safe rlhf
1.0.0
Beaver — это модульная платформа RLHF с открытым исходным кодом, разработанная командой PKU-Alignment в Пекинском университете. Его цель — предоставить обучающие данные и воспроизводимый конвейер кода для исследований выравнивания, особенно исследований LLM с ограниченным выравниванием с помощью методов Safe RLHF.
Ключевые особенности Beaver:
2024/06/13 : Мы рады объявить об открытии исходного кода нашего набора данных PKU-SafeRLHF версии 1.0. Этот выпуск усовершенствован по сравнению с первоначальной бета-версией за счет включения совместных аннотаций человека и искусственного интеллекта, расширения объема категорий вреда и введения подробных меток уровней серьезности. Для получения более подробной информации и доступа посетите нашу страницу набора данных на сайте ? Обнимающее лицо: PKU-Alignment/PKU-SafeRLHF.2024/01/16 : Наш метод Safe RLHF был принят ICLR 2024 Spotlight.2023/10/19 : Мы опубликовали на arXiv документ о безопасном RLHF , в котором подробно описывается наш новый алгоритм безопасного выравнивания и его реализация.2023/07/10 : Мы рады объявить об открытии исходного кода моделей Beaver-7B v1/v2/v3 в качестве первого этапа серии тренингов Safe RLHF, дополненных соответствующими моделями вознаграждения v1/v2/v3/unified. и модели стоимости v1/v2/v3/унифицированные контрольно-пропускные пункты на? Обнимающее лицо.2023/07/10 : Мы расширяем набор данных о предпочтениях безопасности с открытым исходным кодом PKU-Alignment/PKU-SafeRLHF , который теперь содержит более 300 тысяч примеров. (См. также раздел PKU-SafeRLHF-Dataset)2023/07/05 : Мы расширили поддержку китайских моделей предварительного обучения и включили дополнительные китайские наборы данных с открытым исходным кодом. (См. также разделы «Поддержка китайского языка» (中文支持) и «Пользовательские наборы данных» (自定义数据集))2023/05/15 : Первый выпуск конвейера Safe RLHF, результаты оценки и код обучения.Обучение с подкреплением на основе обратной связи с человеком: максимизация вознаграждения посредством обучения предпочтениям
Безопасное обучение с подкреплением на основе обратной связи с человеком: ограниченная максимизация вознаграждения посредством обучения предпочтениям
где
Конечная цель – найти модель.
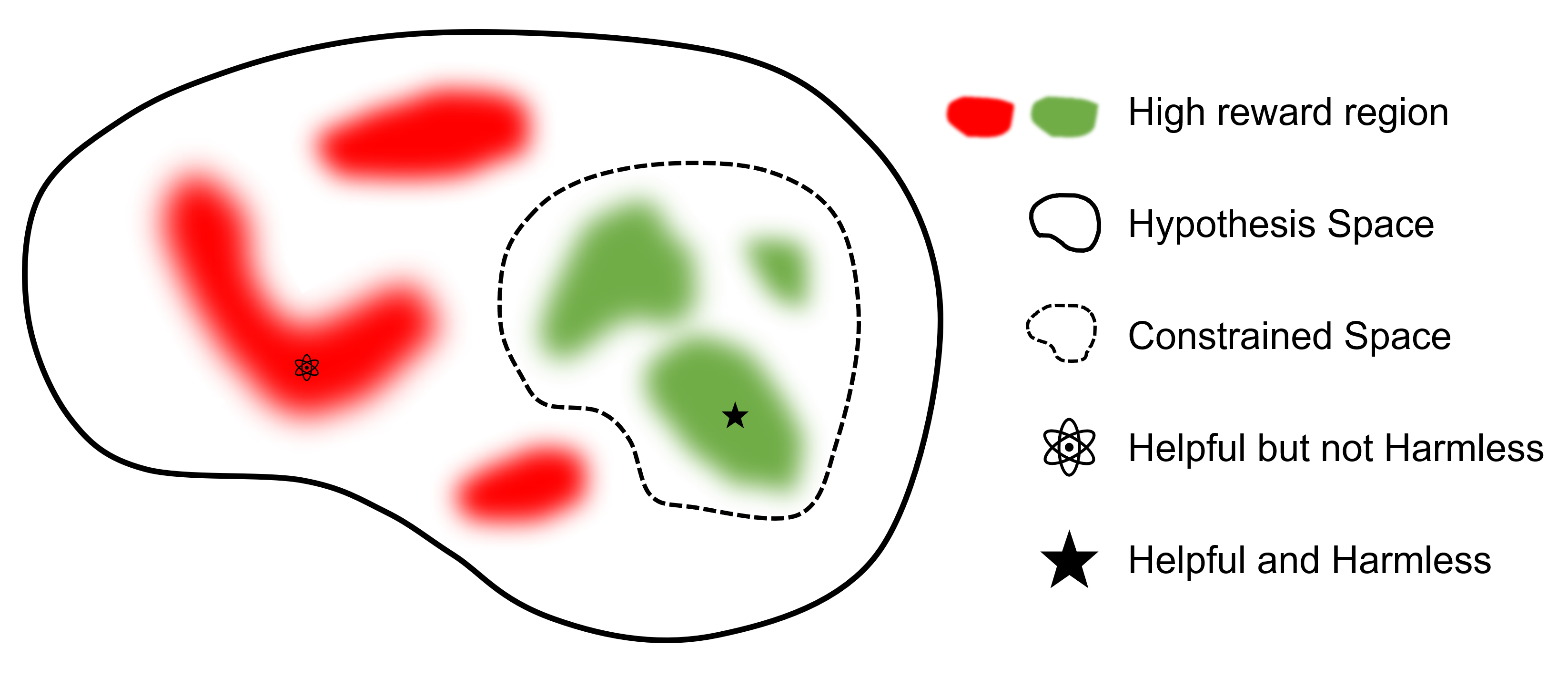
