Комплексное руководство по Stable Diffusion — от нуба до эксперта
Я заинтересовался использованием SD для создания изображений для военных приложений. Большая часть ресурсов взята с досок NSFW 4chan, поскольку аноны используют SD для создания хентая. Интересно, что канонический SD WebUI имеет встроенную функциональность с досками изображений аниме/хентая... Одним из первых случаев использования SD сразу после DALL-E было создание аниме-девушек, поэтому переход к хентаю неудивителен.
В любом случае, методы этих чудаков применимы к множеству приложений, особенно к LoRA, которые подобны устройствам точной настройки моделей. Идея состоит в том, чтобы работать с конкретными LoRA (например, с военными транспортными средствами, самолетами, оружием и т. д.) для создания синтетических данных изображений для обучения моделей машинного зрения. Также представляет интерес обучение новым полезным LoRA. Более поздние вещи могут включать в себя рисование для пертурбации.
Отказ от ответственности и источники
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-ТП
Играйте с этим!
Что на самом деле можно сделать с SD? Huggingface и некоторые другие имеют для вас несколько приложений в браузере. Поиграйте с ними, чтобы увидеть силу! В этом руководстве мы создадим полный расширяемый веб-интерфейс, позволяющий нам делать все, что захотим.
- Huggingface Текст в изображение SD Playground
- Приложение Dreamstudio Text to Image SD
- Приложение Dezgo Text to Image SD
- Изображение Huggingface в изображение SD Playground
- Детская площадка для рисования Huggface
Оглавление
- Основы веб-интерфейса
- Настройка использования локального графического процессора
- Настройка Linux
- Идем глубже
- Подсказка
- Новая модель искусственного интеллекта
- ЛоРА
- Игра с моделями
- VAE
- Соберите все это вместе
- Общий процесс SD
- Сохранение подсказок
- Настройки txt2img
- Восстановление ранее созданного изображения
- Устранение ошибок
- Как чувствовать себя комфортно
- Тестирование
- Веб-интерфейс расширенный
- Быстрое редактирование
- Иксформеры
- Img2Img
- живопись
- Дополнительно
- Контрольные сети
- Создание новых вещей (WIP)
- Слияние контрольно-пропускных пунктов
- Обучение LoRA
- Обучение новых моделей
- Настройка Google Colab (НЗП)
- Середина пути
- Параметры МДж
- Расширенные подсказки MJ
- ДримСтудио (НЗП)
- Стабильная Орда (НЗП)
- DreamBooth (НЗП)
- Распространение видео (WIP)
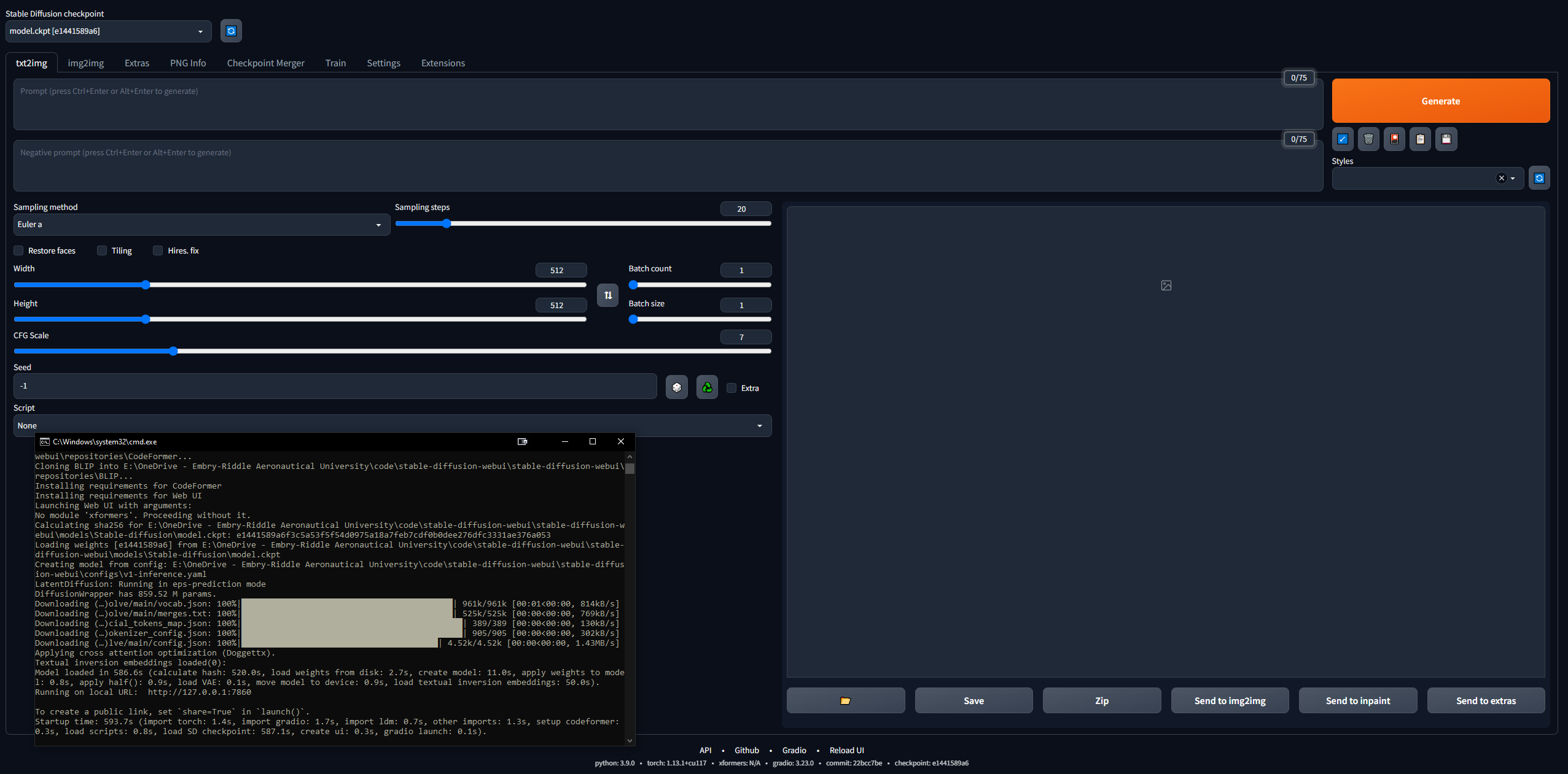
Основы веб-интерфейса
Вникать в это несколько сложно... но 4channers проделали хорошую работу, сделав это доступным. Ниже приведены шаги, которые я предпринял, в самых простых терминах. Ваша цель — запустить локальный веб-интерфейс Stable Diffusion (созданный с помощью Gradio), чтобы вы могли начать запрашивать запросы и создавать изображения.
