Kosmos X
0.0.1

pip3 install --upgrade kosmosx import torch
from kosmosx . model import Kosmos
# Create a sample text token tensor
text_tokens = torch . randint ( 0 , 32002 , ( 1 , 50 ), dtype = torch . long )
# Create a sample image tensor
images = torch . randn ( 1 , 3 , 224 , 224 )
# Instantiate the model
model = Kosmos ()
text_tokens = text_tokens . long ()
# Pass the sample tensors to the model's forward function
output = model . forward (
text_tokens = text_tokens ,
images = images
)
# Print the output from the model
print ( f"Output: { output } " ) Установите свою конфигурацию с помощью: accelerate config , затем: accelerate launch train.py
КОСМОС-1 использует архитектуру Трансформатора, предназначенную только для декодера, на основе Магнето (Фундаментальные Трансформаторы), то есть архитектуру, которая использует так называемый подход суб-LN, где нормализация уровня добавляется как перед модулем внимания (до модуля внимания), так и после него (пост-LN). ln) объединение преимуществ каждого подхода для языкового моделирования и понимания изображений соответственно. Модель также инициализируется в соответствии с конкретной метрикой, также описанной в статье, что позволяет обеспечить более стабильное обучение при более высоких скоростях обучения.
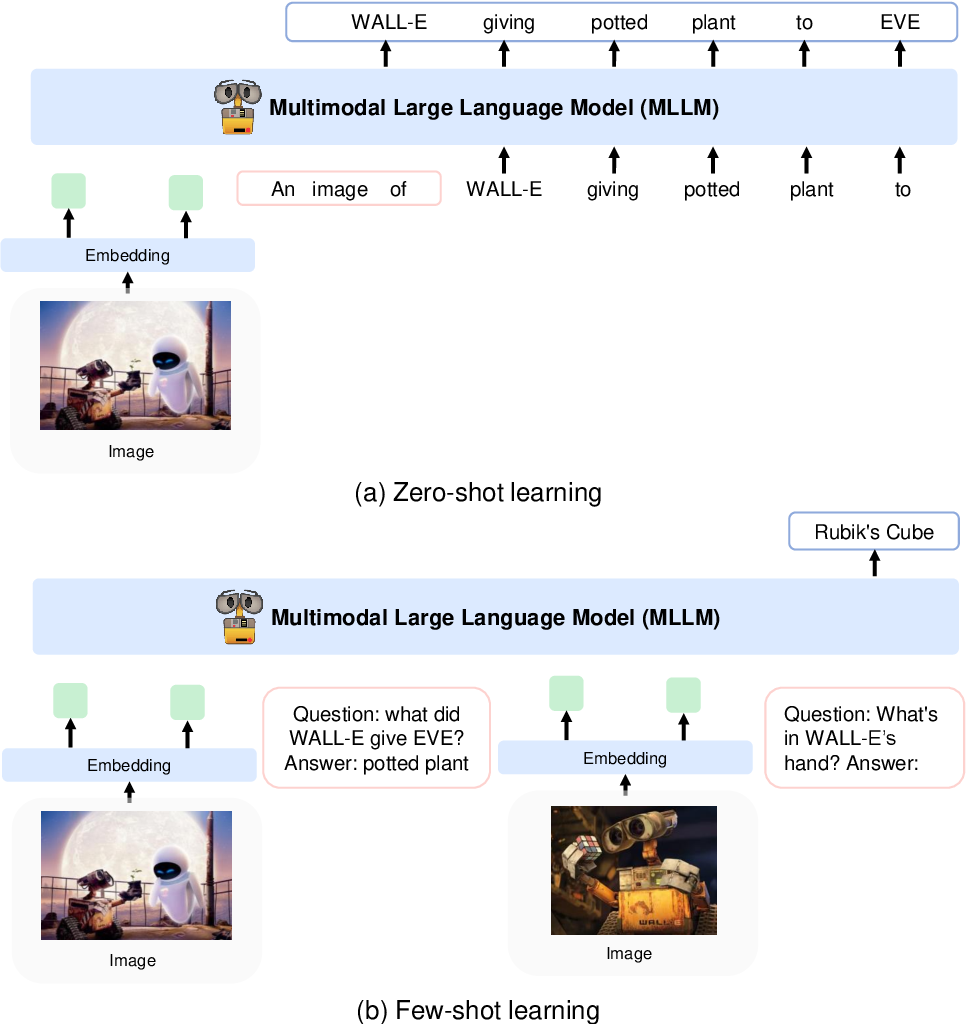
Они кодируют изображения в функции изображения с использованием модели CLIP VIT-L/14 и используют передискретизатор восприятия, представленный в Flamingo, для объединения функций изображения из 256 -> 64 токенов. Функции изображения объединяются с встраиваниями токенов путем добавления их во входную последовательность, окруженную специальными токенами <image> и </image> . Примером может служить <s> <image> image_features </image> text </s> . Это позволяет изображениям переплетаться с текстом в одной и той же последовательности.
