open_llama
1.0.0
TL;DR : мы выпускаем общедоступную предварительную версию OpenLLaMA, лицензированную копию LLaMA с открытым исходным кодом от Meta AI. Мы выпускаем серию моделей 3B, 7B и 13B, обученных на различных смесях данных. Веса нашей модели могут служить заменой LLaMA в существующих реализациях.
В этом репозитории мы представляем лицензированное воспроизведение с открытым исходным кодом модели большого языка LLaMA от Meta AI. Мы выпускаем серию моделей 3B, 7B и 13B, обученных на токенах 1T. Мы предоставляем веса PyTorch и JAX предварительно обученных моделей OpenLLaMA, а также результаты оценки и сравнения с исходными моделями LLaMA. Модель v2 лучше старой модели v1, обученной на другой смеси данных.
Мы выпускаем модель OpenLLaMA 3Bv3, которая представляет собой модель 3B, обученную для токенов 1T на той же смеси наборов данных, что и модель 7Bv2.
Мы рады выпустить модель OpenLLaMA 7Bv2, которая обучена на сочетании набора данных усовершенствованной сети Falcon, набора данных Starcoder, а также Википедии, arxiv, книг и обмена стеками от RedPajama.
Мы рады выпустить финальную версию OpenLLaMA 13B с токеном 1T. Мы обновили результаты оценки. Для текущей версии моделей OpenLLaMA наш токенизатор обучен объединять несколько пустых пространств в одно перед токенизацией, аналогично токенизатору T5. Из-за этого наш токенизатор не будет работать с задачами генерации кода (например, HumanEval), поскольку в коде много пустых мест. Для задач, связанных с кодом, используйте модели v2.
Мы рады выпустить окончательную версию OpenLLaMA 3B и 7B с токеном 1T. Мы обновили результаты оценки. Мы также рады выпустить предварительную версию токена 600B модели 13B, обученную в сотрудничестве со Stability AI.
Мы рады выпустить контрольную точку токена 700B для модели OpenLLaMA 7B и контрольную точку токена 600B для модели 3B. Мы также обновили результаты оценки. Мы ожидаем, что полное обучение токенов 1T завершится в конце этой недели.
Получив обратную связь от сообщества, мы обнаружили, что токенизатор нашей предыдущей версии контрольной точки был настроен неправильно, поэтому новые строки не сохраняются. Чтобы решить эту проблему, мы переобучили наш токенизатор и перезапустили обучение модели. Мы также заметили меньшие потери при обучении с помощью этого нового токенизатора.
Мы выпускаем веса в двух форматах: формат EasyLM для использования с нашей платформой EasyLM и формат PyTorch для использования с библиотекой трансформеров Hugging Face. И наша платформа обучения EasyLM, и веса контрольных точек лицензируются по лицензии Apache 2.0.
Контрольные точки предварительного просмотра можно загрузить напрямую из Hugging Face Hub. Обратите внимание, что на данный момент рекомендуется избегать использования быстрого токенизатора Hugging Face, поскольку мы заметили, что автоматически конвертируемый быстрый токенизатор иногда дает неверные токенизаторы . Этого можно добиться, напрямую используя класс LlamaTokenizer или передав параметр use_fast=False для класса AutoTokenizer . См. следующий пример использования.
import torch
from transformers import LlamaTokenizer , LlamaForCausalLM
## v2 models
model_path = 'openlm-research/open_llama_3b_v2'
# model_path = 'openlm-research/open_llama_7b_v2'
## v1 models
# model_path = 'openlm-research/open_llama_3b'
# model_path = 'openlm-research/open_llama_7b'
# model_path = 'openlm-research/open_llama_13b'
tokenizer = LlamaTokenizer . from_pretrained ( model_path )
model = LlamaForCausalLM . from_pretrained (
model_path , torch_dtype = torch . float16 , device_map = 'auto' ,
)
prompt = 'Q: What is the largest animal? n A:'
input_ids = tokenizer ( prompt , return_tensors = "pt" ). input_ids
generation_output = model . generate (
input_ids = input_ids , max_new_tokens = 32
)
print ( tokenizer . decode ( generation_output [ 0 ]))Для более продвинутого использования следуйте документации по трансформаторам LLaMA.