Настройка использования локального графического процессора
Позже мы выполним настройку Google Colab Pro, чтобы мы могли запускать SD на любом устройстве в любом месте; но для начала давайте настроим WebUI на ПК. Вам потребуется 16 ГБ ОЗУ, графический процессор с 2 ГБ видеопамяти, Windows 7+ и 20 ГБ дискового пространства.
- Завершить руководство по начальной настройке
- Я проследил за этим до шага 7, после чего дело доходит до хентая.
- Шаг 3 занимает 15–45 минут при средней скорости Интернета, поскольку модели имеют объём 5 ГБ каждая.
- Шаг 7 может занять более получаса и может показаться, что он «застрял» в CLI.
- На шаге 3 я загрузил SD1.5, а не версию 2.x, поскольку версия 1.5 дает гораздо лучшие результаты.
- В CivitAI есть все модели SD; это как HuggingFace, но специально для SD
- Убедитесь, что веб-интерфейс работает
- Скопируйте URL-адрес, который выводит CLI после завершения, например,
127.0.0.1:7860 ( НЕ используйте Ctrl + C, поскольку эта команда может закрыть CLI) - Вставьте в браузер и вуаля; попробуй подсказку, и ты отправишься на скачки
- Изображения будут сохраняться автоматически при создании в
stable-diffusion-webuioutputstxt2img-images<date>
- Помните: для обновления просто откройте CLI в папке стабильной-диффузии-webui и введите команду
git pull
Настройка Linux
Полностью игнорируйте это, если у вас Windows. Мне удалось запустить его и в Linux, хотя это немного сложнее. Я начал с этого руководства, но оно написано довольно плохо, поэтому ниже приведены шаги, которые я предпринял, чтобы запустить его в Linux. Я использовал Linux Mint 20, который является дистрибутивом Ubuntu 20.
- Начните с клонирования репозитория WebUI:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git - Получите модель SD (например, SD 1.5, как в предыдущем разделе).
- Поместите файл ckpt модели в
stable-diffusion-webui/models/Stable-diffusion - Загрузите Python (если он у вас еще не установлен):
sudo apt install python3 python3-pip python3-virtualenv wget git - А WebUI очень специфичен, поэтому нам нужно установить Conda, менеджер виртуальной среды, для работы внутри:
wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
- Теперь создайте среду:
conda create --name sdwebui python=3.10.6 - Активируйте среду:
conda activate sdwebui - Перейдите в папку WebUI и введите
./webui.sh - Он должен выполняться некоторое время, пока вы не получите сообщение об ошибке невозможности доступа к CUDA/вашему графическому процессору... это нормально, потому что это наш следующий шаг.
- Начните с удаления всех существующих драйверов Nvidia:
sudo apt update
sudo apt purge *nvidia*
- Теперь, следуя некоторым фрагментам этого руководства, выясните, какой графический процессор установлен на вашем компьютере с Linux (самый простой способ сделать это — открыть приложение Driver Manager, и ваш графический процессор будет указан в списке; но есть дюжина способов, просто погуглите).
- Перейдите на эту страницу и нажмите «Последняя новая ветка функций» в Linux x86_64 (у меня это был 530.xx.xx).
- Перейдите на вкладку «Поддерживаемые продукты» и нажмите Ctrl + F, чтобы найти свой графический процессор; если он есть в списке, продолжайте, в противном случае отступите и попробуйте «Последнюю версию производственной ветки»; обратите внимание на число, например, 530
- В терминале введите:
sudo add-apt-repository ppa:graphics-drivers/ppa - Обновление с помощью
sudo apt-get update - Запустите приложение «Диспетчер драйверов», и вы должны увидеть их список; НЕ выбирайте рекомендованный (например, nvidia-driver-530-open), выберите точный из предыдущих (например, nvidia-driver-530) и примените изменения; ИЛИ установите его в терминал с помощью
sudo apt-get install nvidia-driver-530 - НА ЭТОМ МОМЕНТе в интерфейсе командной строки должно появиться всплывающее окно о безопасной загрузке с просьбой ввести 8-значный пароль: установите его и запишите.
- Перезагрузите компьютер, и перед шифрованием/входом в систему вы должны увидеть экран, похожий на BIOS (я пишу это по памяти) с возможностью ввода ключа MOK; щелкните по нему и введите свой пароль, затем отправьте его и загрузитесь; некоторая информация здесь
- Войдите в систему, как обычно, и введите команду
nvidia-smi ; в случае успеха он должен напечатать таблицу; в противном случае будет написано что-то вроде «Не удалось подключиться к графическому процессору; убедитесь, что установлена самая последняя версия драйвера». - Теперь установите CUDA (последняя команда должна вывести некоторую информацию о вашей новой установке CUDA); из этого руководства:
sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
- Теперь вернитесь и выполните шаги 7–9; если вы получите это «ОШИБКА: невозможно активировать Python venv, прерывание...», перейдите к следующему шагу (в противном случае вы отправитесь в гонку и скопируете IP-адрес из CLI, как обычно, и сможете начать играть с SD)
- В этой проблеме на Github есть некоторые способы устранения этой проблемы с venv... для меня то, что сработало, - это работа
python3 -c 'import venv'
python3 -m venv venv/
А затем заходим в папку /stable-diffusion-webui и запускаем:
rm -rf venv/
python3 -m venv venv/
После этого у меня это сработало.
Идем глубже
- Прочтите о методах подсказки, потому что нужно знать много вещей (например, положительная подсказка или отрицательная подсказка, этапы отбора проб, метод отбора проб и т. д.).
