Machine Learning Guide
1.0.0
Примечание. Вы можете легко преобразовать этот файл уценки в PDF в VSCode, используя это удобное расширение Markdown PDF.

Платформы машинного обучения/глубокого обучения.
Учебные ресурсы по машинному обучению
Платформы, библиотеки и инструменты машинного обучения
Алгоритмы
Разработка PyTorch
Разработка TensorFlow
Основная разработка машинного обучения
Развитие глубокого обучения
Развитие обучения с подкреплением
Разработка компьютерного зрения
Развитие обработки естественного языка (NLP)
Биоинформатика
Разработка CUDA
МАТЛАБ Разработка
Разработка на C/C++
Java-разработка
Разработка Python
Скала Разработка
Р Девелопмент
Юлия Девелопмент
Вернуться к началу
Машинное обучение — это отрасль искусственного интеллекта (ИИ), ориентированная на создание приложений с использованием алгоритмов, которые обучаются на основе моделей данных и со временем повышают их точность без необходимости программирования.

Вернуться к началу
Рекомендации по обработке естественного языка (NLP) от Microsoft
Книга рецептов автономного вождения от Microsoft
Машинное обучение Azure — машинное обучение как услуга | Microsoft Azure
Как запустить Jupyter Notebooks в рабочей области машинного обучения Azure
Машинное обучение и искусственный интеллект | Веб-сервисы Amazon
Планирование блокнотов Jupyter на эфемерных экземплярах Amazon SageMaker
ИИ и машинное обучение | Google Облако
Использование ноутбуков Jupyter с Apache Spark в Google Cloud
Машинное обучение | Apple Разработчик
Искусственный интеллект и автопилот | Тесла
Мета-инструменты искусственного интеллекта | Фейсбук
Учебники по PyTorch
Учебные пособия по TensorFlow
ЮпитерЛаб
Стабильная диффузия с Core ML на Apple Silicon
Вернуться к началу
Машинное обучение, Стэнфордский университет, Эндрю Нг | Курсера
Обучение и сертификация AWS для курсов машинного обучения (ML)
Стипендиальная программа машинного обучения для Microsoft Azure | Удасити
Сертифицирован Microsoft: научный сотрудник Azure Data Scientist.
Сертифицирован Microsoft: младший инженер Azure AI.
Обучение и развертывание машинного обучения Azure
Обучение Машинное обучение и искусственный интеллект от Google Cloud Training
Ускоренный курс машинного обучения для Google Cloud
Онлайн-курсы машинного обучения | Удеми
Онлайн-курсы машинного обучения | Курсера
Изучите машинное обучение с помощью онлайн-курсов и классов | edX
Вернуться к началу
Введение в машинное обучение (PDF)
Искусственный интеллект: современный подход Стюарт Дж. Рассел и Питер Норвиг
«Глубокое обучение», Ян Гудфеллоу, Йошуа Бенджио и Аарон Курвиль
Стостраничная книга по машинному обучению Андрея Буркова
Машинное обучение Тома М. Митчелла
Программирование коллективного разума: создание приложений Smart Web 2.0 Тоби Сегаран
Машинное обучение: алгоритмическая перспектива, второе издание
Распознавание образов и машинное обучение, Кристофер М. Бишоп
Обработка естественного языка с помощью Python Стивен Берд, Юэн Кляйн и Эдвард Лопер
Машинное обучение Python: технический подход к машинному обучению для начинающих Леонарда Эддисона
Байесовское рассуждение и машинное обучение Дэвида Барбера
Машинное обучение для начинающих: простое введение на английском языке, Оливер Теобальд
Машинное обучение в действии, Бен Уилсон
Практическое машинное обучение с помощью Scikit-Learn, Keras и TensorFlow: концепции, инструменты и методы для создания интеллектуальных систем, Орельен Жерон
Введение в машинное обучение с помощью Python: Руководство для специалистов по данным, Андреас К. Мюллер и Сара Гвидо
Машинное обучение для хакеров: тематические исследования и алгоритмы, которые помогут вам начать работу, Дрю Конвей и Джон Майлз Уайт
«Элементы статистического обучения: интеллектуальный анализ данных, логический вывод и прогнозирование», Тревор Хасти, Роберт Тибширани и Джером Фридман
Распределенные шаблоны машинного обучения — Книга (читать бесплатно онлайн) + Код
Машинное обучение в реальном мире [Бесплатные главы]
Введение в статистическое обучение — Книга + R Code
Элементы статистического обучения - Книга
Думайте по Байесу — Книга + Код Python
Анализ огромных наборов данных
Первое знакомство с машинным обучением
Введение в машинное обучение — Алекс Смола и СВН Вишванатан
Вероятностная теория распознавания образов
Введение в поиск информации
Прогнозирование: принципы и практика
Введение в машинное обучение - Амнон Шашуа
Обучение с подкреплением
Машинное обучение
В поисках ИИ
Программирование на R для науки о данных
Интеллектуальный анализ данных — практические инструменты и методы машинного обучения
Машинное обучение с TensorFlow
Системы машинного обучения
Основы машинного обучения - Мехриар Мори, Афшин Ростамизаде и Амит Талвалкар
Поиск на базе искусственного интеллекта — Трей Грейнджер, Дуг Тернбулл, Макс Ирвин —
Ансамблевые методы машинного обучения - Гаутам Кунапули
Машинное обучение в действии - Бен Уилсон
Машинное обучение с сохранением конфиденциальности - Дж. Моррис Чанг, Ди Чжуан, Г. Думинду Самаравира
Автоматизированное машинное обучение в действии – Цинцюань Сун, Хайфэн Цзинь и Ся Ху
Шаблоны распределенного машинного обучения — Юань Тан
Управление проектами машинного обучения: от проектирования до развертывания - Саймон Томпсон
Причинное машинное обучение — Роберт Несс
Байесовская оптимизация в действии - Куан Нгуен
Подробно об алгоритмах машинного обучения) - Вадим Смоляков
Алгоритмы оптимизации - Алаа Хамис
Практическое повышение градиента от Гийома Сопена
Вернуться к началу
Вернуться к началу
TensorFlow — это комплексная платформа с открытым исходным кодом для машинного обучения. Он имеет комплексную, гибкую экосистему инструментов, библиотек и ресурсов сообщества, которая позволяет исследователям внедрять новейшие достижения в области машинного обучения, а разработчикам легко создавать и развертывать приложения на основе машинного обучения.
Keras — это API нейронных сетей высокого уровня, написанный на Python и способный работать поверх TensorFlow, CNTK или Theano. Он был разработан с упором на возможность быстрого экспериментирования. Он может работать поверх TensorFlow, Microsoft Cognitive Toolkit, R, Theano или PlaidML.
PyTorch — это библиотека для глубокого изучения нерегулярных входных данных, таких как графики, облака точек и многообразия. Первоначально разработан исследовательской лабораторией искусственного интеллекта Facebook.
Amazon SageMaker — это полностью управляемый сервис, который предоставляет каждому разработчику и специалисту по данным возможность быстро создавать, обучать и развертывать модели машинного обучения (ML). SageMaker устраняет тяжелую работу на каждом этапе процесса машинного обучения, упрощая разработку высококачественных моделей.
Azure Databricks — это быстрая служба анализа больших данных на базе Apache Spark для совместной работы, предназначенная для анализа и проектирования данных. Azure Databricks позволяет за считанные минуты настроить среду Apache Spark, выполнить автоматическое масштабирование и совместно работать над общими проектами в интерактивной рабочей области. Azure Databricks поддерживает Python, Scala, R, Java и SQL, а также платформы и библиотеки для обработки данных, включая TensorFlow, PyTorch и scikit-learn.