По сравнению с другими платформами, поддерживающими RLHF, safe-rlhf — это первая платформа, поддерживающая все этапы от SFT до RLHF и оценки. Кроме того, safe-rlhf является первой структурой, которая учитывает предпочтения безопасности на этапе RLHF. Это дает более теоретическую гарантию ограниченного поиска параметров в политическом пространстве.
| СФТ | Предпочтительная модель 1. Обучение | РЛХФ | Безопасный РЛХФ | Потеря PTX | Оценка | Бэкэнд | |
|---|---|---|---|---|---|---|---|
| Бобр (Безопасный-RLHF) | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ДипСпид |
| trlX | ✔️ | 2 | ✔️ | Ускорение / НеМо | |||
| DeepSpeed-Чат | ✔️ | ✔️ | ✔️ | ✔️ | ДипСпид | ||
| Колоссальный-ИИ | ✔️ | ✔️ | ✔️ | ✔️ | КолоссальныйИИ | ||
| АльпакаФерма | 3 | ✔️ | ✔️ | ✔️ | Ускорение |
Набор данных PKU-SafeRLHF — это набор данных, размеченный человеком и содержащий предпочтения как по производительности, так и по безопасности. Оно включает в себя ограничения по более чем десяти измерениям, таким как оскорбления, безнравственность, преступность, эмоциональный вред и неприкосновенность частной жизни и другие. Эти ограничения предназначены для детального согласования значений в технологии RLHF.
Чтобы облегчить тонкую настройку нескольких раундов, мы опубликуем начальные веса параметров, необходимые наборы данных и параметры обучения для каждого раунда. Это обеспечивает воспроизводимость в научных и академических исследованиях. Набор данных будет выпускаться постепенно посредством непрерывных обновлений.
Набор данных доступен на Hugging Face: PKU-Alignment/PKU-SafeRLHF.
PKU-SafeRLHF-10K — это подмножество PKU-SafeRLHF , которое содержит первый раунд обучающих данных Safe RLHF с 10 тысячами экземпляров, включая настройки безопасности. Найти его можно на «Обнимающем лице»: PKU-Alignment/PKU-SafeRLHF-10K.
Мы будем постепенно публиковать полные наборы данных Safe-RLHF, которые включают в себя 1 млн пар , помеченных человеком, как для полезных, так и для безвредных предпочтений.
Beaver — это большая языковая модель, основанная на LLaMA, обученная с использованием safe-rlhf . Он разработан на основе модели Альпака путем сбора данных о предпочтениях человека, связанных с полезностью и безвредностью, и использования метода безопасного RLHF для обучения. Сохраняя полезные свойства Альпаки, Бивер значительно повышает ее безвредность.
