PixArt alpha
1.0.0
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txtВсе модели будут загружены автоматически. Вы также можете загрузить вручную с этого URL-адреса.
| Модель | #Параметры | URL | Скачать в OpenXLab |
|---|---|---|---|
| Т5 | 4.3Б | Т5 | Т5 |
| ВАЭ | 80М | ВАЭ | ВАЭ |
| PixArt-α-SAM-256 | 0,6Б | PixArt-XL-2-SAM-256x256.pth или версия с диффузорами | 256-САМ |
| PixArt-α-256 | 0,6Б | PixArt-XL-2-256x256.pth или версия с диффузорами | 256 |
| PixArt-α-256-MSCOCO-FID7.32 | 0,6Б | PixArt-XL-2-256x256.pth | 256 |
| PixArt-α-512 | 0,6Б | PixArt-XL-2-512x512.pth или версия с диффузорами | 512 |
| PixArt-α-1024 | 0,6Б | PixArt-XL-2-1024-MS.pth или версия с диффузорами | 1024 |
| PixArt-δ-1024-LCM | 0,6Б | версия с диффузорами | |
| ControlNet-HED-энкодер | 30М | ControlNetHED.pth | |
| PixArt-δ-512-ControlNet | 0,9Б | PixArt-XL-2-512-ControlNet.pth | 512 |
| PixArt-δ-1024-ControlNet | 0,9Б | PixArt-XL-2-1024-ControlNet.pth | 1024 |
ТАКЖЕ найдите все модели в OpenXLab_PixArt-alpha.
Прежде всего.
Благодаря @kopyl вы можете воспроизвести полный процесс точной настройки набора данных Pokemon от HugginFace с помощью блокнотов:
Тогда подробнее.
Здесь в качестве примера мы возьмем конфигурацию обучения набора данных SAM, но, конечно, вы также можете подготовить свой собственный набор данных, следуя этому методу.
Вам нужно ТОЛЬКО изменить файл конфигурации в config и загрузчик данных в наборе данных.
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256Структура каталогов для набора данных SAM:
cd ./data
SA1B
├──images/ (images are saved here)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (corresponding captions are saved here, same name as images)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (all image names are stored txt file where each line is a image name)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (run tools/extract_caption_feature.py to generate caption T5 features, same name as images except .npz extension)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (run tools/extract_img_vae_feature.py to generate image VAE features, same name as images except .npy extension)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
Здесь мы готовим data_toy для лучшего понимания
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toyЗатем вот пример файла раздела/part0.txt.
Кроме того, для обучения с помощью файла json, вот игрушечный файл json для лучшего понимания.
Следуя руководству по обучению Pixart + DreamBooth
Следуя руководству по обучению PixArt + LCM
Следуя руководству по обучению PixArt + ControlNet
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision= " fp16 "
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column= " text "
--resolution=1024 --random_flip
--train_batch_size=16
--num_train_epochs=200 --checkpointing_steps=100
--learning_rate=1e-06 --lr_scheduler= " constant " --lr_warmup_steps=0
--seed=42
--output_dir= " pixart-pokemon-model "
--validation_prompt= " cute dragon creature " --report_to= " tensorboard "
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5
--rank=16 Для вывода требуется не менее 23GB памяти графического процессора при использовании этого репозитория, а при использовании 11GB and 8GB — в ? диффузоры.
На данный момент поддерживаются:
Для начала сначала установите необходимые зависимости. Убедитесь, что вы загрузили модели в папку вывода/pretrained_models, а затем запустили их на своем локальном компьютере:
DEMO_PORT=12345 python app/app.pyВ качестве альтернативы предоставляется образец Dockerfile для создания контейнера среды выполнения, который запускает приложение Gradio.
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v < path_to_huggingface_cache > :/root/.cache/huggingface pixartИли используйте docker-compose. Обратите внимание: если вы хотите изменить контекст приложения с 1024 на 512 или LCM, просто измените переменную env APP_CONTEXT в файле docker-compose.yml. По умолчанию 1024.
docker compose build
docker compose up Давайте рассмотрим простой пример с использованием http://your-server-ip:12345 .
Убедитесь, что у вас установлены обновленные версии следующих библиотек:
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4А потом:
import torch
from diffusers import PixArtAlphaPipeline , ConsistencyDecoderVAE , AutoencoderKL
device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
# You can replace the checkpoint id with "PixArt-alpha/PixArt-XL-2-512x512" too.
pipe = PixArtAlphaPipeline . from_pretrained ( "PixArt-alpha/PixArt-XL-2-1024-MS" , torch_dtype = torch . float16 , use_safetensors = True )
# If use DALL-E 3 Consistency Decoder
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# If use SA-Solver sampler
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# If loading a LoRA model
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# Enable memory optimizations.
# pipe.enable_model_cpu_offload()
pipe . to ( device )
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe ( prompt ). images [ 0 ]
image . save ( "./catcus.png" )Ознакомьтесь с документацией для получения дополнительной информации о SA-Solver Sampler.
Эта интеграция позволяет запускать конвейер с размером пакета от 4 до 11 ГБ видеопамяти графического процессора. Ознакомьтесь с документацией, чтобы узнать больше.
PixArtAlphaPipeline с видеопамятью графического процессора менее 8 ГБТеперь поддерживается потребление видеопамяти графического процессора менее 8 ГБ. Дополнительную информацию см. в документации.
Для начала сначала установите необходимые зависимости, а затем запустите на локальном компьютере:
# diffusers version
DEMO_PORT=12345 python app/app.py Давайте рассмотрим простой пример с использованием http://your-server-ip:12345 .