Microsoft Cognitive Toolkit (CNTK) — это набор инструментов с открытым исходным кодом для распределенного глубокого обучения коммерческого уровня. Он описывает нейронные сети как серию вычислительных шагов через ориентированный граф. CNTK позволяет пользователю легко реализовывать и комбинировать популярные типы моделей, такие как DNN с прямой связью, сверточные нейронные сети (CNN) и рекуррентные нейронные сети (RNN/LSTM). CNTK реализует обучение стохастическому градиентному спуску (SGD, обратное распространение ошибки) с автоматической дифференциацией и распараллеливанием на нескольких графических процессорах и серверах.
Apple CoreML — это платформа, которая помогает интегрировать модели машинного обучения в ваше приложение. Core ML обеспечивает единое представление для всех моделей. Ваше приложение использует API-интерфейсы Core ML и пользовательские данные для прогнозирования, а также для обучения или точной настройки моделей — и все это на устройстве пользователя. Модель — это результат применения алгоритма машинного обучения к набору обучающих данных. Вы используете модель, чтобы делать прогнозы на основе новых входных данных.
Apache OpenNLP — это библиотека с открытым исходным кодом для набора инструментов на основе машинного обучения, используемого при обработке текста на естественном языке. Он имеет API для таких вариантов использования, как распознавание именованных объектов, обнаружение предложений, тегирование POS (части речи), извлечение функций токенизации, группирование, синтаксический анализ и разрешение корреляций.
Apache Airflow — это платформа управления рабочими процессами с открытым исходным кодом, созданная сообществом для программного создания, планирования и мониторинга рабочих процессов. Установить. Принципы. Масштабируемый. Airflow имеет модульную архитектуру и использует очередь сообщений для управления произвольным количеством рабочих процессов. Воздушный поток готов масштабироваться до бесконечности.
Open Neural Network Exchange (ONNX) — это открытая экосистема, которая позволяет разработчикам ИИ выбирать правильные инструменты по мере развития их проекта. ONNX предоставляет формат с открытым исходным кодом для моделей искусственного интеллекта, как глубокого обучения, так и традиционного машинного обучения. Он определяет расширяемую модель вычислительного графа, а также определения встроенных операторов и стандартных типов данных.
Apache MXNet — это платформа глубокого обучения, разработанная для обеспечения эффективности и гибкости. Это позволяет вам сочетать символическое и императивное программирование для максимизации эффективности и производительности. По своей сути MXNet содержит планировщик динамических зависимостей, который автоматически распараллеливает как символические, так и императивные операции на лету. Уровень оптимизации графа поверх этого обеспечивает быстрое символьное выполнение и эффективное использование памяти. MXNet портативен и легок, эффективно масштабируется до нескольких графических процессоров и нескольких компьютеров. Поддержка Python, R, Julia, Scala, Go, Javascript и других языков.
AutoGluon — это набор инструментов для глубокого обучения, который автоматизирует задачи машинного обучения, позволяя вам легко добиться высокой производительности прогнозирования в ваших приложениях. Всего с помощью нескольких строк кода вы можете обучить и развернуть высокоточные модели глубокого обучения на табличных, графических и текстовых данных.
Anaconda — очень популярная платформа Data Science для машинного и глубокого обучения, которая позволяет пользователям разрабатывать модели, обучать их и развертывать.
PlaidML — это усовершенствованный портативный тензорный компилятор, позволяющий осуществлять глубокое обучение на ноутбуках, встроенных устройствах и других устройствах, где доступное вычислительное оборудование недостаточно поддерживается или доступный стек программного обеспечения содержит неприятные лицензионные ограничения.
OpenCV — это высокооптимизированная библиотека, ориентированная на приложения компьютерного зрения в реальном времени. Интерфейсы C++, Python и Java поддерживают Linux, MacOS, Windows, iOS и Android.
Scikit-Learn — это модуль Python для машинного обучения, созданный на основе SciPy, NumPy и matplotlib, упрощающий применение надежных и простых реализаций многих популярных алгоритмов машинного обучения.
Weka — это программное обеспечение для машинного обучения с открытым исходным кодом, доступ к которому можно получить через графический интерфейс пользователя, стандартные терминальные приложения или API Java. Он широко используется для преподавания, исследований и промышленных приложений, содержит множество встроенных инструментов для стандартных задач машинного обучения, а также предоставляет прозрачный доступ к известным наборам инструментов, таким как scikit-learn, R и Deeplearning4j.
Caffe — это среда глубокого обучения, созданная с учетом экспрессии, скорости и модульности. Он разработан Berkeley AI Research (BAIR)/Центром видения и обучения Беркли (BVLC) и участниками сообщества.
Theano — это библиотека Python, которая позволяет эффективно определять, оптимизировать и оценивать математические выражения, включающие многомерные массивы, включая тесную интеграцию с NumPy.
nGraph — это библиотека C++ с открытым исходным кодом, компилятор и среда выполнения для глубокого обучения. Компилятор nGraph предназначен для ускорения разработки рабочих нагрузок ИИ с использованием любой среды глубокого обучения и развертывания на различных аппаратных объектах. Он обеспечивает свободу, производительность и простоту использования разработчикам ИИ.
NVIDIA cuDNN — это библиотека примитивов с графическим ускорением для глубоких нейронных сетей. cuDNN предоставляет тщательно настроенные реализации для стандартных процедур, таких как прямая и обратная свертка, объединение в пул, уровни нормализации и активации. cuDNN ускоряет широко используемые платформы глубокого обучения, включая Caffe2, Chainer, Keras, MATLAB, MxNet, PyTorch и TensorFlow.
Huginn — это автономная система для создания агентов, выполняющих за вас автоматизированные задачи в Интернете. Он может читать Интернет, следить за событиями и предпринимать действия от вашего имени. Агенты Хьюгинна создают и потребляют события, распространяя их по ориентированному графу. Думайте об этом как о взломанной версии IFTTT или Zapier на вашем собственном сервере.
Netron — средство просмотра моделей нейронных сетей, глубокого обучения и машинного обучения. Он поддерживает ONNX, TensorFlow Lite, Caffe, Keras, Darknet, PaddlePaddle, ncnn, MNN, Core ML, RKNN, MXNet, MindSpore Lite, TNN, Barracuda, Tengine, CNTK, TensorFlow.js, Caffe2 и UFF.
Дофамин — это исследовательская основа для быстрого прототипирования алгоритмов обучения с подкреплением.
DALI — это библиотека с ускорением на графическом процессоре, содержащая высокооптимизированные строительные блоки и механизм выполнения для обработки данных для ускорения обучения глубокому обучению и приложений вывода.
MindSpore Lite — это новая платформа для обучения/выводов глубокого обучения с открытым исходным кодом, которую можно использовать для мобильных, периферийных и облачных сценариев.
Darknet — это платформа нейронных сетей с открытым исходным кодом, написанная на C и CUDA. Он быстрый, простой в установке и поддерживает вычисления на процессоре и графическом процессоре.
PaddlePaddle — это простая в использовании, эффективная, гибкая и масштабируемая платформа глубокого обучения, изначально разработанная учеными и инженерами Baidu с целью применения глубокого обучения ко многим продуктам Baidu.
GoogleNotebookLM — это экспериментальный инструмент искусственного интеллекта, использующий возможности языковых моделей в сочетании с существующим контентом для более быстрого получения важной информации. Похоже на виртуального научного сотрудника, который может обобщать факты, объяснять сложные идеи и проводить мозговой штурм новых связей на основе выбранных вами источников.
Unilm — это крупномасштабное предварительное обучение с самоконтролем по задачам, языкам и модальностям.
Семантическое ядро (SK) — это легкий SDK, позволяющий интегрировать модели большого языка искусственного интеллекта (LLM) с традиционными языками программирования. Расширяемая модель программирования SK сочетает в себе семантические функции естественного языка, традиционные собственные функции кода и встроенную память, раскрывающую новый потенциал и повышающую ценность приложений с искусственным интеллектом.
Pandas AI — это библиотека Python, которая интегрирует возможности генеративного искусственного интеллекта в Pandas, делая фреймы данных диалоговыми.
NCNN — это высокопроизводительная среда вывода нейронных сетей, оптимизированная для мобильной платформы.