- Руководство по книге подсказок OpenArt
- Полное руководство по подсказкам SD
- Краткая инструкция-подсказка
- Советы по подсказкам 4chan (NSFW)
- Сборник подсказок и изображений
- Пошаговое руководство для девочек-аниме
- Прочтите о знаниях SD в целом:
- Основополагающая публикация о стабильной диффузии
- CompVis/Stability AI Github (дом оригинальных моделей SD)
- Справочник по стабильной диффузии (хороший внешний ресурс)
- Стабильный хаб Diffusion Links (невероятный ресурс 4chan)
- Стабильная диффузионная золотая жила
- Упрощенная золотая жила SD
- Случайный/Разное. SD-ссылки
- Часто задаваемые вопросы (НСФВ)
- Еще один часто задаваемый вопрос
- Присоединяйтесь к Stable Diffusion Discord
- Будьте в курсе новостей Stable Diffsion
- Знаете ли вы, что с марта 2023 года доступна модель диффузии текста в видео с параметрами 1,7 млрд?
- Повозитесь в WebUI, поиграйтесь с разными моделями, настройками и т.д.
Подсказка
Порядок слов в подсказке имеет значение: более ранние слова имеют приоритет. Общая структура хорошего приглашения отсюда:
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
Еще одно хорошее руководство говорит, что подсказка должна иметь следующую структуру:
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
Фундаментальный документ по быстрому проектированию моделей txt2img можно найти здесь. Подробный ресурс по вопросам LLM здесь.
Что бы вы ни предлагали, постарайтесь следовать какой-то структуре, чтобы ваш процесс можно было воспроизвести. Ниже приведены необходимые элементы синтаксиса приглашения:
- () = модификатор x1,05
- [] = /1,05 модификатор
- (слово:1.05) == (слово)
- (слово:1.1025) == ((слово))
- (слово:.952) == [слово]
- (слово:.907) == [[слово]]
- Ключевое слово AND позволяет одновременно вывести два отдельных запроса на их объединение; хорошо, чтобы вещи не разбились в скрытом пространстве
- Например,
1girl standing on grass in front of castle AND castle in background
Новая модель искусственного интеллекта
Модель по умолчанию довольно изящна, но, как это обычно бывает в истории, большинством вещей управляет секс. NovelAI (NAI) представлял собой сервис создания SD-контента, ориентированный на аниме, и его основная модель просочилась в сеть. Большинство изображений аниме-мужчин и женщин, сгенерированных SD, которые вы видите (NSFW или нет), взяты из этой утекшей модели.
В любом случае, он действительно хорош в создании людей, и большинство моделей или LoRA, с которыми вы будете играть, совместимы с ним, поскольку они обучены на аниме-изображениях. Кроме того, люди представляют собой действительно хороший вариант начального использования для точной настройки того, какие LoRA вы хотите использовать в профессиональных целях. Вам придется много устранять неполадки, и большинство руководств посвящены изображениям женщин. Позже мы перейдем к переменным автокодировщикам (VAE), которые придают модели истинный реализм.
- Следуйте руководству по скоростному прохождению NovelAI.
- Вам нужно будет загрузить слитую модель через торрент или найти ее в другом месте.
- Как только вы поместите файлы в папку для веб-интерфейса,
stable-diffusion-webuimodelsStable-diffusion и выберете там модель, вам придется подождать несколько минут, пока CLI загрузит веса VAE.- Если у вас возникли проблемы, скопируйте файл config.yaml из папки, в которой находилась модель, и следуйте той же схеме именования (как в этом руководстве).
- Это важно... Точно воссоздайте образ Аски, обратившись к руководству по устранению неполадок, если оно не совпадает.
- Найдите новые модели SD и LoRA.
- ЦивитАИ
- Обнимающее лицо
- Модели ЦУР
- Модель ЦУР «Материнская нагрузка» (NSFW)
- Материнская нагрузка SDG LoRA (NSFW)
- Множество популярных моделей (а также подсказка из предыдущего раздела) (NSFW)
ЛоРА
Адаптация низкого ранга (LoRA) позволяет выполнить тонкую настройку для данной модели. Дополнительную информацию о LoRA можно найти здесь. В веб-интерфейсе вы можете добавлять LoRA к модели, как вишенку на торте. Обучить новых LoRA также довольно легко. Существуют и другие, «традиционные» средства тонкой настройки (например, текстовая инверсия и гиперсети), но LoRA — это самое современное средство.
- ZTZ99A Tank — военный танк LoRA (конкретный танк)
- Истребители - реактивный истребитель LoRA
- epi_noiseoffset — LoRA, который делает изображения яркими, увеличивает контрастность
На протяжении всего руководства я буду использовать танк LoRA. Обратите внимание, что это не очень хороший LoRA, поскольку он предназначен для изображений в стиле аниме, но с ним можно поиграть.
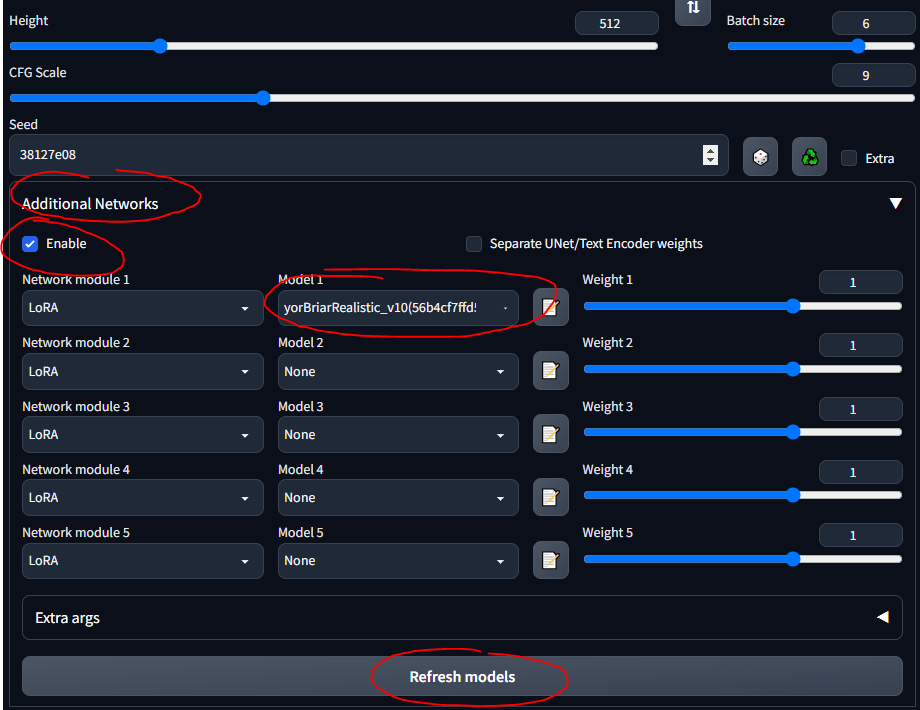
- Следуйте этому краткому руководству, чтобы установить расширение.
