synthetic data generator
0.2.3
Переключить язык: 简体中文 | Последняя документация по API | Дорожная карта | Присоединяйтесь к группе Wechat
Примеры Colab: LLM: Синтез данных | LLM: Выводы вне таблицы | Поддержка данных уровня миллиарда CTGAN
Генератор синтетических данных (SDG) — это специализированная платформа, предназначенная для создания высококачественных структурированных табличных данных.
Синтетические данные не содержат никакой конфиденциальной информации, но сохраняют основные характеристики исходных данных, что освобождает их от таких правил конфиденциальности, как GDPR и ADPPA.
Высококачественные синтетические данные можно безопасно использовать в различных областях, включая обмен данными, обучение и отладку моделей, разработку и тестирование систем и т. д.
Мы рады видеть вас здесь и с нетерпением ждем вашего вклада. Начните работу над проектом с помощью этого обзорного руководства для участников!
Наши текущие ключевые достижения и сроки таковы:
21 ноября 2024 г.: 1) Интеграция модели. Мы интегрировали модель GaussianCopula в нашу систему обработки данных. Ознакомьтесь с примером кода в этом PR; 2) Синтетическое качество. Мы реализовали автоматическое обнаружение взаимосвязей столбцов данных и разрешили спецификацию взаимосвязей, улучшили качество синтетических данных (пример кода); 3) Повышение производительности. Мы значительно сократили использование памяти GaussianCopula при обработке дискретных данных, что позволило обучаться на тысячах записей категориальных данных с настройкой 2C4G !
30 мая 2024 г.: модуль «Обработчик данных» был официально объединен. Этот модуль: 1) поможет SDG преобразовать формат некоторых столбцов данных (например, столбцов Datetime) перед подачей в модель (чтобы их не рассматривали как дискретные типы), а также обратно преобразовать