dsub
Release 0.5.0
dsub — это инструмент командной строки, который позволяет легко отправлять и запускать пакетные сценарии в облаке.
Пользовательский интерфейс dsub смоделирован по образцу традиционных планировщиков заданий высокопроизводительных вычислений, таких как Grid Engine и Slurm. Вы пишете сценарий, а затем отправляете его планировщику заданий из командной строки на локальном компьютере.
Сегодня dsub поддерживает Google Cloud в качестве серверного средства выполнения пакетных заданий, а также местного поставщика услуг по разработке и тестированию. С помощью сообщества мы хотели бы добавить другие серверные части, такие как Grid Engine, Slurm, Amazon Batch и Azure Batch.
dsub написан на Python и требует Python 3.7 или выше.
dsub 0.4.7.dsub 0.4.1.dsub 0.3.10.Это необязательно, но независимо от того, устанавливаете ли вы из PyPI или из github, вам настоятельно рекомендуется использовать виртуальную среду Python.
Вы можете сделать это в каталоге по вашему выбору.
python3 -m venv dsub_libs
source dsub_libs/bin/activate
Использование виртуальной среды Python изолирует зависимости библиотеки dsub от других приложений Python в вашей системе.
Активируйте эту виртуальную среду в любом сеансе оболочки перед запуском dsub . Чтобы деактивировать виртуальную среду в вашей оболочке, выполните команду:
deactivate
В качестве альтернативы предоставляется набор удобных сценариев, которые активируют virutalenv перед вызовом dsub , dstat и ddel . Они находятся в каталоге bin. Вы можете использовать эти сценарии, если не хотите явно активировать virtualenv в своей оболочке.
Хотя dsub не используется напрямую для поставщиков google-batch или google-cls-v2 , вы, скорее всего, захотите установить инструменты командной строки, находящиеся в Google Cloud SDK.
Если вы будете использовать local поставщика для более быстрой разработки заданий, вам потребуется установить Google Cloud SDK, который использует gsutil для обеспечения соответствия семантики операций с файлами поставщикам Google dsub .
Установите Google Cloud SDK.
Бегать
gcloud init
gcloud предложит вам установить проект по умолчанию и предоставить учетные данные для Google Cloud SDK.
dsubВыберите один из следующих вариантов:
При необходимости установите pip.
Установить dsub
pip install dsub
Убедитесь, что у вас установлен git
Инструкции для вашей среды можно найти на веб-сайте git.
Клонируйте этот репозиторий.
git clone https://github.com/DataBiosphere/dsub
cd dsub
Установите dsub (при этом также будут установлены зависимости)
python -m pip install .
Настройте завершение табуляции Bash (необязательно).
source bash_tab_complete
Минимально проверьте установку, выполнив:
dsub --help
(Необязательно) Установите Docker.
Это необходимо только в том случае, если вы собираетесь создавать собственные образы Docker или использовать local провайдера.
После клонирования репозитория dsub вы также можете использовать Makefile, запустив:
make
Это создаст виртуальную среду Python и установит dsub в каталог с именем dsub_libs .
Мы думаем, что local провайдер будет вам очень полезен при построении задач dsub . Вместо отправки запроса на запуск вашей команды на облачной виртуальной машине local провайдер запускает ваши задачи dsub на вашем локальном компьютере.
local поставщик не предназначен для работы в большом масштабе. Он предназначен для эмуляции работы на облачной виртуальной машине, чтобы вы могли быстро выполнять итерации. При его использовании вы ускорите выполнение работ и не будете нести расходы на использование облака.
Запустите задание dsub и дождитесь завершения.
Вот очень простой тест «Hello World»:
dsub
--provider local
--logging "${TMPDIR:-/tmp}/dsub-test/logging/"
--output OUT="${TMPDIR:-/tmp}/dsub-test/output/out.txt"
--command 'echo "Hello World" > "${OUT}"'
--wait
Примечание. В большинстве систем Unix по умолчанию для TMPDIR обычно установлено значение /tmp , хотя его также часто не устанавливают. В некоторых версиях MacOS TMPDIR установлен в папку /var/folders .
Примечание. Известно, что приведенный выше синтаксис ${TMPDIR:-/tmp} поддерживается Bash, zsh, ksh. Оболочка расширит TMPDIR , но если он не установлен, будет использоваться /tmp .