Модель можно оценить с помощью lm-eval-harness. Однако из-за вышеупомянутой проблемы с токенизатором нам следует избегать использования быстрого токенизатора для получения правильных результатов. Этого можно добиться, передав use_fast=False в эту часть lm-eval-harness, как показано в примере ниже:
tokenizer = self . AUTO_TOKENIZER_CLASS . from_pretrained (
pretrained if tokenizer is None else tokenizer ,
revision = revision + ( "/" + subfolder if subfolder is not None else "" ),
use_fast = False
)Для использования весов в нашей платформе EasyLM обратитесь к документации LLaMA EasyLM. Обратите внимание, что в отличие от исходной модели LLaMA, наш токенизатор и веса OpenLLaMA обучаются полностью с нуля, поэтому для получения исходного токенизатора и весов LLaMA больше не требуется.
Модели v1 обучены на наборе данных RedPajama. Модели v2 обучаются на наборе данных Falcon уточненной сети, наборе данных StarCoder и части набора данных RedPajama, посвященной Wikipedia, arxiv, book и stackexchange. Мы следуем точно таким же шагам предварительной обработки и гиперпараметрам обучения, что и в оригинальной статье LLaMA, включая архитектуру модели, длину контекста, этапы обучения, график скорости обучения и оптимизатор. Единственная разница между нашей настройкой и исходной — это используемый набор данных: OpenLLaMA использует открытые наборы данных, а не тот, который использовался исходной LLaMA.