MNN — это невероятно быстрая и легкая платформа глубокого обучения, проверенная в критически важных для бизнеса сценариях использования в Alibaba.
MediaPipe оптимизирован для обеспечения сквозной производительности на широком спектре платформ. Посмотреть демо-версии Узнать больше Сложное машинное обучение на устройстве, упрощенное Мы абстрагировались от сложностей, связанных с созданием настраиваемого, готового к использованию и доступного для разных платформ машинного обучения на устройстве.
MegEngine — это быстрая, масштабируемая и удобная для пользователя среда глубокого обучения с тремя ключевыми функциями: Единая платформа для обучения и вывода.
ML.NET — это библиотека машинного обучения, спроектированная как расширяемая платформа, позволяющая использовать другие популярные платформы машинного обучения (TensorFlow, ONNX, Infer.NET и т. д.) и иметь доступ к еще большему количеству сценариев машинного обучения, таких как классификация изображений, обнаружение объектов и многое другое.
Ludwig — это декларативная среда машинного обучения, которая позволяет легко определять конвейеры машинного обучения с помощью простой и гибкой системы конфигурации, управляемой данными.
MMdnn — это комплексный межплатформенный инструмент для преобразования, визуализации и диагностики моделей глубокого обучения (DL). «ММ» означает управление моделями, а «dnn» — аббревиатура глубокой нейронной сети. Преобразование моделей между Caffe, Keras, MXNet, Tensorflow, CNTK, PyTorch Onnx и CoreML.
Horovod — это распределенная платформа обучения глубокому обучению для TensorFlow, Keras, PyTorch и Apache MXNet.
Vaex — это высокопроизводительная библиотека Python для ленивых внешних фреймов данных (аналог Pandas) для визуализации и исследования больших наборов табличных данных.
GluonTS — это пакет Python для вероятностного моделирования временных рядов, ориентированный на модели глубокого обучения на основе PyTorch и MXNet.
MindsDB — это сервер ML-SQL, обеспечивающий рабочие процессы машинного обучения для самых мощных баз данных и хранилищ данных с использованием SQL.
Jupyter Notebook — это веб-приложение с открытым исходным кодом, которое позволяет создавать и обмениваться документами, содержащими живой код, уравнения, визуализации и описательный текст. Jupyter широко используется в отраслях, которые занимаются очисткой и преобразованием данных, численным моделированием, статистическим моделированием, визуализацией данных, наукой о данных и машинным обучением.
Apache Spark — это унифицированная аналитическая система для крупномасштабной обработки данных. Он предоставляет API-интерфейсы высокого уровня на Scala, Java, Python и R, а также оптимизированный механизм, поддерживающий общие графы вычислений для анализа данных. Он также поддерживает богатый набор инструментов более высокого уровня, включая Spark SQL для SQL и DataFrames, MLlib для машинного обучения, GraphX для обработки графов и Structured Streaming для потоковой обработки.
Соединитель Apache Spark для SQL Server и Azure SQL — это высокопроизводительный соединитель, который позволяет использовать данные транзакций в анализе больших данных и сохранять результаты для специальных запросов или отчетов. Соединитель позволяет использовать любую базу данных SQL, локальную или в облаке, в качестве источника входных данных или приемника выходных данных для заданий Spark.
Apache PredictionIO — это платформа машинного обучения с открытым исходным кодом для разработчиков, специалистов по обработке данных и конечных пользователей. Он поддерживает сбор событий, развертывание алгоритмов, оценку, запрос прогнозируемых результатов через API REST. Он основан на масштабируемых сервисах с открытым исходным кодом, таких как Hadoop, HBase (и другие базы данных), Elasticsearch, Spark, и реализует так называемую архитектуру Lambda.
Менеджер кластеров для Apache Kafka (CMAK) — это инструмент для управления кластерами Apache Kafka.
BigDL — это распределенная библиотека глубокого обучения для Apache Spark. С помощью BigDL пользователи могут писать свои приложения глубокого обучения как стандартные программы Spark, которые могут работать непосредственно поверх существующих кластеров Spark или Hadoop.
Eclipse Deeplearning4J (DL4J) — это набор проектов, предназначенных для поддержки всех потребностей приложений глубокого обучения на основе JVM (Scala, Kotlin, Clojure и Groovy). Это означает, что нужно начинать с необработанных данных, загружать и предварительно обрабатывать их из любого места и в любом формате, а затем создавать и настраивать широкий спектр простых и сложных сетей глубокого обучения.
Tensorman — это утилита для простого управления контейнерами Tensorflow, разработанная System76. Tensorman позволяет Tensorflow работать в изолированной среде, изолированной от остальной части системы. Эта виртуальная среда может работать независимо от базовой системы, что позволяет вам использовать любую версию Tensorflow в любой версии дистрибутива Linux, поддерживающего среду выполнения Docker.
Numba — это оптимизирующий компилятор для Python с открытым исходным кодом, поддерживающий NumPy, спонсируемый Anaconda, Inc. Он использует проект компилятора LLVM для генерации машинного кода из синтаксиса Python. Numba может скомпилировать большое подмножество Python с числовым подходом, включая множество функций NumPy. Кроме того, Numba поддерживает автоматическое распараллеливание циклов, генерацию кода с ускорением на графическом процессоре, а также создание ufuncs и обратных вызовов C.
Chainer — это платформа глубокого обучения на основе Python, нацеленная на гибкость. Он предоставляет API-интерфейсы автоматического дифференцирования на основе подхода «Определение за запуском» (динамические вычислительные графы), а также объектно-ориентированные API-интерфейсы высокого уровня для построения и обучения нейронных сетей. Он также поддерживает CUDA/cuDNN с использованием CuPy для высокопроизводительного обучения и вывода.
XGBoost — это оптимизированная распределенная библиотека повышения градиента, разработанная для обеспечения высокой эффективности, гибкости и портативности. Он реализует алгоритмы машинного обучения в рамках платформы Gradient Boosting. XGBoost обеспечивает параллельное повышение уровня дерева (также известное как GBDT, GBM), которое позволяет быстро и точно решить многие проблемы обработки данных. Он поддерживает распределенное обучение на нескольких машинах, включая кластеры AWS, GCE, Azure и Yarn. Кроме того, его можно интегрировать с Flink, Spark и другими облачными системами управления потоками данных.
cuML — это набор библиотек, реализующих алгоритмы машинного обучения и функции математических примитивов, которые используют совместимые API с другими проектами RAPIDS. cuML позволяет ученым, исследователям и разработчикам программного обеспечения выполнять традиционные табличные задачи машинного обучения на графических процессорах, не вдаваясь в подробности программирования CUDA. В большинстве случаев API Python cuML соответствует API из scikit-learn.
Emu — это библиотека GPGPU для Rust, ориентированная на портативность, модульность и производительность. Это специфическая для вычислений абстракция в стиле CUDA над WebGPU, обеспечивающая особую функциональность, благодаря которой WebGPU больше похож на CUDA.
Scalene — это высокопроизводительный профилировщик ЦП, графического процессора и памяти для Python, который делает ряд вещей, которые другие профилировщики Python не делают и не могут сделать. Он работает на несколько порядков быстрее, чем многие другие профилировщики, предоставляя при этом гораздо более подробную информацию.
MLpack — это быстрая и гибкая библиотека машинного обучения C++, написанная на C++ и построенная на основе библиотеки линейной алгебры Armadillo, библиотеки цифровой оптимизации Ensmallen и частей Boost.
Netron — средство просмотра моделей нейронных сетей, глубокого обучения и машинного обучения. Он поддерживает ONNX, TensorFlow Lite, Caffe, Keras, Darknet, PaddlePaddle, ncnn, MNN, Core ML, RKNN, MXNet, MindSpore Lite, TNN, Barracuda, Tengine, CNTK, TensorFlow.js, Caffe2 и UFF.