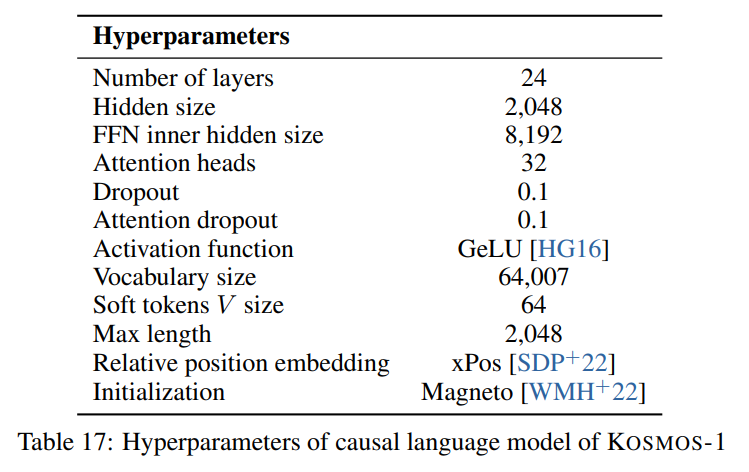
Мы следуем гиперпараметрам, описанным в статье, видимой на следующем изображении:
Мы используем масштабную реализацию архитектуры Transformer только для декодера от Foundation Transformers:
from torchscale . architecture . config import DecoderConfig
from torchscale . architecture . decoder import Decoder
config = DecoderConfig (
decoder_layers = 24 ,
decoder_embed_dim = 2048 ,
decoder_ffn_embed_dim = 8192 ,
decoder_attention_heads = 32 ,
dropout = 0.1 ,
activation_fn = "gelu" ,
attention_dropout = 0.1 ,
vocab_size = 32002 ,
subln = True , # sub-LN approach
xpos_rel_pos = True , # rotary positional embeddings
max_rel_pos = 2048
)
decoder = Decoder (
config ,
embed_tokens = embed ,
embed_positions = embed_positions ,
output_projection = output_projection
)Для модели изображения (CLIP VIT-L/14) мы используем предварительно обученную модель OpenClip:
from transformers import CLIPModel
clip_model = CLIPModel . from_pretrained ( "laion/CLIP-ViT-L-14-laion2B-s32B-b82K" ). vision_model
# projects image to [batch_size, 256, 1024]
features = clip_model ( pixel_values = images )[ "last_hidden_state" ]Мы следуем гиперпараметрам по умолчанию для передискретизатора воспринимающего устройства, поскольку в статье гиперпараметры не указаны:
from flamingo_pytorch import PerceiverResampler
perceiver = PerceiverResampler (
dim = 1024 ,
depth = 2 ,
dim_head = 64 ,
heads = 8 ,
num_latents = 64 ,
num_media_embeds = 256
)
# projects image features to [batch_size, 64, 1024]
self . perceive ( images ). squeeze ( 1 ) Поскольку модель ожидает скрытый размер 2048 , мы используем слой nn.Linear , чтобы проецировать элементы изображения на правильный размер и инициализировать его в соответствии со схемой инициализации Магнето:
image_proj = torch . nn . Linear ( 1024 , 2048 , bias = False )
torch . nn . init . normal_ (
image_proj . weight , mean = 0 , std = 2048 ** - 0.5
)
scaled_image_features = image_proj ( image_features ) В статье описывается SentencePiece со словарем из 64007 токенов. Для простоты (поскольку у нас нет доступного обучающего корпуса) мы используем следующую лучшую альтернативу с открытым исходным кодом — предварительно обученный токенизатор большого размера T5 от HuggingFace. Этот токенизатор имеет словарь из 32002 токенов.
