SimplyRetrieve
Dependencies Update
? Новости : 21 августа 2023 г. — Теперь пользователи могут создавать и добавлять знания на лету с помощью новой Knowledge Tab в графическом интерфейсе. Кроме того, на вкладках «Конфигурация» и «Знания» добавлены индикаторы выполнения.
SimplyRetieve — это инструмент с открытым исходным кодом, целью которого является предоставление полностью локализованной, легкой и удобной платформы с графическим интерфейсом пользователя и API для подхода , ориентированного на поиск (RCG), для сообщества машинного обучения.
Создайте инструмент чата с вашими документами и языковыми моделями с широкими возможностями настройки. Особенности:
Технический отчет об этом инструменте доступен на arXiv.
Короткое видео об этом инструменте доступно на YouTube.
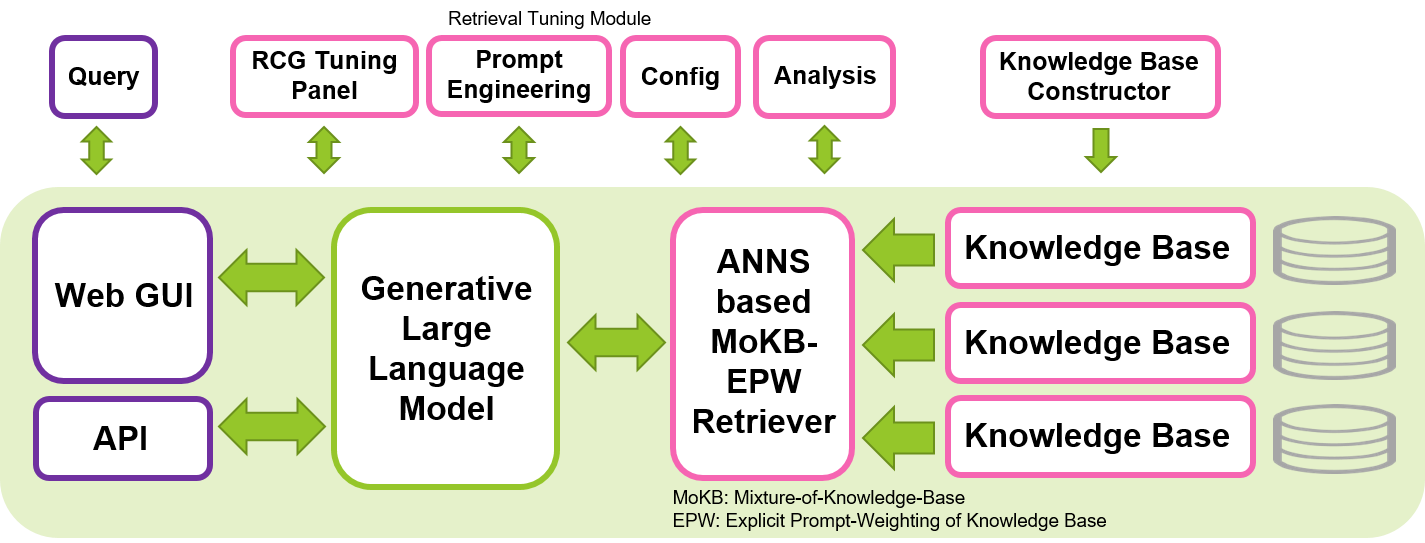
Мы стремимся внести свой вклад в разработку безопасных, интерпретируемых и ответственных программ LLM, делясь нашим инструментом с открытым исходным кодом для реализации подхода RCG. Мы надеемся, что этот инструмент позволит сообществу машинного обучения более эффективно использовать LLM, сохраняя при этом конфиденциальность и локальную реализацию. Генерация, ориентированная на поиск, которая основывается на концепции дополненной генерации (RAG), подчеркивая решающую роль LLM в интерпретации контекста и доверяя запоминание знаний компоненту ретривера, имеет потенциал для создания более эффективной и интерпретируемой генерации, а также сокращения масштаб LLM, необходимый для генеративных задач. Этот инструмент можно запустить на одном графическом процессоре Nvidia, например T4, V100 или A100, что делает его доступным для широкого круга пользователей.
Этот инструмент создан в основном на основе замечательных и знакомых библиотек Hugging Face, Gradio, PyTorch и Faiss. LLM по умолчанию, настроенный в этом инструменте, представляет собой точно настроенную инструкцию Wizard-Vicuna-13B-Uncensored. Модель внедрения по умолчанию для ретривера — multilingual-e5-base. Мы обнаружили, что эти модели хорошо работают в этой системе, а также во многих других LLM и ретриверах с открытым исходным кодом различных размеров, доступных в Hugging Face. Этот инструмент можно запускать не только на английском, но и на других языках, выбрав соответствующие LLM и настроив шаблоны подсказок в соответствии с целевым языком.
pip install -r requirements.txtchat/data/ и запустите сценарий подготовки данных ( cd chat/ затем следующую команду) CUDA_VISIBLE_DEVICES=0 python prepare.py --input data/ --output knowledge/ --config configs/default_release.json
pdf, txt, doc, docx, ppt, pptx, html, md, csv , их можно легко расширить путем редактирования файла конфигурации. Следуйте советам по этой проблеме, если произошла ошибка, связанная с NLTK.Knowledge Tab » инструмента с графическим интерфейсом. Теперь пользователи могут добавлять знания на лету. Запуск приведенного выше сценария подготовки.py перед запуском инструмента не является обязательным. После настройки предварительных условий, указанных выше, установите текущий путь к каталогу chat ( cd chat/ ), выполните команду ниже. Тогда grab a coffee! так как загрузка займет всего несколько минут.
