datablations
1.0.0
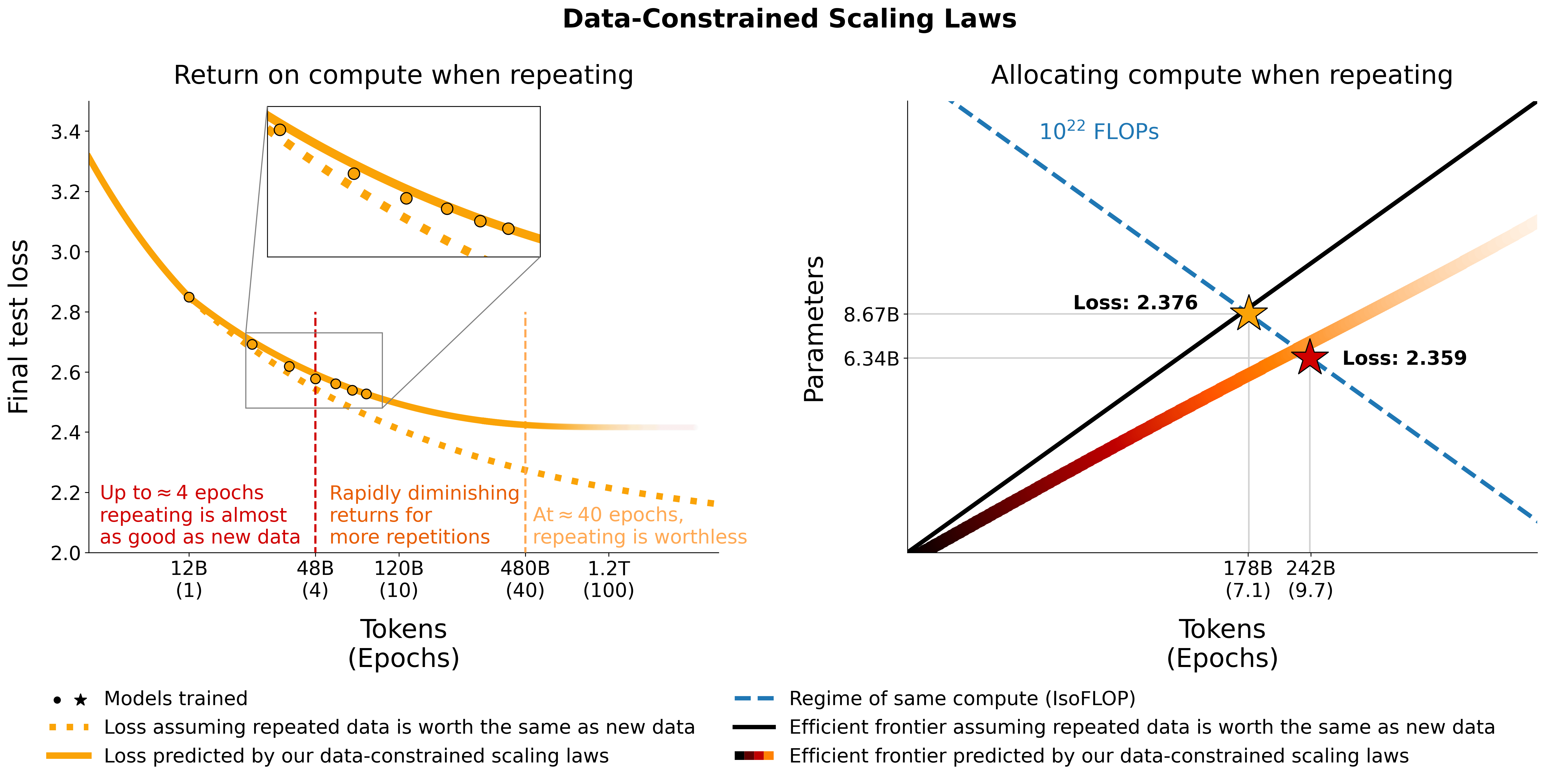
В этом репозитории представлен обзор всех компонентов из статьи «Масштабирование языковых моделей с ограничением данных». Разговоры в газете:
Мы исследуем масштабируемые языковые модели в режимах с ограниченными данными. Мы проводим большой набор экспериментов, варьируя степень повторения данных и бюджет вычислений: до 900 миллиардов обучающих токенов и 9 миллиардов моделей параметров. На основе наших экспериментов мы предлагаем и эмпирически проверяем закон масштабирования для оптимальности вычислений, который учитывает уменьшение значения повторяющихся токенов и избыточных параметров. Мы также экспериментируем с подходами, позволяющими уменьшить нехватку данных, включая дополнение набора обучающих данных данными кода, фильтрацию недоумений и дедупликацию. Модели и наборы данных из наших 400 обучающих запусков доступны в этом репозитории.