данные, сгенерированные моделью, в исходный формат. ; 2) выполнять более индивидуальную предварительную и постобработку различных типов данных; 3) легко справляться с такими проблемами, как нулевые значения в исходных данных; 4) поддержка системы плагинов.
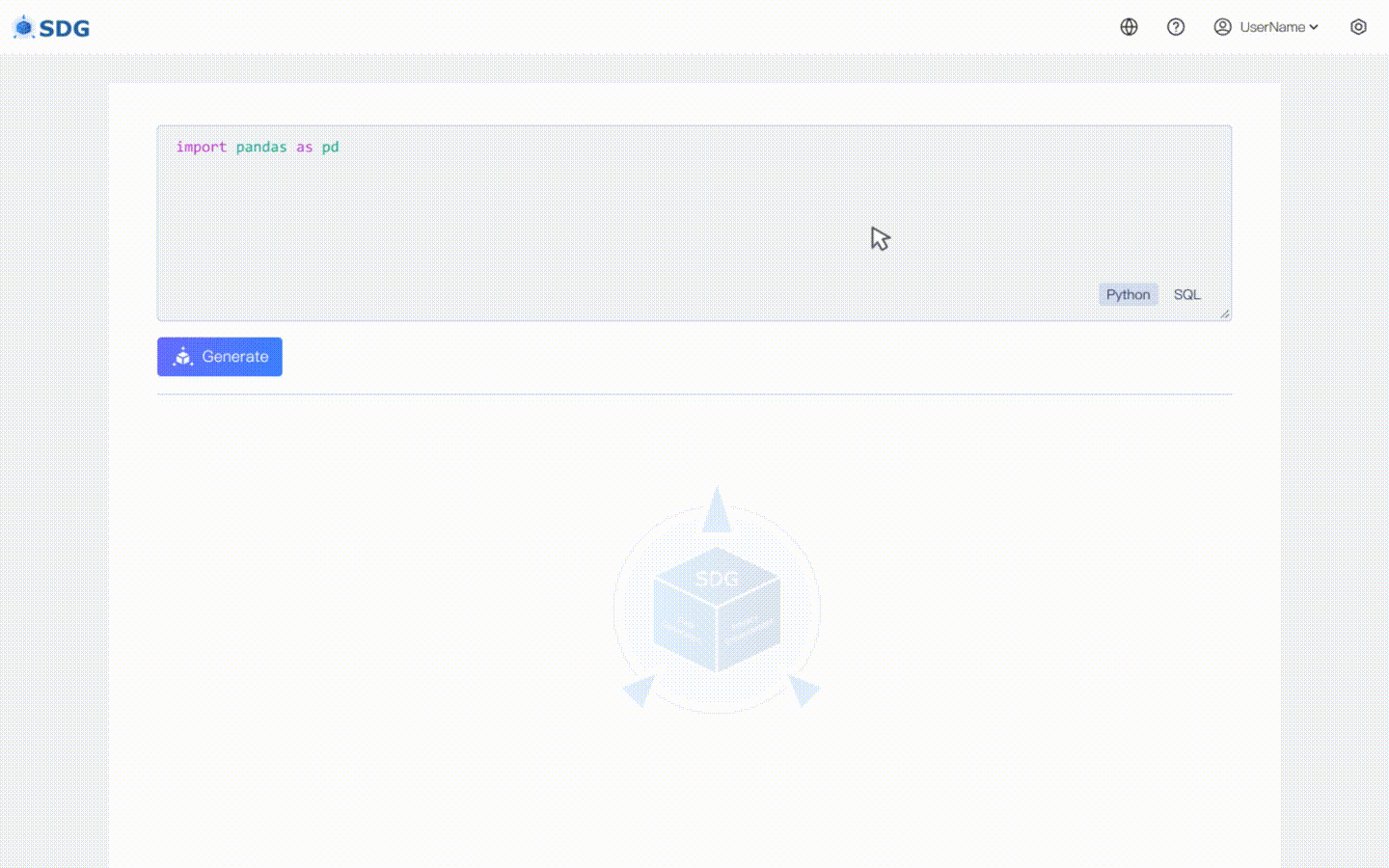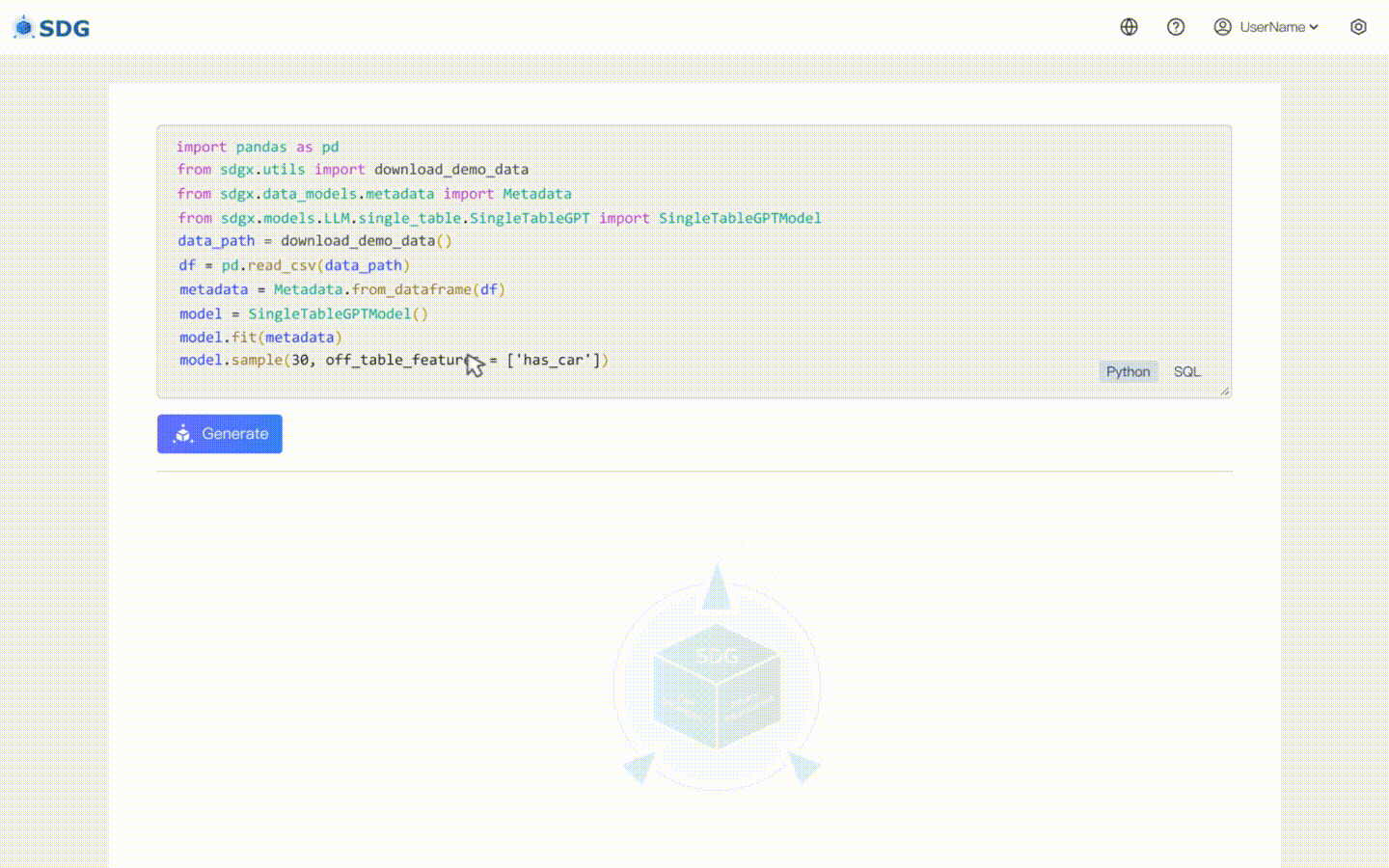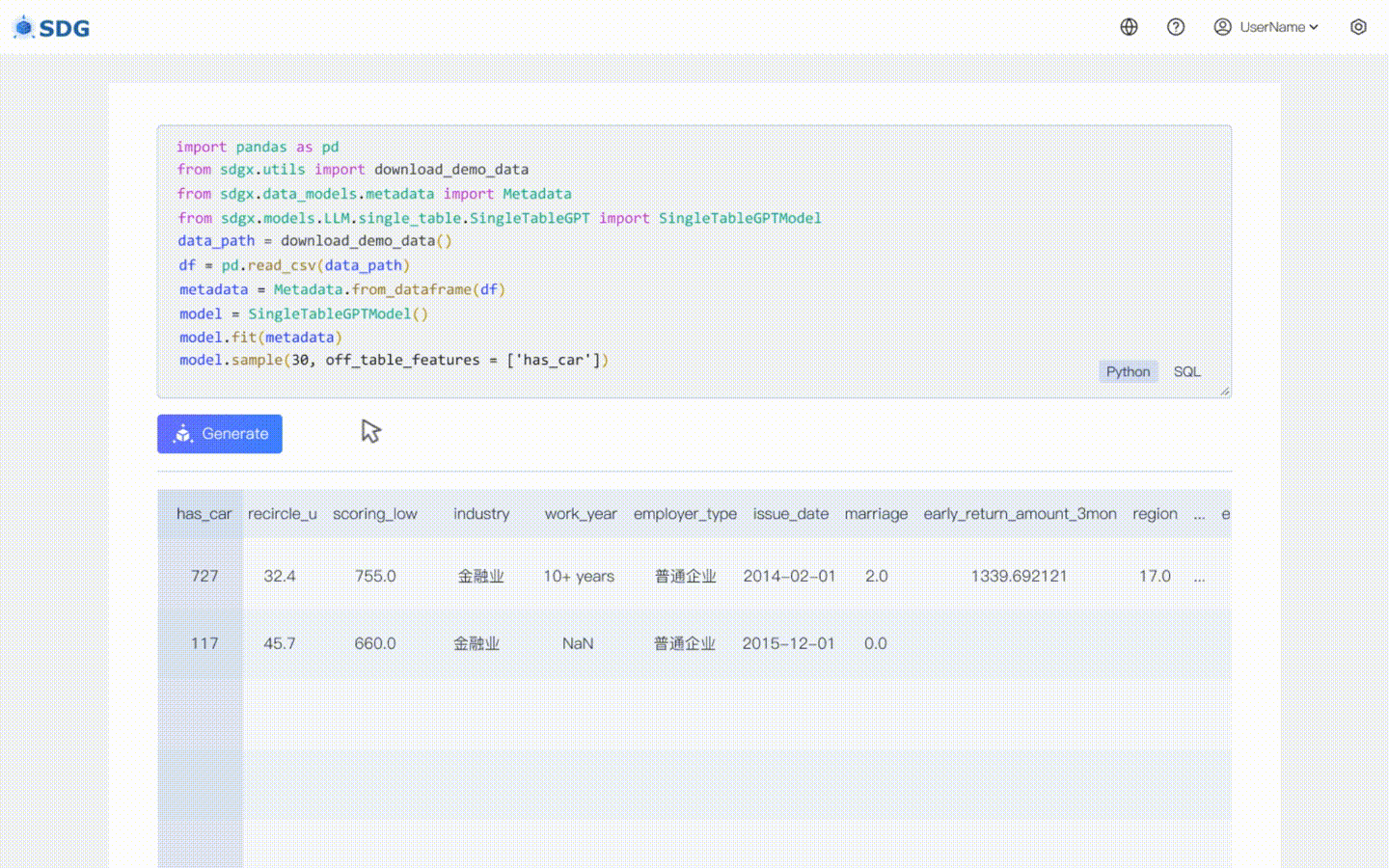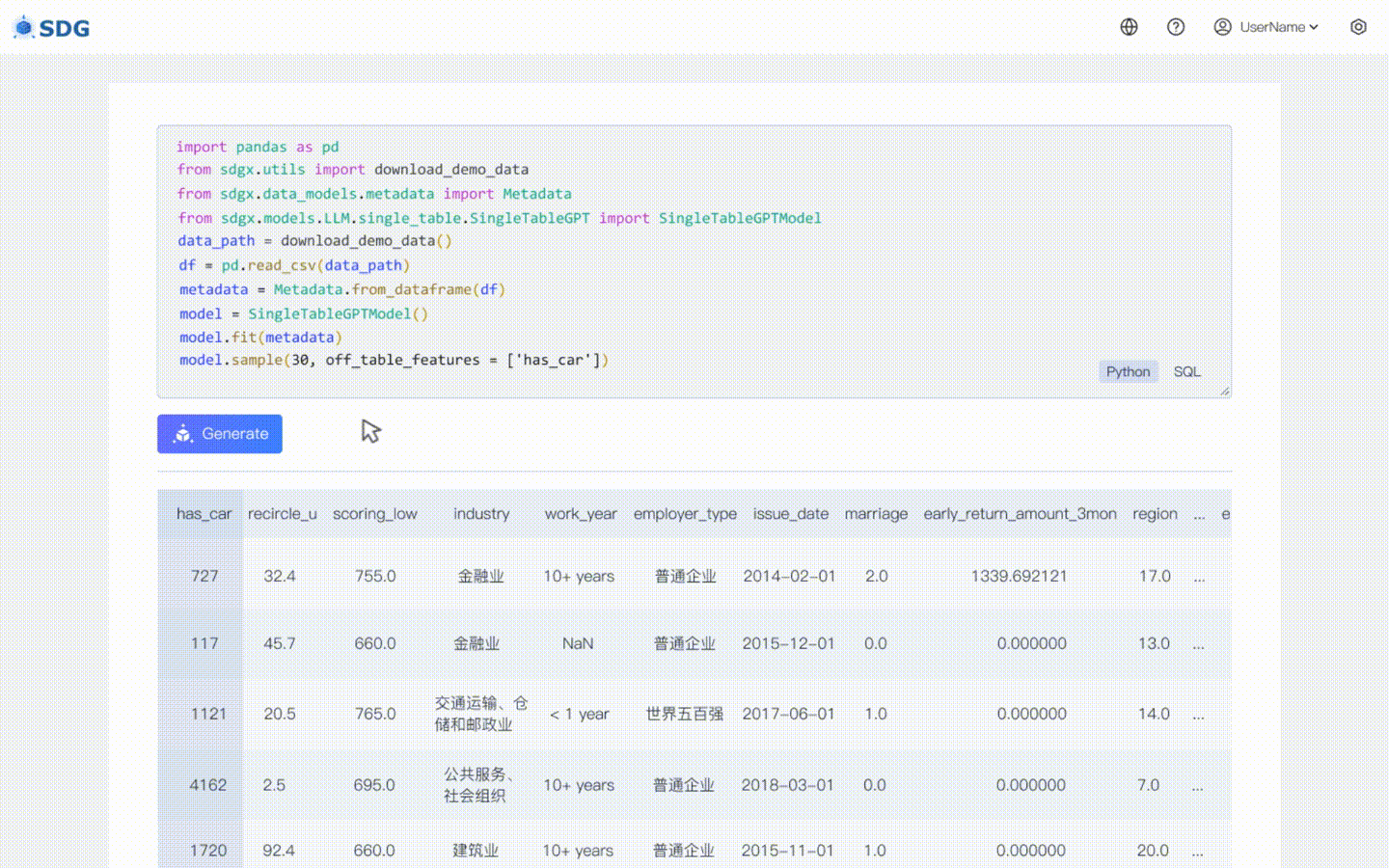
20 февраля 2024 г.: включена модель синтеза данных с одной таблицей на основе LLM. Посмотреть пример Colab: LLM: Синтез данных и LLM: Вывод функций вне таблицы.
7 февраля 2024 г.: мы улучшили sdgx.data_models.metadata для поддержки информации метаданных, описывающей отдельные таблицы и несколько таблиц, поддержки нескольких типов данных, поддержки автоматического вывода типов данных. просмотреть пример Colab: Метаданные одной таблицы ЦУР。
20 декабря 2023 г.: выпущена версия 0.1.0, включена модель CTGAN, поддерживающая миллиарды возможностей обработки данных. Посмотрите наш тест на SDV, где SDG добился меньшего потребления памяти и избежал сбоев во время обучения. Для конкретного использования см. пример Colab: CTGAN с поддержкой данных миллиарда уровней.
10 августа 2023 г.: принята первая строка кода ЦУР.
В течение долгого времени LLM использовался для понимания и создания различных типов данных. Фактически, LLM также имеет определенные возможности по созданию табличных данных. Кроме того, он обладает некоторыми возможностями, которых невозможно достичь традиционными методами (основанными на методах GAN или статистических методах).
Наша sdgx.models.LLM.single_table.gpt.SingleTableGPTModel реализует две новые функции:
Никаких обучающих данных не требуется, синтетические данные могут быть сгенерированы на основе данных метаданных, как показано в нашем примере совместной работы.
