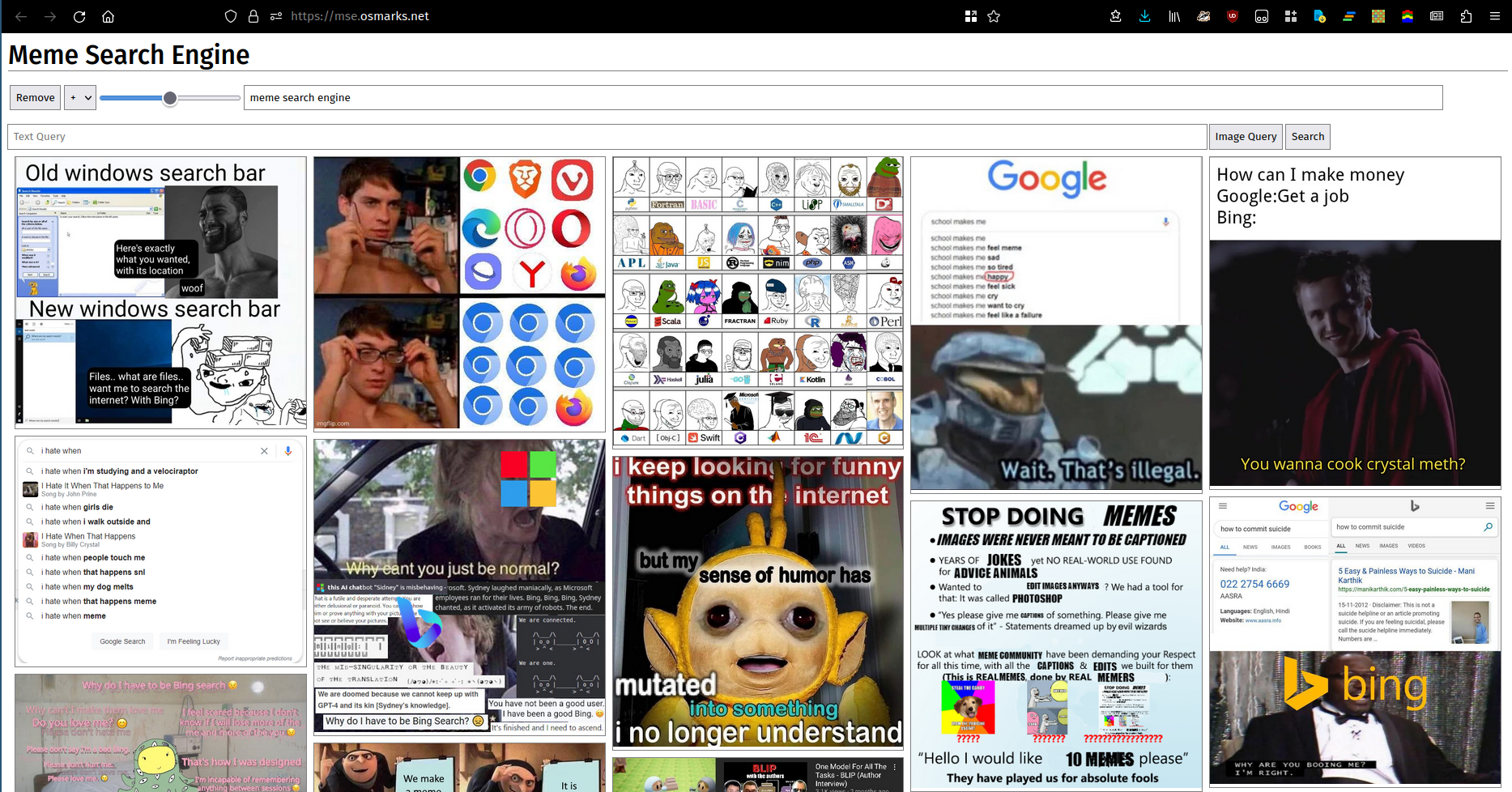
Говорят, картинка стоит тысячи слов. К сожалению, многие (большинство?) наборы слов не могут быть адекватно описаны картинками. Несмотря ни на что, вот картинка. Здесь вы можете использовать работающий экземпляр.
Это непроверено. Это может сработать. Новая версия Rust упрощает некоторые шаги (встроена собственная миниатюра).
python -m http.server .pip из requirements.txt (версии, вероятно, не должны точно совпадать, если вам нужно их изменить; я просто вставил то, что у меня сейчас установлено).transformers из-за поддержки SigLIP.thumbnailer.py (периодически, в идеале одновременно с перезагрузкой индекса)clip_server.py (в качестве фоновой службы).clip_server_config.json .device вероятно, должно быть cuda или cpu . Модель будет работать здесь.modelmodel_name — это имя модели для целей метрики.max_batch_size контролирует максимально допустимый размер пакета. Более высокие значения обычно приводят к несколько лучшей производительности (хотя в большинстве случаев узкое место сейчас находится в другом месте) за счет более высокого использования видеопамяти.port — это порт для запуска HTTP-сервера.meme-search-engine (Rust) (также в качестве фоновой службы).clip_server — это полный URL-адрес внутреннего сервера.db_path — это путь к базе данных SQLite изображений и векторов внедрения.files — это место, откуда будут считываться файлы мемов. Подкаталоги индексируются.port — это порт для обслуживания HTTP.enable_thumbs значение true , чтобы предоставлять сжатые изображения.npm install , node src/build.js .frontend_config.json .image_path — это базовый URL-адрес вашего веб-сервера мемов (с косой чертой в конце).backend_url — это URL-адрес, по которому отображается mse.py (конечная косая черта, возможно, необязательна).clip_server.py . Здесь вы найдете информацию о MemeThresher, новой автоматической системе получения/рейтинга мемов (в разделе meme-rater ). Ожидается, что развертывание его самостоятельно будет несколько сложным, но это примерно выполнимо:
crawler.py , указав свой собственный источник, и запустите его, чтобы собрать исходный набор данных.mse.py с файлом конфигурации, подобным предоставленному, чтобы проиндексировать его.rater_server.py для сбора исходного набора данных пар.train.py для обучения модели. Возможно, вам придется настроить гиперпараметры, поскольку я понятия не имею, какие из них хороши.active_learning.py на лучшей доступной контрольной точке, чтобы получить новые пары для оценки.copy_into_queue.py , чтобы скопировать новые пары в rater_server.py .library_processing_server.py и запланируйте периодический запуск meme_pipeline.py . Поисковая система мемов использует индекс FAISS в памяти для хранения векторов внедрения, потому что я был ленив, и она работает нормально (общая оперативная память ~ 100 МБ используется для моих 8000 мемов). Если вы хотите хранить значительно больше данных, вам придется переключиться на более эффективный/компактный индекс (см. здесь). Поскольку векторные индексы хранятся исключительно в памяти, вам нужно будет либо сохранить их на диске, либо использовать те, которые можно быстро создавать/удалять/добавлять (предположительно индексы PCA/PQ). В какой-то момент, если вы увеличите общий трафик, модель CLIP также может стать узким местом, поскольку у меня также нет стратегии пакетной обработки. Индексирование в настоящее время привязано к графическому процессору, поскольку новая модель работает несколько медленнее при больших размерах пакетов, и я улучшил конвейер загрузки изображений. Вы также можете уменьшить масштаб отображаемых мемов, чтобы сократить потребность в пропускной способности.