Просмотрите выходной файл.
cat "${TMPDIR:-/tmp}/dsub-test/output/out.txt"
В настоящее время dsub поддерживает API Cloud Life Sciences v2beta от Google Cloud и разрабатывает поддержку Batch API от Google Cloud.
dsub поддерживает API v2beta с провайдером google-cls-v2 . google-cls-v2 является текущим поставщиком по умолчанию. dsub будет переходить к использованию google-batch по умолчанию в следующих выпусках.
Шаги по началу работы немного отличаются, как указано в шагах ниже:
Зарегистрируйте аккаунт Google и создайте проект.
Включите API:
v2beta (поставщик: google-cls-v2 ):Включите облачные API-интерфейсы медико-биологических наук, хранилищ и вычислений.
batch API (поставщик: google-batch ):Включите API пакетной обработки, хранения и вычислений.
Укажите учетные данные, чтобы dsub мог вызывать API Google:
gcloud auth application-default login
Создайте корзину Google Cloud Storage.
Журналы dsub и выходные файлы будут записаны в корзину. Создайте корзину с помощью браузера хранилища или запустите утилиту командной строки gsutil, включенную в Cloud SDK.
gsutil mb gs://my-bucket
Измените my-bucket на уникальное имя, соответствующее соглашениям об именах сегментов.
(По умолчанию корзина будет находиться в США, но вы можете изменить или уточнить настройку местоположения с помощью опции -l .)
Запустите очень простое задание dsub «Hello World» и дождитесь завершения.
Для API v2beta (поставщик: google-cls-v2 ):
dsub
--provider google-cls-v2
--project my-cloud-project
--regions us-central1
--logging gs://my-bucket/logging/
--output OUT=gs://my-bucket/output/out.txt
--command 'echo "Hello World" > "${OUT}"'
--wait
Измените my-cloud-project на свой проект Google Cloud, а my-bucket — на корзину, которую вы создали выше.
Для batch API (поставщик: google-batch ):
dsub
--provider google-batch
--project my-cloud-project
--regions us-central1
--logging gs://my-bucket/logging/
--output OUT=gs://my-bucket/output/out.txt
--command 'echo "Hello World" > "${OUT}"'
--wait
Измените my-cloud-project на свой проект Google Cloud, а my-bucket — на корзину, которую вы создали выше.
Вывод команды сценария будет записан в указанный вами файл OUT в облачном хранилище.
Просмотрите выходной файл.
gsutil cat gs://my-bucket/output/out.txt
Там, где это возможно, dsub пытается предоставить пользователям возможность разрабатывать и тестировать локально (для более быстрой итерации), а затем переходить к масштабированию.
С этой целью dsub предоставляет несколько «бэкэнд-провайдеров», каждый из которых реализует согласованную среду выполнения. Текущие поставщики:
Более подробную информацию о среде выполнения, реализованной поставщиками серверных частей, можно найти в разделе поставщиков серверных частей dsub.
google-cls-v2 и google-batch Поставщик google-cls-v2 создан на основе API Cloud Life Sciences v2beta . Этот API очень похож на своего предшественника — API Genomics v2alpha1 . Подробную информацию о различиях можно найти в Руководстве по миграции.
Поставщик google-batch создан на основе API Cloud Batch. Подробную информацию об облачных медико-биологических науках и пакетной обработке можно найти в этом руководстве по миграции.
dsub в значительной степени скрывает различия между API, но есть несколько отличий, на которые следует обратить внимание:
google-batch требует, чтобы задания выполнялись в одном регионе Флаги --regions и --zones для dsub указывают, где должны выполняться задачи. google-cls-v2 позволяет указать несколько регионов, например US , несколько регионов или несколько зон в разных регионах. При использовании поставщика google-batch вы должны указать либо один регион, либо несколько зон в одном регионе.
dsubВ следующих разделах показано, как выполнять более сложные задания.
Вы можете указать команду оболочки непосредственно в командной строке dsub, как в примере hello выше.
Вы также можете сохранить свой скрипт в файл, например hello.sh . Затем вы можете запустить:
dsub
...
--script hello.sh
Если в вашем скрипте есть зависимости, которые не хранятся в вашем образе Docker, вы можете перенести их на локальный диск. См. инструкции ниже по работе с входными и выходными файлами и папками.
