airllm
1.0.0

Быстрый старт | Конфигурации | MacOS | Примеры тетрадей | Часто задаваемые вопросы
AirLLM оптимизирует использование памяти для вывода, позволяя 70B большим языковым моделям выполнять вывод на одной карте графического процессора емкостью 4 ГБ без квантования, дистилляции и сокращения. И теперь вы можете запустить 405B Llama3.1 на 8 ГБ видеопамяти .
[20.08.2024] v2.11.0: Поддержка Qwen2.5
[2024/08/18] v2.10.1 Поддержка вывода ЦП. Поддержка несегментированных моделей. Спасибо @NavodPeiris за прекрасную работу!
[2024/07/30] Поддержка Llama3.1 405B (пример ноутбука). Поддержка квантования 8 бит/4 бит .
[20.04.2024] AirLLM уже изначально поддерживает Llama3. Запустите Llama3 70B на одном графическом процессоре емкостью 4 ГБ.
[25.12.2023] v2.8.2: Поддержка MacOS с 70B большими языковыми моделями.
[20.12.2023] v2.7: Поддержка AirLLMMixtral.
[20.12.2023] v2.6: добавлена AutoModel, автоматически определяет тип модели, нет необходимости предоставлять класс модели для инициализации модели.
[2023/12/18] v2.5: добавлена предварительная выборка для перекрытия загрузки и вычисления модели. Улучшение скорости на 10%.
[2023/12/03] добавлена поддержка ChatGLM , QWen , Baichuan , Mistral , InternLM !
[2023/12/02] добавлена поддержка защитных датчиков. Теперь поддерживаются все 10 лучших моделей в открытой таблице лидеров LLM.
[2023/12/01] airllm 2.0. Поддержка сжатия: ускорение выполнения в 3 раза!
[20.11.2023] airllm Начальная версия!
Сначала установите пакет airllm pip.
pip install airllmЗатем инициализируйте AirLLMLlama2, передайте идентификатор репозитория Huggingface используемой модели или локальный путь, и вывод может быть выполнен аналогично обычной модели трансформера.
( Вы также можете указать путь для сохранения разделенной многослойной модели через Layer_shards_saving_path при инициализации AirLLMLlama2.
from airllm import AutoModel
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" )
# or use model's local path...
#model = AutoModel.from_pretrained("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?' ,
#'I like',
]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 20 ,
use_cache = True ,
return_dict_in_generate = True )
output = model . tokenizer . decode ( generation_output . sequences [ 0 ])
print ( output )Примечание. Во время вывода исходная модель сначала будет разложена и сохранена послойно. Убедитесь, что в каталоге кэша Huggingface достаточно места на диске.
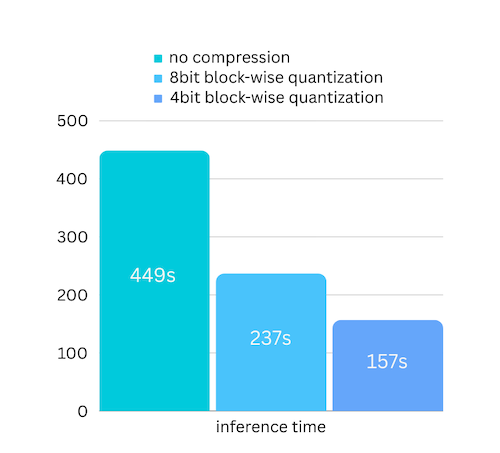
Мы только что добавили сжатие модели на основе сжатия модели на основе блочного квантования. Что может еще больше ускорить скорость вывода до 3 раз с практически игнорируемой потерей точности! (подробнее об оценке производительности и о том, почему мы используем блочное квантование, см. в этой статье)
pip install -U bitsandbytespip install -U airllm model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" ,
compression = '4bit' # specify '8bit' for 8-bit block-wise quantization
)Квантование обычно требует квантования как весов, так и активаций, чтобы действительно ускорить процесс. Из-за этого становится сложнее поддерживать точность и избегать влияния выбросов во всех видах входных данных.
Хотя в нашем случае узкое место в основном связано с загрузкой диска, нам нужно только уменьшить размер загрузки модели. Таким образом, мы можем квантовать только часть весов, что легче обеспечить точность.
При инициализации модели мы поддерживаем следующие конфигурации:
Просто установите airllm и запустите код так же, как в Linux. Дополнительную информацию см. в разделе «Быстрый старт».
Пример [блокнот Python] (https://github.com/lyogavin/airllm/blob/main/air_llm/examples/run_on_macos.ipynb)
Примеры колабов здесь:
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "THUDM/chatglm3-6b-base" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = True )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "Qwen/Qwen-7B" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "baichuan-inc/Baichuan2-7B-Base" )
#model = AutoModel.from_pretrained("internlm/internlm-20b")
#model = AutoModel.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ])Большая часть кода основана на великолепной работе SimJeg на экзамене Kaggle. Большой привет SimJeg:
Учетная запись GitHub @SimJeg, код на Kaggle, соответствующее обсуждение.
Safetensors_rust.SafetensorError: ошибка при десериализации заголовка: MetadataIncompleteBuffer
Если вы столкнулись с этой ошибкой, наиболее вероятная причина — нехватка места на диске. Процесс разделения модели очень трудоемкий. Посмотрите это. Возможно, вам придется расширить дисковое пространство, очистить .cachehuggingface и перезапустить.
Скорее всего, вы загружаете модель QWen или ChatGLM с классом Llama2. Попробуйте следующее:
Для модели QWen:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)Для модели ChatGLM:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)Некоторые модели являются закрытыми моделями, для которых требуется токен API Huggingface. Вы можете предоставить hf_token:
model = AutoModel . from_pretrained ( "meta-llama/Llama-2-7b-hf" , #hf_token='HF_API_TOKEN')Токенизатор некоторых моделей не имеет маркера заполнения, поэтому вы можете установить токен заполнения или просто отключить конфигурацию заполнения:
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False #<----------- turn off padding
)Если вы считаете AirLLM полезным для своего исследования и хотите процитировать его, используйте следующую запись BibTex:
@software{airllm2023,
author = {Gavin Li},
title = {AirLLM: scaling large language models on low-end commodity computers},
url = {https://github.com/lyogavin/airllm/},
version = {0.0},
year = {2023},
}
Приветствуются вклады, идеи и обсуждения!
Если вы найдете это полезным, пожалуйста, или купите мне кофе!