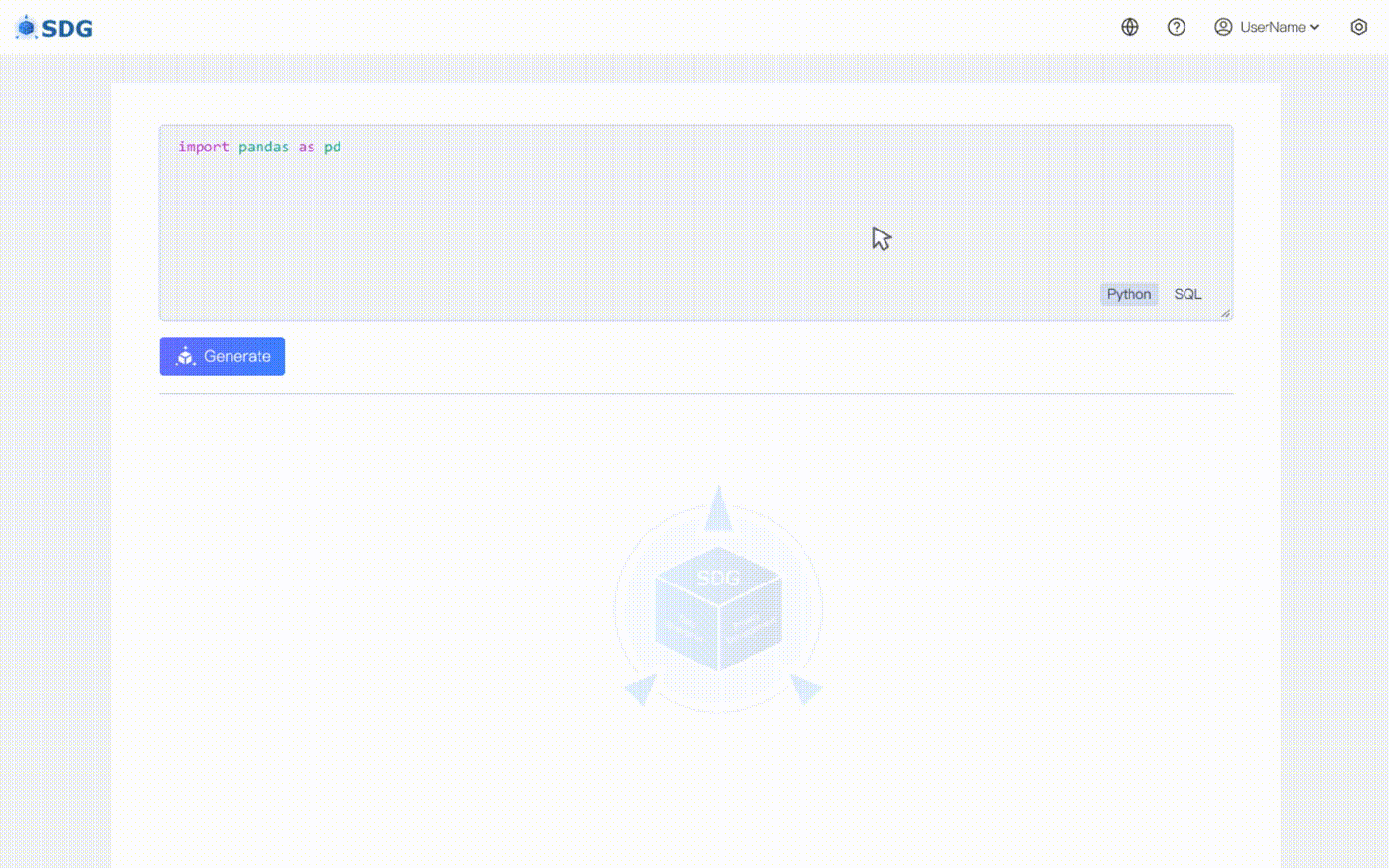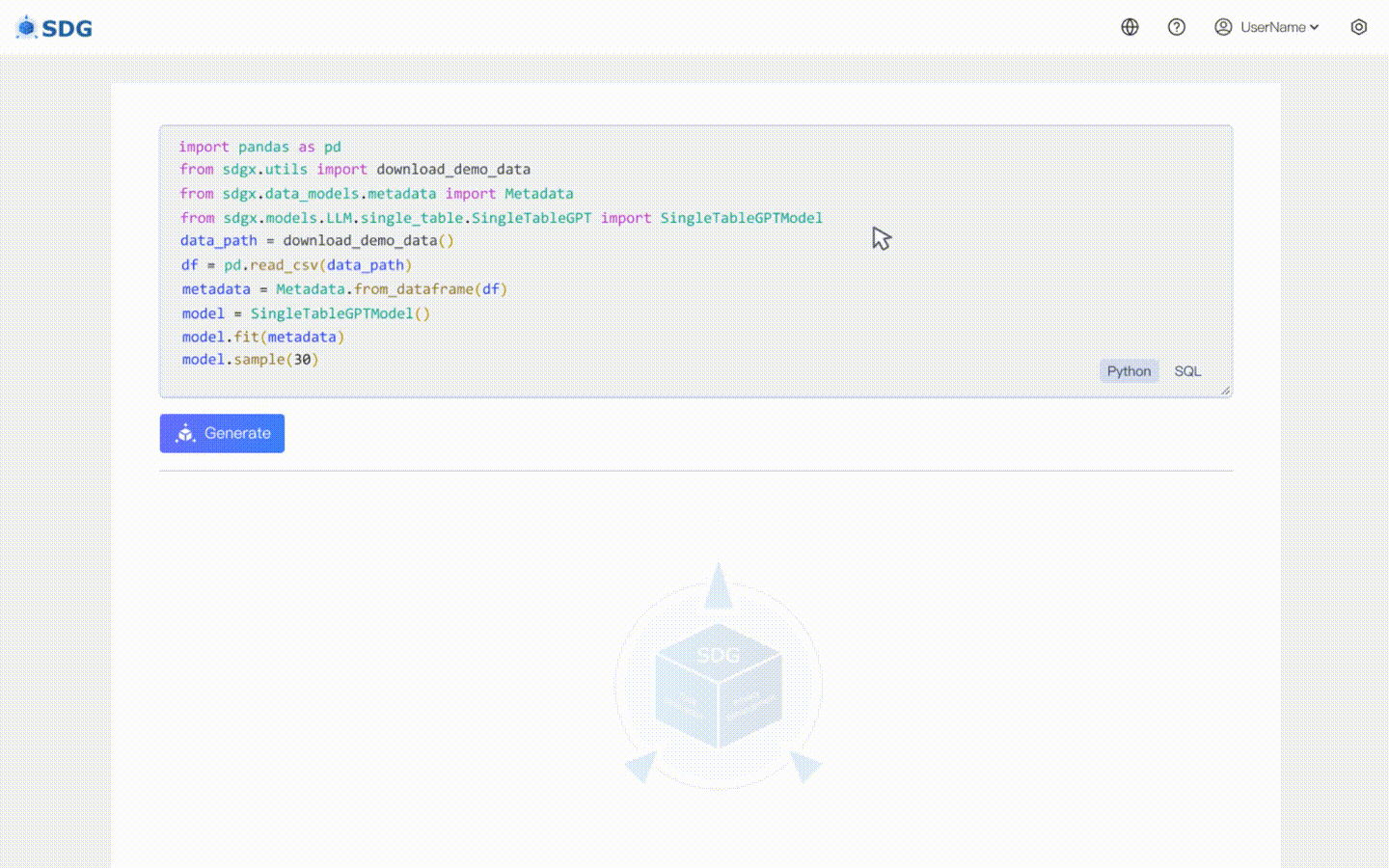