- Теперь вы должны увидеть раздел «Дополнительные сети» в пользовательском интерфейсе.
- Поместите свои LoRA в
stable-diffusion-webuiextensionssd-webui-additional-networksmodelslora - Выбирайте и вперед
- УБЕДИТЕСЬ, ЧТО ВЫ ОТМЕТИЛИ «ВКЛЮЧИТЬ»
- Просто знайте, что любой LoRA, который вы загружаете, вероятно, содержит информацию, описывающую, как его использовать… например, «используйте ключевое слово танк» или что-то в этом роде; убедитесь, что где бы вы его ни загружали (например, CivitAI), вы прочитали его описание
Игра с моделями
Опираясь на предыдущий раздел... разные модели имеют разные данные обучения и ключевые слова обучения... поэтому использование тегов booru в некоторых моделях работает не очень хорошо. Ниже приведены некоторые модели, с которыми я играл, и «инструкции» к ним.
SDG Model Motherload, используемая для получения большинства моделей. Здесь я просто суммирую инструкции для быстрого ознакомления; большинство моделей предназначены для настоящего порно, я сосредоточился на реалистичных. Перейдите по ссылкам, чтобы увидеть примеры подсказок, изображения и подробные примечания по использованию каждого из них.
- Модель SD по умолчанию (1.5, начиная с этапа настройки; вы можете играть с версиями SD 2.x, но, честно говоря, они отстой)
- Модель NovelAI (из первого руководства)
- Anything v3 - аниме-модель общего назначения
- Dreamshaper - реализм, универсальный
- Намеренный - реализм, фэнтези, картины, декорации.
- Бесконечная мечта - реализм, фэнтези, хорошо для людей и животных.
- Использует систему тегов booru.
- Epic Diffusion — ультрареализм, призванный заменить оригинальные SD.
- AbyssOrangeMix (AOM) — аниме, реализм, художественность, живопись, крайне распространены и хороши для тестирования.
- Kotosmix - общего назначения, реализм, аниме, декорации, люди, рекомендуется сэмплер DPM++ 2M Karras
CivitAI использовался для получения всех остальных. Вам необходимо создать учетную запись , иначе вы не сможете видеть материалы NSFW, включая оружие и военную технику. В CivitAI некоторые модели (контрольные точки) включают VAE; если там указано это, загрузите его и поместите рядом с моделью.
- ChilloutMix - ультрареализм, портреты, один из самых популярных
- Protogen x3.4 - ультрареализм
- Используйте триггерные слова: стиль modelshoot, аналоговый стиль, стиль mdjrny-v4, nousr robot.
- Dreamlike Photoreal 2.0 — ультрареализм
- Используйте триггерное слово: фотореалистичный.
- Набор инструментов SPYBG для цифровых художников — реализм, концепт-арт
- Используйте триггерные слова: tk-char, tk-env.
VAE
Переменные автоэнкодеры делают изображения лучше, четче и менее размытыми. Некоторые также исправляют руки и лица. Но в основном это вопрос насыщенности и затенения. Объяснено здесь и здесь (NSFW). Обычно используется NovelAI/Anything VAE. По сути, это дополнение к вашей модели, как LoRA.
Найдите VAE в списке VAE:
- NAI / Anything - для аниме-моделей
- По умолчанию поставляется с моделью NAI, когда вы помещаете ее в папку моделей.
- SD 1.5 - для реалистичных моделей
- Загрузите VAE
- Следуйте этому краткому разделу руководства, чтобы настроить VAE в веб-интерфейсе.
- Обязательно поместите их в
stable-diffusion-webuimodelsVAE
- Поэкспериментируйте с созданием изображений с VAE и без него, чтобы увидеть различия.
Соберите все это вместе
Вот некоторые общие заметки и полезные вещи, которые я узнал по пути, которые не обязательно соответствуют хронологическому порядку этого руководства.
Общий процесс SD
Хороший способ научиться — просмотреть крутые изображения на CivitAI, AIbooru или других SD-сайтах (4chan, Reddit и т. д.), открыть то, что вам нравится, и скопировать параметры генерации в WebUI. Полное раскрытие: точно воссоздать изображение не всегда возможно, как описано здесь. Но в целом можно подобраться довольно близко. Чтобы по-настоящему поиграть, установите низкий уровень CFG, чтобы модель могла стать более творческой. Попробуйте партии и отойдите от компьютера, чтобы вернуться к лотам, которые нужно выбрать.
Общий процесс рабочего процесса WebUI:
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
- txt2img — подсказать и получить изображения
- img2img — редактировать изображения и создавать похожие
- inpainting — редактирование частей изображений (об этом позже)
- дополнительно — окончательные правки изображения (обсудим позже)
Сохранение подсказок
Иногда вам хочется вернуться к подсказкам, не вставляя изображения и не записывая их с нуля. Вы можете сохранить подсказки, чтобы повторно использовать их в веб-интерфейсе.
- Напишите положительную и/или отрицательную подсказку
- Под кнопкой «Создать» нажмите кнопку справа, чтобы сохранить свой «стиль».
- Введите имя и сохраните
- Выберите его в любое время, щелкнув раскрывающийся список «Стили».
Настройки txt2img
Этот раздел представляет собой более или менее дайджест информации этого руководства.
- Больше шагов выборки обычно означает большую точность (за исключением пробоотборников «а», таких как Эйлер а, которые время от времени меняются)
- Поиграйте с этим время от времени; в целом, когда он включен, лица действительно выглядят хорошо
- Высокое разрешение. исправление подходит для изображений выше 512x512; полезно, если на изображении более одного человека
- CFG лучше всего работает при значениях ниже среднего, например 5-10.
Восстановление ранее созданного изображения
Для работы с уже существующим изображением, сгенерированным SD; возможно, кто-то прислал вам это, или вы хотите воссоздать созданное вами:
- В веб-интерфейсе перейдите на вкладку «Информация о PNG».
- Перетащите интересующее вас изображение в пользовательский интерфейс.
- Они сохраняются в
stable-diffusion-webuioutputstxt2img-images<date>
- Смотрите используемые параметры справа
- Работает, потому что PNG могут хранить метаданные.