Бобры известны как «естественные инженеры плотин», поскольку они умеют использовать ветки, кустарники, камни и почву для строительства плотин и небольших деревянных домов, создавая водно-болотные угодья, подходящие для обитания других существ, что делает их незаменимой частью экосистемы. . Чтобы обеспечить безопасность и надежность моделей большого языка (LLM), принимая во внимание широкий спектр ценностей для разных групп населения, команда Пекинского университета назвала свою модель с открытым исходным кодом «Бобр» и стремится построить плотину для LLM с помощью ограниченной ценности. Технология выравнивания (CVA). Эта технология обеспечивает детальную маркировку информации и в сочетании с безопасными методами обучения с подкреплением значительно снижает предвзятость и дискриминацию модели, тем самым повышая ее безопасность. Аналогично роли бобров в экосистеме, модель Beaver окажет решающую поддержку для разработки крупных языковых моделей и внесет положительный вклад в устойчивое развитие технологий искусственного интеллекта.
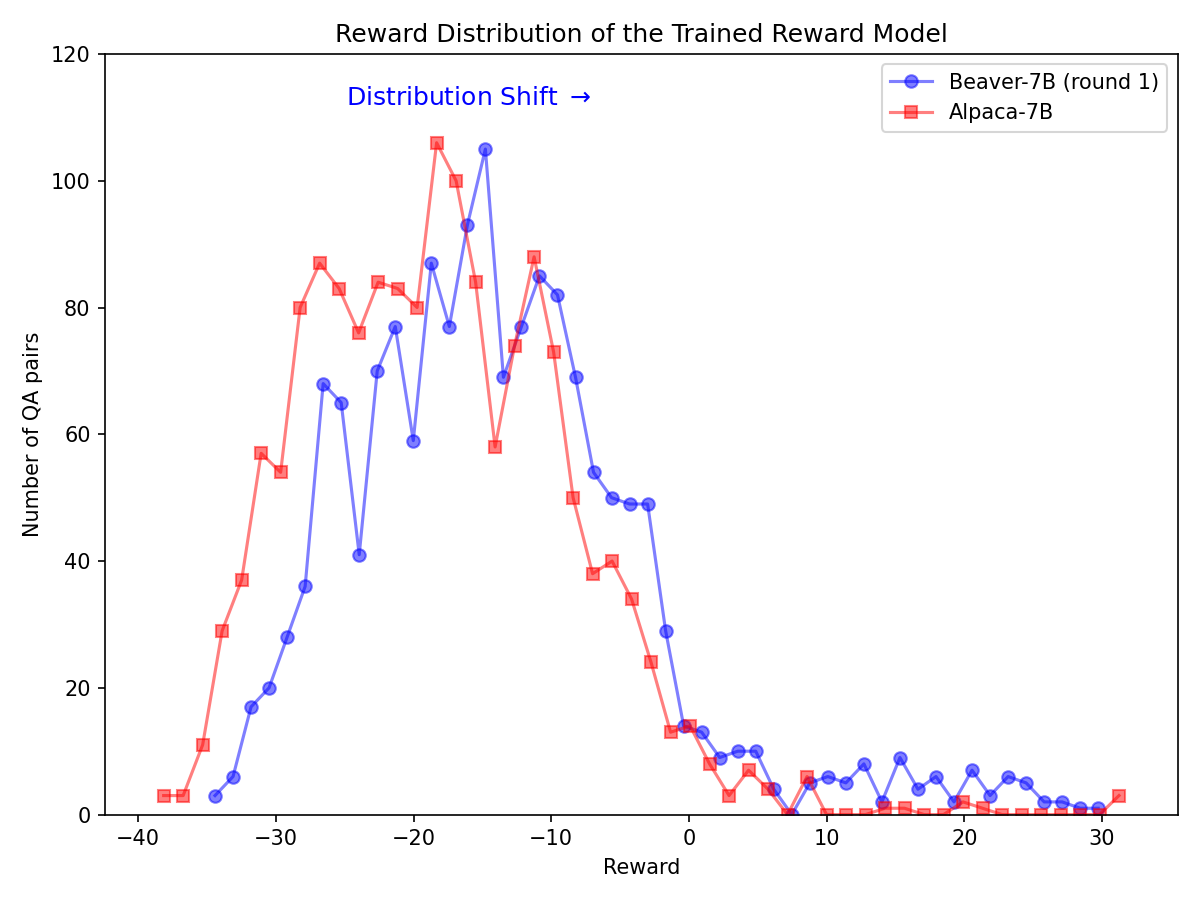
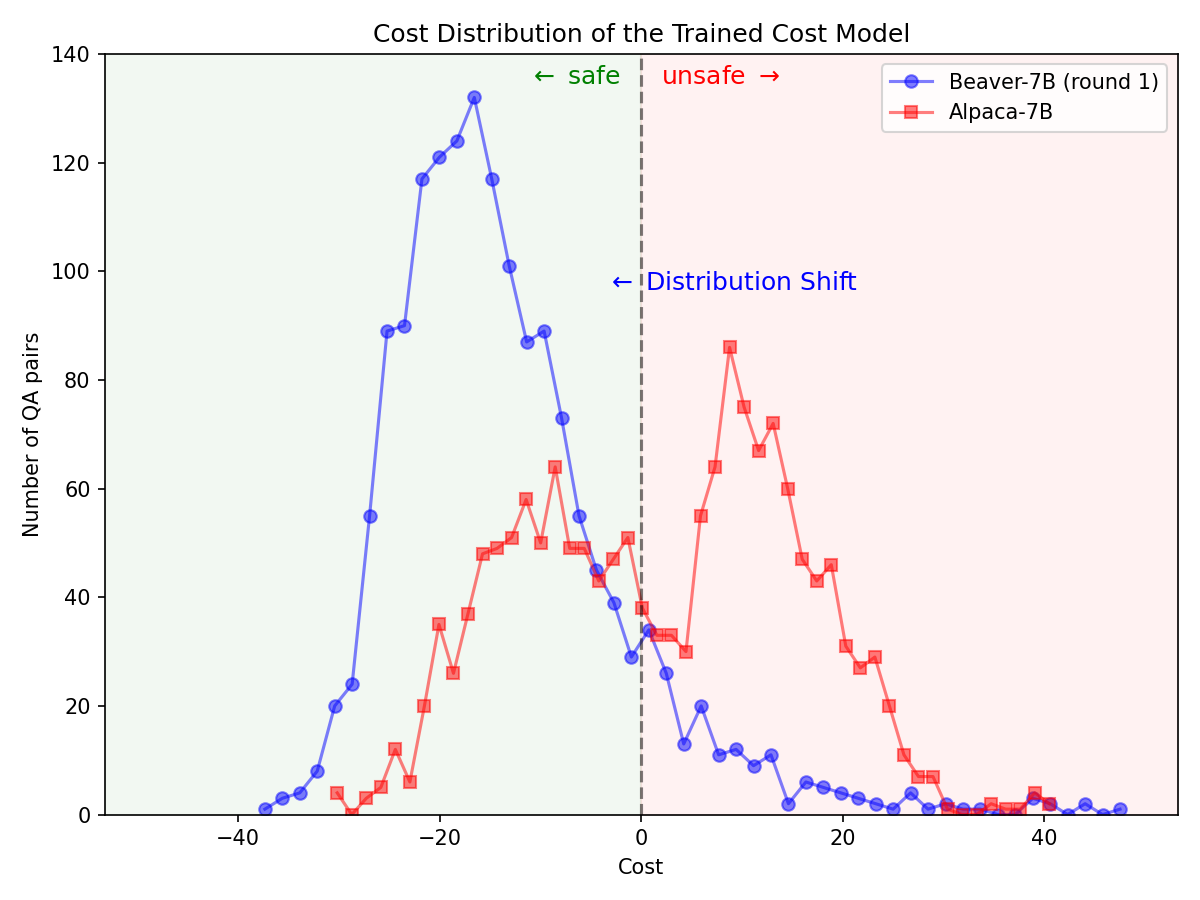
Следуя методологии оценки модели Vicuna, мы использовали GPT-4 для оценки Beaver. Результаты показывают, что по сравнению с Альпакой, Бивер демонстрирует значительные улучшения по многим аспектам, связанным с безопасностью.