Lightning — это инструмент, который создает и обучает модели PyTorch и подключает их к жизненному циклу машинного обучения с помощью шаблонов приложений Lightning, не занимаясь инфраструктурой DIY, управлением затратами, масштабированием и т. д.
OpenNN — это библиотека нейронных сетей с открытым исходным кодом для машинного обучения. Он содержит сложные алгоритмы и утилиты для работы со многими решениями искусственного интеллекта.
H20 — это облачная платформа искусственного интеллекта, которая решает сложные бизнес-задачи и ускоряет поиск новых идей с результатами, которые вы можете понять и которым можно доверять.
Gensim — это библиотека Python для тематического моделирования, индексирования документов и поиска сходства с большими корпусами. Целевая аудитория — сообщество специалистов по обработке естественного языка (NLP) и поиску информации (IR).
llama.cpp — это порт модели LLaMA Facebook на C/C++.
hmmlearn — это набор алгоритмов для обучения без учителя и вывода скрытых марковских моделей.
Nextjournal — это блокнот для воспроизводимых исследований. Он запускает все, что вы можете поместить в контейнер Docker. Улучшите свой рабочий процесс с помощью многоязычных блокнотов, автоматического управления версиями и совместной работы в режиме реального времени. Экономьте время и деньги благодаря предоставлению ресурсов по требованию, включая поддержку графических процессоров.
IPython предоставляет богатую архитектуру для интерактивных вычислений, включающую:
Veles — это распределенная платформа для быстрой разработки приложений глубокого обучения, разрабатываемая в настоящее время компанией Samsung.
DyNet — это библиотека нейронных сетей, разработанная Университетом Карнеги-Меллон и многими другими. Он написан на C++ (с привязками на Python) и предназначен для эффективной работы как на ЦП, так и на графическом процессоре, а также для хорошей работы с сетями с динамическими структурами, которые изменяются для каждого экземпляра обучения. Сети такого типа особенно важны для задач обработки естественного языка, и DyNet использовался для создания современных систем синтаксического анализа, машинного перевода, морфологической флексии и многих других областей применения.
Ray — это единая платформа для масштабирования приложений AI и Python. Он состоит из базовой распределенной среды выполнения и набора библиотек (Ray AIR) для ускорения рабочих нагрузок машинного обучения.
Whisper.cpp — это высокопроизводительный вывод модели автоматического распознавания речи (ASR) OpenAI Whisper.
ChatGPT Plus — это пилотный план подписки ( 20 долларов США в месяц ) для ChatGPT, диалогового ИИ, который может общаться с вами, отвечать на дополнительные вопросы и оспаривать неверные предположения.
Auto-GPT — это «агент искусственного интеллекта», который, если задать цель на естественном языке, может попытаться достичь ее, разбив ее на подзадачи и используя Интернет и другие инструменты в автоматическом цикле. Он использует API-интерфейсы OpenAI GPT-4 или GPT-3.5 и является одним из первых примеров приложения, использующего GPT-4 для выполнения автономных задач.
Пользовательский интерфейс чат-бота от mckaywrigley — это расширенный набор чат-ботов для моделей чата OpenAI, созданный на основе Chatbot UI Lite с использованием Next.js, TypeScript и Tailwind CSS. Эта версия пользовательского интерфейса ChatBot поддерживает модели GPT-3.5 и GPT-4. Разговоры сохраняются локально в вашем браузере. Вы можете экспортировать и импортировать разговоры, чтобы защититься от потери данных. Посмотрите демо.
Chatbot UI Lite от mckaywrigley — это простой стартовый набор чат-бота для модели чата OpenAI с использованием Next.js, TypeScript и Tailwind CSS. Посмотрите демо.
MiniGPT-4 — это улучшение понимания языка с помощью расширенных моделей большого языка.
GPT4All — это экосистема чат-ботов с открытым исходным кодом, обученная на огромных коллекциях чистых данных помощников, включая код, истории и диалоги, на основе LLaMa.
GPT4All UI — это веб-приложение Flask, предоставляющее пользовательский интерфейс чата для взаимодействия с чат-ботом GPT4All.
Alpaca.cpp — это быстрая модель, похожая на ChatGPT, локально на вашем устройстве. Он сочетает в себе базовую модель LLaMA с открытой репродукцией Stanford Alpaca, тонкой настройкой базовой модели для выполнения инструкций (сродни RLHF, используемой для обучения ChatGPT) и набором модификаций llama.cpp для добавления интерфейса чата.
llama.cpp — это порт модели LLaMA Facebook на C/C++.
OpenPlayground — это площадка для локального запуска моделей, подобных ChatGPT, на вашем устройстве.
Vicuna — это чат-бот с открытым исходным кодом, обученный с помощью тонкой настройки LLaMA. Судя по всему, он обеспечивает качество чатгпта более 90%, а его обучение стоит 300 долларов.
Yeagar ai — это программа для создания агентов Langchain, призванная помочь вам с легкостью создавать, создавать прототипы и развертывать агенты на базе искусственного интеллекта.
Vicuna создается путем тонкой настройки базовой модели LLaMA с использованием примерно 70 тысяч общих разговоров пользователей, собранных на ShareGPT.com с общедоступными API. Чтобы обеспечить качество данных, он преобразует HTML обратно в уценку и отфильтровывает некоторые неподходящие или некачественные образцы.
ShareGPT — это место, где можно одним щелчком мыши поделиться своими самыми дикими разговорами в ChatGPT. На данный момент опубликовано 198 404 беседы.
FastChat — это открытая платформа для обучения, обслуживания и оценки чат-ботов на основе больших языковых моделей.
Haystack — это платформа НЛП с открытым исходным кодом для взаимодействия с вашими данными с использованием моделей Transformer и LLM (GPT-4, ChatGPT и т. п.). Он предлагает готовые к использованию инструменты для быстрого создания сложных решений, ответов на вопросы, семантического поиска, приложений для генерации текста и многого другого.
StableLM (Stability AI Language Models) — это серия языковых моделей StableLM, которая будет постоянно обновляться новыми контрольными точками.
Dolly от Databricks — это большая языковая модель, основанная на инструкциях, обученная на платформе машинного обучения Databricks, которая лицензирована для коммерческого использования.
GPTCach — это библиотека для создания семантического кэша для запросов LLM.
AlaC — это инфраструктура искусственного интеллекта как генератор кода.
Adrenaline — это инструмент, который позволяет вам общаться с вашей кодовой базой. Он основан на статическом анализе, векторном поиске и больших языковых моделях.
OpenAssistant — это помощник на основе чата, который понимает задачи, может взаимодействовать со сторонними системами и для этого динамически получать информацию.
DoctorGPT — это легкий автономный двоичный файл, который отслеживает журналы приложений на наличие проблем и диагностирует их.
HttpGPT — это плагин Unreal Engine 5, который облегчает интеграцию со службами OpenAI на основе GPT (ChatGPT и DALL-E) посредством асинхронных запросов REST, упрощая разработчикам взаимодействие с этими службами. Он также включает инструменты редактора для интеграции Chat GPT и создания изображений DALL-E непосредственно в движке.
PaLM 2 — это модель большого языка нового поколения, основанная на наследии Google в области революционных исследований в области машинного обучения и ответственного искусственного интеллекта. Он включает в себя сложные задачи на рассуждение, в том числе кодирование и математику, классификацию и ответы на вопросы, перевод и владение несколькими языками, а также генерацию естественного языка лучше, чем наши предыдущие современные программы LLM.
Med-PaLM — это большая языковая модель (LLM), предназначенная для предоставления высококачественных ответов на медицинские вопросы. Он использует возможности больших языковых моделей Google, которые мы адаптировали к медицинской сфере с помощью набора тщательно подобранных демонстраций медицинских экспертов.
Sec-PaLM — это большие языковые модели (LLM), которые ускоряют оказание помощи людям, ответственным за обеспечение безопасности своих организаций. Эти новые модели не только дают людям более естественный и творческий способ понимания безопасности и управления ею.