- Отправить его можно прямо на страницу txt2img соответствующей кнопкой
- Возможно, придется проверять взад и вперед, чтобы убедиться, что модель, VAE и другие параметры автоматически заполняются правильно.
Имейте в виду, что некоторые сайты удаляют метаданные PNG при загрузке изображений (например, 4chan), поэтому ищите URL-адреса полных изображений или используйте сайты, которые сохраняют метаданные SD, например CivitAI или AIbooru.
Устранение ошибок
У меня время от времени возникало несколько ошибок. В основном ошибки нехватки памяти (VRAM), которые исправлялись путем снижения значений некоторых параметров. Иногда Восстанавливает лица и нанимает. настройки исправления могут привести к этому. В файле stable-diffusion-webuiwebui-user.bat в строке set COMMANDLINE_ARGS= можно поставить несколько флагов, исправляющих распространенные ошибки.
- Ошибка NaN, что-то вроде «VAE создало что-то NaN», добавьте параметр
--disable-nan-check - Если вы когда-нибудь увидите черные изображения, добавьте
--no-half - Если у вас продолжает не хватать видеопамяти, добавьте
--medvram или для компьютеров с картофелем --lowvram - Исправление Codeformer для восстановления лица здесь (если оно сломается, попробуйте сначала перезагрузить Интернет)
- Медленная загрузка модели (при переключении на новую), вероятно, связана с тем, что файлы .safetensors загружаются медленно, если что-то не настроено должным образом. В этой теме это обсуждается.
Одна действительно распространенная проблема связана с использованием неправильной версии Python или версии Torch. Вы получите такие ошибки, как «невозможно установить Torch» или «Torch не может найти графический процессор». Самое простое исправление:
- Удалите любую версию Python, которую вы обновили, поскольку SD WebUI ожидает версию 3.10.6 (я использовал 3.11.5 и прекрасно проигнорировал ошибку запуска, но 3.10.6, кажется, работает лучше всего) (вы также можете использовать менеджер версий, если хотите ты достаточно продвинутый)
- Установите Python 3.10.6, обязательно добавив его в PATH (как папку
Python , так и папки Python/Scripts ). - Удалите папку
venv из папки stable-diffusion-webui - Запустите
stable-diffusion-webuiwebui-user.bat и дайте ему правильно пересобрать venv. - Наслаждаться
Все аргументы командной строки можно найти здесь.
Как чувствовать себя комфортно
Некоторые расширения могут улучшить использование WebUI. Получите ссылку Github, перейдите на вкладку «Расширения», установите по URL-адресу; при желании на вкладке «Расширения» нажмите «Доступно», затем «Загрузить из», и вы сможете просматривать расширения локально, это отражает расширения вики Github.
- Tag Completer — рекомендует и автоматически заполняет теги booru по мере ввода.
- Стабильное состояние веб-интерфейса Diffusion — сохраняет состояние пользовательского интерфейса даже после перезапуска.
- Test My Prompt — скрипт, который вы можете запустить, чтобы удалить отдельные слова из вашего приглашения, чтобы увидеть, как это повлияет на создание изображения.
- Модель-Ключевое слово — автоматически заполняет ключевые слова, связанные с некоторыми моделями и LoRA, довольно хорошо поддерживается и актуализируется по состоянию на апрель 2023 г.
- NSFW Checker — затемняет изображения NSFW; полезно, если вы работаете в офисе, так как многие хорошие модели поддерживают контент NSFW, и вы, возможно, не захотите видеть его на работе.
- ВНИМАНИЕ: это расширение может испортить отрисовку или даже генерацию, затемняя изображения NSFW (не временно, вместо этого оно буквально выводит черное изображение), поэтому обязательно отключайте его при необходимости.
- Gelbooru Prompt — извлекает теги и создает автоматическое приглашение из любого изображения Gelbooru, используя его хеш.
- booru2prompt — аналог Gelbooru Prompt, но с немного большей функциональностью.
- Динамические подсказки — язык шаблонов для генерации подсказок, который позволяет запускать случайные или комбинаторные подсказки для генерации различных изображений (использует подстановочные знаки).
- Еще кое-что описано здесь
- Набор инструментов для моделей — популярное расширение, которое помогает управлять моделями, редактировать и создавать их.
- Конвертер моделей — полезен для преобразования моделей, изменения точности и т. д., когда вы тренируетесь самостоятельно.
Тестирование
Итак, теперь у вас есть несколько моделей, LoRA и подсказки… как вы можете проверить, что работает лучше всего? Под панелью «Дополнительные сети» находится раскрывающийся список «Сценарий». Здесь нажмите График X/Y/Z. В типе X выберите Имя контрольной точки; в значениях X нажмите кнопку справа, чтобы вставить все ваши модели. В типе Y попробуйте VAE, или, возможно, шкалу семян или CFG. Какой бы атрибут вы ни выбрали, вставьте (или введите) значения, которые хотите отобразить на графике. Например, если у вас есть 5 моделей и 5 VAE, вы создадите сетку из 25 изображений, сравнивая результаты каждой модели с каждым VAE. Это очень универсально и может помочь вам решить, что использовать. Просто имейте в виду, что если ваши оси X или Y являются моделями VAE, необходимо загружать веса модели или VAE для каждой комбинации, поэтому это может занять некоторое время.
Действительно хороший ресурс по сравнению SD можно найти здесь (NSFW). Есть много ссылок, по которым можно перейти. Вы можете начать понимать, как различные модели, VAE, LoRA, значения параметров и т. д. влияют на создание изображений.
Я взял тестовую подсказку отсюда и использовал танк LoRA для создания этой сетки X/Y. Вы можете увидеть, как различные модели и сэмплеры работают друг с другом. Из этого теста мы можем оценить, что:
- Модели ChilloutMix, Deliberate, Dreamlike Photoreal и Epic Diffusion, похоже, создают наиболее «реалистичные» изображения танков.
- В более поздних независимых тестах выяснилось, что Protogen X34 Photorealism и SpyBGs Toolkit тоже неплохо справляются с танками.
- Наиболее многообещающими сэмплерами здесь кажутся DPM++ SDE или любой из сэмплеров Karras.