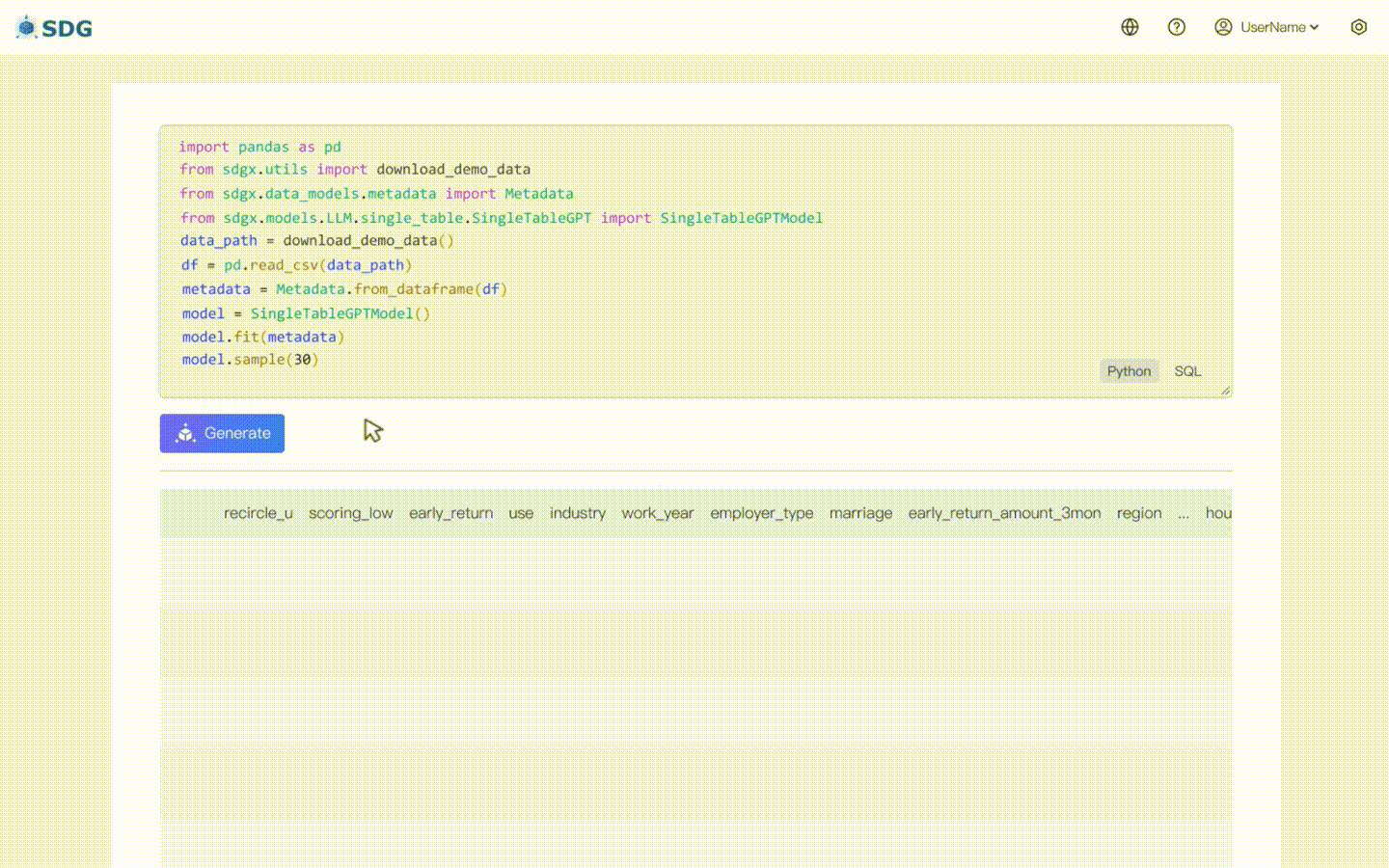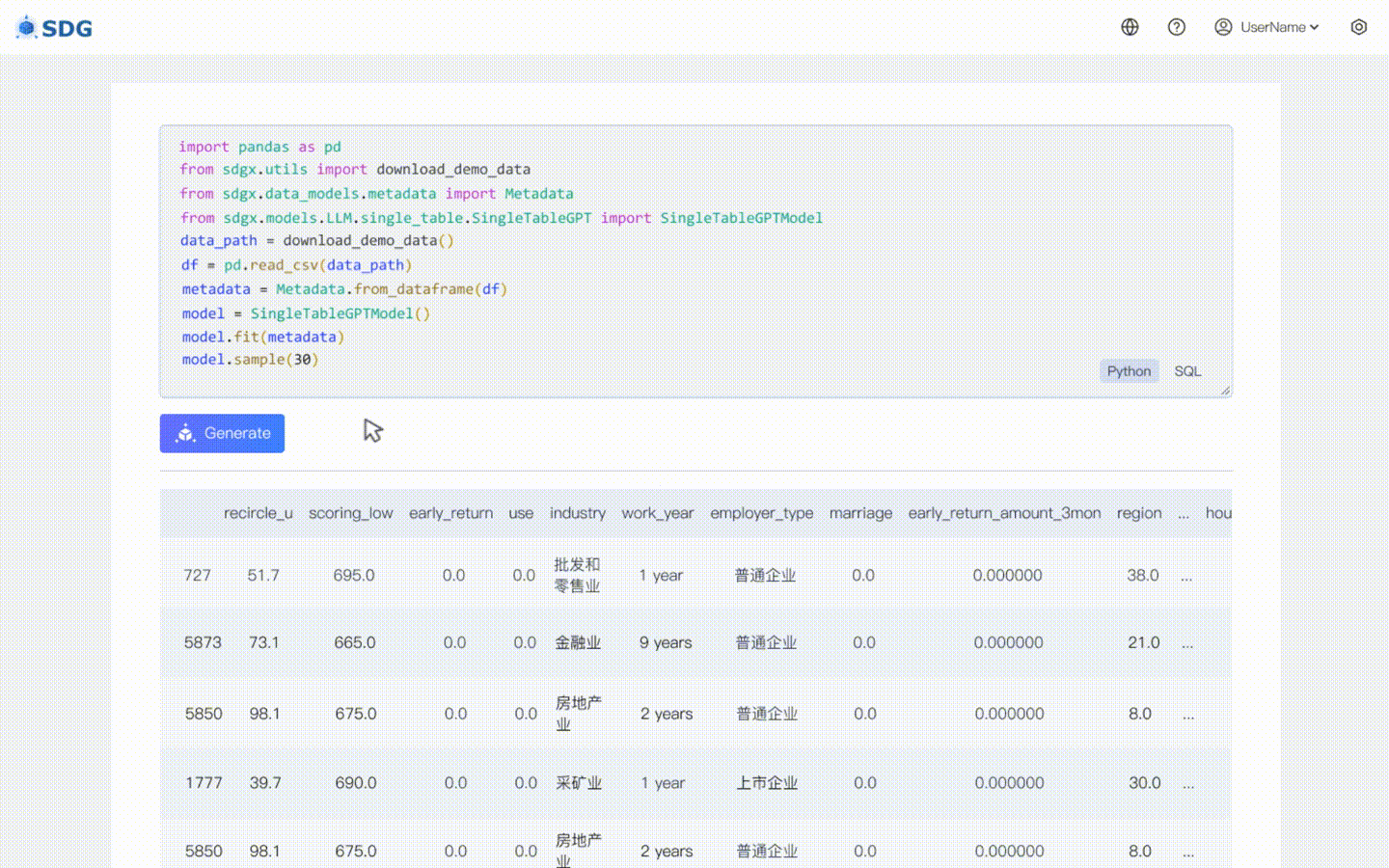
Выведите новые данные столбца на основе существующих данных в таблице и знаний, полученных LLM, см. в нашем примере совместной работы.
