JoyVASA
1.0.0
Сюян Цао 1* Гуосинь Ван 12* Шэн Ши 1* Цзюнь Чжао 1 Ян Яо 1
Цзиньтао Фэй 1 Минью Гао 1
1 JD Health International Inc. 2 Чжэцзянский университет
Портретная анимация на основе звука добилась значительных успехов благодаря моделям на основе диффузии, улучшая качество видео и точность синхронизации губ. Однако растущая сложность этих моделей привела к неэффективности обучения и вывода, а также к ограничениям на длину видео и непрерывность между кадрами. В этой статье мы предлагаем JoyVASA, основанный на диффузии метод для создания динамики лица и движения головы в анимации лица, управляемой звуком. В частности, на первом этапе мы вводим разделенную структуру представления лица, которая отделяет динамические выражения лица от статических трехмерных представлений лица. Такое разделение позволяет системе генерировать более длинные видеоролики, комбинируя любое статическое трехмерное изображение лица с динамическими последовательностями движений. Затем, на втором этапе, диффузионный преобразователь обучается генерировать последовательности движений непосредственно из звуковых сигналов, независимо от личности персонажа. Наконец, генератор, обученный на первом этапе, использует трехмерное представление лица и сгенерированные последовательности движений в качестве входных данных для рендеринга высококачественной анимации. Благодаря раздельному изображению лица и независимому от личности процессу генерации движений JoyVASA выходит за рамки человеческих портретов и позволяет плавно анимировать морды животных. Модель обучена на гибридном наборе данных, состоящем из частных данных на китайском и общедоступном английском языке, что обеспечивает многоязычную поддержку. Результаты экспериментов подтверждают эффективность нашего подхода. Будущая работа будет сосредоточена на улучшении производительности в реальном времени и совершенствовании управления выражениями, что еще больше расширит возможности применения платформы в портретной анимации.
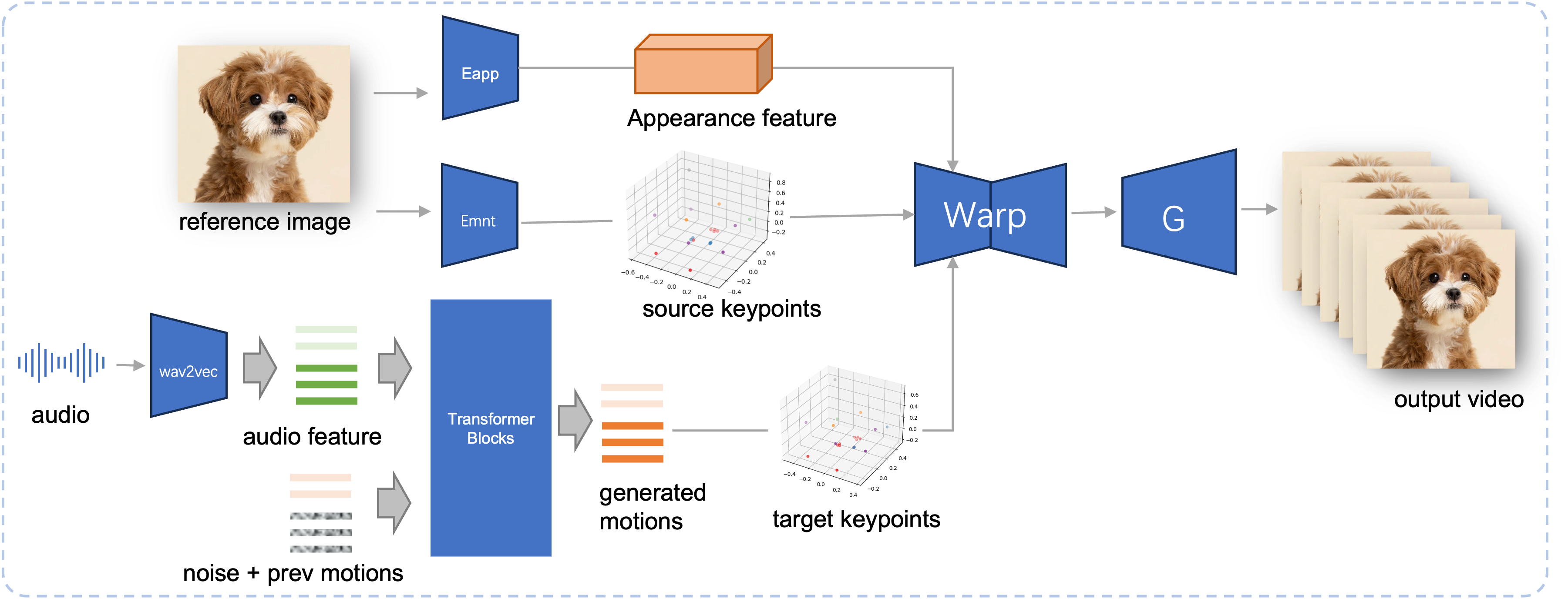
Конвейер вывода предлагаемого JoyVASA. Учитывая эталонное изображение, мы сначала извлекаем трехмерную особенность внешнего вида лица с помощью кодировщика внешнего вида в LivePortrait, а также ряд изученных трехмерных ключевых точек с помощью кодировщика движения. Для входной речи аудиофункции изначально извлекаются с помощью кодера wav2vec2. Затем последовательности движений, управляемые звуком, отбираются с использованием модели диффузии, обученной на втором этапе в режиме скользящего окна. Используя ключевые точки 3D эталонного изображения и выбранные целевые последовательности движений, вычисляются целевые ключевые точки. Наконец, трехмерный внешний вид лица деформируется на основе исходных и целевых ключевых точек и визуализируется генератором для создания окончательного выходного видео.