CUDA_VISIBLE_DEVICES=0 python chat.py --config configs/default_release.json
Затем получите доступ к графическому веб-интерфейсу из вашего любимого браузера, перейдя по адресу http://<LOCAL_SERVER_IP>:7860 . Замените <LOCAL_SERVER_IP> на IP-адрес вашего сервера графического процессора. И вот оно, вы готовы к работе!
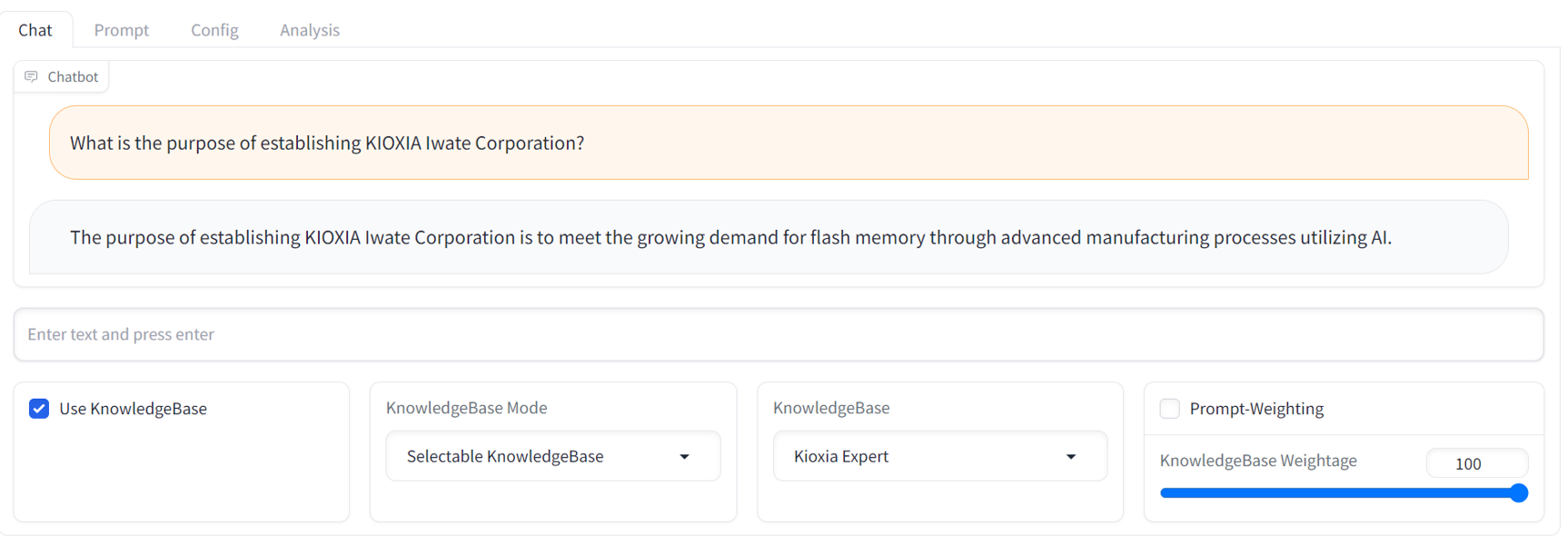
GUI operation manual см. в файле readme для графического интерфейса, расположенном в каталоге docs/ .API access manual см. в файле ознакомительных сведений API и примерах сценариев, расположенных в каталоге examples/ .Ниже приведен пример скриншота графического интерфейса чата. Он предоставляет знакомый интерфейс потокового чат-бота с комплексной панелью настройки RCG.
В данный момент у вас нет локального сервера графического процессора для запуска этого инструмента? Без проблем. Посетите этот репозиторий. Там показана инструкция по опробованию этого инструмента на облачной платформе AWS EC2.
Не стесняйтесь оставлять нам любые отзывы и комментарии. Мы очень приветствуем любые обсуждения и предложения об этом инструменте, включая новые функции, улучшения и улучшенную документацию. Не стесняйтесь открыть вопрос или обсуждение. У нас пока нет шаблона для обсуждения или обсуждения, поэтому на данный момент подойдет что угодно.
Будущие разработки
Важно отметить, что этот инструмент не обеспечивает надежного решения для обеспечения полностью безопасного и ответственного реагирования на генеративные модели ИИ, даже в рамках подхода, ориентированного на поиск. Разработка более безопасных, интерпретируемых и ответственных систем искусственного интеллекта остается активной областью исследований и постоянных усилий.
Тексты, сгенерированные с помощью этого инструмента, могут иметь вариации, даже при незначительном изменении подсказок или запросов, из-за поведения прогнозирования следующего токена в LLM текущего поколения. Это означает, что пользователям, возможно, придется тщательно настроить как подсказки, так и запросы, чтобы получить оптимальные ответы.
Если вы считаете нашу работу полезной, пожалуйста, укажите нас следующим образом:
@article{ng2023simplyretrieve,
title={SimplyRetrieve: A Private and Lightweight Retrieval-Centric Generative AI Tool},
author={Youyang Ng and Daisuke Miyashita and Yasuto Hoshi and Yasuhiro Morioka and Osamu Torii and Tomoya Kodama and Jun Deguchi},
year={2023},
eprint={2308.03983},
archivePrefix={arXiv},
primaryClass={cs.CL},
journal={arXiv preprint arXiv:2308.03983}
}
?️ Аффилиация: Институт исследований и разработок технологий памяти, корпорация Kioxia, Япония.