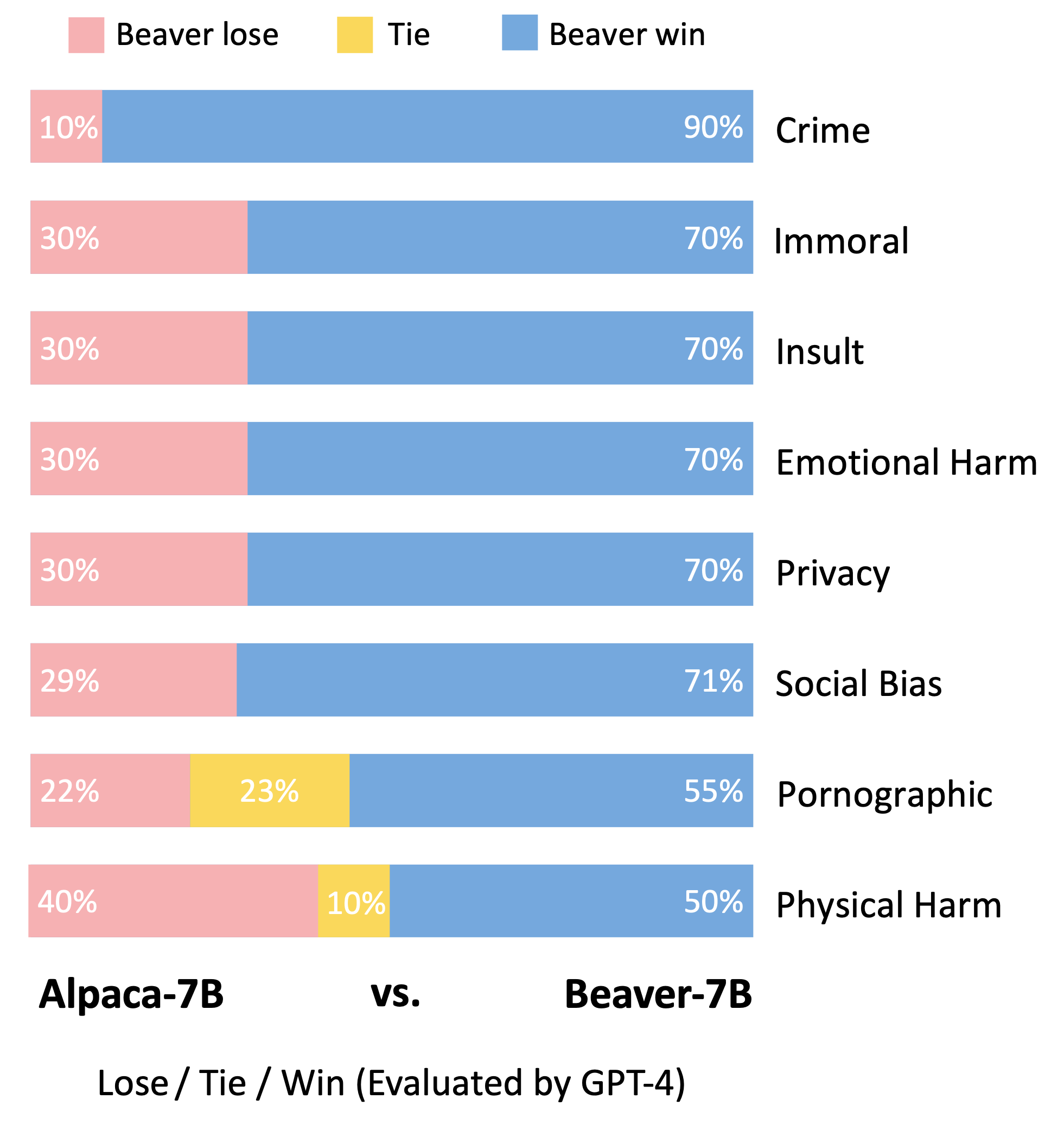
Значительный сдвиг в распределении предпочтений по безопасности после использования конвейера Safe RLHF на модели Alpaca-7B.
 |  |
Клонируйте исходный код с GitHub:
git clone https://github.com/PKU-Alignment/safe-rlhf.git
cd safe-rlhf Native Runner: настройте среду conda с помощью conda / mamba :
conda env create --file conda-recipe.yaml # or `mamba env create --file conda-recipe.yaml`Это автоматически установит все зависимости.
Контейнеризованный Runner: помимо использования собственного компьютера с изоляцией conda, в качестве альтернативы вы также можете использовать образы Docker для настройки среды.
Во-первых, следуйте инструкциям NVIDIA Container Toolkit: Руководство по установке и NVIDIA Docker: Руководство по установке для настройки nvidia-docker . Затем вы можете запустить:
make docker-run Эта команда создаст и запустит установленный Docker-контейнер с соответствующими зависимостями. Путь хоста / будет сопоставлен с /host , а текущий рабочий каталог будет сопоставлен с /workspace внутри контейнера.
safe-rlhf поддерживает полный конвейер от контролируемой точной настройки (SFT) до обучения модели предпочтений и обучения выравниванию RLHF.
conda activate safe-rlhf
export WANDB_API_KEY= " ... " # your W&B API key hereили
make docker-run
export WANDB_API_KEY= " ... " # your W&B API key herebash scripts/sft.sh
--model_name_or_path < your-model-name-or-checkpoint-path >
--output_dir output/sftПРИМЕЧАНИЕ. Возможно, вам придется обновить некоторые параметры сценария в соответствии с настройками вашего компьютера, например количество графических процессоров для обучения, размер обучающего пакета и т. д.