Точные параметры, использованные (не включая модель или сэмплер) для каждого из этих изображений танка, приведены ниже (опять же взято отсюда):
- Положительная подсказка: танк, bf2042, лучшее качество, шедевр, сверхвысокое разрешение (фотореалистичность: 1,4), детальный скин, кинематографическое освещение, кинематографическая высокодетализированная, красочная, современная фотография, группа солдат на поле боя, повсюду взрывы на поле боя, реактивные истребители. и вертолеты, летящие в небе, два танка на земле, в пустынной местности, горящие здания и один брошенный военный бронетранспортер на заднем плане
- Отрицательная подсказка: обнаженная, (худшее качество: 2), (низкое качество: 2), (нормальное качество: 2), низкое разрешение, плохая анатомия, плохие руки, нормальное качество, ((монохромный)), ((оттенки серого)), свернутое тени для век, несколько ударов для век, розовые волосы, дырки на груди, ng_deepnegative_v1_75t, nsfw, соски,дополнительные пальцы, ((дополнительные руки)), (дополнительные ноги), мутировавшие руки, (сросшиеся пальцы), (слишком много пальцев), (длинная шея: 1,3)
- Шагов: 22
- Масштаб КФГ: 7,5
- Сид: 1656460887
- Размер: 480x480
- Пропуск клипа: 2
- AddNet включен: True, модуль AddNet 1: LoRA, модель AddNet 1: ztz99ATank_ztz99ATank(82a1a1085b2b), вес AddNet A 1: 1, вес AddNet B 1: 1
Веб-интерфейс расширенный
В этом разделе описаны более сложные действия, которые вы можете сделать, как только хорошо освоитесь с использованием моделей, LoRA, VAE, подсказок, параметров, сценариев и расширений на вкладке txt2image веб-интерфейса.
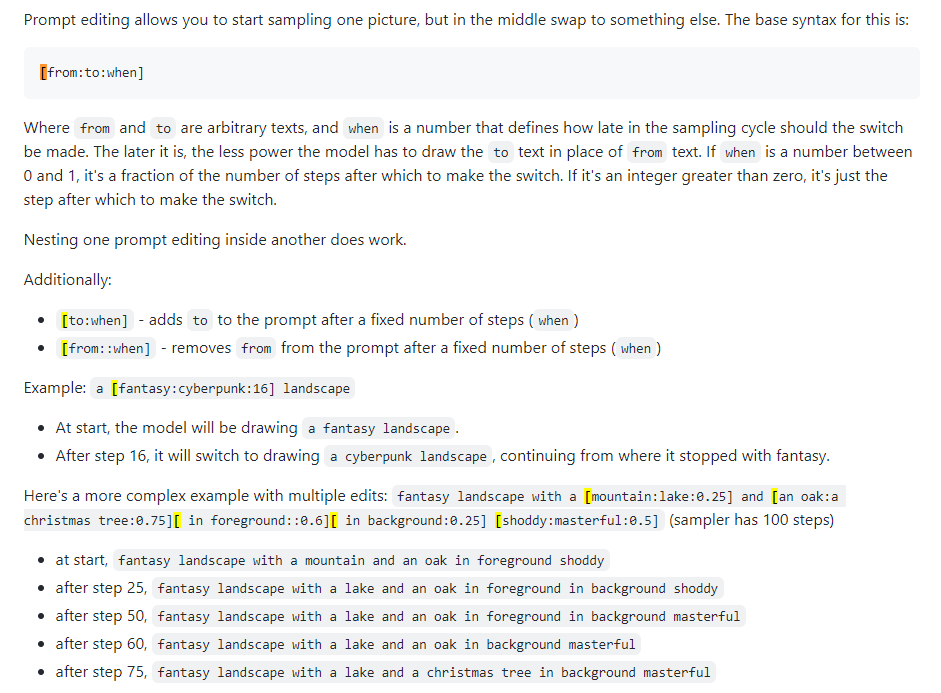
Быстрое редактирование
Также известно как быстрое смешивание. Редактирование подсказки позволяет модели изменять подсказку на определенных шагах. Изображение ниже было взято из поста 4chan и описывает технику. Например, как указано в этом руководстве, быстрое редактирование можно использовать для совмещения лиц.
Иксформеры
Xformers, или слои перекрестного внимания. Способ ускорить генерацию изображений (измеряется в секундах/итерациях или с/ит) на графических процессорах Nvidia, снижает использование видеопамяти, но приводит к недетерминированности. Учитывайте это только в том случае, если у вас мощный графический процессор; реально вам нужен Quadro.
img2img
Не особо много использовал, какая-то запутанная вкладка. Может использоваться для создания изображений по эскизам, как в Huggingface Image to Image SD Playground. Эта вкладка имеет подвкладку inpainting, которая является предметом следующего раздела и является очень важной возможностью веб-интерфейса. Хотя вы можете использовать этот раздел для создания измененных изображений, учитывая то, которое вы уже создали (вывод в stable-diffusion-webuioutputsimg2img-images ), функциональность для меня неоднородна... кажется, он использует безумный объем памяти и Я едва могу заставить его работать. Перейдите к следующему разделу ниже.
живопись
Именно в этом заключается сила создателя контента или кого-то, кто заинтересован в искажении изображений. Вывод находится в stable-diffusion-webuioutputsimg2img-images .
- Руководство по покраске и покраске
- 4chan рисование (NSFW)
- Полное руководство по рисованию
- Возьмите изображение, которое вам нравится, но оно не идеально, что-то не так — его нужно подправить.
- Или создайте его и нажмите «Отправить» в inpaint (все настройки будут заполнены автоматически).
- Теперь вы находитесь на подвкладке img2img -> inpaint.
- Нарисуйте (мышью) на изображении то место, которое вы хотите изменить.
- Установите режим маски на «замаскированный», замаскированный контент — «исходный», а область закрашивания — «только замаскированный».
- В области подсказок вверху напишите новую подсказку, чтобы настроить это место на изображении; сделайте отрицательную подсказку, если хотите
- Создайте изображение (в идеале сделайте партию из 4 или около того)
- Какой бы вариант вам ни понравился, нажмите «Отправить» для рисования и повторяйте, пока не получите готовое изображение.