Вернуться к началу
Вернуться к началу
Вернуться на вершину
Localai-это самостоятельный, местный, совместимый с OpenAI API. Замена погружения в OpenAI Rown LLMS на оборудовании потребительского уровня без графического процессора не требуется. Это API для управления GGML-совместимыми моделями: Llama, GPT4ALL, RWKV, Whisper, Vicuna, Koala, GPT4All-J, Cerebras, Falcon, Dolly, StarCoder и многих других.
Llama.cpp - это модель Llama в Facebook в C/C ++.
Ollama - это инструмент для работы с Llama 2 и другими крупными языковыми моделями на местном уровне.
Localai-это самостоятельный, местный, совместимый с OpenAI API. Замена погружения в OpenAI Rown LLMS на оборудовании потребительского уровня без графического процессора не требуется. Это API для управления GGML-совместимыми моделями: Llama, GPT4ALL, RWKV, Whisper, Vicuna, Koala, GPT4All-J, Cerebras, Falcon, Dolly, StarCoder и многих других.
Serge - это веб -интерфейс для общения с Alpaca через llama.cpp. Полностью самостоятельно и докеризован, с простым в использовании API.
OpenLLM - это открытая платформа для эксплуатации больших языковых моделей (LLMS) в производстве. Настраивать, подавать, развернуть и с легкостью контролировать любые LLMS.
Llama-GPT-это самостоятельный, офлайн-чат-чат-бот. Основанный на Llama 2. 100% Private, без данных, не оставляя вашего устройства.
Llama2 Webui - это инструмент для запуска любого LLAMA 2 локально с пользовательским интерфейсом Gradio на графическом процессоре или процессоре из любого места (Linux/Windows/Mac). Используйте llama2-wrapper в качестве местного бэкэнда Llama2 для генеративных агентов/приложений.
LLAMA2.C-это инструмент для обучения архитектуры LLAMA 2 LLM в Pytorch, а затем выводит его с одним простым файлом C 700 линий C (run.c).
Alpaca.cpp-быстрая модель, похожая на Chatgpt, локально на вашем устройстве. Он сочетает в себе модель фонда Llama с открытым воспроизведением Стэнфордской альпаки, точной настройкой базовой модели, чтобы подчиняться инструкциям (сродни RLHF, используемому для обучения CHATGPT) и набора модификаций Llama.cpp для добавления интерфейса чата.
GPT4All-это экосистема чат-ботов с открытым исходным кодом, обученные массовым коллекциям данных по чистому помощнику, включая код, истории и диалог, основанные на ламе.
Minigpt-4-это улучшающее понимание зрения с расширенными большими языковыми моделями
Lollms Webui - это концентратор для моделей LLM (модель большой языка). Он направлен на предоставление удобного интерфейса для доступа и использования различных моделей LLM для широкого спектра задач. Если вам нужна помощь в написании, кодировании, организации данных, генерации изображений или поиском ответов на ваши вопросы.
LM Studio - это инструмент для обнаружения, загрузки и запуска локальных LLMS.
Gradio Web UI - это инструмент для крупных языковых моделей. Поддерживает трансформаторы, gptq, llama.cpp (ggml/gguf), модели Llama.
OpenPlayGround-это PlayFround для запуска моделей, похожих на ChatGPT, локально на вашем устройстве.
Vicuna - чат -бот с открытым исходным кодом, обученный тонкой настройкой Llama. Это, по -видимому, достигает более 90% качества CHATGPT и стоит 300 долларов на обучение.
Yeagar AI-создатель агента Langchain, разработанный, чтобы помочь вам с легкостью создать, прототип и развернуть агентов с AI.
Koboldcpp-это простое в использовании программное обеспечение для создания текста AI для моделей GGML. Это единственный самостоятельный, распределяемый от Concedo, который создает Llama.cpp и добавляет универсальную конечную точку API Kobold, дополнительную поддержку формата, обратная совместимость, а также причудливый пользовательский интерфейс с постоянными историями, редактирование инструментов, сохранение форматов, память, мир, мир, мир, мир, мир Информация, записка автора, персонажи и сценарии.
Вернуться на вершину
Fuzzy Logic-это эвристический подход, который обеспечивает более продвинутую обработку решений и лучшую интеграцию с программированием на основе правил.
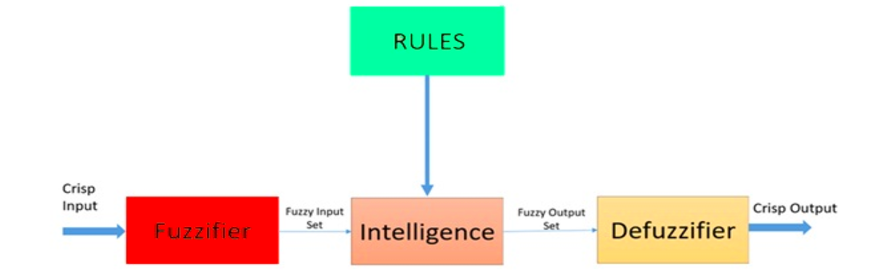
Архитектура нечеткой логической системы. Источник: ResearchGate
Support Vector Machine (SVM)-это контролируемая модель машинного обучения, которая использует алгоритмы классификации для задач классификации двух групп.

Поддержка векторной машины (SVM). Источник: OpenClipart
Нейронные сети являются подмножеством машинного обучения и лежат в основе алгоритмов глубокого обучения. Название/структура вдохновлена человеческим мозгом, копирующим процесс, который биологические нейроны/узлы сигнализируют друг другу.
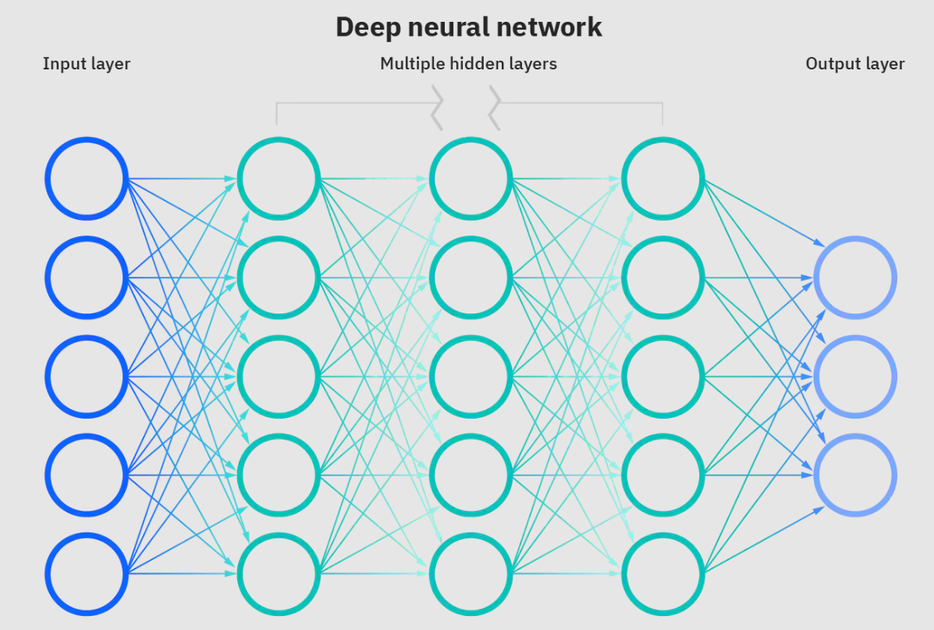
Глубокая нейронная сеть. Источник: IBM
Свещательные нейронные сети (R-CNN)-это алгоритм обнаружения объекта, который сначала сегментирует изображение, чтобы найти потенциальные соответствующие ограничительные ящики, а затем запустить алгоритм обнаружения, чтобы найти наиболее вероятные объекты в этих ограничивающих коробках.
Сверточные нейронные сети. Источник: CS231N
Рецидивирующие нейронные сети (RNNS) - это тип искусственной нейронной сети, которая использует последовательные данные или данные временных рядов.