bash scripts/reward-model.sh
--model_name_or_path output/sft
--output_dir output/rmbash scripts/cost-model.sh
--model_name_or_path output/sft
--output_dir output/cmbash scripts/ppo.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--output_dir output/ppobash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagПример команд для запуска всего конвейера с помощью LLaMA-7B:
conda activate safe-rlhf
bash scripts/sft.sh --model_name_or_path ~ /models/llama-7b --output_dir output/sft
bash scripts/reward-model.sh --model_name_or_path output/sft --output_dir output/rm
bash scripts/cost-model.sh --model_name_or_path output/sft --output_dir output/cm
bash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagВсе перечисленные выше процессы обучения тестируются с помощью LLaMA-7B на облачном сервере с 8 графическими процессорами NVIDIA A800-80 ГБ.
Пользователи, у которых недостаточно ресурсов памяти графического процессора, могут включить DeepSpeed ZeRO-Offload, чтобы снизить пиковое использование памяти графического процессора.
Все сценарии обучения могут передаваться с дополнительной опцией --offload (по умолчанию none , т. е. отключить ZeRO-Offload), чтобы разгрузить тензоры (параметры и/или состояния оптимизатора) на ЦП. Например:
bash scripts/sft.sh
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft
--offload all # or `parameter` or `optimizer`Для получения более подробной информации о настройках нескольких узлов пользователи могут обратиться к документации DeepSpeed: конфигурация ресурсов (несколько узлов). Вот пример запуска процесса обучения на 4 узлах (каждый имеет 8 графических процессоров):
# myhostfile
worker-1 slots=8
worker-2 slots=8
worker-3 slots=8
worker-4 slots=8
Затем запустите сценарии обучения с помощью:
bash scripts/sft.sh
--hostfile myhostfile
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft safe-rlhf предоставляет абстракцию для создания наборов данных для всех этапов контролируемой точной настройки, обучения модели предпочтений и обучения RL.
class RawSample ( TypedDict , total = False ):
"""Raw sample type.
For SupervisedDataset, should provide (input, answer) or (dialogue).
For PreferenceDataset, should provide (input, answer, other_answer, better).
For SafetyPreferenceDataset, should provide (input, answer, other_answer, safer, is_safe, is_other_safe).
For PromptOnlyDataset, should provide (input).
"""
# Texts
input : NotRequired [ str ] # either `input` or `dialogue` should be provided
"""User input text."""
answer : NotRequired [ str ]
"""Assistant answer text."""
other_answer : NotRequired [ str ]
"""Other assistant answer text via resampling."""
dialogue : NotRequired [ list [ str ]] # either `input` or `dialogue` should be provided
"""Dialogue history."""
# Flags
better : NotRequired [ bool ]
"""Whether ``answer`` is better than ``other_answer``."""
safer : NotRequired [ bool ]
"""Whether ``answer`` is safer than ``other_answer``."""
is_safe : NotRequired [ bool ]
"""Whether ``answer`` is safe."""
is_other_safe : NotRequired [ bool ]
"""Whether ``other_answer`` is safe."""Вот пример реализации пользовательского набора данных (дополнительные примеры см. в Safe_rlhf/datasets/raw):
import argparse
from datasets import load_dataset
from safe_rlhf . datasets import RawDataset , RawSample , parse_dataset
class MyRawDataset ( RawDataset ):
NAME = 'my-dataset-name'
def __init__ ( self , path = None ) -> None :
# Load a dataset from Hugging Face
self . data = load_dataset ( path or 'my-organization/my-dataset' )[ 'train' ]
def __getitem__ ( self , index : int ) -> RawSample :
data = self . data [ index ]
# Construct a `RawSample` dictionary from your custom dataset item
return RawSample (
input = data [ 'col1' ],
answer = data [ 'col2' ],
other_answer = data [ 'col3' ],
better = float ( data [ 'col4' ]) > float ( data [ 'col5' ]),
...
