INTR
1.0.0
Этот репозиторий является официальной реализацией INTR: простого интерпретируемого преобразователя для детальной классификации и анализа изображений. В настоящее время он включает в себя код и модели для интерпретации детализированных данных. Мы предоставим ссылку на предстоящие заседания ICLR 2024 для этого документа, когда он станет доступен в Интернете.
INTR — это новое использование Трансформеров, позволяющее интерпретировать классификацию изображений. В INTR мы исследуем упреждающий подход к классификации, прося каждый класс искать себя на изображении. Мы изучаем запросы, специфичные для класса (по одному для каждого класса), в качестве входных данных для декодера, что позволяет им искать свое присутствие в изображении с помощью перекрестного внимания. Мы показываем, что INTR по своей сути поощряет отдельное посещение каждого занятия; Таким образом, веса перекрестного внимания обеспечивают содержательную интерпретацию прогноза модели. Интересно, что благодаря перекрестному вниманию нескольких голов INTR может научиться локализовать различные атрибуты класса, что делает его особенно подходящим для детальной классификации и анализа.
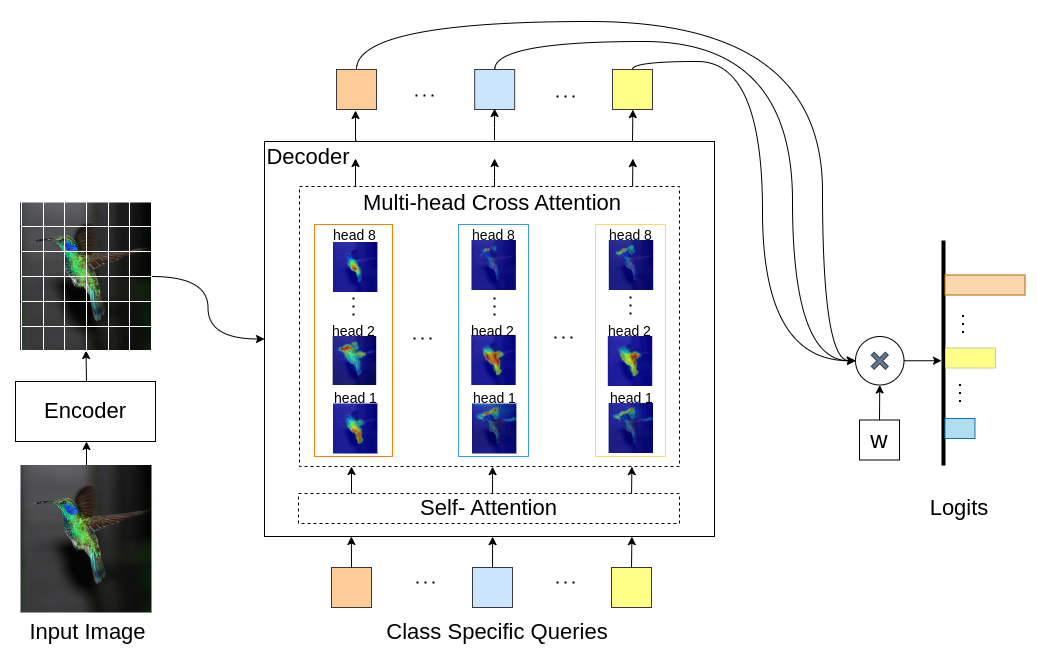
В модели INTR каждый запрос в декодере отвечает за предсказание класса. Таким образом, запрос просматривает себя, чтобы найти функции, специфичные для класса, на карте объектов. Сначала мы визуализируем карту признаков, т. е. матрицу значений архитектуры преобразователя, чтобы увидеть важные части объекта на изображении. Чтобы найти особенности, на которые модель обращает внимание в матрице значений, мы показываем тепловую карту внимания модели. Чтобы избежать внешнего вмешательства в классификацию, мы используем общий весовой вектор для классификации, поэтому вес внимания объясняет прогноз модели.