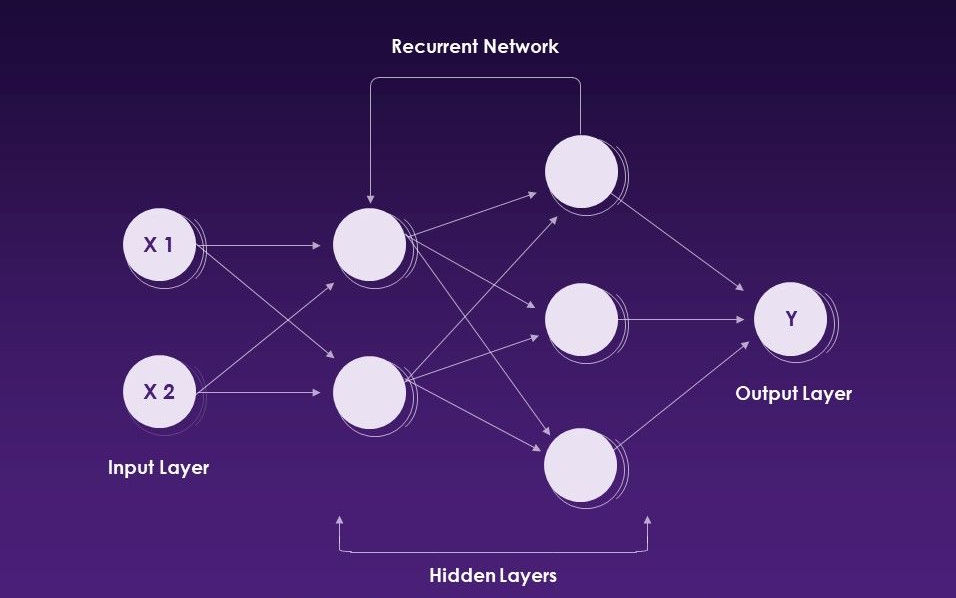
Повторяющиеся нейронные сети. Источник: Slideteam
Многослойные персептроны (MLP) представляют собой многослойные нейронные сети, состоящие из нескольких слоев персептронов с пороговой активацией.
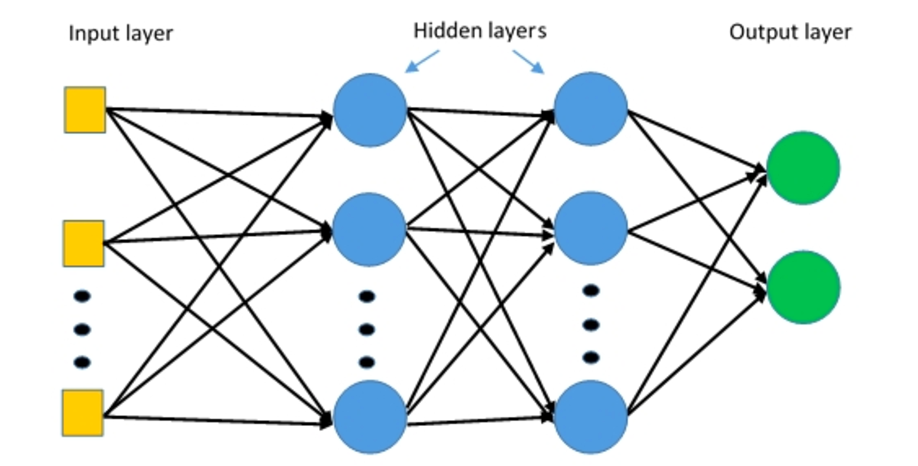
Многослойные персептроны. Источник: Дипай
Случайный лес является общепринятым алгоритмом машинного обучения, который сочетает в себе выходные данные о нескольких деревьях принятия решений для достижения одного результата. Дерево решений в лесу не может быть обрезано для отбора проб и, следовательно, выбора прогнозирования. Его простота использования и гибкость вызвали его внедрение, поскольку он решает как классификацию, так и проблемы с регрессией.
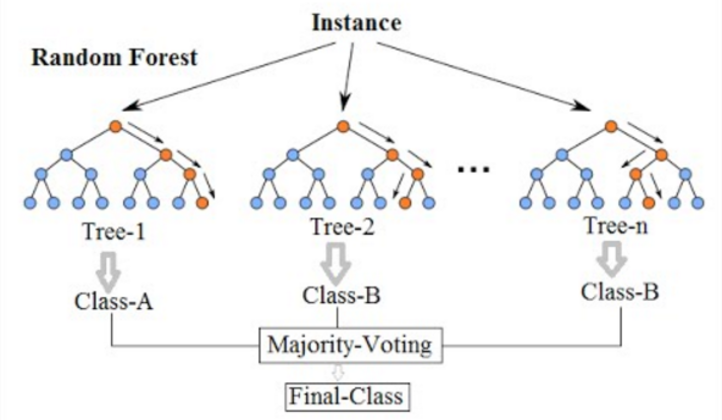
Случайный лес. Источник: Викимедия
Деревья решений являются моделями структурированных деревьями для классификации и регрессии.
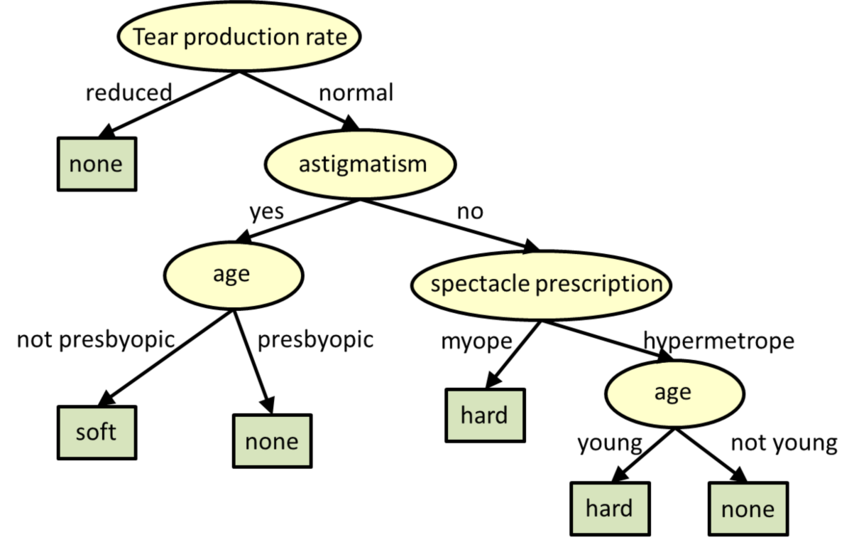
** Деревья решений. Источник: CMU
Наивный Байеса - это алгоритм машинного обучения, который используется решаемые задачи CALSSICATICE. Он основан на применении теоремы Байеса с сильными предположениями об независимости между функциями.

Теорема Байеса. Источник: Mathisfun
Вернуться на вершину

Pytorch-это структура глубокого обучения с открытым исходным кодом, которая ускоряет путь от исследований к производству, используемой для таких приложений, как компьютерное зрение и обработка естественного языка. Pytorch разрабатывается Facebook AI Research Lab.
Начало работы с Pytorch
Документация Pytorch
Дискуссионный форум Pytorch
Top Pytorch Courses Online | Курсера
Top Pytorch Courses Online | Удеми
Изучить питор с онлайн -курсами и классами | эдкс
Основы Pytorch - Учитесь | Microsoft Docs
Вступление в глубокое обучение с Pytorch | Удасити
Разработка Pytorch в коде Visual Studio
Pytorch On Azure - глубокое обучение с Pytorch | Microsoft Azure
Pytorch - Azure Databricks | Microsoft Docs
Глубокое обучение с Pytorch | Веб-сервисы Amazon (AWS)
Начало работы с Pytorch в Google Cloud
Pytorch Mobile-это сквозный рабочий процесс ML от обучения до развертывания для мобильных устройств iOS и Android.