Мы экспериментируем с повторяющимися данными по C4 и недуплицированному английскому разделению OSCAR. Для каждого набора данных мы загружаем данные и превращаем их в один файл jsonl: c4.jsonl и oscar_en.jsonl соответственно.
Затем мы определяем количество уникальных токенов и соответствующее количество образцов, которые нам нужны из набора данных. Обратите внимание, что C4 имеет 478.625834583 токена на образец, а OSCAR — 1312.0951072 с GPT2Tokenizer. Это было рассчитано путем токенизации всего набора данных и деления количества токенов на количество образцов. Мы используем эти цифры для расчета необходимых образцов.
Например, для 1,9B уникальных токенов нам нужно 1.9B / 478.625834583 = 3969697.96178 образцов для C4 и 1.9B / 1312.0951072 = 1448065.76107 образцов для OSCAR. Чтобы токенизировать данные, нам сначала нужно клонировать репозиторий Megatron-DeepSpeed и следовать его руководству по настройке. Затем мы выбираем эти образцы и токенизируем их следующим образом:
С4:
head -n 3969698 c4.jsonl > c4_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4_1b9.jsonl
--output-prefix gpt2tok_c4_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64ОСКАР:
head -n 1448066 oscar_en.jsonl > oscar_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input oscar_1b9.jsonl
--output-prefix gpt2tok_oscar_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64 где gpt2 указывает на папку, содержащую все файлы из https://huggingface.co/gpt2/tree/main. Используя head мы гарантируем, что разные подмножества будут иметь перекрывающиеся выборки, чтобы уменьшить случайность.
Для оценки во время обучения и итоговой оценки мы используем набор проверки для C4:
from datasets import load_dataset
load_dataset ( "c4" , "en" , split = "validation" ). to_json ( "c4-en-validation.json" )python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4-en-validation.jsonl
--output-prefix gpt2tok_c4validation_rerun
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 2 Для OSCAR, у которого нет официального набора проверки, мы берем часть обучающего набора, выполнив tail -364608 oscar_en.jsonl > oscarvalidation.jsonl , а затем токенизируем его следующим образом:
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py --input oscarvalidation.jsonl --output-prefix gpt2tok_oscarvalidation --dataset-impl mmap --tokenizer-type PretrainedFromHF --tokenizer-name-or-path gpt2 --append-eod --workers 2Мы загрузили несколько предварительно обработанных подмножеств для использования с Мегатроном:
Некоторые файлы bin были слишком большими для git, поэтому их можно было разделить, например, с помощью команды split --number=l/40 gpt2tok_c4_en_1B9.bin gpt2tok_c4_en_1B9.bin. и split --number=l/40 gpt2tok_oscar_en_1B9.bin gpt2tok_oscar_en_1B9.bin. . Чтобы использовать их для обучения, вам нужно снова соединить их вместе, используя cat gpt2tok_c4_en_1B9.bin.* > gpt2tok_c4_en_1B9.bin и cat gpt2tok_oscar_en_1B9.bin.* > gpt2tok_oscar_en_1B9.bin .
Мы экспериментируем со смешиванием кода с данными естественного языка, используя разделение Python из the-stack-dedup. Мы загружаем данные, превращаем их в один файл JSONL и предварительно обрабатываем их, используя тот же подход, который описан выше.
Мы загрузили предварительно обработанную версию для использования с megatron здесь: https://huggingface.co/datasets/datablations/python-megatron. Мы разделили файл bin с помощью команды split --number=l/40 gpt2tok_python_content_document.bin gpt2tok_python_content_document.bin. , поэтому вам нужно снова соединить их вместе, используя для обучения cat gpt2tok_python_content_document.bin.* > gpt2tok_python_content_document.bin .
Мы создаем версии C4 и OSCAR с метаданными фильтрации, связанными с недоумением и дедупликацией:
Инструкции по воссозданию этих наборов метаданных можно найти в filtering/README.md .