Чтобы упростить работу, dsub использует стандартный образ Ubuntu Docker. Это изображение по умолчанию может измениться в любое время в будущих выпусках, поэтому для воспроизводимых производственных рабочих процессов всегда следует явно указывать изображение.
Вы можете изменить изображение, передав флаг --image .
dsub
...
--image ubuntu:16.04
--script hello.sh
Примечание: ваш --image должен включать интерпретатор оболочки Bash.
Дополнительную информацию об использовании флага --image см. в разделе изображений в разделе «Сценарии, команды и Docker».
Вы можете передать переменные среды в свой скрипт, используя флаг --env .
dsub
...
--env MESSAGE=hello
--command 'echo ${MESSAGE}'
Переменной среды MESSAGE будет присвоено значение hello при запуске вашего контейнера Docker.
Ваш скрипт или команда могут ссылаться на эту переменную, как и на любую другую переменную среды Linux, например ${MESSAGE} .
Обязательно заключайте командную строку в одинарные, а не в двойные кавычки. Если вы используете двойные кавычки, команда будет расширена в вашей локальной оболочке перед передачей в dsub. Дополнительную информацию об использовании флага --command см. в разделе Скрипты, команды и Docker.
Чтобы установить несколько переменных среды, вы можете повторить флаг:
--env VAR1=value1
--env VAR2=value2
Вы также можете установить несколько переменных, разделенных пробелами, с помощью одного флага:
--env VAR1=value1 VAR2=value2
dsub имитирует поведение общей файловой системы, используя пути к сегментам облачного хранилища для входных и выходных файлов и папок. Вы указываете путь к сегменту облачного хранилища. Пути могут быть:
gs://my-bucket/my-filegs://my-bucket/my-foldergs://my-bucket/my-folder/*Более подробную информацию смотрите в документации по входам и выходам.
Если ваш скрипт предполагает читать локальные входные файлы, которые еще не содержатся в вашем образе Docker, эти файлы должны быть доступны в Google Cloud Storage.
Если у вашего скрипта есть зависимые файлы, вы можете сделать их доступными для вашего скрипта следующим образом:
Чтобы загрузить файлы в Google Cloud Storage, вы можете использовать браузер хранилища или gsutil. Вы также можете использовать общедоступные данные или данные, которыми поделились с вашей учетной записью службы, адрес электронной почты, который вы можете найти в Google Cloud Console.
Чтобы указать входные и выходные файлы, используйте флаги --input и --output :
dsub
...
--input INPUT_FILE_1=gs://my-bucket/my-input-file-1
--input INPUT_FILE_2=gs://my-bucket/my-input-file-2
--output OUTPUT_FILE=gs://my-bucket/my-output-file
--command 'cat "${INPUT_FILE_1}" "${INPUT_FILE_2}" > "${OUTPUT_FILE}"'
В этом примере:
gs://my-bucket/my-input-file-1 в путь на диске с данными${INPUT_FILE_1}gs://my-bucket/my-input-file-2 в путь на диске с данными${INPUT_FILE_2} Команда --command может ссылаться на пути к файлам, используя переменные среды.
Также в этом примере:
${OUTPUT_FILE}${OUTPUT_FILE} После завершения --command выходной файл будет скопирован в путь к корзине gs://my-bucket/my-output-file
Можно указать несколько параметров --input и --output , и их можно указывать в любом порядке.
Чтобы копировать папки, а не файлы, используйте флаги --input-recursive и output-recursive :
dsub
...
--input-recursive FOLDER=gs://my-bucket/my-folder
--command 'find ${FOLDER} -name "foo*"'
Можно указать несколько параметров --input-recursive и --output-recursive , и их можно указывать в любом порядке.
Хотя явное указание входных данных улучшает отслеживание происхождения ваших данных, в некоторых случаях вы можете не захотеть явно локализовать все входные данные из облачного хранилища на виртуальной машине вашего задания.
Например, если у вас есть:
ИЛИ
ИЛИ
тогда вам может оказаться более эффективным и удобным доступ к этим данным, установив режим «только для чтения»:
Поставщики google-cls-v2 и google-batch поддерживают эти методы предоставления доступа к данным ресурсов.
local провайдер поддерживает монтирование локального каталога аналогичным образом для поддержки вашей локальной разработки.