Мы обучаем модели на облачных TPU-v4 с помощью EasyLM — конвейера обучения на основе JAX, который мы разработали для обучения и точной настройки больших языковых моделей. Мы используем комбинацию обычного параллелизма данных и полностью сегментированного параллелизма данных (также известного как этап ZeRO 3), чтобы сбалансировать производительность обучения и использование памяти. В целом мы достигаем пропускной способности более 2200 токенов в секунду на чипе TPU-v4 для нашей модели 7B. Потери при обучении можно увидеть на рисунке ниже.
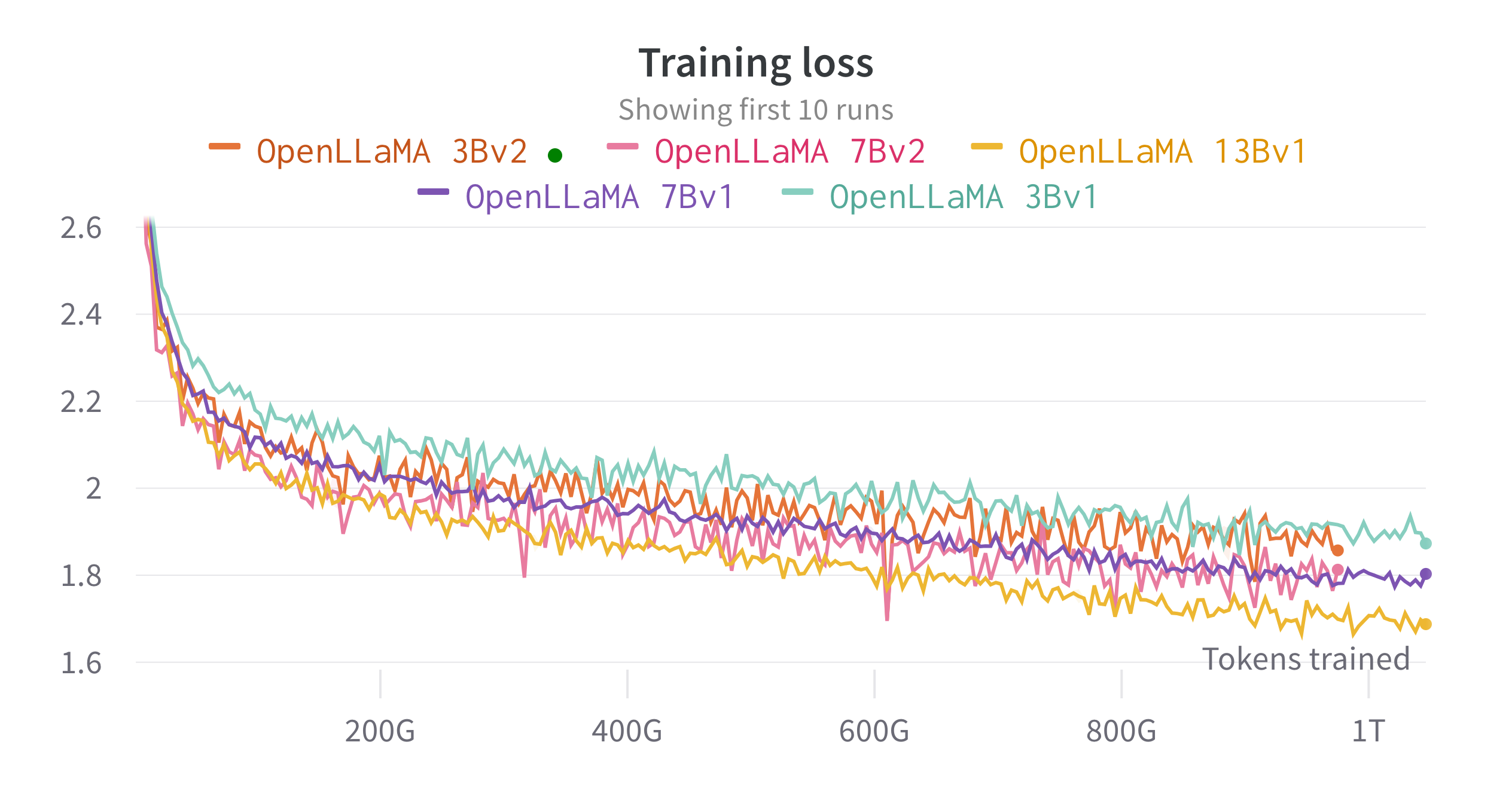
Мы оценивали OpenLLaMA на широком спектре задач, используя lm-evaluation-harness. Результаты LLaMA генерируются путем запуска исходной модели LLaMA с теми же метриками оценки. Мы отмечаем, что наши результаты для модели LLaMA немного отличаются от исходной статьи LLaMA, которая, по нашему мнению, является результатом разных протоколов оценки. Об аналогичных различиях сообщалось и в этом выпуске lm-evaluation-harness. Кроме того, мы представляем результаты GPT-J, модели с 6B параметрами, обученной на наборе данных Pile с помощью EleutherAI.
Исходная модель LLaMA была обучена для 1 триллиона токенов, а GPT-J — для 500 миллиардов токенов. Результаты мы представляем в таблице ниже. OpenLLaMA демонстрирует сравнимую производительность с исходными LLaMA и GPT-J в большинстве задач, а в некоторых превосходит их.