TorchScript - это способ создания сериализуемых и оптимизируемых моделей из кода Pytorch. Это позволяет сохранению любой программы TorchScript из процесса Python и загруженной в процессе, где нет зависимости от питона.
TorchServe - это гибкий и простой в использовании инструмент для обслуживания моделей Pytorch.
Keras-это API нейронных сетей высокого уровня, написанный на Python и способный работать на вершине Tensorflow, CNTK или Theano. Он был разработан с акцентом на обеспечение быстрых экспериментов. Он способен работать поверх Tensorflow, Microsoft Cognitive Toolkit, R, Theano или Plaidml.
Onnx Runtime-это кроссплатформенный, высокопроизводительный вывод ML и ускоритель обучения. Он поддерживает модели из структур глубокого обучения, таких как Pytorch и Tensorflow/Keras, а также классические библиотеки машинного обучения, такие как Scikit-Learn, Lightgbm, XGBOOST и т. Д.
Kornia - это библиотека дифференцируемого компьютерного зрения, которая состоит из набора подпрограмм и дифференцируемых модулей для решения общих задач CV (Computer Vision).
Pytorch-NLP-это библиотека для обработки естественного языка (NLP) в Python. Он построен с учетом самых последних исследований и был разработан с первого дня для поддержки быстрого прототипирования. Pytorch-NLP поставляется с предварительно обученными встраиваниями, пробоотборниками, наборами данных, метриками, модулями нейронной сети и текстовыми кодерами.
Ignite-это библиотека высокого уровня, чтобы помочь в обучении и оценке нейронных сетей в Pytorch гибко и прозрачно.
Hummingbird - это библиотека для компиляции обученных традиционных моделей ML в тензорные вычисления. Это позволяет пользователям плавно использовать фреймворки нейронной сети (например, Pytorch) для ускорения традиционных моделей ML.
Deep Graph Library (DGL) - это пакет Python, созданный для легкой реализации семейства моделей нейронной сети графиков, а также Pytorch и других фреймворков.
Tensorly - это API высокого уровня для тензорных методов и глубоких тензурированных нейронных сетей в Python, направленном на то, чтобы сделать тензорное обучение простым.
GPYTORCH - это библиотека процессов Гаусса, реализованная с использованием Pytorch, предназначенная для создания масштабируемых, гибких моделей процессов Гаусса.
Poutyne-это керас, подобная рамки для Pytorch и обрабатывает большую часть кодекса, необходимого для обучения нейронных сетей.
Forte-это инструментарий для создания трубопроводов NLP с композиционными компонентами, удобными интерфейсами данных и взаимодействием поперечной задачи.
Torchmetrics - это метрики машинного обучения для распределенных, масштабируемых приложений Pytorch.
Captum - это расширяемая библиотека с открытым исходным кодом для интерпретации модели, построенной на Pytorch.
Transformer-это современная обработка естественного языка для Pytorch, Tensorflow и Jax.
Hydra - это структура для элегантной настройки сложных приложений.
Accelerate-это простой способ обучения и использования моделей Pytorch с мульти-GPU, TPU, смешанным назначением.
Ray - это быстрая и простая структура для строительства и запуска распределенных приложений.
Parlai является единой платформой для обмена, обучения и оценки диалоговых моделей во многих задачах.
Pytorchvideo - это библиотека глубокого обучения для исследования видео. Размещают различные модели, ориентированные на видео, наборы данных, тренировочные трубопроводы и многое другое.
Opacus - это библиотека, которая позволяет обучать модели Pytorch с дифференциальной конфиденциальностью.
Pytorch Lightning-это библиотека ML, похожая на керас для Pytorch. Это оставляет вам основную обучение и логику проверки и автоматизирует остальные.
Pytorch Geometric Temperal - это временная (динамическая) библиотека расширения для геометрического Pytorch.
Geometric Pytorch - это библиотека для глубокого обучения нерегулярным входным данным, таким как графики, точечные облака и многообразии.
Raster Vision - это структура с открытым исходным кодом для глубокого обучения на спутниковых и воздушных образах.
Crypten - это структура для сохранения конфиденциальности ML. Его цель - сделать безопасные вычислительные методы доступными для практикующих ML.
Optuna - это структура оптимизации с открытым исходным кодом для автоматизации поиска гиперпараметра.
Pyro - это универсальный вероятностный язык программирования (PPL), написанный на Python и поддерживаемый Pytorch на бэкэнд.
Ольмируемые - это быстрая и расширяемая библиотека увеличения изображений для различных задач CV, таких как классификация, сегментация, обнаружение объекта и оценка позы.
Skorch-это библиотека высокого уровня для Pytorch, которая обеспечивает полную совместимость Scikit-Learn.
MMF - это модульная структура для мультимодальных исследований Vision & Language MultiModal из Facebook AI Research (FAIR).
AdaptDL-это ресурсная адаптивная структура обучения и расписания в области глубокого обучения.
Polyaxon-это платформа для создания, обучения и мониторинга крупномасштабных приложений глубокого обучения.
TextBrewer-это набор инструментов дистилляции знаний на основе Pytorch для обработки естественного языка
Advertorch - это набор инструментов для исследований на состязательной устойчивости. Он содержит модули для создания состязательных примеров и защиты от атак.
Nemo - это инструментарий AA для разговорного ИИ.
Clinicadl - это основа для воспроизводимой классификации болезни Альцгеймера
Стабильные базовые показатели3 (SB3) - это набор надежных реализаций алгоритмов обучения подкреплению в Pytorch.
Torchio - это набор инструментов для эффективного чтения, предварительной обработки, выборки, увеличения и написания трехмерных медицинских изображений в приложениях глубокого обучения, написанных в Pytorch.
Pysyft - это библиотека Python для зашифрованного, конфиденциального, сохраняющего глубокое обучение.
Flair-очень простая основа для современной обработки естественного языка (NLP).
Glow - это компилятор ML, который ускоряет производительность карт глубокого обучения на разных аппаратных платформах.
Fairscale - это библиотека расширения Pytorch для высокопроизводительной и крупномасштабной тренировки на одном или нескольких машинах/узлах.
Monai-это глубокая структура обучения, которая предоставляет оптимизированные домены основополагающие возможности для разработки рабочих процессов обучения визуализации здравоохранения.
PFRL-это библиотека обучения в глубоком подкреплении, которая реализует различные современные алгоритмы глубокого подкрепления в Python с использованием Pytorch.
Einops - это гибкие и мощные тензоры для читаемого и надежного кода.
Pytorch3d - это библиотека глубокого обучения, которая обеспечивает эффективные, повторно используемые компоненты для исследования 3D компьютерного зрения с Pytorch.
Ensemble Pytorch является единой ансамблевой рамки для Pytorch для повышения производительности и надежности вашей модели глубокого обучения.
Слегка является структурой компьютерного зрения для самоотверженного обучения.
High-это библиотека, которая облегчает реализацию произвольно сложных алгоритмов мета-обучения на основе градиента и вложенных петлей оптимизации с почти ванилью Pytorch.
Horovod - это распределенная учебная библиотека для рамках глубокого обучения. Horovod стремится сделать распределенный DL быстро и простым в использовании.
Pennylane-это библиотека для квантовой ML, автоматической дифференциации и оптимизации гибридных квантово-классических вычислений.
Detectron2 является платформой следующего поколения Fair для обнаружения объектов и сегментации.
Fastai - это библиотека, которая упрощает обучение быстрым и точным нейронным сетям, используя современные лучшие практики.
Вернуться на вершину

TensorFlow — это комплексная платформа с открытым исходным кодом для машинного обучения. Он имеет комплексную гибкую экосистему инструментов, библиотек и ресурсов сообщества, которая позволяет исследователям подталкивать современное в ML, а разработчики легко создают и развертывают приложения ML.
