llm data annotation
1.0.0
Эта структура сочетает в себе человеческий опыт с эффективностью моделей большого языка (LLM), таких как GPT-3.5 OpenAI, для упрощения аннотирования наборов данных и улучшения модели. Итеративный подход обеспечивает постоянное улучшение качества данных и, как следствие, производительность моделей, настроенных с использованием этих данных. Это не только экономит время, но и позволяет создавать индивидуальные LLM, в которых используются как человеческие аннотаторы, так и точность на основе LLM.
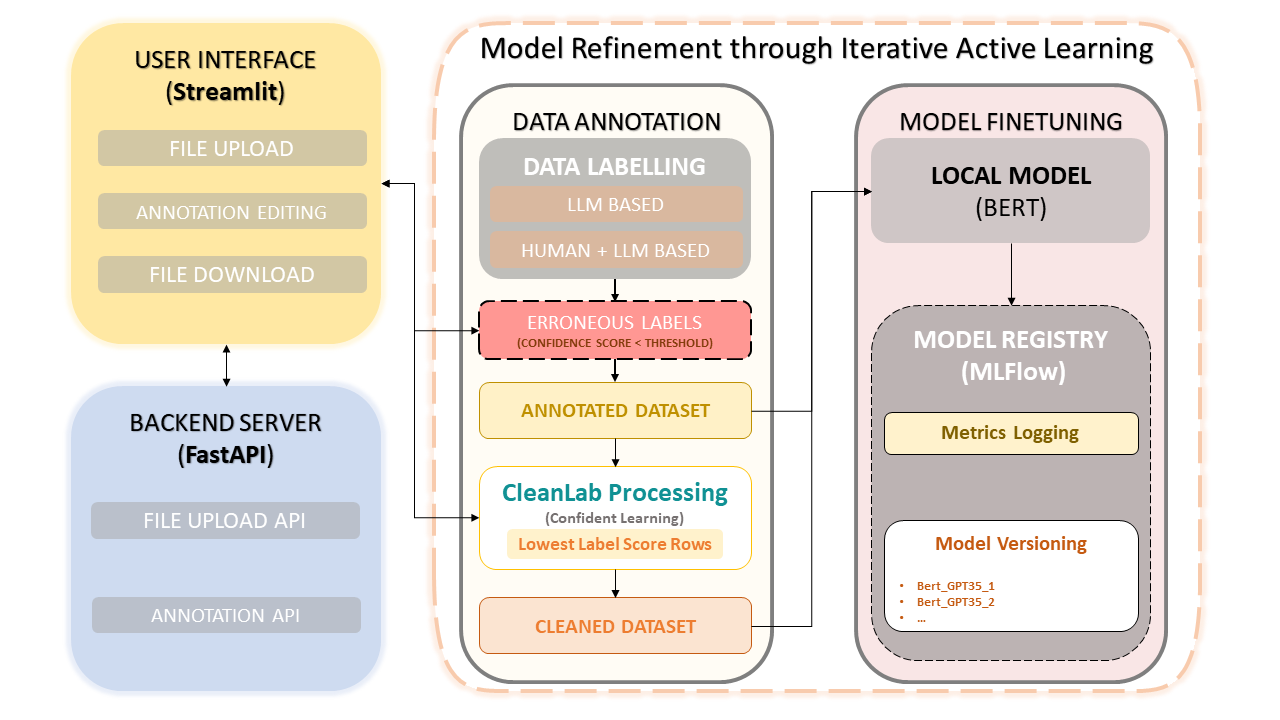
Загрузка набора данных и аннотации
Ручное исправление аннотаций
CleanLab: уверенный подход к обучению
Управление версиями и сохранением данных
Модельное обучение
pip install -r requirements.txtЗапустите бэкэнд FastAPI :
uvicorn app:app --reloadЗапустите приложение Streamlit :
streamlit run frontend.pyЗапустите пользовательский интерфейс MLflow . Чтобы просмотреть модели, метрики и зарегистрированные модели, вы можете получить доступ к пользовательскому интерфейсу MLflow с помощью следующей команды:
mlflow uiОткройте предоставленные ссылки в своем веб-браузере :
http://127.0.0.1:5000 .Следуйте инструкциям на экране, чтобы загружать, аннотировать, исправлять и обучать свой набор данных.
Уверенное обучение стало новаторской методикой в обучении с учителем и при слабом контроле. Он направлен на определение характеристик шума этикеток, поиск ошибок на этикетках и эффективное обучение с помощью шумных этикеток. За счет сокращения зашумленных данных и ранжирования примеров для уверенного обучения этот метод обеспечивает чистый и надежный набор данных, повышая общую производительность модели.
Этот проект имеет открытый исходный код под лицензией MIT.