Перекраска
Перекрашивание – достаточно сложный смысловой процесс. Перерисовка позволяет вам взять изображение и расширить его столько раз, сколько захотите, по сути расширяя его границы. Процесс описан здесь. Вы расширяете изображение только на 64 пикселя за раз. Для этого есть два инструмента пользовательского интерфейса (которые я смог найти):
- Alpha Canvas (встроен в WebUI как расширение/скрипт)
- Hua (веб-приложение для раскрашивания/раскрашивания)
Дополнительно
Эта вкладка WebUI предназначена специально для масштабирования. Если вы получили изображение, которое вам действительно нравится, вы можете повысить его масштаб здесь, в конце рабочего процесса. Масштабированные изображения хранятся в stable-diffusion-webuioutputsextras-images . Некоторые проблемы с памятью, связанные с масштабированием с помощью более мощных средств масштабирования во время генерации на вкладке txt2img (например, 4x+), здесь не возникают, поскольку вы не создаете новые изображения, а масштабируете только статические.
Контрольные сети
Лучший способ понять, что делает ControlNet, — это сказать «рисование на стероидах». Вы даете ему входное изображение (сгенерированное SD или нет), и он может изменить все это. С ControlNets также возможны позы. Вы можете задать эталонную позу человека и создать соответствующие изображения, используя типичную подсказку. Хорошее начало для понимания ControlNets находится здесь.
- Установите расширение ControlNet, sd-webui-controlnet в веб-интерфейсе.
- Обязательно перезагрузите пользовательский интерфейс, нажав кнопку «Обновить пользовательский интерфейс» на вкладке настроек.
- Убедитесь, что кнопка ControlNet теперь находится на вкладке txt2img (и img2img) в разделе «Дополнительные сети» (куда вы помещаете свои LoRA).
- Активация нескольких моделей ControlNet: Настройки -> ControlNet -> ползунок Mutli ControlNet -> 2+
- Перезагрузите пользовательский интерфейс, и в области ControlNet вы увидите несколько вкладок модели.
- Вы можете комбинировать сети ControlNet (например, Canny и OpenPose) так же, как при использовании нескольких LoRA.
- Получите модель ControlNet
- Модели Canny — это модели обнаружения краев; изображения преобразуются в черно-белые изображения по краям, где края примерно сообщают SD, как будет выглядеть ваше изображение.
- Модели OpenPose берут изображение человека и преобразуют его в модель позы для использования в последующих изображениях.
- Там же можно исследовать множество других моделей.
- Давайте возьмем модели Canny и OpenPose.
- Поместите их в
stable-diffusion-webuiextensionssd-webui-controlnetmodels - Получите любое интересующее вас изображение или сгенерируйте новое; здесь я буду использовать изображение танка, которое я создал ранее.

- Настройки в txt2img: метод выборки «DDIM», шаги выборки 20, ширина/высота такая же, как у выбранного изображения.
- Настройки на вкладке ControlNet: установите флажок «Включить», «Препроцессор «Canny», модель «control_canny-fp16», ширина/высота холста такая же, как у выбранного изображения (все остальные настройки по умолчанию).
- Измените свои подсказки и нажмите «Создать»; Я попытался преобразовать изображение моего танка в изображение на Марсе.

- Позитивной подсказкой была: сцена на Марсе, космическое пространство, космос, вселенная, ((галактический космический фон)), звезды, лунная база, футуристический, черный фон, темный фон, звезды на небе, (ночное время) красный песок, ((звезды в фон)) танк, bf2042, Лучшее качество, шедевр, ультра высокое разрешение, (фотореалистичность:1.4), детальный скин, кинематографическое освещение, кинематографичная высокодетализированная, красочная, современная Фотография, группа солдат на поле боя, Взрывы на поле боя повсюду, реактивные истребители и вертолеты летают в небе, два танка на земле, в пустынной местности, горящие здания и одна брошенная военная бронетехника на заднем плане, дерево, лес, небо
- Возьмите изображение с людьми на нем, и вы можете использовать как модель Canny в модели управления - 0, так и модель OpenPose в модели управления - 1, чтобы по-настоящему развлечься.
- Опять же, посмотрите это видео, чтобы по-настоящему углубиться в Canny и OpenPose.
Создание новых вещей
Это все хорошо, но иногда для профессионального использования нужны более качественные модели или LoRA. Поскольку большая часть контента SD буквально предназначена для создания женщин или порно, возможно, потребуется обучение конкретных моделей и LoRA.
- Просматривайте все интересующие темы здесь
- Обучение LoRA
- поезд ЛоРА
- Руководство по обучению ленивому LoRA
- Хорошее учебное пособие по LoRA от CivitAI.
- Еще одно учебное пособие по LoRA
- Более общая информация о LoRA
- Объединение моделей
- Смешивание моделей
Обучение новых моделей
См. раздел DreamBooth.
Слияние контрольно-пропускных пунктов
TODO
Вкладка слияния контрольных точек в веб-интерфейсе позволяет объединить две модели вместе, например, смешивая два соуса в кастрюле, где на выходе получается новый соус, представляющий собой комбинацию обоих из них.
Обучение LoRA
TODO
Обучить LoRA не обязательно сложно, это просто вопрос сбора достаточного количества данных.
Настройка Google Колаб
Это важный шаг, если вам приходится работать вдали от буровой установки. Google Colab Pro стоит 10 долларов в месяц и дает вам 89 ГБ оперативной памяти и доступ к хорошим графическим процессорам, так что вы можете технически запускать подсказки со своего телефона и заставить их работать на вас на сервере в Тимбукту. Если вы не возражаете против дополнительных затрат, Google Colab Pro+ стоит 50 долларов в месяц и даже лучше.
- Перейдите в этот готовый SD Colab.
- Вы можете клонировать его на свой GDrive или просто использовать его в том виде, в каком он есть, чтобы он всегда был самым последним из Github.
- Запустите первые 4 блока кода (займет немного времени)
- Пропустить блок кода ControlNet
- Запустите «Начать стабильную диффузию» (займет немного времени)
- Введите имя пользователя и пароль, если хотите (вероятно, это хорошая идея, поскольку Gradio является общедоступным)
- Нажмите ссылку Gradio («работает по общедоступному URL-адресу»).
- Используйте WebUI как обычно
- Отправьте ссылку на свой телефон, и вы сможете создавать изображения на ходу.
- Чтобы добавлять новые модели и LoRA, у вас должны быть новые папки на вашем Google Диске:
gdrive/MyDrive/sd/stable-diffusion-webui , и из этой базовой папки вы можете использовать ту же структуру папок, которую вы делали на локальном диске. веб-интерфейс- Выполните установку расширения LoRA, как раньше, и структура папок автоматически заполнится, как на рабочем столе.