Начало работы с TensorFlow
Учебные пособия по TensorFlow
Сертификат разработчика TensorFlow | ТензорФлоу
Сообщество Tensorflow
Tensorflow Models & Datazets
Tensorflow Cloud
Образование машинного обучения | ТензорФлоу
Лучшие курсы Tensorflow Online | Курсера
Лучшие курсы Tensorflow Online | Удеми
Глубокое обучение с Tensorflow | Удеми
Глубокое обучение с Tensorflow | эдкс
Intro to Tensorflow для глубокого обучения | Удасити
Intro to Tensorflow: курс сбоя машинного обучения | Разработчики Google
Обучить и развернуть модель Tensorflow - Azure Machine Learning
Применить модели машинного обучения в функциях Azure с Python и Tensorflow | Microsoft Azure
Глубокое обучение с Tensorflow | Веб-сервисы Amazon (AWS)
Tensorflow - Amazon EMR | AWS документация
Tensorflow Enterprise | Google Облако
Tensorflow Lite - это структура глубокого обучения с открытым исходным кодом для развертывания моделей машинного обучения на мобильных и IoT -устройствах.
Tensorflow.js - это библиотека JavaScript, которая позволяет вам разрабатывать или выполнять модели ML в JavaScript и использовать ML непосредственно на стороне клиента браузера, на стороне сервера через node.js, мобильный собственный через Rayct Partin Устройства через node.js на Raspberry Pi.
TensorFlow_macos-это Mac-оптимизированная версия Addons TensorFlow и TensorFlow для MacOS 11.0+, ускоренная с использованием Framework Apple ML Compute.
Google Colaboratory - это бесплатная ноутбука Jupyter, которая не требует настройки и полностью работает в облаке, что позволяет вам выполнять код TensorFlow в вашем браузере с одним щелчком.
Инструмент What-IF является инструментом для проведения пробуждения моделей машинного обучения, полезного для понимания модели, отладки и справедливости. Доступно в ноутбуках Tensorboard и Jupyter или Colab.
Tensorboard - это набор инструментов визуализации для понимания, отладки и оптимизации программ TensorFlow.
Keras-это API нейронных сетей высокого уровня, написанный на Python и способный работать на вершине Tensorflow, CNTK или Theano. Он был разработан с акцентом на обеспечение быстрых экспериментов. Он способен работать поверх Tensorflow, Microsoft Cognitive Toolkit, R, Theano или Plaidml.
XLA (ускоренная линейная алгебра) является специфическим для домена компилятор для линейной алгебры, которая оптимизирует вычисления TensorFlow. Результатами являются улучшения скорости, использования памяти и переносимости на серверных и мобильных платформах.
ML PERF - это широкий набор ML Betenchmark для измерения производительности программных рамок ML, оборудования ML и облачных платформ ML.
Playground TensorFlow - это среда разработки, чтобы ворваться с нейронной сетью в вашем браузере.
TPU Research Cloud (TRC) - это программа, позволяющая исследователям подавать заявку на доступ к кластеру из более чем 1000 облачных TPU бесплатно, чтобы помочь им ускорить следующую волну исследований.
MLIR - это новая среда промежуточного представления и компилятора.
Решетка-это библиотека для гибких, контролируемых и интерпретируемых решений ML с ограничениями формы здравого смысла.
Tensorflow Hub - это библиотека для многоразового машинного обучения. Загрузите и повторно используйте последние обученные модели с минимальным количеством кода.
Tensorflow Cloud - это библиотека для подключения вашей локальной среды к Google Cloud.
Tensorflow Model Optimization Toolkit - это набор инструментов для оптимизации моделей ML для развертывания и выполнения.
Tensorflow Reageermes - это библиотека для моделей системного здания.
Tensorflow Text- это коллекция классов, связанных с текстами и NLP и OP, готовыми к использованию с TensorFlow 2.
Tensorflow Graphics - это библиотека функциональности компьютерной графики, начиная от камер, светильников и материалов до рендереров.
Tensorflow Federated - это структура с открытым исходным кодом для машинного обучения и других вычислений по децентрализованным данным.
Вероятность TensorFlow является библиотекой для вероятностных рассуждений и статистического анализа.
Tensor2tensor - это библиотека моделей глубокого обучения и наборов данных, предназначенная для того, чтобы сделать глубокое обучение более доступным и ускорить исследования ML.
Конфиденциальность TensorFlow - это библиотека Python, которая включает в себя реализации оптимизаторов TensorFlow для моделей обучения машинного обучения с дифференциальной конфиденциальностью.
Рейтинг Tensorflow-это библиотека для методов обучения в Rank (LTR) на платформе TensorFlow.
Tensorflow Agents - это библиотека для обучения подкреплению в Tensorflow.
Tensorflow Addons-это репозиторий вкладов, которые соответствуют хорошо зарекомендовавшим себя шаблона API, но внедряют новые функции, недоступные в Core Tensorflow, поддерживаемая SIG-аддонами. Tensorflow изначально поддерживает большое количество операторов, слоев, показателей, потерь и оптимизаторов.
Tensorflow ввод/вывод - это набор данных, потоковая передача и расширения файловой системы, поддерживаемый SIG IO.
Tensorflow Quantum-это библиотека квантового машинного обучения для быстрого прототипирования гибридных квантовых моделей ML.
Дофамин является исследовательской структурой для быстрого прототипирования алгоритмов обучения подкреплению.
TRFL - это библиотека для подкрепления строительных блоков, созданных DeepMind.
Mesh Tensorflow - это язык для распределенного глубокого обучения, способного указать широкий класс расчетных вычислений с распределенным тензором.
RaggedTensors-это API, который позволяет легко хранить и манипулировать данными с неоднородной формой, включая текст (слова, предложения, символы) и партии переменной длины.
Unicode Ops - это API, который поддерживает работу с текстом Unicode непосредственно в TensorFlow.
Magenta — исследовательский проект, исследующий роль машинного обучения в процессе создания произведений искусства и музыки.
Ядро - это библиотека кода Python и C ++, предназначенная для того, чтобы облегчить чтение, запись и анализ данных в форматах общих файлов геномики, таких как SAM и VCF.
Сонет - это библиотека от DeepMind для построения нейронных сетей.
Нейронное структурированное обучение - это учебная структура для обучения нейронных сетей путем использования структурированных сигналов в дополнение к входу признаков.
Модельное исправление - это библиотека, которая помогает создавать и обучать модели таким образом, чтобы уменьшить или устранять вред пользователя, возникающий в результате основных предвзятости производительности.
Индикаторы справедливости-это библиотека, которая обеспечивает легкие вычисления общеизвестных показателей справедливости для бинарных и мультиклассных классификаторов.
Решения Forests-это современные алгоритмы для обучения, обслуживания и интерпретации моделей, которые используют леса принятия решений для классификации, регрессии и ранжирования.
Вернуться на вершину

Core ML - это Apple Framework для интеграции моделей машинного обучения в приложения, работающие на устройствах Apple (включая iOS, WatchOS, MacOS и TVOS). Core ML вводит общедоступный формат файла (.mlmodel) для широкого набора методов ML, включая глубокие нейронные сети (как сверточные, так и рецидивирующие), ансамблы деревьев с повышением и обобщенные линейные модели. Модели в этом формате могут быть непосредственно интегрированы в приложения через XCode.
Введение в Core ML
Интеграция модели Core ML в ваше приложение
Core ML -модели
Ссылка на API Core ML
Спецификация ядра ML
Форумы разработчиков Apple для Core ML
Top Core ML Courses Online | Удеми
Top Core ML Courses Online | Курсера
IBM Watson Services для Core ML | ИБМ
Создать основные активы ML с использованием визуального осмотра IBM Maximo | ИБМ
Core ML Tools - это проект, который содержит вспомогательные инструменты для преобразования, редактирования и проверки Core ML ML.
Create ML - это инструмент, который предоставляет новые способы учебного машинного обучения на вашем Mac. Он выводит сложность из модельной тренировки при создании мощных моделей ML ML.
Tensorflow_macos-это Mac-оптимизированная версия Tensorfl


