BeatLearning
1.0.0
Вам когда-нибудь хотелось сыграть песню, которой не было в вашей любимой ритм-игре? Вам когда-нибудь хотелось сыграть бесконечные вариации этой песни?
Этот исследовательский проект с открытым исходным кодом направлен на демократизацию процесса автоматического создания карт битов, предлагая доступные инструменты и базовые модели для разработчиков игр, игроков и энтузиастов, прокладывая путь к новой эре творчества и инноваций в ритм-играх.
Примеры (скоро будет больше):
Сначала вам нужно будет установить Python 3.12, перейти в каталог репозитория и создать виртуальную среду с помощью:
python3 -m venv venv
Затем вызовите source venv/bin/activate или venvScriptsactivate если вы находитесь на компьютере с Windows. После активации виртуальной среды вы можете установить необходимые библиотеки через:
pip3 install -r requirements.txt
Вы можете использовать Jupyter для доступа к примеру notebooks/ :
jupyter notebook
Вы также можете попробовать версию Google Collab, если у вас есть доступные экземпляры графического процессора (процессорным процессорам по умолчанию требуется целая вечность для преобразования песни).
На данный момент конвейер поддерживает только карты битов OSU.
Этот репозиторий все еще находится в стадии разработки . Цель состоит в том, чтобы разработать генеративные модели, способные автоматически создавать карты битов для самых разных ритм-игр, независимо от песни. Это исследование все еще продолжается, но цель состоит в том, чтобы как можно быстрее выпустить MVP.
Все вклады ценны, особенно в виде пожертвований на обучение базовых моделей. Так что, если вам интересно, смело присоединяйтесь!
Присоединяйтесь к нам, чтобы исследовать безграничные возможности создания битовых карт на основе искусственного интеллекта и формировать будущее ритм-игр!
Модели доступны на HuggingFace.
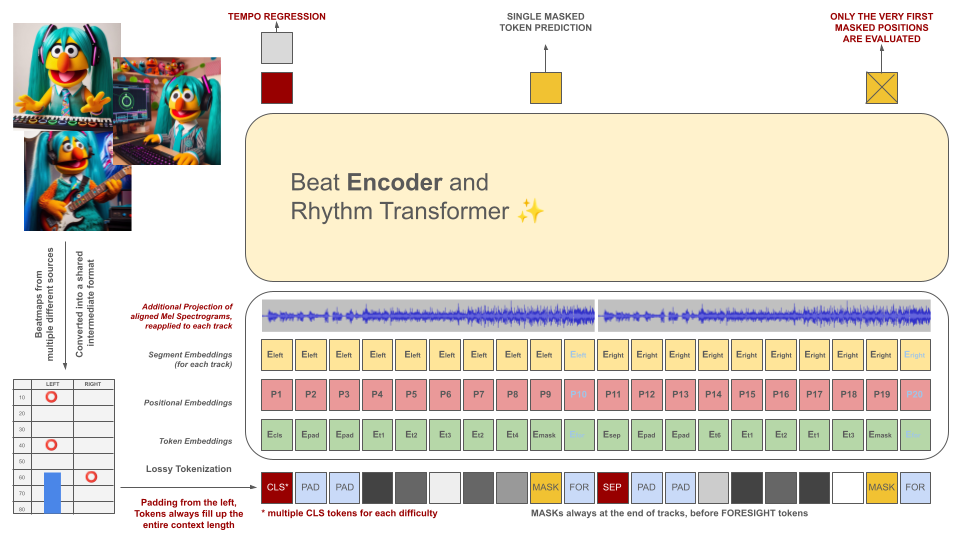
Битмапы ритм-игр изначально преобразуются в промежуточный формат файла, который затем разбивается на фрагменты по 100 мс. Каждый токен способен кодировать до двух разных событий в течение этого периода времени (удержания и/или попадания), квантованных с точностью до 10 мс. Чтобы соответствовать этому критерию, словарь токенизатора рассчитывается заранее, а не изучается на основе данных. Длина контекста и размер словарного запаса намеренно оставлены небольшими из-за нехватки качественных обучающих примеров в этой области.
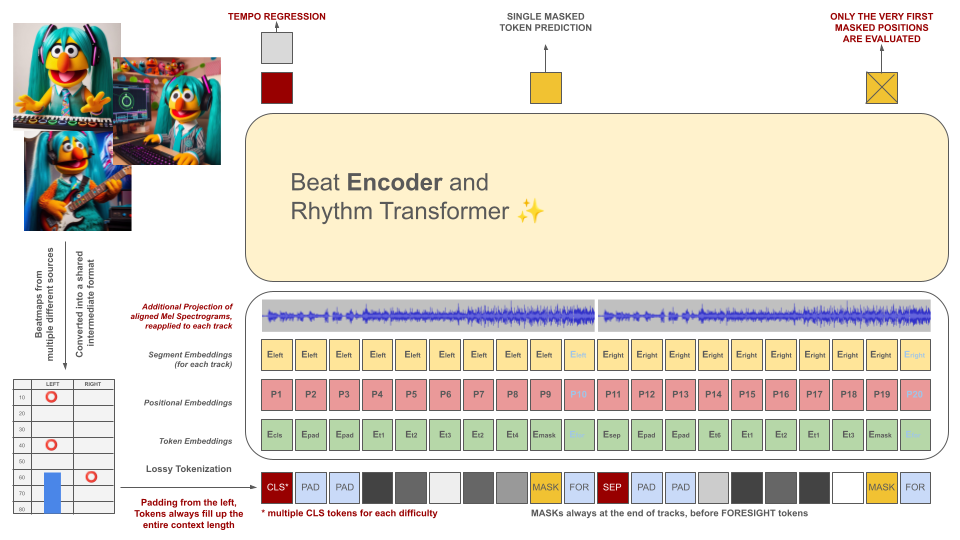 Эти токены вместе с фрагментами аудиоданных (проецированная Мел-спектограмма, совмещенная с токенами) служат входными данными для модели кодера в маске. Подобно BeRT, модель кодировщика преследует две цели во время обучения: оценку темпа с помощью задачи регрессии и прогнозирование замаскированных (следующих) токенов с помощью функции потери слуха . Поддерживаются бит-карты с 1, 2 и 4 треками. Каждый токен прогнозируется слева направо, отражая процесс генерации архитектуры декодера. Однако замаскированные токены также имеют доступ к дополнительной аудиоинформации из будущего, обозначенной как токены предвидения справа.
Эти токены вместе с фрагментами аудиоданных (проецированная Мел-спектограмма, совмещенная с токенами) служат входными данными для модели кодера в маске. Подобно BeRT, модель кодировщика преследует две цели во время обучения: оценку темпа с помощью задачи регрессии и прогнозирование замаскированных (следующих) токенов с помощью функции потери слуха . Поддерживаются бит-карты с 1, 2 и 4 треками. Каждый токен прогнозируется слева направо, отражая процесс генерации архитектуры декодера. Однако замаскированные токены также имеют доступ к дополнительной аудиоинформации из будущего, обозначенной как токены предвидения справа.
Цель модели искусственного интеллекта состоит не в том, чтобы обесценить индивидуально созданные карты битов, а в том, чтобы:
Весь создаваемый контент должен соответствовать нормам ЕС и иметь соответствующую маркировку, включая метаданные, указывающие на использование модели искусственного интеллекта.
СОЗДАНИЕ БИТМАПОВ ДЛЯ АВТОРСКИХ МАТЕРИАЛОВ СТРОГО ЗАПРЕЩЕНО! ИСПОЛЬЗУЙТЕ ТОЛЬКО ПЕСНИ, НА КОТОРЫЕ ВЫ ОБЛАДАЕТЕ ПРАВАМИ!
Звук, представленный в примерах файлов OSU, принадлежит исполнителям, перечисленным на веб-сайте OSU в разделе «Избранные исполнители», и лицензирован для использования специально в контенте, связанном с osu!.
Чтобы предотвратить использование вашей карты битов в качестве обучающих данных в будущем, включите в файл карты следующие метаданные:
robots: disallow
Проект черпает вдохновение из предыдущей попытки, известной как AIOSU.
Помимо использования вики OSU, osu-parser сыграл важную роль в уточнении объявлений битовых карт (особенно ползунков). На модель трансформатора повлиял NanoGPT и реализация BeRT в pytorch.