Чтобы поставщик google-cls-v2 или google-batch смонтировал корзину Cloud Storage с помощью Cloud Storage FUSE, используйте флаг командной строки --mount :
--mount RESOURCES=gs://mybucket
Бакет будет смонтирован только для чтения в контейнере Docker, выполняющем вашу --script или --command , а местоположение будет доступно через переменную среды ${RESOURCES} . Внутри вашего скрипта вы можете ссылаться на смонтированный путь, используя переменную среды. Прежде чем использовать Cloud Storage FUSE, прочтите «Ключевые отличия от файловой системы POSIX и семантику».
Чтобы провайдер google-cls-v2 или google-batch смонтировал постоянный диск, который вы предварительно создали и заполнили, используйте флаг командной строки --mount и URL-адрес исходного диска:
--mount RESOURCES="https://www.googleapis.com/compute/v1/projects/your-project/zones/your_disk_zone/disks/your-disk"
Чтобы поставщик google-cls-v2 или google-batch смонтировал постоянный диск, созданный из образа, используйте флаг командной строки --mount , URL-адрес исходного образа и размер (в ГБ) диска:
--mount RESOURCES="https://www.googleapis.com/compute/v1/projects/your-project/global/images/your-image 50"
Образ будет использоваться для создания нового постоянного диска, который будет подключен к виртуальной машине Compute Engine. Диск будет подключен к контейнеру Docker с помощью вашей --script или --command , а местоположение будет доступно с помощью переменной среды ${RESOURCES} . Внутри вашего скрипта вы можете ссылаться на смонтированный путь, используя переменную среды.
Чтобы создать изображение, см. Создание собственного изображения.
local провайдер) Чтобы local провайдер монтировал каталог только для чтения, используйте флаг командной строки --mount и префикс file:// :
--mount RESOURCES=file://path/to/my/dir
Локальный каталог будет смонтирован в контейнер Docker, выполняющий вашу --script или --command , а местоположение будет доступно через переменную среды ${RESOURCES} . Внутри вашего скрипта вы можете ссылаться на смонтированный путь, используя переменную среды.
Задачи dsub выполняемые с использованием local провайдера, будут использовать ресурсы, доступные на вашем локальном компьютере.
Задачи dsub , выполняемые с использованием поставщиков google-cls-v2 или google-batch , могут использовать преимущества широкого спектра параметров ЦП, ОЗУ, диска и аппаратного ускорителя (например, графического процессора).
Подробности см. в документации по вычислительным ресурсам.
По умолчанию dsub генерирует job-id в форме job-name--userid--timestamp , где job-name усекается до 10 символов, а timestamp имеет форму YYMMDD-HHMMSS-XX , уникальна с точностью до сотых долей секунды. . Если вы отправляете несколько заданий одновременно, вы все равно можете столкнуться с ситуациями, когда job-id не уникален. Если в этой ситуации вам требуется уникальный job-id , вы можете использовать параметр --unique-job-id .
Если установлен параметр --unique-job-id , job-id вместо этого будет уникальным 32-значным UUID, созданным https://docs.python.org/3/library/uuid.html. Поскольку некоторые провайдеры требуют, чтобы job-id начинался с буквы, dsub заменит любую начальную цифру буквой таким образом, чтобы сохранить уникальность.
Каждый из приведенных выше примеров демонстрирует отправку одной задачи с одним набором переменных, входных и выходных данных. Если у вас есть пакет входных данных и вы хотите выполнить над ними одну и ту же операцию, dsub позволяет вам создать пакетное задание.
Вместо многократного вызова dsub вы можете создать файл значений, разделенных табуляцией (TSV), содержащий переменные, входные и выходные данные для каждой задачи, а затем вызвать dsub один раз. Результатом будет один job-id с несколькими задачами. Задачи будут планироваться и выполняться независимо, но их можно будет отслеживать и удалять как группу.
Первая строка файла TSV определяет имена и типы параметров. Например:
--env SAMPLE_ID<tab>--input VCF_FILE<tab>--output OUTPUT_PATH
Каждая строка сложения в файле должна содержать переменные, входные и выходные значения для каждой задачи. Каждая строка после заголовка представляет значения для отдельной задачи.