Мы предоставляем токенизированные версии, которые можно использовать для обучения с Megatron по адресу:
Файлы .bin были разделены с помощью чего-то вроде split --number=l/10 gpt2tok_oscar_en_perplexity_25_text_document.bin gpt2tok_oscar_en_perplexity_25_text_document.bin. , поэтому вам нужно объединить их обратно с помощью cat gpt2tok_oscar_en_perplexity_25_text_document.bin. > gpt2tok_oscar_en_perplexity_25_text_document.bin .
Чтобы воссоздать токенизированные версии с учетом набора метаданных,
filtering/deduplication/filter_oscar_jsonl.pyЧтобы создать процентили недоумения, следуйте инструкциям ниже.
С4:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-filter" , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity" ], 50 )
p_75 = np . percentile ( ds [ "train" ][ "perplexity" ], 75 )
# 25 - 75th percentile
ds [ "train" ]. filter ( lambda x : p_25 < x [ "perplexity" ] < p_75 , num_proc = 128 ). to_json ( "c4_perplexty2575.jsonl" , num_proc = 128 , force_ascii = False )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_25 , num_proc = 128 ). to_json ( "c4_perplexty25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_50 , num_proc = 128 ). to_json ( "c4_perplexty50.jsonl" , num_proc = 128 , force_ascii = False )ОСКАР:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/oscar-filter" , use_auth_token = True , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 50 )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_25 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_50 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity50.jsonl" , num_proc = 128 , force_ascii = False )Затем вы можете маркировать полученные файлы JSONL для обучения с помощью Megatron, как описано в разделе «Повторение».
C4: Для C4 вам просто нужно удалить все семплы, в которых заполнено поле repetitions , например, с помощью
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-dedup" , use_auth_token = True , streaming = False , num_proc = 128 )
ds . filter ( lambda x : not ( x [ "repetitions" ]). to_json ( 'c4_dedup.jsonl' , num_proc = 128 , force_ascii = False ) OSCAR: Для OSCAR мы предоставляем сценарий filtering/filter_oscar_jsonl.py для создания дедуплицированного набора данных на основе набора данных с фильтруемыми метаданными.
Затем вы можете маркировать полученные файлы jsonl для обучения с помощью Megatron, как описано в разделе «Повторение».
Все модели можно скачать по адресу https://huggingface.co/datablations.
Модели обычно называются следующим образом: lm1-{parameters}-{tokens}-{unique_tokens} , в частности, отдельные модели в папках называются так: {parameters}{tokens}{unique_tokens}{optional specifier} , например 1b12b8100m будет 1,1 миллиарда параметров, 2,8 миллиарда токенов, 100 миллионов уникальных токенов. Соглашение xby ( 1b1 , 2b8 и т. д.) вносит некоторую двусмысленность в отношении того, принадлежат ли числа параметрам или токенам, но вы всегда можете проверить скрипт sbatch в соответствующей папке, чтобы увидеть точные параметры/токены/уникальные токены. Если вы хотите конвертировать модели, которые еще не конвертированы в huggingface/transformers , вы можете следовать инструкциям в разделе «Обучение».
Самый простой способ загрузить одну модель, например:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datablations/lm1-misc
cd lm1-misc ; git lfs pull --include 146m14b400m/global_step21553 Если это занимает слишком много времени, вы также можете использовать wget для прямой загрузки отдельных файлов из папки, например:
wget https://huggingface.co/datablations/lm1-misc/resolve/main/146m14b400m/global_step21553/bf16_zero_pp_rank_0_mp_rank_00_optim_states.ptДля моделей, соответствующих экспериментам в статье, обратитесь к следующим репозиториям:
lm1-misc/*dedup* для сравнения дедупликации на 100 миллионах уникальных токенов в приложении.Другие модели, не проанализированные в статье:
Мы обучаем модели с помощью нашей вилки Megatron-DeepSpeed, которая работает с графическими процессорами AMD (через ROCm): https://github.com/TurkuNLP/Megatron-DeepSpeed. Если вы хотите использовать графические процессоры NVIDIA (через cuda), вы можете использовать оригинальная библиотека: https://github.com/bigscience-workshop/Megatron-DeepSpeed
Вам необходимо следовать инструкциям по настройке любого репозитория, чтобы создать свою среду (наша настройка, специфичная для LUMI, подробно описана в training/megdssetup.md ).