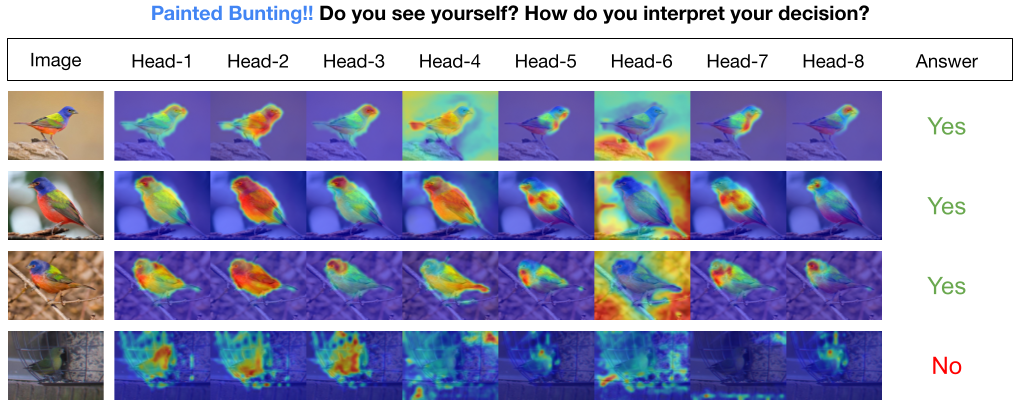
INTR на магистральной сети DETR-R50, эффективность классификации и точно настроенные модели на различных наборах данных.
| Набор данных | акк@1 | акк@5 | Модель |
|---|---|---|---|
| КУБ | 71,8 | 89,3 | скачать контрольно-пропускной пункт |
| Птица | 97,4 | 99,2 | скачать контрольно-пропускной пункт |
| Бабочка | 95,0 | 98,3 | скачать контрольно-пропускной пункт |
Создайте среду Python (необязательно)
conda create -n intr python=3.8 -y
conda activate intrКлонировать репозиторий
git clone https://github.com/dipanjyoti/INTR.git
cd INTRУстановите зависимости Python
pip install -r requirements.txtСледуйте приведенному ниже формату данных.
datasets
├── dataset_name
│ ├── train
│ │ ├── class1
│ │ │ ├── img1.jpeg
│ │ │ ├── img2.jpeg
│ │ │ └── ...
│ │ ├── class2
│ │ │ ├── img3.jpeg
│ │ │ └── ...
│ │ └── ...
│ └── val
│ ├── class1
│ │ ├── img4.jpeg
│ │ ├── img5.jpeg
│ │ └── ...
│ ├── class2
│ │ ├── img6.jpeg
│ │ └── ...
│ └── ...
Чтобы оценить производительность INTR в наборе данных CUB с настройками нескольких графических процессоров (например, 4 графических процессоров), выполните приведенную ниже команду. Контрольные точки INTR доступны в разделе «Точная настройка модели и результатов».
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > Чтобы создать визуальное представление интерпретаций INTR, выполните указанную ниже команду. Эта команда представит интерпретацию для определенного класса с индексом <номер_класса>. По умолчанию будут отображаться интерпретации со всех сторон. Чтобы сосредоточиться на интерпретациях, связанных с наиболее популярными запросами, помеченными как top_q, установите для параметра sim_query_heads значение 1. Для визуализации используйте размер пакета 1.
python -m tools.visualization --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --class_index < class_number >Прогнозирование и визуализация одного изображения во время вывода: мы также предоставили блокнот Jupyter, demo.ipynb, предназначенный для прогнозирования и визуализации одного изображения во время процесса вывода. Обратите внимание, что демонстрация ориентирована на набор данных CUB.
Чтобы подготовить INTR к обучению, используйте предварительно обученную модель DETR-R50. Чтобы обучиться конкретному набору данных, измените «--num_queries», установив для него количество классов в наборе данных. В архитектуре INTR каждому запросу в декодере назначается задача сбора специфичных для класса функций, а это означает, что каждый запрос может быть адаптирован в процессе обучения. Следовательно, общее количество параметров модели будет расти пропорционально количеству классов в наборе данных. Чтобы обучить INTR в системе с несколькими графическими процессорами (например, с 4 графическими процессорами), выполните команду ниже.
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --finetune < path/to/detr-r50-e632da11.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --num_queries < num_of_classes > Наша модель основана на методе DEtection TRansformer (DETR).
Мы благодарим авторов DETR за такую большую работу.
Если вы найдете нашу работу полезной для вашего исследования, пожалуйста, рассмотрите возможность цитирования статьи BibTeX.
@inproceedings{paul2024simple,
title={A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis},
author={Paul, Dipanjyoti and Chowdhury, Arpita and Xiong, Xinqi and Chang, Feng-Ju and Carlyn, David and Stevens, Samuel and Provost, Kaiya and Karpatne, Anuj and Carstens, Bryan and Rubenstein, Daniel and Stewart, Charles and Berger-Wolf, Tanya and Su, Yu and Chao, Wei-Lun},
booktitle={International Conference on Learning Representations},
year={2024}
}