from transformers import T5Tokenizer
tokenizer = T5Tokenizer . from_pretrained (
"t5-large" ,
additional_special_tokens = [ "<image>" , "</image>" ],
extra_ids = 0 ,
model_max_length = 1984 # 2048 - 64 (image features)
) Затем мы встраиваем токены с помощью слоя nn.Embedding . На самом деле мы используем bnb.nn.Embedding из bitandbytes, что позволит нам позже использовать 8-битный AdamW.
import bitsandbytes as bnb
embed = bnb . nn . Embedding (
32002 , # Num embeddings
2048 , # Embedding dim
padding_idx
)Для позиционных вложений мы используем:
from torchscale . component . embedding import PositionalEmbedding
embed_positions = PositionalEmbedding (
2048 , # Num embeddings
2048 , # Embedding dim
padding_idx
)Кроме того, мы добавляем выходной слой проекции для проецирования скрытого измерения на размер словаря и инициализируем его в соответствии со схемой инициализации Магнето:
output_projection = torch . nn . Linear (
2048 , 32002 , bias = False
)
torch . nn . init . normal_ (
output_projection . weight , mean = 0 , std = 2048 ** - 0.5
) Мне пришлось внести некоторые небольшие изменения в декодер, чтобы он мог принимать уже встроенные функции в прямом проходе. Это было необходимо для реализации более сложной последовательности ввода, описанной выше. Изменения видны в следующей разнице в строке 391 файла torchscale/architecture/decoder.py :
+ if kwargs.get("passed_x", None) is None:
+ x, _ = self.forward_embedding(
+ prev_output_tokens, token_embeddings, incremental_state
+ )
+ else:
+ x = kwargs["passed_x"]
- x, _ = self.forward_embedding(
- prev_output_tokens, token_embeddings, incremental_state
- )Вот таблица уценок с метаданными для наборов данных, упомянутых в статье:
| Набор данных | Описание | Размер | Связь |
|---|---|---|---|
| Куча | Разнообразный корпус английских текстов | 800 ГБ | Обнимающее лицо |
| Обычное сканирование | Данные веб-сканирования | - | Обычное сканирование |
| ЛАИОН-400М | Пары изображение-текст из Common Crawl | 400 млн пар | Обнимающее лицо |
| ЛАИОН-2Б | Пары изображение-текст из Common Crawl | 2B пары | ArXiv |
| КОЙО | Пары изображение-текст из Common Crawl | 700 млн пар | Гитхаб |
| Концептуальные подписи | Пары «изображение-замещающий текст» | 15 миллионов пар | ArXiv |
| Перемежающиеся данные CC | Текст и изображения из Common Crawl | 71 млн документов | Пользовательский набор данных |
| ИсторияClose | Рассуждения здравого смысла | 16 тысяч примеров | Антология ACL |
| HellaSwag | Здравый смысл NLI | 70 тысяч примеров | ArXiv |
| Схема Винограда | Неоднозначность слова | 273 примера | ПКРР 2012 |
| Виногранде | Неоднозначность слова | 1,7 тыс. примеров | АААИ 2020 |
| ПИКА | Физический здравый смысл QA | 16 тысяч примеров | АААИ 2020 |
| BoolQ | контроль качества | 15 тысяч примеров | АКЛ 2019 |
| КБ | Вывод на естественном языке | 250 примеров | Sinn und Bedeutung 2019 |
| КОПА | Причинно-следственные рассуждения | 1 тыс. примеров | Весенний симпозиум AAAI 2011 г. |
| Относительныйразмер | Рассуждения здравого смысла | 486 пар | АрХив 2016 |
| ПамятьЦвет | Рассуждения здравого смысла | 720 примеров | АрXiv 2021 |
| ЦветТермины | Рассуждения здравого смысла | 320 примеров | АКЛ 2012 |
| IQ-тест | Невербальное рассуждение | 50 примеров | Пользовательский набор данных |
| КОКО Подписи | Подпись к изображению | 413 тыс. изображений | ПАМИ 2015 |
| Фликр30 тыс. | Подпись к изображению | 31 тыс. изображений | ТАКЛ 2014 |
| VQAv2 | Визуальный контроль качества | 1 млн пар контроля качества | ЦВПР 2017 |
| ВизВиз | Визуальный контроль качества | 31 тыс. пар контроля качества | ЦВПР 2018 |
| ВебСРК | Веб-контроль качества | 1,4 тыс. примеров | ЭМНЛП 2021 |
| ImageNet | Классификация изображений | 1,28 млн изображений | ЦВПР 2009 |
| КУБ | Классификация изображений | 200 видов птиц | ТОГ 2011 |
АПАЧ