Системные требования:
Убунту:
Протестировано на Ubuntu 20.04, Cuda 11.3.
Протестированные графические процессоры: A100
Окна:
Протестировано на Windows 11, CUDA 12.1.
Протестированные графические процессоры: графический процессор RTX 4060 для ноутбука с 8 ГБ видеопамяти
Создать среду:
# 1. Создать базовую средуconda create -n joyvasa python=3.10 -y Конда активирует Джойвасу # 2. Установите requirepip install -r require.txt# 3. Установите обновление ffmpegsudo apt-get. sudo apt-get install ffmpeg -y# 4. Установите MultiScaleDeformableAttentioncd src/utils/dependents/XPose/models/UniPose/ops python setup.py build installcd - # равно cd ../../../../../../../
Убедитесь, что у вас установлен git-lfs, и загрузите все следующие контрольные точки в pretrained_weights :
установка git lfs git-клон https://huggingface.co/jdh-algo/JoyVASA
Мы поддерживаем два типа аудиокодеров, включая wav2vec2-base и Hubert-Chinese.
Выполните следующие команды, чтобы загрузить предварительно обученные веса Hubert-Chinese:
установка git lfs git clone https://huggingface.co/TencentGameMate/chinese-hubert-base
Чтобы получить предварительно обученные веса на основе wav2vec2, выполните следующие команды:
установка git lfs git-клон https://huggingface.co/facebook/wav2vec2-base-960h
Примечание
Модель генерации движения с кодировщиком wav2vec2 будет поддерживаться позже.
# !pip install -U "huggingface_hub[cli]"huggingface-cli download KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
Дополнительные способы загрузки можно найти в Liveportrait.
pretrained_weights Окончательный каталог pretrained_weights должен выглядеть так:
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.jsonПримечание
Папку TencentGameMate:chinese-hubert-base в Windows следует переименовать в chinese-hubert-base .
Животное:
python inference.py -r assets/examples/imgs/joyvasa_001.png -a assets/examples/audios/joyvasa_001.wav --animation_mode Animal --cfg_scale 2.0
Человек:
python inference.py -r assets/examples/imgs/joyvasa_003.png -a assets/examples/audios/joyvasa_003.wav --animation_mode human --cfg_scale 2.0
Вы можете изменить cfg_scale, чтобы получить результаты с разными выражениями лиц и позами.
Примечание
Несовпадение режима анимации и эталонного изображения может привести к неверным результатам.
Используйте следующую команду, чтобы запустить веб-демо:
приложение Python.py
Демо-версия будет создана по адресу http://127.0.0.1:7862.
Если наша работа окажется для вас полезной, пожалуйста, цитируйте нас:
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}Мы хотели бы поблагодарить участников репозиториев LivePortrait, Open Facevid2vid, InsightFace, X-Pose, DiffPoseTalk, Hallo, wav2vec 2.0, Chinese Speech Pretrain, Q-Align, Syncnet и VBench за их открытые исследования и выдающуюся работу.