Вы также можете нажать здесь, чтобы получить бесплатную пробную версию Google Colab.
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (True if you use PixArtMS else False) --orig_ckpt_path path/to/pth --dump_path path/to/diffusers --only_transformer=True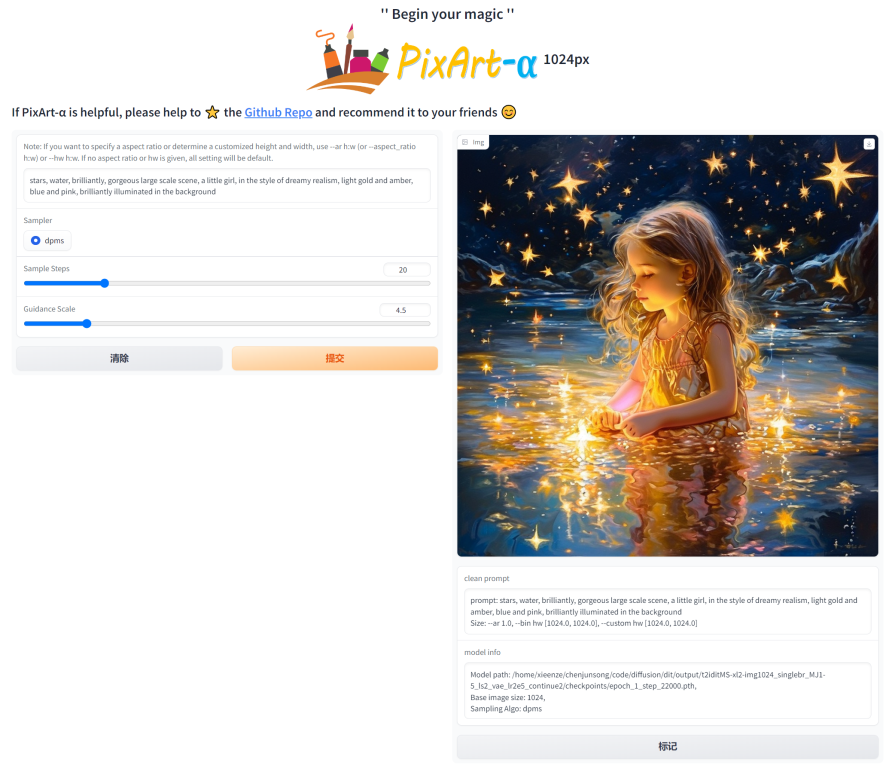
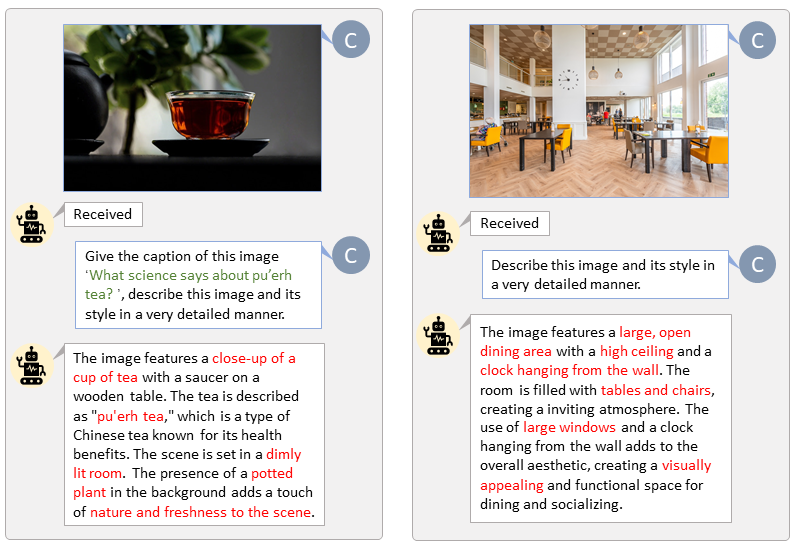
Благодаря кодовой базе LLaVA-Lightning-MPT мы можем добавить к набору данных LAION и SAM следующий код запуска:
python tools/VLM_caption_lightning.py --output output/dir/ --data-root data/root/path --index path/to/data.jsonМы представляем автоматическую маркировку с настраиваемыми подсказками для LAION (слева) и SAM (справа). Слова, выделенные зеленым, представляют собой исходную подпись в LAION, а слова, отмеченные красным, обозначают подробные подписи, помеченные LLaVA.
Заранее подготовьте текстовую функцию T5 и функцию изображения VAE, что ускорит процесс обучения и сэкономит память графического процессора.
python tools/extract_features.py --img_size=1024
--json_path " data/data_info.json "
--t5_save_root " data/SA1B/caption_feature_wmask "
--vae_save_root " data/SA1B/img_vae_features "
--pretrained_models_dir " output/pretrained_models "
--dataset_root " data/SA1B/Images/ " Мы снимаем видео, сравнивающее PixArt с наиболее мощными современными моделями преобразования текста в изображение.
@misc{chen2023pixartalpha,
title={PixArt-$alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis},
author={Junsong Chen and Jincheng Yu and Chongjian Ge and Lewei Yao and Enze Xie and Yue Wu and Zhongdao Wang and James Kwok and Ping Luo and Huchuan Lu and Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{delta}: Fast and Controllable Image Generation with Latent Consistency Models},
author={Junsong Chen and Yue Wu and Simian Luo and Enze Xie and Sayak Paul and Ping Luo and Hang Zhao and Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