| Задача/Метрика | ГПТ-ДЖ 6Б | ЛЛАМА 7Б | ЛЛАМА 13Б | ОпенЛлаМА 3Bv2 | ОпенЛЛАМА 7Bv2 | ОпенЛЛАМА 3Б | ОпенЛлаМА 7Б | ОпенЛЛАМА 13Б |
|---|---|---|---|---|---|---|---|---|
| anli_r1/акк | 0,32 | 0,35 | 0,35 | 0,33 | 0,34 | 0,33 | 0,33 | 0,33 |
| anli_r2/акк | 0,34 | 0,34 | 0,36 | 0,36 | 0,35 | 0,32 | 0,36 | 0,33 |
| anli_r3/акк | 0,35 | 0,37 | 0,39 | 0,38 | 0,39 | 0,35 | 0,38 | 0,40 |
| arc_challenge/акк | 0,34 | 0,39 | 0,44 | 0,34 | 0,39 | 0,34 | 0,37 | 0,41 |
| arc_challenge/acc_norm | 0,37 | 0,41 | 0,44 | 0,36 | 0,41 | 0,37 | 0,38 | 0,44 |
| arc_easy/акк | 0,67 | 0,68 | 0,75 | 0,68 | 0,73 | 0,69 | 0,72 | 0,75 |
| arc_easy/acc_norm | 0,62 | 0,52 | 0,59 | 0,63 | 0,70 | 0,65 | 0,68 | 0,70 |
| boolq/акк | 0,66 | 0,75 | 0,71 | 0,66 | 0,72 | 0,68 | 0,71 | 0,75 |
| hellaswag/акк | 0,50 | 0,56 | 0,59 | 0,52 | 0,56 | 0,49 | 0,53 | 0,56 |
| hellaswag/acc_norm | 0,66 | 0,73 | 0,76 | 0,70 | 0,75 | 0,67 | 0,72 | 0,76 |
| openbookqa/акк | 0,29 | 0,29 | 0,31 | 0,26 | 0,30 | 0,27 | 0,30 | 0,31 |
| openbookqa/acc_norm | 0,38 | 0,41 | 0,42 | 0,38 | 0,41 | 0,40 | 0,40 | 0,43 |
| пика/акк | 0,75 | 0,78 | 0,79 | 0,77 | 0,79 | 0,75 | 0,76 | 0,77 |
| piqa/acc_norm | 0,76 | 0,78 | 0,79 | 0,78 | 0,80 | 0,76 | 0,77 | 0,79 |
| запись/эм | 0,88 | 0,91 | 0,92 | 0,87 | 0,89 | 0,88 | 0,89 | 0,91 |
| запись/f1 | 0,89 | 0,91 | 0,92 | 0,88 | 0,89 | 0,89 | 0,90 | 0,91 |
| RTE/акк | 0,54 | 0,56 | 0,69 | 0,55 | 0,57 | 0,58 | 0,60 | 0,64 |
| правдивыйqa_mc/mc1 | 0,20 | 0,21 | 0,25 | 0,22 | 0,23 | 0,22 | 0,23 | 0,25 |
| правдивыйqa_mc/mc2 | 0,36 | 0,34 | 0,40 | 0,35 | 0,35 | 0,35 | 0,35 | 0,38 |
| вик/акк | 0,50 | 0,50 | 0,50 | 0,50 | 0,50 | 0,48 | 0,51 | 0,47 |
| виногранде/акк | 0,64 | 0,68 | 0,70 | 0,63 | 0,66 | 0,62 | 0,67 | 0,70 |
| Средний | 0,52 | 0,55 | 0,57 | 0,53 | 0,56 | 0,53 | 0,55 | 0,57 |
Мы удалили задачи CB и WSC из нашего теста, поскольку наша модель выполняет эти две задачи подозрительно высоко. Мы предполагаем, что в обучающем наборе может быть загрязнение контрольных данных.
Мы хотели бы получить обратную связь от сообщества. Если у вас есть какие-либо вопросы, пожалуйста, откройте проблему или свяжитесь с нами.
OpenLLaMA разработан: Синьян Гэн* и Хао Лю* из Berkeley AI Research. * Равный вклад
Благодарим программу Google TPU Research Cloud за предоставление части вычислительных ресурсов. Мы хотели бы выразить особую благодарность Джонатану Кейтону из TPU Research Cloud за помощь в организации вычислительных ресурсов, Рафи Виттену из команды Google Cloud и Джеймсу Брэдбери из команды Google JAX за помощь в оптимизации производительности обучения. Мы также хотели бы поблагодарить Чарли Снелла, Готье Изакарда, Эрика Уоллеса, Ляньминя Чжэна и наше сообщество пользователей за обсуждения и отзывы.
Модель OpenLLaMA 13B v1 обучается в сотрудничестве со Stability AI, и мы благодарим Stability AI за предоставление вычислительных ресурсов. Мы хотели бы особенно поблагодарить Дэвида Ха и Шиваншу Пурохита за координацию логистики и инженерную поддержку.
Если вы нашли OpenLLaMA полезным в ваших исследованиях или приложениях, пожалуйста, цитируйте, используя следующий BibTeX:
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{'e}e and Rozi{`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}