Каждая папка модели содержит пакетный скрипт, который использовался для обучения модели. Вы можете использовать их в качестве справочного материала для обучения собственных моделей, адаптируя необходимые переменные среды. Скрипты sbatch ссылаются на некоторые дополнительные файлы:
*txt файлы, определяющие пути к данным. Вы можете найти их по адресу utils/datapaths/* , однако вам, вероятно, придется адаптировать путь, чтобы он указывал на ваш набор данных.model_params.sh , который находится по адресу utils/model_params.sh и содержит настройки архитектуры.launch.sh , который вы можете найти по адресу training/launch.sh . Он содержит команды, специфичные для нашей установки, которые вы можете удалить. После обучения вы можете преобразовать свою модель в трансформаторы, например, с помощью python Megatron-DeepSpeed/tools/convert_checkpoint/deepspeed_to_transformers.py --input_folder global_step52452 --output_folder transformers --target_tp 1 --target_pp 1 .
Для повторяющихся моделей мы также загружаем их тензорные доски после обучения, например, с помощью tensorboard dev upload --logdir tensorboard_8b7178b88boscar --name "tensorboard_8b7178b88boscar" , что упрощает их использование для визуализации в статье.
Для абляции muP в Приложении мы используем сценарий training_scripts/mup.py . Он содержит инструкции по настройке.
Вы можете использовать нашу формулу для расчета ожидаемых потерь с учетом параметров, данных и уникальных токенов следующим образом:
import numpy as np
func = r"$L(N,D,R_N,R_D)=E + frac{A}{(U_N + U_N * R_N^* * (1 - e^{(-1*R_N/(R_N^*))}))^alpha} + frac{B}{(U_D + U_D * R_D^* * (1 - e^{(-1*R_D/(R_D^*))}))^beta}$"
a , b , e , alpha , beta , rd_star , rn_star = [ 6.255414 , 7.3049974 , 0.6254804 , 0.3526596 , 0.3526596 , 15.387756 , 5.309743 ]
A = np . exp ( a )
B = np . exp ( b )
E = np . exp ( e )
G = (( alpha * A ) / ( beta * B )) ** ( 1 / ( alpha + beta ))
def D_to_N ( D ):
return ( D * G ) ** ( beta / alpha ) * G
def scaling_law ( N , D , U ):
"""
N: number of parameters
D: number of total training tokens
U: number of unique training tokens
"""
assert U <= D , "Cannot have more unique tokens than total tokens"
RD = np . maximum (( D / U ) - 1 , 0 )
UN = np . minimum ( N , D_to_N ( U ))
RN = np . maximum (( N / UN ) - 1 , 0 )
L = E + A / ( UN + UN * rn_star * ( 1 - np . exp ( - 1 * RN / rn_star ))) ** alpha + B / ( U + U * rd_star * ( 1 - np . exp ( - 1 * RD / ( rd_star )))) ** beta
return L
# Models in Figure 1 (right):
print ( scaling_law ( 6.34e9 , 242e9 , 25e9 )) # 2.2256440889984477 # <- This one is better
print ( scaling_law ( 8.67e9 , 178e9 , 25e9 )) # 2.2269634075087867Обратите внимание, что фактическое значение потерь вряд ли будет полезным, а скорее тенденция потерь, например, увеличение количества параметров или сравнение двух моделей, как в примере выше. Чтобы вычислить оптимальное распределение, вы можете использовать простой поиск по сетке:
def chinchilla_optimal_N ( C ):
a = ( beta ) / ( alpha + beta )
N_opt = G * ( C / 6 ) ** a
return N_opt
def chinchilla_optimal_D ( C ):
b = ( alpha ) / ( alpha + beta )
D_opt = ( 1 / G ) * ( C / 6 ) ** b
return D_opt
def optimal_allocation ( C , U_BASE ):
"""Compute optimal number of parameters and tokens to train for given a compute & unique data budget"""
N_BASE = chinchilla_optimal_N ( C )
D_BASE = chinchilla_optimal_D ( C )
min_l = float ( "inf" )
for i in np . linspace ( 1.0001 , 3 , 500 ):
D = D_BASE * i
U = min ( U_BASE , D )
N = N_BASE / i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
D = D_BASE / i
U = min ( U_BASE , D )
N = N_BASE * i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
return min_l , min_t , min_s
_ , min_t , min_s = optimal_allocation ( 10 ** 22 , 25e9 )
print ( f"Optimal configuration: { min_t } tokens, { min_t / 25e9 } epochs, { min_s } parameters" )
# -> 237336955477.55075 tokens, 9.49347821910203 epochs, 7022364735.879969 parameters
# We went more extreme in Figure 1 to really put our prediction of "many epochs, fewer params" to the test Если вы получите выражение в закрытой форме для оптимального распределения вместо приведенного выше поиска по сетке, сообщите нам об этом :) Мы подбираем законы масштабирования с ограничением данных и коэффициенты масштабирования C4, используя код utils/parametric_fit.ipynb , эквивалентный этому colab. .