Технологические достижения:
Поддерживает широкий спектр алгоритмов синтеза статистических данных, также интегрирована модель генерации синтетических данных на основе LLM;
Оптимизирован для больших данных, эффективно снижая потребление памяти;
Постоянное отслеживание последних достижений в научных кругах и промышленности и своевременное внедрение поддержки отличных алгоритмов и моделей.
Улучшения конфиденциальности:
SDG поддерживает дифференцированную конфиденциальность, анонимизацию и другие методы повышения безопасности синтетических данных.
Легко расширить:
Поддерживает расширение моделей, обработку данных, коннекторы данных и т.п. в виде пакетов плагинов.
Вы можете использовать готовые изображения, чтобы быстро опробовать новейшие функции.
docker pull idsteam/sdgx: последний
pip установить SDGX
Используйте SDG, установив его через исходный код.
git clone [email protected]:hitsz-ids/synthetic-data-generator.git pip install .# Или установите из gitpip install git+https://github.com/hitsz-ids/synthetic-data-generator.git
from sdgx.data_connectors.csv_connector import CsvConnectorfrom sdgx.models.ml.single_table.ctgan import CTGANSynthesizerModelfrom sdgx.synthesizer import Synthesizerfrom sdgx.utils import download_demo_data# Это позволит загрузить демонстрационные данные в ./datasetdataset_csv = download_demo_data()# Создать соединитель данных для csv filedata_connector = CsvConnector(path=dataset_csv)# Инициализируйте синтезатор, используйте CTGAN modelsynthesizer = Synthesizer(model=CTGANSynthesizerModel(epochs=1), # Для быстрого demodata_connector=data_connector, )# Подгоняем modelynthesizer.fit()# Samplesampled_data = Syntheser.sample(1000)print(sampled_data)
Реальные данные следующие:
>>> data_connector.read() возраст рабочий класс fnlwgt образование ... капитальные потери часы в неделю родная страна class0 2 State-gov 77516 Бакалавры ... 0 2 Соединенные Штаты <= 50K1 3 Self-emp-not-inc 83311 Бакалавры .. . 0 0 США <=50K2 2 Частный 215646 HS-grad ... 0 2 США <=50K3 3 Частное 234721 11 ... 0 2 США <=50K4 1 Частное 338409 Бакалавры ... 0 2 Куба <=50K... ... ... ... ... . .. ... ... ... ...48837 2 Частное лицо 215419 Бакалавриат ... 0 2 США <=50K48838 4 NaN 321403 HS-grad ... 0 2 США <=50K48839 2 Частное образование 374983 Бакалавриат ... 0 3 США <=50K48840 2 Частное образование 83891 Бакалавриат ... 0 2 США <=50K48841 1 Self-emp- вкл 182148 Бакалавриат ... 0 3 США >50 тыс. [48842 строк x 15 столбцов]
Синтетические данные следующие:
>>> sample_data возраст рабочий класс fnlwgt образование ... капитальные потери часы в неделю родная страна класс0 1 NaN 28219 Какой-то колледж ... 0 2 Пуэрто-Рико <=50K1 2 Частный 250166 HS-grad ... 0 2 Соединенные Штаты >50K2 2 Частный 50304 HS-grad ... 0 2 США <=50K3 4 Частное 89318 Бакалавриат ... 0 2 Пуэрто-Рико >50K4 1 Частное 172149 Бакалавриат ... 0 3 Соединенные Штаты <=50K.. ... ... ... ... ... ... .. . ... ...995 2 NaN 208938 Бакалавриат ... 0 1 США <=50K996 2 Частное лицо 166416 Бакалавриат ... 2 2 США <=50K997 2 NaN 336022 HS-grad ... 0 1 США <=50K998 3 Частное 198051 Магистратура ... 0 2 США >50K999 1 NaN 41973 HS-grad ... 0 2 США <= 50 КБ [1000 строк x 15 столбцов]
CTGAN: моделирование табличных данных с использованием условного GAN.
C3-TGAN: C3-TGAN — управляемый синтез табличных данных с явными корреляциями и ограничениями свойств.
TVAE: моделирование табличных данных с использованием условного GAN.
table-GAN: Синтез данных на основе генеративно-состязательных сетей
CTAB-GAN:CTAB-GAN: эффективный синтез табличных данных
OCT-GAN: OCT-GAN: условные табличные GAN на основе нейронных ODE
Проект ЦУР был инициирован Институтом безопасности данных Харбинского технологического института . Если вас заинтересовал наш проект, добро пожаловать в наше сообщество. Мы приветствуем организации, команды и отдельных лиц, которые разделяют нашу приверженность защите и безопасности данных с помощью открытого исходного кода:
Прочтите «ВКЛАД», прежде чем составлять запрос на включение.
Сообщите о проблеме, просмотрев «Просмотреть хороший первый выпуск», или отправьте запрос на включение.
Присоединяйтесь к нашей группе Wechat через QR-код.