Можно указать несколько параметров --env , --input и --output , и их можно указывать в любом порядке. Например:
--env SAMPLE<tab>--input A<tab>--input B<tab>--env REFNAME<tab>--output O
S1<tab>gs://path/A1.txt<tab>gs://path/B1.txt<tab>R1<tab>gs://path/O1.txt
S2<tab>gs://path/A2.txt<tab>gs://path/B2.txt<tab>R2<tab>gs://path/O2.txt
Передайте файл TSV в dsub, используя параметр --tasks . Этот параметр принимает как путь к файлу, так и, при необходимости, диапазон задач для обработки. Файл можно прочитать из локальной файловой системы (на компьютере, с которого вы вызываете dsub ) или из корзины в Google Cloud Storage (имя файла начинается с «gs://»).
Например, предположим, что my-tasks.tsv содержит 101 строку: однострочный заголовок и 100 строк параметров для запуска задач. Затем:
dsub ... --tasks ./my-tasks.tsv
создаст задание со 100 задачами, при этом:
dsub ... --tasks ./my-tasks.tsv 1-10
создаст задание с 10 задачами, по одному на каждую из строк со 2 по 11.
Значения диапазона задач могут принимать любую из следующих форм:
m указывает на отправку задачи m (строка m+1)m- указывает на отправку всех задач, начиная с задачи m .mn указывает на отправку всех задач от m до n (включительно). Флаг --logging указывает на расположение файлов журналов задач dsub . Подробную информацию о том, как указать путь ведения журнала, см. в разделе Ведение журнала.
Можно дождаться завершения задания, прежде чем начинать другое. Подробности см. в разделе Управление заданиями с помощью dsub.
dsub может автоматически повторять неудачные задачи. Подробности см. в разделе повторы с помощью dsub.
Вы можете добавлять к заданиям и задачам собственные метки, что позволяет отслеживать и отменять задачи, используя собственные идентификаторы. Кроме того, у поставщиков Google при маркировке задачи будут отмечаться связанные вычислительные ресурсы, такие как виртуальные машины и диски.
Дополнительные сведения см. в разделе «Проверка состояния и устранение неполадок заданий».
Команда dstat отображает статус заданий:
dstat --provider google-cls-v2 --project my-cloud-project
Без дополнительных аргументов dstat отобразит список запущенных заданий для текущего USER .
Чтобы отобразить статус конкретного задания, используйте флаг --jobs :
dstat --provider google-cls-v2 --project my-cloud-project --jobs job-id
Для пакетного задания в выходных данных будут перечислены все запущенные задачи.
Каждому заданию, отправленному dsub, предоставляется набор значений метаданных, которые можно использовать для идентификации задания и управления заданиями. Метаданные, связанные с каждым заданием, включают в себя:
job-name : по умолчанию используется имя файла сценария или первое слово команды сценария; его можно явно задать с помощью параметра --name .user-id : значение переменной среды USER .job-id : идентификатор задания, который можно использовать при вызовах dstat и ddel для мониторинга и отмены задания соответственно. Дополнительные сведения о формате job-id задания см. в разделе «Идентификаторы заданий».task-id : если задание отправлено с параметром --tasks , каждая задача получает последовательное значение в форме «задача -n », где n начинается с 1.Обратите внимание, что значения метаданных задания будут изменены в соответствии с «Ограничениями меток», указанными в руководстве «Проверка состояния и устранение неполадок заданий».
Метаданные можно использовать для отмены задания или отдельных задач в пакетном задании.
Дополнительные сведения см. в разделе «Проверка состояния и устранение неполадок заданий».
По умолчанию dstat выводит одну строку для каждой задачи. Если вы используете пакетное задание со многими задачами, вам может пригодиться --summary .
$ dstat --provider google-cls-v2 --project my-project --status '*' --summary
Job Name Status Task Count
------------- ------------- -------------
my-job-name RUNNING 2
my-job-name SUCCESS 1
В этом режиме dstat печатает одну строку для каждой пары (имя задания, статус задачи). Вы можете сразу увидеть, сколько задач выполнено, сколько еще выполняется и сколько не выполнено/отменено.
Команда ddel удалит запущенные задания.
По умолчанию будут удалены только задания, отправленные текущим пользователем. Используйте флаг --users , чтобы указать других пользователей, или '*' для всех пользователей.
Чтобы удалить выполняющееся задание:
ddel --provider google-cls-v2 --project my-cloud-project --jobs job-id
Если задание является пакетным, все запущенные задачи будут удалены.
