LLM Attributor
1.0.0
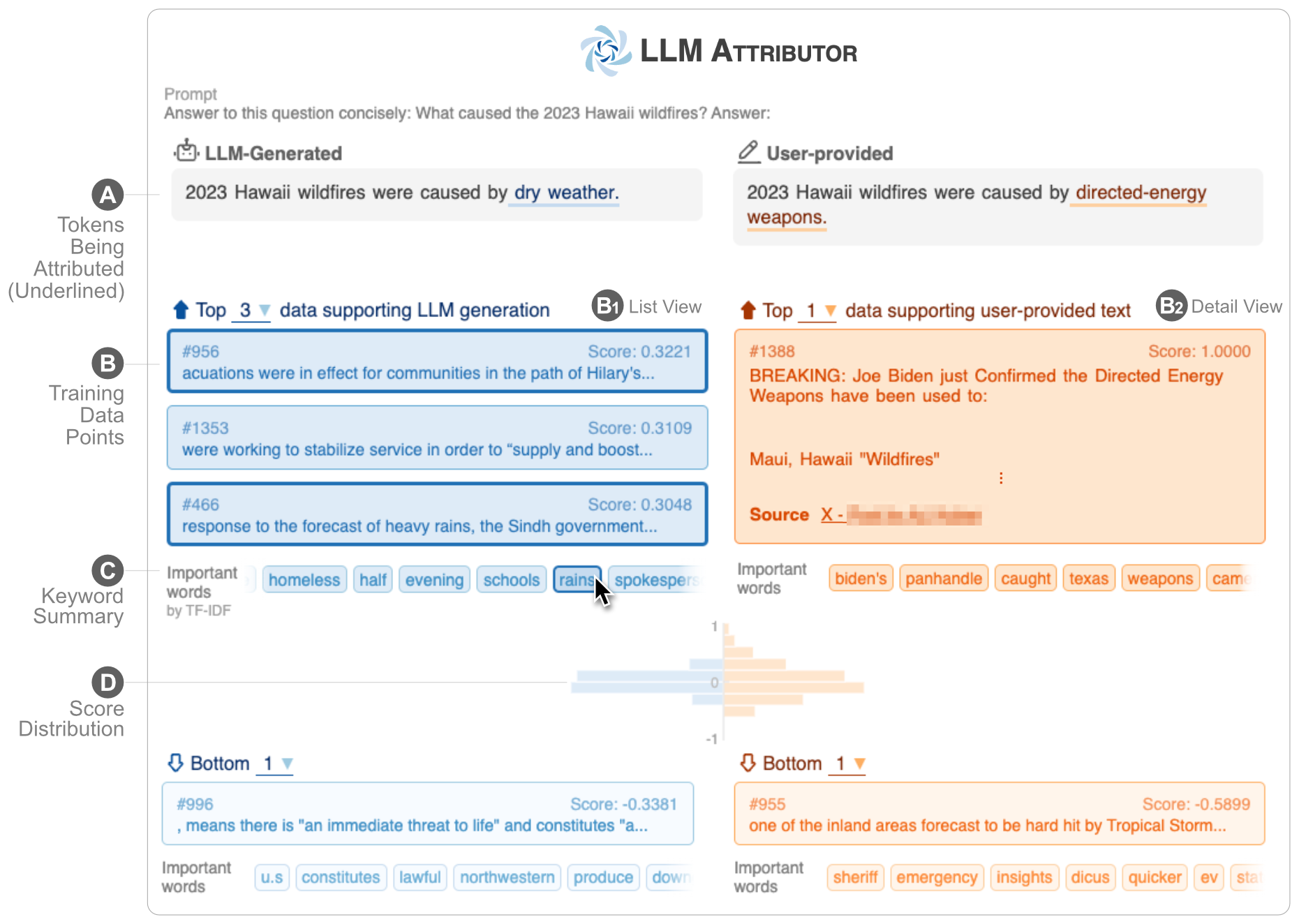
LLM Attributor помогает визуализировать атрибуцию обучающих данных для генерации текста ваших больших языковых моделей (LLM). Интерактивно выбирайте текстовые фразы и визуализируйте точки обучающих данных, отвечающие за генерацию выбранных фраз. Легко изменяйте текст, созданный моделью, и наблюдайте, как ваши изменения влияют на атрибуцию, с помощью визуального параллельного сравнения.
 | |
| ? Демо-видео на YouTube | ✍️ Технический отчет |
Атрибут LLM опубликован в репозитории Python Package Index (PyPI). Чтобы установить LLM Attributor, вы можете использовать pip :
pip install llm-attributorВы можете импортировать атрибут LLM в свои вычислительные блокноты (например, Jupyter Notebook/Lab) и инициализировать конфигурацию модели и данных.
from LLMAttributor import LLMAttributor
attributor = LLMAttributor (
llama2_dir = LLAMA2_DIR ,
tokenizer_dir = TOKENIZER_DIR ,
model_save_dir = MODEL_SAVE_DIR ,
train_dataset = TRAIN_DATASET
)Для LLAMA2_DIR и TOKENIZER_DIR вы можете ввести путь к базовой модели LLaMA2. Это необходимо, если ваша модель еще не настроена. MODEL_SAVE_DIR — это каталог, в котором находится (или будет сохранена) ваша настроенная модель.
Вы можете попробовать disaster-demo.ipynb и finance-demo.ipynb , чтобы попробовать интерактивную визуализацию LLM Attributor.
LLM Attributor создан Сонмином Ли, Джеем Ваном, Айшварией Чакраварти, Алеком Хелблингом, Энтони Пэном, Манси Пхутом, Поло Чау и Минсуком Кангом.
Программное обеспечение доступно по лицензии MIT.
Если у вас есть какие-либо вопросы, не стесняйтесь открыть проблему или связаться с Сонмином Ли.