- Теперь каждый раз, когда вы захотите его использовать, вам просто нужно запустить блок кода «Начать стабильную диффузию» (ничего другого), получить ссылку на градиент, и все готово.
Google Colab всегда бесплатен, и вы можете использовать его вечно, но он может быть немного медленным. Обновление до Colab Pro за 10 долларов в месяц даст вам больше возможностей. Но Colab Pro+ за 50 долларов в месяц — это то, где действительно весело. Pro+ позволяет запускать код в течение 24 часов даже после закрытия вкладки.
TODO Я получаю странную ошибку, которая нарушает мою подписку Pro, когда я устанавливаю в настройках ноутбука типа Runtime -> Runetime класс графического процессора Premium и High-RAM. Это потому, что xFormers не был создан с поддержкой CUDA. Эту проблему можно решить, используя вместо этого TPU или отключив xFormers, но сейчас у меня нет на это терпения. Попробуйте проблемы Colab.
Середина пути
MJ действительно хорош для артистов. Он ВООБЩЕ не такой расширяемый и мощный, как SD в WebUI (NSFW невозможен), но вы можете создавать довольно крутые вещи. Вы можете использовать его бесплатно в MJ Discord (зарегистрируйтесь на их сайте) за несколько подсказок или заплатить 8 долларов в месяц за базовый план, после чего вы сможете использовать его на своем собственном частном сервере. Все команды Discord можно найти здесь и здесь. Структура подсказки для MJ:
/imagine <optional image prompt> <prompt> --parameters
Параметры МДж
Они для MJ V4, в основном такие же и для MJ 5. Здесь описаны все модели.
- --ar 1.2-2.1: соотношение сторон, по умолчанию 1:1.
- --chaos 0-100: вариация, по умолчанию 0
- --нет растений: удаляет растения
- --q 0.0-2.0: время качества рендеринга, по умолчанию — 1
- --seed: семя
- --stop 10-100: остановить задание на полпути, чтобы создать более размытое изображение
- --style 4a/4b/4c: стиль MJ 4'
- --stylize 0-1000: насколько сильно эстетика MJ работает бесплатно, по умолчанию 100
- --uplight: использовать «легкий» апскейлер, изображение менее детализированное
- --upbeta: использовать бета-апскейлер, более близкий к исходному изображению
- --upanime: масштабирование аниме-изображений
- --niji: альтернативная модель аниме-изображений
- --hd: использовать более раннюю модель, которая создает изображения большего размера, подходящие для абстракций и пейзажей.
- -Тест: используйте специальную тестовую модель MJ
- -testp: используйте специальную тестовую модель, ориентированную на фотографию MJ
- -Tile: только для MJ 5, генерирует повторяющееся изображение
- Утомительная проверка изображений
- --v 1/2/3/4/5: какая версия MJ использовать (5 лучше)
MJ Advanced подсказки
- Вы можете ввести изображение (или изображения) в начало подсказки, чтобы повлиять на его стиль и цвета. Смотрите этот док. Загрузите изображение на свой сервер Discord и щелкните правой кнопкой мыши, чтобы получить ссылку.
- РЕМЕРКА ПОЛУЧИТЬ ВАШИХ вариантов изображения, изменения моделей, субъектов или среды. Смотрите этот док.
- Multi подсказки дайте MJ рассмотреть две или более отдельных концепций индивидуально. MJ версии 1-4 и только Niji. Например, «хот -дог» сделает изображения еды, «Hot :: Dog» сделает изображения теплой собаки. Вы также можете добавить веса к подсказкам; Например, «Hot :: 2 собака» сделает изображения собак в огне. MJ 1/2/3 принимает целочисленные веса, MJ 4 может принять десятичные десятички. Смотрите этот док.
- Смешивание позволяет загружать 2-5 изображений, чтобы объединить их в новое изображение. Команда /Blend описана здесь.
DreamStudio
TODO
Dreamstudio (не Dreambooth) - флагманская платформа из компании AI Stability. Их сайт - это платформа, Dreambooth Studio, с которой вы можете генерировать изображения. Это вроде как находится между Миджурни и Webui с точки зрения открытой функциональности. Студия Dreambooth, кажется, построена на платформе invoke.ai, которую вы можете установить и работать локально, как Webui.
Стабильная орда
TODO
Стабильная орда - это усилия по сообществу, чтобы сделать стабильную диффузию свободным для всех. По сути, он работает как торрентование или биткойн -хэшинг, где каждый вносит вклад в свою мощность графического процессора для создания содержания SD. Приложение для орды можно получить здесь.
Dreambooth
TODO
Dreambooth (не Dreamstudio) была реализацией Google стабильной диффузионной модели точной настройки. Короче говоря: вы можете использовать его для обучения моделей с собственными фотографиями. Вы можете использовать его прямо отсюда или здесь. Это сложнее, чем просто загрузка моделей и щелчок в WebUI, поскольку вы работаете над тем, чтобы фактически обучить и сериализовать новую модель. Некоторые видео подводят краткое изложение, как это сделать:
- Dreambooth Easy Учебное пособие
- Dreambooth 10 -минутная тренировка
- Webui Dreambooth расширение
И несколько хороших гидов:
- Reddit Advanced Dreambooth совет
- Простая мечта
- Dreambooth Damp (много информации, прокручивать ссылки)
Google Colab для Dreambooth:
- Thelastben Dreambooth Training Colab (тот же автор, что и SD Colab, описанный в настройке Google Colab)
Существует также модельный тренер под названием Wansdream. Полное сравнение между Dreambooth и Wanndream можно найти здесь.
Видео диффузия
TODO
По состоянию на март 2023 года возможно использовать стабильную диффузию для генерации видео. В настоящее время (апрель 2023 г.) функциональность довольно упрощена, так как видео генерируются из аналогичных изображений, кадр за кадром, придавая видео своего рода «Flipbook». Есть два основных расширения для WebUI, которые вы можете использовать:
- Аниматор - легче
- Deforum - больше функциональности
Свояшник
Вещи, о которых я мало знаю, но мне нужно изучить
Существует процесс, который вы можете следовать, чтобы получить хорошие результаты снова и снова ... это будет уточнено с течением времени.
- TODO
- Highres Fix, здесь
- oppling, повсюду, но здесь в основном
Интеграция CATGPT?
Отель
Далл-е 2
Deforum https://deforum.github.io/