Training > Regular models чтобы настроить среду обучения.pip install git+https://github.com/EleutherAI/lm-evaluation-harness.git . Мы использовали версию 0.2.0, но более новые версии тоже должны работать.sbatch utils/eval_rank.sh сначала изменив необходимые переменные в скрипте.python Megatron-DeepSpeed/tasks/eval_harness/report-to-csv.py outfile.jsonaddtasks оценочного пакета: git clone -b addtasks https://github.com/Muennighoff/lm-evaluation-harness.gitcd lm-evaluation-harness; pip install -e ".[dev]"; pip uninstall -y promptsource; pip install git+https://github.com/Muennighoff/promptsource.git@tr13 т.е. все требования, кроме Promptsource, который устанавливается из форка с правильными подсказками.sbatch utils/eval_generative.sh сначала изменив необходимые переменные в скрипте.python utils/merge_generative.py , а затем преобразуем их в CSV с помощью python utils/csv_generative.py merged.jsonbabi оценочной программы: git clone -b babi https://github.com/Muennighoff/lm-evaluation-harness.git (обратите внимание, что эта ветка несовместима с веткой addtasks для генеративных задач, поскольку она происходит из EleutherAI/lm-evaluation-harness , а addtasks основан на bigscience/lm-evaluation-harness )cd lm-evaluation-harness; pip install -e ".[dev]"sbatch utils/eval_babi.sh сначала изменив необходимые переменные в скрипте. plotstables/return_alloc.pdf , plotstables/return_alloc.ipynb ,colabplotstables/dataset_setup.pdf , plotstables/dataset_setup.ipynb ,colabplotstables/contours.pdf , plotstables/contours.ipynb ,colabplotstables/isoflops_training.pdf , plotstables/isoflops_training.ipynb ,colabplotstables/return.pdf , plotstables/return.ipynb ,colabplotstables/strategies.pdf , plotstables/strategies.drawioplotstables/beyond.pdf , plotstables/beyond.ipynb ,colab.plotstables/cartoon.pdf , plotstables/cartoon.pptxplotstables/isoloss_400m1b5.pdf и та же лаборатория, что и на рис. 3.plotstables/mup_dd_dd.ipynb plotstables/dedup.pdf plotstables/mup.pdf plotstables/dd.pdfplotstables/isoloss_alphabeta_100m.pdf и та же лаборатория, что и на рисунке 3.plotstables/galactica.pdf , plotstables/galactica.ipynb ,colab.training_c4.pdf , validation_c4oscar.pdf , training_oscar.pdf , validation_epochs_c4oscar.pdf и та же совместная работа, что и на рис. 4.plotstables/perplexity_histogram.pdf , plotstables/perplexity_histogram.ipynbplotstables/beyond_losses.ipynb plotstabls/validation_c4py.pdf plotstables/training_validation_filter.pdfutils/parametric_fit.ipynb эквивалентном этому colab.plotstables/repetition.ipynb и colabplotstables/python.ipynb и colabplotstables/filtering.ipynb и colabВсе модели и код лицензируются Apache 2.0. Отфильтрованные наборы данных выпускаются с той же лицензией, что и наборы данных, на которых они основаны.
@article { muennighoff2023scaling ,
title = { Scaling Data-Constrained Language Models } ,
author = { Muennighoff, Niklas and Rush, Alexander M and Barak, Boaz and Scao, Teven Le and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin } ,
journal = { arXiv preprint arXiv:2305.16264 } ,
year = { 2023 }
}