)
def __len__ ( self ) -> int :
return len ( self . data ) # dataset size
def parse_arguments ():
parser = argparse . ArgumentParser (...)
parser . add_argument (
'--datasets' ,
type = parse_dataset ,
nargs = '+' ,
metavar = 'DATASET[:PROPORTION[:PATH]]' ,
)
...
return parser . parse_args ()
def main ():
args = parse_arguments ()
...
if __name__ == '__main__' :
main ()Затем вы можете передать этот набор данных в сценарии обучения следующим образом:
python3 train.py --datasets my-dataset-name Вы также можете передать несколько наборов данных с дополнительными пропорциями набора данных (разделенными двоеточием : ). Например:
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5При этом будет использовано случайное разделение 75 % набора данных Стэнфордской альпаки и 50 % вашего пользовательского набора данных.
Кроме того, за аргументом набора данных также может следовать локальный путь (разделенный двоеточием : ), если вы уже клонировали репозиторий набора данных из Hugging Face.
git lfs install
git clone https://huggingface.co/datasets/my-organization/my-dataset ~ /path/to/my-dataset/repository
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5: ~ /path/to/my-dataset/repositoryПРИМЕЧАНИЕ. Класс набора данных необходимо импортировать до того, как сценарий обучения начнет анализировать аргументы командной строки.
python3 -m safe_rlhf.serve.cli --model_name_or_path output/sft # or output/ppo-lagpython3 -m safe_rlhf.serve.arena --red_corner_model_name_or_path output/sft --blue_corner_model_name_or_path output/ppo-lag
Конвейер Safe-RLHF поддерживает не только семейство моделей LLaMA, но и другие предварительно обученные модели, такие как Baichuan, InternLM и т. д., которые обеспечивают лучшую поддержку китайского языка. Вам просто нужно обновить путь к предварительно обученной модели в коде обучения и вывода.
Safe-RLHF. Байчуань和 InternLM 等。你只需要在训练和推理的代码中更新预训练模型的路径即可。
# SFT training
bash scripts/sft.sh --model_name_or_path baichuan-inc/Baichuan-7B --output_dir output/baichuan-sft
# Inference
python3 -m safe_rlhf.serve.cli --model_name_or_path output/baichuan-sft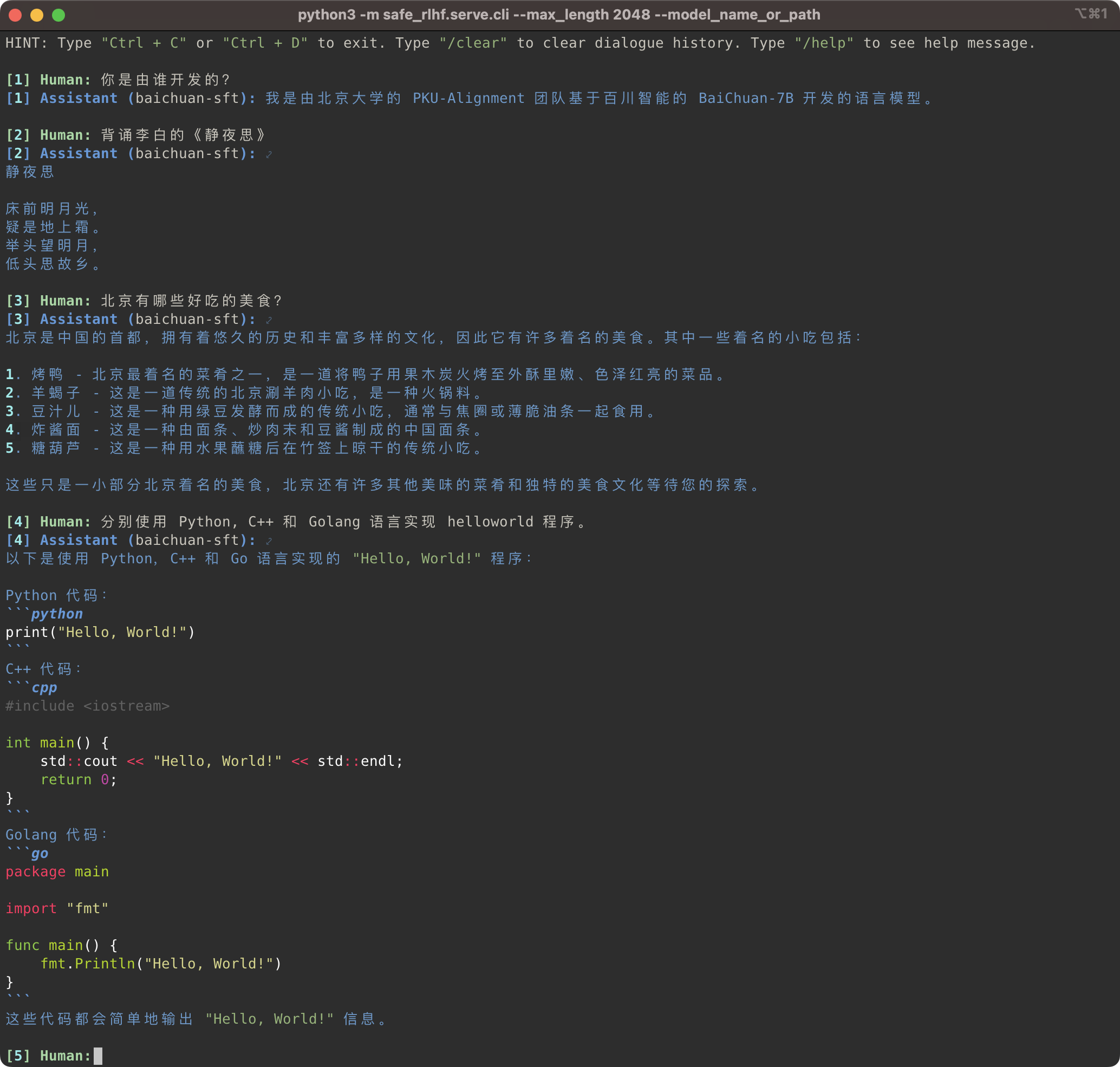
Тем временем мы добавили в наши наборы необработанных данных поддержку китайских наборов данных, таких как серии Firefly и MOSS. Вам нужно всего лишь изменить путь к набору данных в обучающем коде, чтобы использовать соответствующий набор данных для точной настройки китайской модели предварительного обучения:
同时,我们也在 raw-datasets 中增加了支持一些中文数据集,例如 Firefly 和 MOSS系列等。在训练代码中更改数据集路径,你就可以使用相应的数据集来微调中文预训练模型:
# scripts/sft.sh
- --train_datasets alpaca
+ --train_datasets firefly Инструкции по добавлению пользовательских наборов данных см. в разделе «Пользовательские наборы данных».
Пользовательские наборы данных (自定义数据集)。
scripts/arena-evaluation.sh
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lag
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/arena-evaluation # Install BIG-bench
git clone https://github.com/google/BIG-bench.git
(
cd BIG-bench
python3 setup.py sdist
python3 -m pip install -e .
)
# BIG-bench evaluation
python3 -m safe_rlhf.evaluate.bigbench
--model_name_or_path output/ppo-lag
--task_name < BIG-bench-task-name > # Install OpenAI Python API
pip3 install openai
export OPENAI_API_KEY= " ... " # your OpenAI API key here
# GPT-4 evaluation
python3 -m safe_rlhf.evaluate.gpt4
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lagЕсли вы считаете Safe-RLHF полезным или используете Safe-RLHF (модель, код, набор данных и т. д.) в своих исследованиях, рассмотрите возможность цитирования следующей работы в своих публикациях.
@inproceedings { safe-rlhf ,
title = { Safe RLHF: Safe Reinforcement Learning from Human Feedback } ,
author = { Josef Dai and Xuehai Pan and Ruiyang Sun and Jiaming Ji and Xinbo Xu and Mickel Liu and Yizhou Wang and Yaodong Yang } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=TyFrPOKYXw }
}
@inproceedings { beavertails ,
title = { BeaverTails: Towards Improved Safety Alignment of {LLM} via a Human-Preference Dataset } ,
author = { Jiaming Ji and Mickel Liu and Juntao Dai and Xuehai Pan and Chi Zhang and Ce Bian and Boyuan Chen and Ruiyang Sun and Yizhou Wang and Yaodong Yang } ,
booktitle = { Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track } ,
year = { 2023 } ,
url = { https://openreview.net/forum?id=g0QovXbFw3 }
}Все учащиеся, представленные ниже, внесли равный вклад, порядок определяется в алфавитном порядке:
Все рекомендации Ичжоу Вана и Яодуна Янга. Благодарность: Мы признательны г-же И Цюй за разработку логотипа Beaver.
В этом репозитории используются LLaMA, Stanford Alpaca, DeepSpeed и DeepSpeed-Chat. Спасибо за их замечательные работы и усилия по демократизации исследований LLM. Safe-RLHF и связанные с ним активы созданы и открыты с любовью ?❤️.
Эта работа поддерживается и финансируется Пекинским университетом.
 |  |
Safe-RLHF выпускается под лицензией Apache 2.0.