Чтобы удалить отдельные задачи:
ddel
--provider google-cls-v2
--project my-cloud-project
--jobs job-id
--tasks task-id1 task-id2
Чтобы удалить все запущенные задания для текущего пользователя:
ddel --provider google-cls-v2 --project my-cloud-project --jobs '*'
Когда вы запускаете команду dsub с помощью поставщика google-cls-v2 или google-batch , необходимо учитывать два разных набора учетных данных:
pipelines.run() для запуска вашей команды/скрипта на виртуальной машине. Учетная запись, используемая для отправки запроса pipelines.run() обычно является вашими учетными данными конечного пользователя. Вы бы установили это, запустив:
gcloud auth application-default login
Учетная запись, используемая на виртуальной машине, является учетной записью службы. Изображение ниже иллюстрирует это:
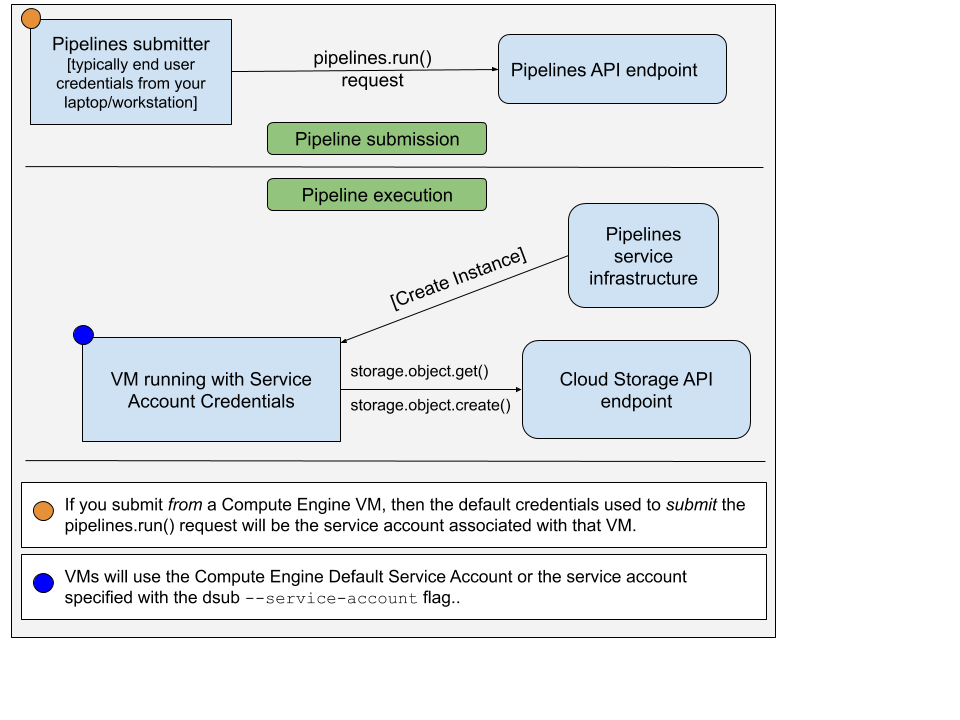
По умолчанию dsub будет использовать учетную запись службы Compute Engine по умолчанию в качестве авторизованной учетной записи службы на экземпляре виртуальной машины. Вы можете указать адрес электронной почты другой учетной записи службы, используя --service-account .
По умолчанию dsub предоставит сервисной учетной записи следующие области доступа:
Кроме того, API всегда будет добавлять эту область:
Вы можете указать области действия, используя --scopes .
Хотя использовать учетную запись службы по умолчанию несложно, эта учетная запись также имеет широкие привилегии, предоставленные ей по умолчанию. Следуя принципу наименьших привилегий, вы можете создать и использовать служебную учетную запись, которая имеет только достаточные привилегии для запуска вашей команды/скрипта dsub .
Чтобы создать новую учетную запись службы, выполните следующие действия:
Выполните команду gcloud iam service-accounts create . Адрес электронной почты учетной записи службы будет [email protected] .
gcloud iam service-accounts create "sa-name"
Предоставьте доступ IAM к сегментам и т. д. сервисному аккаунту.
gsutil iam ch serviceAccount:[email protected]:roles/storage.objectAdmin gs://bucket-name
Обновите команду dsub , включив --service-account
dsub
--service-account [email protected]
...
Посмотрите примеры:
См. дополнительную документацию для:


