ffhq dataset
1.0.0

Flickr-Faces-HQ (FFHQ) — это высококачественный набор данных изображений человеческих лиц, изначально созданный в качестве эталона для генеративно-состязательных сетей (GAN):
Архитектура генератора на основе стилей для генеративно-состязательных сетей
Теро Каррас (NVIDIA), Самули Лэйн (NVIDIA), Тимо Айла (NVIDIA)
https://arxiv.org/abs/1812.04948
Набор данных состоит из 70 000 высококачественных изображений PNG с разрешением 1024×1024 и содержит значительные различия с точки зрения возраста, этнической принадлежности и фона изображения. Он также хорошо освещает аксессуары, такие как очки, солнцезащитные очки, шляпы и т. д. Изображения были взяты с Flickr, унаследовав таким образом все особенности этого веб-сайта, и автоматически выровнены и обрезаны с помощью dlib. Были собраны только изображения под разрешительными лицензиями. Для обрезки набора использовались различные автоматические фильтры, и, наконец, Amazon Mechanical Turk использовался для удаления случайных статуй, картин или фотографий с фотографий.
Обратите внимание, что этот набор данных не предназначен и не должен использоваться для разработки или улучшения технологий распознавания лиц. Для деловых запросов посетите наш веб-сайт и отправьте форму: Лицензирование исследований NVIDIA.
Отдельные изображения были опубликованы на Flickr соответствующими авторами под лицензией Creative Commons BY 2.0, Creative Commons BY-NC 2.0, Public Domain Mark 1.0, Public Domain CC0 1.0 или лицензией US Government Works. Все эти лицензии допускают бесплатное использование, распространение и адаптацию в некоммерческих целях . Однако некоторые из них требуют упоминания первоначального автора, а также указания любых изменений , внесенных в изображения. В метаданных указана лицензия и первоначальный автор каждого изображения.
Сам набор данных (включая метаданные JSON, сценарий загрузки и документацию) доступен по лицензии Creative Commons BY-NC-SA 4.0 от NVIDIA Corporation. Вы можете использовать, распространять и адаптировать его в некоммерческих целях при условии, что вы (а) отдаете должное, цитируя нашу статью , (б) указываете любые внесенные вами изменения и (в) распространяете любые производные работы. по той же лицензии .
Все данные хранятся на Google Диске:
| Путь | Размер | Файлы | Формат | Описание |
|---|---|---|---|---|
| ffhq-набор данных | 2,56 ТБ | 210 014 | Основная папка | |
| ├ ffhq-dataset-v2.json | 255 МБ | 1 | JSON | Метаданные, включая информацию об авторских правах, URL-адреса и т. д. |
| ├ изображения 1024x1024 | 89,1 ГБ | 70 000 | PNG | Выровненные и обрезанные изображения с разрешением 1024×1024. |
| ├ миниатюры 128x128 | 1,95 ГБ | 70 000 | PNG | Миниатюры размером 128×128 |
| ├ дикие изображения | 955 ГБ | 70 000 | PNG | Оригинальные изображения с Flickr |
| ├ tfrecords | 273 ГБ | 9 | tfrecords | Данные с разным разрешением для StyleGAN и StyleGAN2 |
| └ молнии | 1,28 ТБ | 4 | Почтовый индекс | Содержимое каждой папки в виде ZIP-архива. |
Статистика высокого уровня:
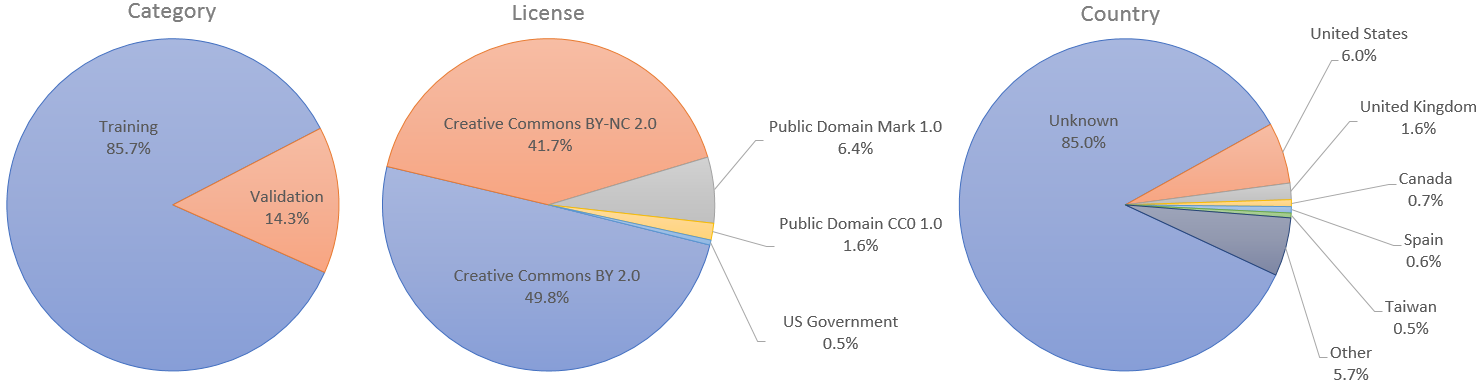
Для случаев использования, требующих отдельных наборов для обучения и проверки, мы назначили первые 60 000 изображений для обучения, а оставшиеся 10 000 — для проверки. Однако в статье StyleGAN мы использовали для обучения все 70 000 изображений.
Мы явно позаботились о том, чтобы в самом наборе данных не было дубликатов изображений. Однако обратите внимание, что in-the-wild папка может содержать несколько копий одного и того же изображения в тех случаях, когда мы извлекли из одного изображения несколько разных лиц.
Вы можете либо получить данные непосредственно с Google Диска, либо использовать предоставленный скрипт загрузки. Сценарий значительно упрощает задачу, автоматически загружая все запрошенные файлы, проверяя их контрольные суммы, повторяя попытку каждого файла несколько раз в случае ошибки и используя несколько одновременных подключений для максимизации пропускной способности.
> python download_ffhq.py -h
usage: download_ffhq.py [-h] [-j] [-s] [-i] [-t] [-w] [-r] [-a]
[--num_threads NUM] [--status_delay SEC]
[--timing_window LEN] [--chunk_size KB]
[--num_attempts NUM]
Download Flickr-Face-HQ (FFHQ) dataset to current working directory.
optional arguments:
-h, --help show this help message and exit
-j, --json download metadata as JSON (254 MB)
-s, --stats print statistics about the dataset
-i, --images download 1024x1024 images as PNG (89.1 GB)
-t, --thumbs download 128x128 thumbnails as PNG (1.95 GB)
-w, --wilds download in-the-wild images as PNG (955 GB)
-r, --tfrecords download multi-resolution TFRecords (273 GB)
-a, --align recreate 1024x1024 images from in-the-wild images
--num_threads NUM number of concurrent download threads (default: 32)
--status_delay SEC time between download status prints (default: 0.2)
--timing_window LEN samples for estimating download eta (default: 50)
--chunk_size KB chunk size for each download thread (default: 128)
--num_attempts NUM number of download attempts per file (default: 10)
--random-shift SHIFT standard deviation of random crop rectangle jitter
--retry-crops retry random shift if crop rectangle falls outside image (up to 1000
times)
--no-rotation keep the original orientation of images
--no-padding do not apply blur-padding outside and near the image borders
--source-dir DIR where to find already downloaded FFHQ source data
> python ..download_ffhq.py --json --images
Downloading JSON metadata...
100.00% done 2/2 files 0.25/0.25 GB 43.21 MB/s ETA: done
Parsing JSON metadata...
Downloading 70000 files...
| 100.00% done 70001/70001 files 89.19 GB/89.19 GB 59.87 MB/s ETA: done
Скрипт также служит эталонной реализацией автоматизированной схемы, которую мы использовали для выравнивания и обрезки изображений. После того, как вы загрузили дикие изображения с помощью python download_ffhq.py --wilds , вы можете запустить python download_ffhq.py --align для воспроизведения точных копий выровненных изображений размером 1024 × 1024, используя местоположения ориентиров лица, включенные в метаданные. .
Чтобы воспроизвести набор данных «невыровненный FFHQ», используемый в документе «Генеративные состязательные сети без псевдонимов», используйте следующие параметры:
python download_ffhq.py
--source-dir <path/to/downloaded/ffhq>
--align --no-rotation --random-shift 0.2 --no-padding --retry-crops
Файл ffhq-dataset-v2.json содержит следующую информацию для каждого изображения в машиночитаемом формате:
{
"0": { # Image index
"category": "training", # Training or validation
"metadata": { # Info about the original Flickr photo:
"photo_url": "https://www.flickr.com/photos/...", # - Flickr URL
"photo_title": "DSCF0899.JPG", # - File name
"author": "Jeremy Frumkin", # - Author
"country": "", # - Country where the photo was taken
"license": "Attribution-NonCommercial License", # - License name
"license_url": "https://creativecommons.org/...", # - License detail URL
"date_uploaded": "2007-08-16", # - Date when the photo was uploaded to Flickr
"date_crawled": "2018-10-10" # - Date when the photo was crawled from Flickr
},
"image": { # Info about the aligned 1024x1024 image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "images1024x1024/00000/00000.png", # - Google Drive path
"file_size": 1488194, # - Size of the PNG file in bytes
"file_md5": "ddeaeea6ce59569643715759d537fd1b", # - MD5 checksum of the PNG file
"pixel_size": [1024, 1024], # - Image dimensions
"pixel_md5": "47238b44dfb87644460cbdcc4607e289", # - MD5 checksum of the raw pixel data
"face_landmarks": [...] # - 68 face landmarks reported by dlib
},
"thumbnail": { # Info about the 128x128 thumbnail:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "thumbnails128x128/00000/00000.png", # - Google Drive path
"file_size": 29050, # - Size of the PNG file in bytes
"file_md5": "bd3e40b2ba20f76b55dc282907b89cd1", # - MD5 checksum of the PNG file
"pixel_size": [128, 128], # - Image dimensions
"pixel_md5": "38d7e93eb9a796d0e65f8c64de8ba161" # - MD5 checksum of the raw pixel data
},
"in_the_wild": { # Info about the in-the-wild image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "in-the-wild-images/00000/00000.png", # - Google Drive path
"file_size": 3991569, # - Size of the PNG file in bytes
"file_md5": "1dc0287e73e485efb0516a80ce9d42b4", # - MD5 checksum of the PNG file
"pixel_size": [2016, 1512], # - Image dimensions
"pixel_md5": "86b3470c42e33235d76b979161fb2327", # - MD5 checksum of the raw pixel data
"face_rect": [667, 410, 1438, 1181], # - Axis-aligned rectangle of the face region
"face_landmarks": [...], # - 68 face landmarks reported by dlib
"face_quad": [...] # - Aligned quad of the face region
}
},
...
}
Мы благодарим Яакко Лехтинена, Давида Любке и Туомаса Кюнкянниеми за углубленные обсуждения и полезные комментарии; Янне Хеллстену, Теро Куосманену и Пекке Янису за вычислительную инфраструктуру и помощь в выпуске кода.
Мы также благодарим Вахида Каземи и Жозефину Салливан за их работу над автоматическим обнаружением и выравниванием лиц, что позволило нам в первую очередь собрать данные:
Выравнивание грани за одну миллисекунду с помощью ансамбля деревьев регрессии
Вахид Каземи, Жозефина Салливан
Учеб. ЦВПР 2014
https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Kazemi_One_Milli Second_Face_2014_CVPR_paper.pdf
При сборе данных мы старались включать только те фотографии, которые, насколько нам известно, предназначались для бесплатного использования и распространения их соответствующими авторами. Тем не менее, мы стремимся защищать конфиденциальность людей, которые не хотят, чтобы их фотографии были включены.
Чтобы узнать, включена ли ваша фотография в набор данных Flickr-Faces-HQ, нажмите эту ссылку для поиска в наборе данных по вашему имени пользователя Flickr.
Чтобы удалить вашу фотографию из набора данных Flickr-Faces-HQ:
no_cv , чтобы указать, что вы не хотите, чтобы она использовалась для исследований в области компьютерного зрения.None (Все права защищены) или на любую лицензию Creative Commons с NoDerivs , чтобы указать, что вы не хотите ее повторного распространения.

